5. Using the C String Library
어떤 프로그래밍 언어는 문자열 복사, 문자열 비교, 문자열 잇기, 자를 문자열 선택 등의 연산자를 제공한다. 하지만 C언어의 연산자는 본질적으로 문자열 작업에 쓸모가 없다. 문자열은 C에서 배열처럼 다루어지는데, 그래서 문자열은 배열과 같은 방식으로 제한된다. 특히 연산자를 사용하여 복사되거나 비교될 수 없다.
문자열을 직접적으로 복사하거나 비교하려는 시도는 실패할 것이다. 예를 들어 아래의 str과 str2가 선언되었다고 생각해보자.
char str1[10], str2[10];= 연산자를 사용하여 문자 배열에 문자열을 복사하는 것은 불가능하다.
str1 = "abc"; /*** WRONG ***/
str2 = str1; /*** WRONG ***/배열의 이름을 = 연산자의 왼쪽 피연선자로 사용하는 것은 규칙에 어긋난다는 것을 Section 12.3에서 보았다. 하지만 문자 배열을 = 연산자를 사용해 초기화 하는 것은 규칙에 어긋나지 않는다.
char str1[10] = "abc";이 선언의 맥락에서는, =는 대입 연산자가 아니다.
문자열을 비교할 때 관계 연산자나 동등 연산자를 사용하려고 시도하는 것은 규칙에 맞긴 하지만 요구하는 결과를 내지는 못한다.
if (str1 == str2) ... /*** WRONG ***/이 구문은 str1과 str2를 포인터로써 비교한다. 이 구문은 두개의 배열의 내용물을 비교하지 않는다. str1과 str2가 다른 주소를 가지고 있기 때문에, str1 == str2는 반드시 0의 값을 가진다.
다행히도, 방법이 없는 것은 아니다. C 라이브러리는 문자에 대한 연산을 수행하는 풍부한 함수의 집합을 제공한다. 이 함수들에 대한 prototype은 <string.h>헤더에 있어서, 문자열 연산을 필요로 하는 프로그램은 아래의 행을 포함해야 한다.
#include <string.h><string.h>안에 선언된 대부분의 함수는 argument로써 최소한 하나의 문자열을 필요로 한다. 문자열 parameter들은 argument로써 문자 배열이나, char * 자료형의 변수나, 문자열 리터럴과 같은 char *의 자료형을 가지도록 선언해야 한다. 그러나 const가 선언되지 않은 문자열 parameter에 대해서는 조심해야 한다. 이러한 parameter는 함수가 호출되었을 때 수정될 수 있고, 그래서 대응되는 argumnet는 문자열 리터럴이면 안된다.
<string.h>에는 많은 함수가 있다. 가장 기본적인 몇가지만 알아보겠다.
아래에 이어지는 예시는 str1과 str2가 문자열로써 사용되는 문자 배열이라고 가정할 것이다.
The strcpy(String Copy) Function
strcpy 함수는 <string.h> 안에서 아래의 prototype을 가진다.
char *strcpy(char *s1, const char *s2);strcpy는 문자열 s2를 문자열 s1로 복사한다.(더 정확하게는, "strcpy가 s2가 가리키는 문자열을 s1이 가리키는 배열에 복사하는 것이다.") 즉, strcpy는 s2로부터 문자들을 복사해 s2 안의 첫번째 null 문자까지 s1에 복사한다. strcpy는 s1(목표 문자열을 가리키는 포인터)을 반환한다. s2가 가리키는 문자열은 수정되지 않으며, 그래서 const로 선언되었다.
strcpy의 존재는 우리가 문자열을 복사하는 것에 대입 연산자를 사용할 수 없다는 사실을 의미한다. 예를 들어 문자열 "abcd"를 str2에 복사하고 싶다고 가정해보자.
str2 = "abcd"; /*** WRONG ***/우리는 이 대입을 사용할 수 없는데, str2가 배열의 이름이고, 대입의 왼쪽 부분에 나타날 수 없기 때문이다. 그래서 대신 우리는 strcpy를 호출해야 한다.
strcpy(str2, "abcd"); /* str2 now contains "abcd" */간단하게 말하면, str2를 str1에 직접적으로 대입하지는 못하지만, strcpy를 호출할 수는 있다.
strcpy(str1, str2); /* str1 now contains "abcd" */우리는 대부분 strcpy가 반환하는 값을 폐기할 것이다. 그러나 때때로 strcpy의 반환값을 사용하기 위한 큰 표현식의 일부로써 strcpy를 유용하게 사용할 수 있다. 예를 들어 strcpy들을 연속적으로 이을 수 있다.
strcpy(str1, strcpy(str2, "abcd"));
/* both str1 and str2 now contain "abcd" */strcpy(str1, str2)의 호출 안에서, str2가 가리키는 포인터가 str1이 가리키는 포인터에 적합한지 strcpy가 실제로 확인할 수 있는 방법이 없다. str1이 길이 n의 배열을 가리킨다고 가정해보자. 만약 str2가 가리키는 문자열이 n - 1문자보다 더 짧다면 복사는 성공적일 것이다. 그러나 str2가 더 긴 문자열을 가지고 있다면 undefined behavior가 발생한다. (strcpy는 첫번째 null 문자를 항상 복사하기 때문에, str1이 가리키는 끝의 배열을 지나서 복사할 것이다.)
