Google Vertex AI로 신용카드 이상탐지 AutoML 모델 만들기 2/2편
MLOps
Google Vertex AI 간단한 소개
Google Cloud의 AI Platform, AutoML 등 다양한 머신러닝 서비스를 하나의 인터페이스(UI / API)에서 사용할 수 있도록 구성된 종합선물 과자세트 같은 서비스입니다.
데이터셋 구성부터 모델 생성, 학습, 테스트, 검증하고 애플리케이션에서 Endpoint로 사용할 수 있도록 배포까지 하나의 파이프라인으로 구성 가능합니다.
API를 이용하여 Jupyter Notebook에서 구성할 수도 있고, 클라우드 엔지니어가 직접 UI에서 AutoML을 이용하여 개발할 수도 있습니다.

Preface
지난 이야기
지난 포스팅에서는 신용카드 이상탐지 분류 모델을 AutoML을 이용하여 만들고 훈련(Train)을 시켜보았습니다.
이어서 모델을 평가하고 컨테이너로 배포하여 엔드포인트로 서비스를 테스트 해봅시다.
Pre Hands-On Requirements
- Google Cloud Platform 계정 (Google 계정으로 무료 크레딧을 받아봅시다!)
아주 약간의 머신러닝 지식- Confusion Matrix (혼동행렬)
- Feature Importance
- Precision
- Recall
- ROC Curve
아주 약간의 컴퓨터 사이언스 지식- Application Programming Interface
- 컨테이너🐳
- Python 쓸 줄 안다
- Jupyter Notebook 가 뭔지 안다
아주 약간의 클라우드 컴퓨팅 지식- CLI 쓸 줄 안다
- Vertex AI에 Fraud Detection 모델
