
LDA와 같은 주제분석을 할 때 평가를 위한 지표로 Perplexity, 주제 응집도, 주제 다양도 등이 있다. (관련 내용에 대한 이전 블로그 글)
주제 응집도는 주제를 구성하는 단어들이 서로 연관된 정도를 측정하는 것이 목적이다. 즉, 한 주제에 대해서 단어들이 얼마나 관계가 있느냐를 보는 것이다. 주제 다양도는 주제들끼리 얼마나 관련이 없는지를 측정한다. 여러개의 주제가 있다면 서로 다른 주제여야 주제 분석의 의미가 있다.
주제 다양도는 학계에 널리 알려진 지표는 아직 없지만 Dieng,Ruiz,&Blei(2019)가 논문에서 제안한 측정 방법이 있다.
주제별 상위 25개에 포함되는 중복 제외 단어 수 / (주제 수 x 25)
예를 들어, 주제가 5개가 있다고 했을 때, 각 주제별로 상위 단어 25개씩 뽑는다면 총 125개의 단어가 나온다. 여기서 극단적으로 주제별 상위 25개의 단어가 모두 다르다면 겹치는 단어가 없으므로 주제 다양도는 1이 된다(125/(5x25)). 반대로 주제별 상위 25개의 단어가 모두 같다면 겹치는 단어를 모두 제외하고 계산하면 주제 다양도는 0이 된다(0/(5x25)). 즉, 0에 가까울 수록 모든 주제의 상위 단어가 같고, 1에 가까울수록 다르다. 주제 다양도가 1에 가까울 수록 주제 다양성이 높다고 볼 수 있다.
- 주제 다양도 실습
import numpy as np
import pandas as pd
pd.set_option('max_row', 200)
# 문서의 제목과 내용을 합친다.
# 제목의 단어는 가중치가 높다고 판단해 2번 반복해서 내용과 합친다.
doc = doc[['post_id', 'title', 'text']]
doc['all_text'] = (doc['title']+' ')*2 + doc['text']
doc['all_text'] = doc['all_text'].str.replace('\n', '')
# 토크나이저 불러오기
from sklearn.feature_extraction.text import CountVectorizer
from kiwipiepy import Kiwi
kiwi = Kiwi()
kiwi.prepare()
# 토크나이저 함수
def extract_keywords(text):
result = kiwi.analyze(text)
for token, pos, _, _ in result[0][0]:
if (pos[0] in 'N') & (len(token)>1): # 명사만 추출, 한 글자는 제외
yield token
# 단어 빈도 추출 모델
cv = CountVectorizer(ngram_range=(1,1), tokenizer=extract_keywords)
# 주제 다양도 추출 함수
def get_topic_diversity(df):
df_sum_top = pd.DataFrame()
for i in range(len(df)):
tdm = cv.fit_transform([df['all_text'][i]])
word_count = pd.DataFrame({
'단어': cv.get_feature_names(),
'빈도': tdm.sum(axis=0).flat
})
top20 = word_count.sort_values('빈도', ascending=False).head(10) # 빈도 상위 10개 단어씩 추출
df_sum_top = pd.concat([df_sum_top,top20])
topic_diversity =len(df_sum_top.drop_duplicates(subset=['단어'], keep=False))/len(df_sum_top)
return len(df_sum_top), topic_diversity
# 유저id별 주제 다양도 계산
# 유저별로 얼마나 다른 주제의 글을 읽었는지 확인을 위함
user_id_list =list(df.drop_duplicates(subset=['user_id'], keep='first')['user_id'].values)
topic_div = []
for i in range(len(user_id_list)):
cr = df['user_id']==user_id_list[i]
df1 = df[cr].reset_index(drop=True)
topic_div.append(get_topic_diversity(df1))
df_topic_div = pd.DataFrame(topic_div)
df_topic_div['user_id']=user_id_list
df_topic_div.columns = ['단어 총 합', '주제 다양도', 'user_id']
df_topic_div.iloc[:200]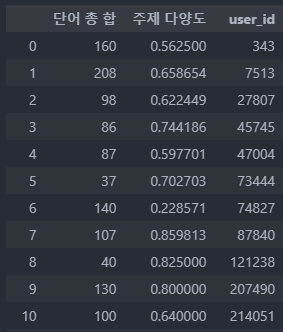
.jpg)
ML/DL swimmer