-
단어 임베딩 : 단어를 낮은 차원의 벡터로 나타내는 것
- 원핫 인코딩은 sparse, 용량 많이 차지, 단어 의미 고려 안함
- 단어의 의미를 좌표로 나타내는 것 또는 수치화 → 의미가 비슷한 단어들은 비슷한 값을 가짐
- 단어 임베딩의 다차원 공간상에서 방향에 의미가 있어야 함
-
단어 임베딩 만드는 방법
- (데이터가 적을때) NMF : 문서단어행렬에서 토픽모델링 (문서,토픽), (토픽, 단어) ..
- (데이터 중간) GloVe: 두 단어가 함께 나타난 관계를 이용
- (데이터 많음) Word2Vec: 신경망 언어 모형을 이용
-
Word2Vec
- 두 단어의 임베딩을 신경망에 입력했을 때, 두 단어가 가까이 나올 확률을 계산하는 신경망을 만들어 학습
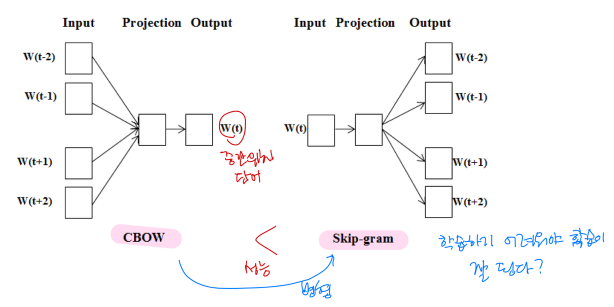
- 두 단어의 임베딩을 신경망에 입력했을 때, 두 단어가 가까이 나올 확률을 계산하는 신경망을 만들어 학습
-
FastText
-
Word2Vec은 등록된 어휘의 임베딩만 만들 수 있음
-
FastTest는 새로운 어휘의 임베딩도 만들 수 있게 한 방법
-
한 단어를 n-gram으로 분해
(예) Orange → or, ora, ran, ang, nge, ge_
-
각 n-gram의 임베딩을 더하면 단어의 임베딩이 되도록 학습
import re def find_hangul(text): return re.findall(r'[ㄱ-ㅎ가-힣]+', text) data = nsmc['document'].map(find_hangul) from gensim.models.fasttext import FastText ft = FastText(vector_size=16) # 단어 하나당 16개 vector를 활용해서 표현 # 어휘를 파악 ft.build_vocab(corpus_iterable=data) # 학습 ft.train( corpus_iterable=data, epochs=5, total_examples=ft.corpus_count, total_words=ft.corpus_total_words ) # 임베딩 보기 ft.wv['히어로'] # 16개.. ft.wv.similarity('슈퍼히어로', '히어로') ft.wv.most_similar('송강호')
-
-
문서 임베딩
- 문서를 이루는 단어의 임베딩의 평균
- 토픽 모델링
- 인접한 모형을 예측하는 모형을 사용
-
FastTest를 이용한 감성 분석
import numpy as np x = np.zeros((1000, 16)) #1000개만 doc = nsmc['document'].iloc[:1000] y = nsmc['label'].values[:1000] for i, d in enumerate(doc): vs = [ft.wv[word] for word in find_hangul(d)] if vs: x[i,] = np.mean(vs, axis=0) # 모든 단어들의 임베딩을 평균 낸 것 # 분할 from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test, idx_train, idx_test = train_test_split( x, y, doc.index, test_size=0.2, random_state=42) from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(x_train, y_train) model.score(x_test, y_test) -
코사인 유사도(단어 임베딩에 주로 쓰는 유사도)
*|a||b| : 값 크기 보정
-
임베딩을 이용한 검색: 느리다
import numpy as np from sklearn.metrics.pairwise import cosine_distances, cosine_similarity %%time i = 1 d = cosine_distances([x_test[i]], x_train) ids = np.argsort(d)[0, :3] # ms는 굉장히 긴 시간임 dist = np.sort(d)[0, :3] for j, d in zip(ids, dist): idx = idx_train[j] print(f'{d:.02f}', idx, nsmc.loc[idx, 'document'], nsmc.loc[idx, 'label']) -
ANN(Aproximate Nearest Neighbor Search)
- 문서를 검색할 때, 1:1로 비교할 경우 → 문서 수에 비례하여 검색 시간 증가
- ANN : 정확도를 감소시키는 대신, 검색 속도를 높임
- nmslib
-
트리를 이용한 문서 검색
- 공간을 무작위로 분할 → 트리로 만듦
- 문서를 찾을 때 트리의 같은 말단에 있는 문서를 비슷한 문서로 판정
- 여러 트리의 결과를 합쳐서 비슷한 문서들을 찾음
- 문제 : 해리포터 - 어린이? 영국문학?
-
해서(hasher)를 이용한 문서 검색
- 해시 함수: 데이터를 임의의 크기로 고정되 값으로 매핑하는 함수(예: 나머지)
- 아무리 길어도 100으로 나눈 나머지는 2자리 이하
- Locally Sensitive Hashing: 비슷한 데이터를 쉽게 찾기 위한 해싱 방법
- 비슷한 데이터는 비슷한 해시값을 갖도록 하는 방법을 여러번 적용
- 해시 함수: 데이터를 임의의 크기로 고정되 값으로 매핑하는 함수(예: 나머지)
-
위계적 탐색 가능한 작은 세상 네트워크(Hierarchical Navigable Small World network)
- 작은 세상 네트워크 : 주로 가까운 점과 연결되어 있지만, 멀리 떨어진 점들과도 일정 비율 연결된 상태
- 서울 → 부산: 기차로 지역단위로 멀리 이동→ 택시 or 전철을 타고 역으로 이동 → 걸어서 목적지 도착..
.jpg)
ML/DL swimmer