- Google Vertex AI로 신용카드 이상탐지 AutoML 모델 만들기 1/2편를 먼저 하고 오세요!
Hands-On
6. 모델 평가하기
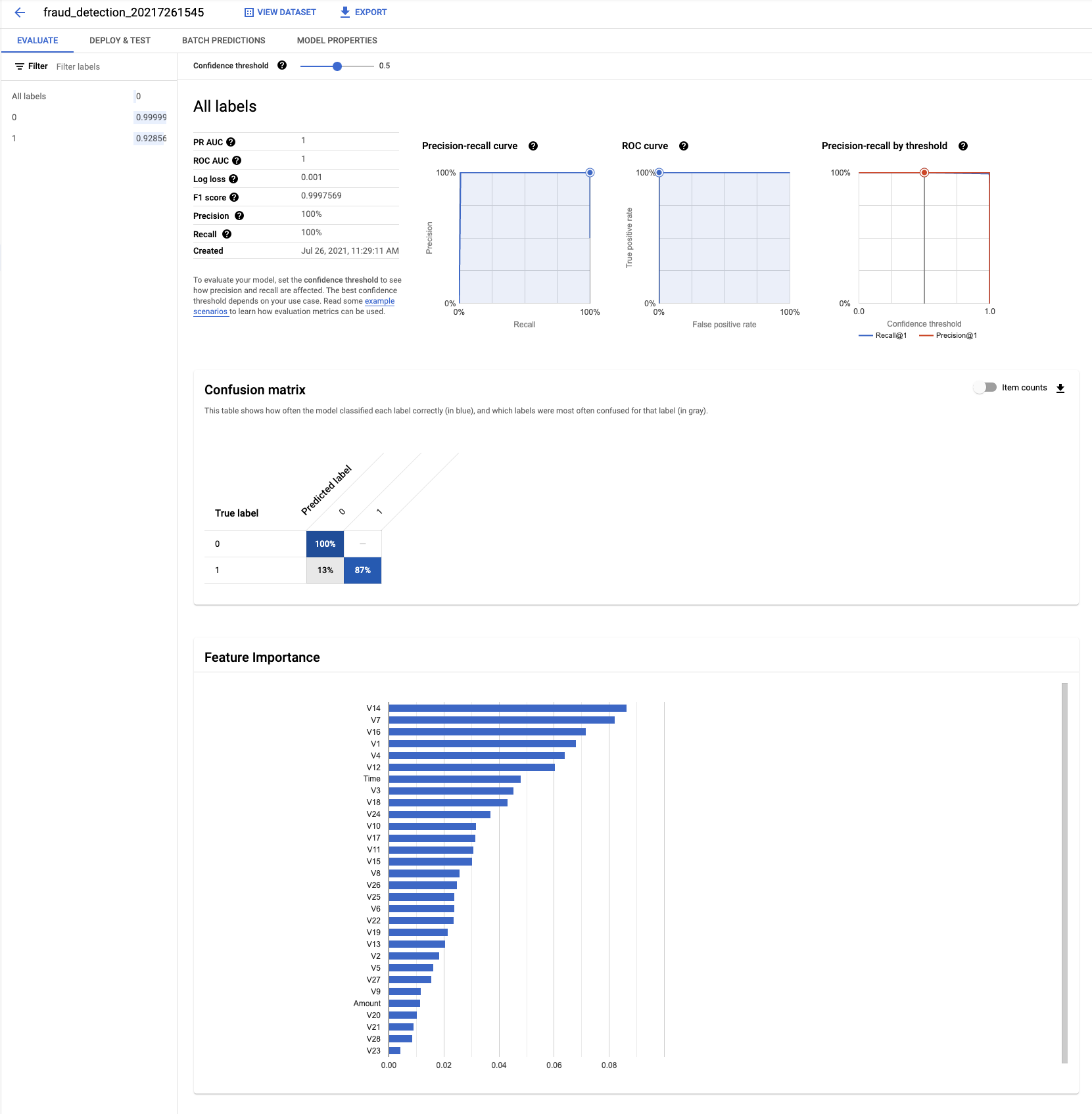
AutoML을 통해 만든 Classification 분류 모델을 학습을 약 1시간 22분 걸려서 완료하였습니다.
머신러닝 모델을 학습하면 일반적으로는 평가라는 단계를 거칩니다. 이 모델의 성능이 잘 나왔는지, 살펴보는 검증의 시간인 것이지요.
자, 학습된 모델을 클릭해서 들어가봅시다!
Evaluate 탭이 첫 화면으로 보일 거에요.
BI 화면도 아닌 것이 무슨 그래프 여러개와 알파벳과 숫자들의 향연을 마주하시게 될 것입니다.
여러분들은 당황한 티 내지 마시고
우선 말 없이 고개를 두 번 끄덕입시다.

머신러닝도 잘 하는구나 하고 사람들이 생각할 것입니다.
좋아 자연스러웠어
6.1. Confusion Matrix 이해하기
먼저 Classification 모델에서 평가지표로 사용되는 Confusion Matrix입니다.
아! 맞다 그 전에 왜 머신러닝 용어들은 긴 영어 단어를 굳이 꿋꿋하게 쓰고 있는지 설명 드릴게요!
매우매우매우 중요합니다!!
머신러닝 논문을 읽거나 사람들과 대화할 때 영어 단어를 자주 사용하는 편입니다.
그러니까 우리도 머신러닝 스페셜리스트인냥 위장을 위해 익숙해집시다.
다시 우리가 만든 모델의 Confustion Matrix를 살펴봅시다!
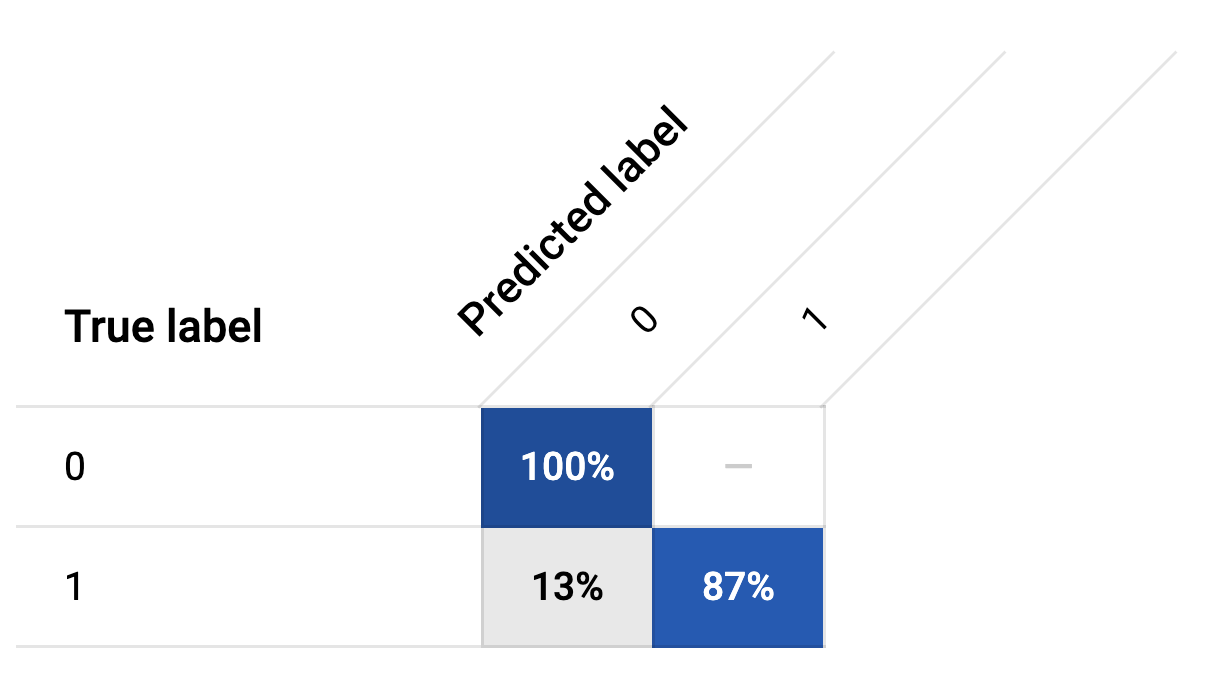
각 항에는 True label, Predicted label이 있고 0,1이 써있습니다.
Classification은 지도학습으로 답(label)을 알려주고 예측을 시키는 방법입니다.
우리가 예측하고 싶은 이상여부의 실제값(True label)과 예측값(Predicted label)을 비교해서 정확도를 나타내는 것입니다.
- 실제 0인데, 예측도 0인 확률 (정답입니다)
- 실제 0인데, 예측이 1인 확률
- 실제 1인데, 예측이 0인 확률
- 실제 1인데, 예측도 1인 확률 (정답입니다)
순서대로 TP(True Positive),FP(False Positive), FN(False Negative), TN(True Negative)라고 부릅니다.
그리고 이 항목들을 요리조리 더하고 나누면 Accuracy, Precision, Recall 항목을 도출할 수 있습니다.
이야기를 더하고 싶지만 사실 어려워서 도망,
제가 머리가 아픈 관계로 다음에 설명 드리도록 하고 모델 평가를 이어 하겠습니다.

성능이 엄청나군요!!
정상 처리인 0을 100% 맞췄습니다.
그리고 사기 케이스인 1을 87% 맞췄습니다.
축하합니다! 🎉🎉🎉
여러분은 자신도 모르는 사이에 이미 훌륭한 머신러닝 스페셜리스트로 진화하였습니다.👩🏫
6.2. Feature Importance
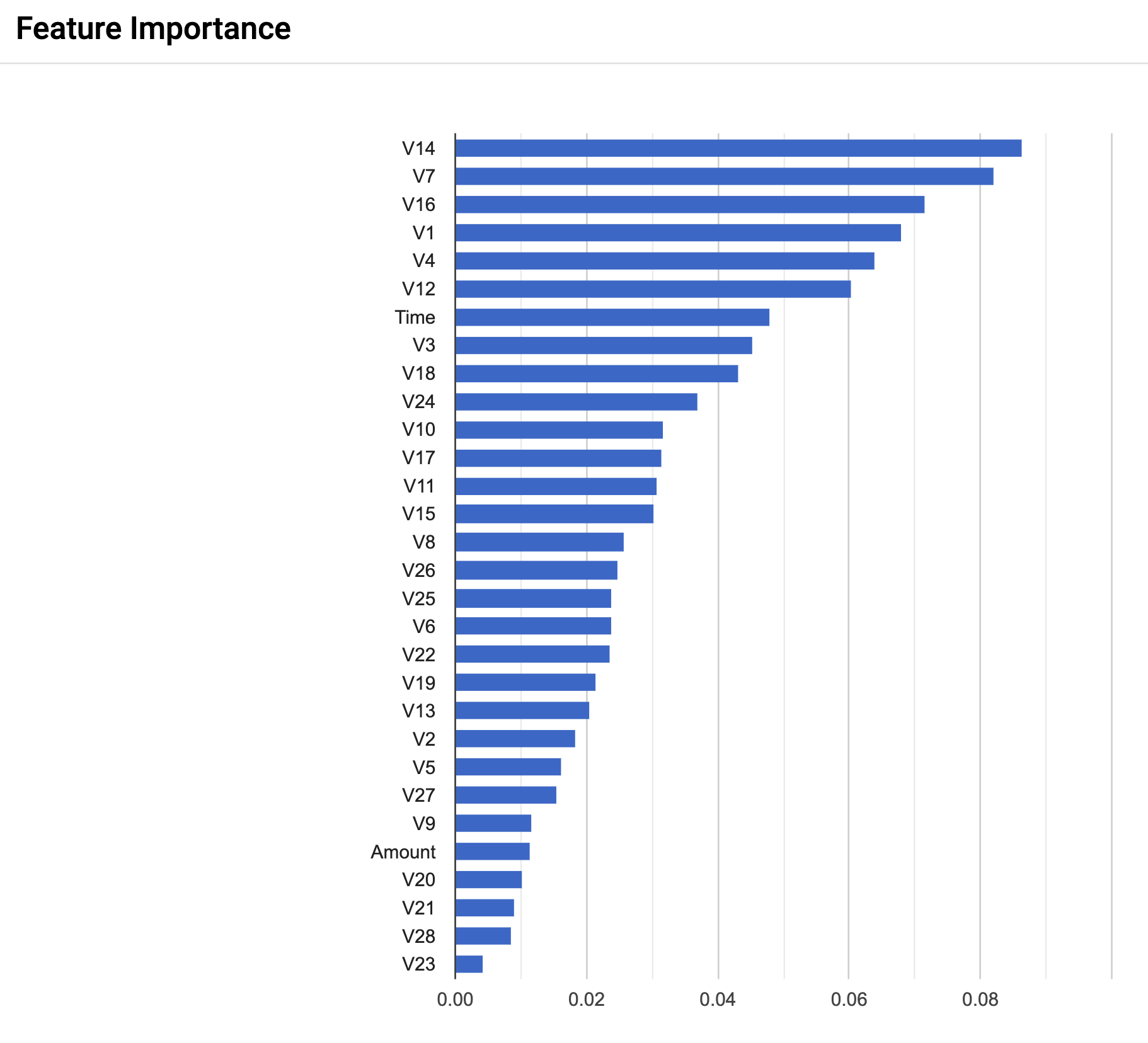
Confusion Matrix 밑에 요 그래프가 보이실 거에요.
모델에서 예측할 때 가장 영향이 높았던 Feature들입니다.
실제 데이터를 비식별화하여 Feature 이름만 보고 알 수 없지만,
가지고 계신 데이터를 이용해서 돌려보면, 이해도가 높기 때문에 데이터 이해와 통찰력을 더 빠르게 얻을 수 있습니다.
6.3. ROC(Receiver operating characteristic) Curve
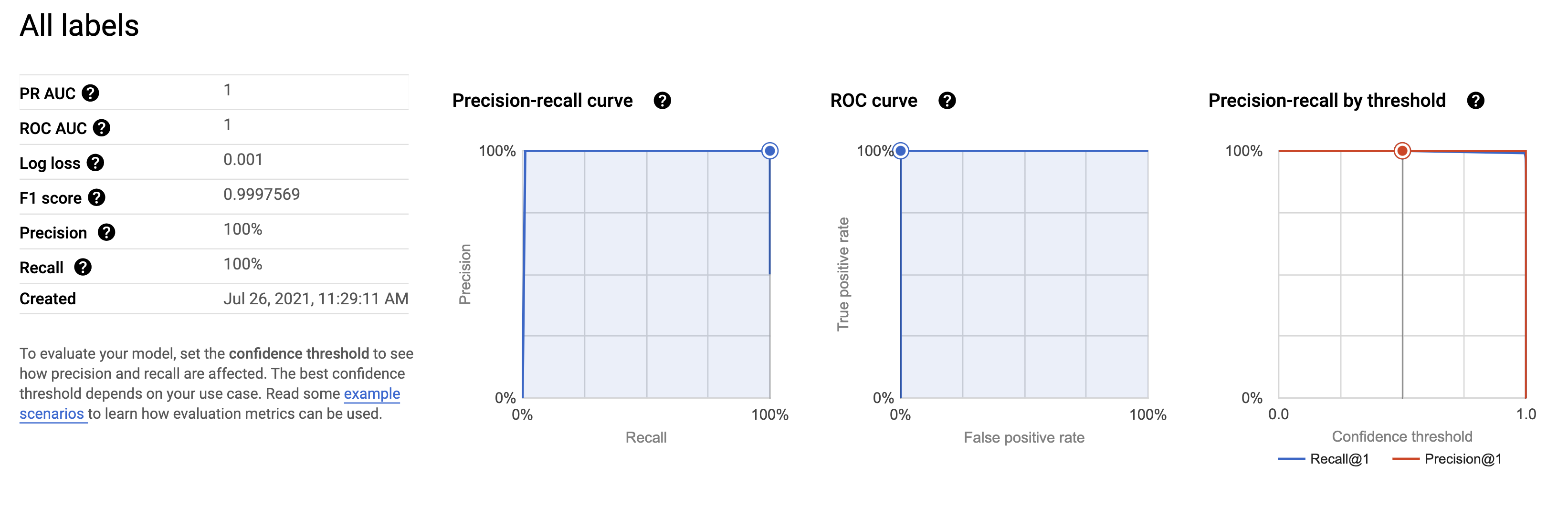
설명하기 위해서 찾아봤더니 한국말로는 수신자 조작 특성이라고 부르나 봐요.

괜찮습니다. 몰라도 되요.
다 필요 없고 ROC Curve라는 그래프 선이 왼쪽 상단 모서리에 가까운 모양일수록 성능이 좋다는 뜻입니다.
ROC Curve 그래프가 그리는 선 아래에 넓이를 AUC라고 부르고, Curve 그래프와 달리, 넓이로 수치화하여 성능을 표현할 수 있기 떄문에 사용합니다.
1에 가까울 수록 좋은 겁니다.
우리가 만든 모델의 ROC Curve를 봅시다.
왼쪽 상단 모서리를 찍었습니다.
값은 1입니다.
다시 한 번 말씀 드리지만,
여러분은 엄청난 Classification 모델을 만들었습니다.

대단하시니까, 쌍따봉 드립니다.
7. 엔드포인트 배포
훈련과 평가가 끝난 이 훌륭한 모델을 사용해보도록 합시다!
과거 Monolithic 애플리케이션에서는 배포를 위해 중단이 필요했습니다.
하지만 엔드포인트로 통신하며 업데이트된 모델을 중단 없이 바로 사용할 수 있도록 엔드포인트 배포를 해보도록 하겠습니다.

모델에서 DEPLOY & TEST를 클릭합니다.
그리고 Deploy your model 섹션에 위치한 DEPLOY TO ENDPOINT를 클릭합니다.
Endpoint name은 적절하게 명명하고 CONTINUE를 클릭합니다.
저는 엄청난 모델을 만든 기쁨을 표현해보았습니다.
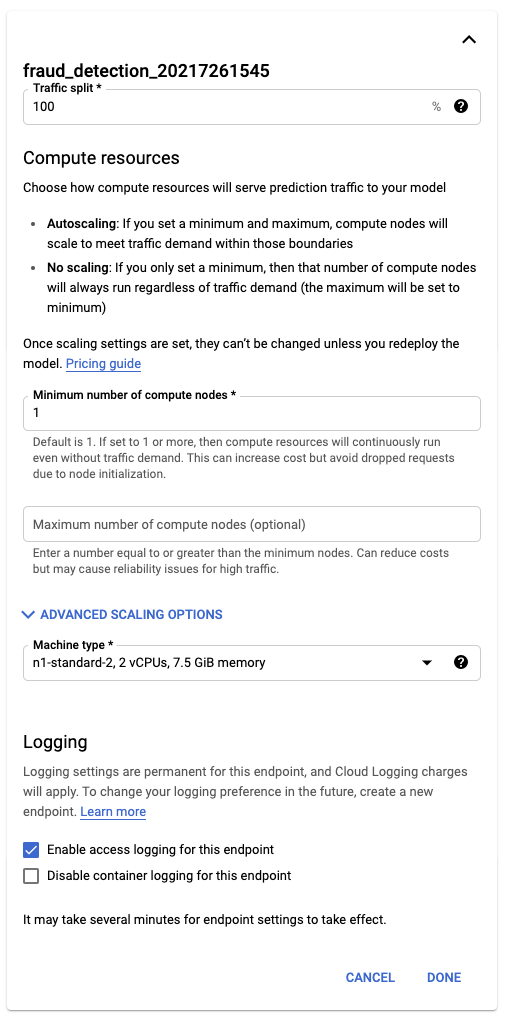
ADVANCED SCALING OPTIONS에서 적절한 Machine type을 선택합니다.
저는 돈을 아끼고 싶기 때문에 선택지에서 가장 작은 n1-standard-2를 선택하고 DEPLOY 하겠습니다.
8. API로 서비스 테스트하기
모델을 엔드포인트로 배포 되었나요?
이제 여러분의 엄청난 모델을 서비스 할 시간입니다.
아까 만든 Jupyter Notebook을 가볼까요

OPEN JUPYTERLAB을 클릭합니다.
그 다음에 Notebook > Python 3를 클릭합니다.
빈 칸에 아래 코드를 입력한 다음 OPTION + ENTER (ALT + ENTER)를 쳐봅니다.
!pip3 install google-cloud-aiplatform --upgrade --user해당 라인이 실행되면서 다음 칸이 추가됩니다.

그 다음 칸에 아래 코드를 넣고 Project number와 Endpoint ID를 복사해서 수정합니다.
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(
endpoint_name="projects/YOUR-PROJECT-NUMBER/locations/us-central1/endpoints/YOUR-ENDPOINT-ID"
)
프로젝트 번호는 상단 우측에 콜론이 진화한 점 세 개 클릭 > Project settings 클릭하면 아래와 같이 Project number를 확인할 수 있습니다.

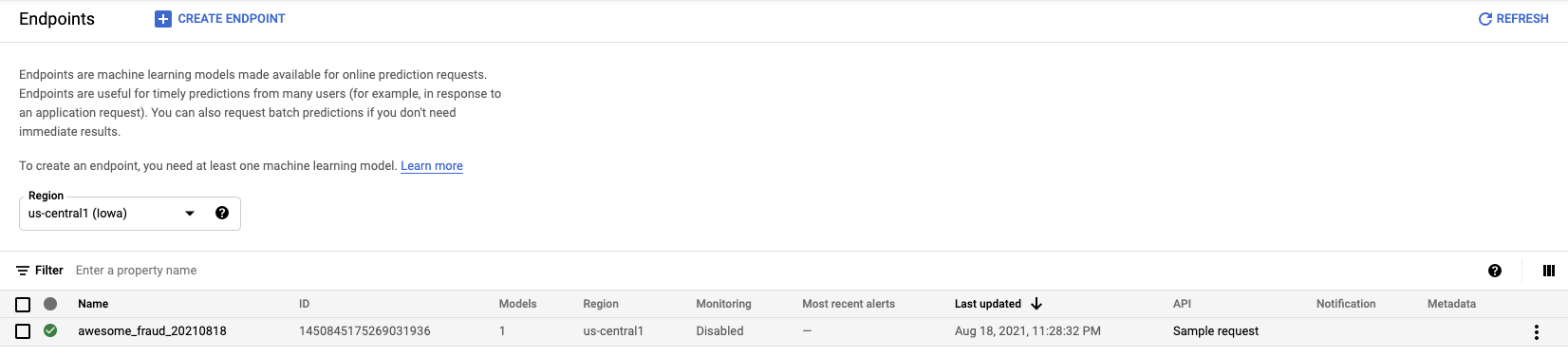
Endpoint ID는 Vertex AI > Endpoints 를 클릭합니다.
생성한 Endpoint의 ID가 보입니다.
위의 코드에 수정해서 넣은 후에 OPTION + ENTER
실행되고 새로 추가된 칸에 아래 테스트 데이터를 넣고 실행합니다.
test_instance={
'Time': 80422,
'Amount': 17.99,
'V1': -0.24,
'V2': -0.027,
'V3': 0.064,
'V4': -0.16,
'V5': -0.152,
'V6': -0.3,
'V7': -0.03,
'V8': -0.01,
'V9': -0.13,
'V10': -0.18,
'V11': -0.16,
'V12': 0.06,
'V13': -0.11,
'V14': 2.1,
'V15': -0.07,
'V16': -0.033,
'V17': -0.14,
'V18': -0.08,
'V19': -0.062,
'V20': -0.08,
'V21': -0.06,
'V22': -0.088,
'V23': -0.03,
'V24': 0.01,
'V25': -0.04,
'V26': -0.99,
'V27': -0.13,
'V28': 0.003
}
response = endpoint.predict([test_instance])
print('API response: ', response)Tabular 데이터로 생각해보면 위의 JSON은 Row 1개입니다.
그 다음에
Row 1개의 데이터를 test_instance 변수에 담고
모델이 배포된 엔드포인트에 API로 던져서 결과를 받아봅시다.

Score가 매우 높습니다.
축하합니다!
이제 나의 돈 또는 크레딧을 지키기 위해 엔드포인트와 Jupyter Notebook을 삭제합시다!
프로덕션 환경이라면 그대로 유지하시면 됩니다 ㅋㅋ
다음에는 직접 개발한 ML Code로 파이프라인을 만들어보도록 하겠습니다.
고생 많으셨습니다! 🥳
참고문서