더 느리더라도 문자열을 복사하는 방법으로는 strncpy가 더 안전하다. strncpy는 strcpy와 비슷하지만 세번째 argument가 복사될 문자의 개수에 제한을 둔다. str2를 str1에 복사하기 위해, 우리는 strncpy를 아래와 같이 호출할 수 있다.
strncpy(str1, str2, sizeof(str1));str2에 저장된 문자열을 str1이 가지고 있을 수 있을 만큼 충분히 넓다면(null 문자 포함해서), 복사는 올바르게 완료될 것이다. 그러나 strncpy 자체가 위험하지 않은 것은 아니다. 한 가지 예로 들면, str2에 저장된 문자열의 크기가 str1 배열보다 크거나 같다면 str1은 null 문자가 없는 채로 남겨질 것이다. 아래는 strncpy를 안전하게 사용하는 방법이다.
strncpy(str1, str2, sizeof(str1) - 1);
str1[sizeof(str1)-1] = '\0';두번째 구문은 strncpy가 str2로부터 null 분자를 복사하는 것에 실패해도 str1이 언제나 null로 끝난다는 것을 보장한다.
The strlen(String Length) Fucntion
strlen 함수는 아래의 prototype을 따른다.
size_t strlen(const char *s);C 라이브러리 내부에 정의된 size_t는 C언어의 unsigned integer type으로 표현되는 typedef 이름이다. 엄청나게 긴 문자열을 사용하는 것이 아니라면, 이는 기술적으로 우려될 일은 없다. 우리는 정수로써 strlen의 반환 값을 다룰 것이다.
strlen은 문자열 s의 길이를 반환한다. s에 있는 문자들의 갯수지만, 첫번째 null 문자까지는 포함하지 않는다. 아래에 여러 개의 예시가 있다.
int len;
len = strlen("abc"); /* len is now 3 */
len = strlen(""); /* len is now 0 */
strcpy(str1, "abc");
len = strlen(str1); /* len is now 3 */마지막 예제는 아주 중요한 점이다. strlen의 argument로써 배열이 주어졌을 때, strlen은 배열 자체의 길이를 측정하지 않고, 대신에 배열 안에 저장된 문자열의 길이를 반환한다.
The strcat(String Concatenation) Function
strcat 함수는 아래의 prototype을 가진다.
char *strcat(char *s1, const char *s2);strcat는 문자열 s1의 끝부분에 문자열 s2의 내용물을 붙인다. strcat는 s1(결과 문자열을 가리키는 포인터)을 반환한다.
strcat가 동작하는 몇 개의 예제가 아래에 있다.
strcpy(str1, "abc");
strcat(str1, "def"); /* str1 now contains "abcdef" */
strcpy(str1, "abc");
strcpy(str2, "def");
strcat(str1, str2); /* str1 now contains "abcdef" */strcpy처럼, strcat에 의해 반환되는 값은 일반적으로 폐기된다. 아래의 예제는 어떻게 반환된 값이 사용되는지 보여준다.
strcpy(str1, "abc");
strcpy(str2, "def");
strcat(str1, strcat(str2, "ghi"));
/* str1 now contains "abcdefghi"; str2 contains "defghi" */strcat(str1, str2) 호출의 효과는 만약 str1이 가리키는 배열이 str2의 추가적인 문자를 수용할 수 없을 정도로 길지 못하다면 이는 undefined이다. 아래의 예시를 보자.
char str1[6] = "abc";
strcat(str1, "def"); /*** WRONG ***/strcat는 문자 d, e, f, \0을 str1에 이미 저장된 문자열의 끝부분에 추가하려고 시도할 것이다. 불행하게도, str1은 6개의 문자로 제한되어 있고 이는 strcat가 배열의 끝부분을 넘어서 쓰도록(write)할 것이다.
strcat의 느린 버전이지만 strncat 함수가 더 안전하다. strncpy와 비슷하게, strncat는 복사할 문자들의 개수를 제한하는 3번째 argument를 가지고 있다.
아래의 예시를 보자.
strncat(str1, str2, sizeof(str1) - strlen(str1) - 1);strncat는 str1이 null 문자로 끝나도록 하는데, null 문자는 3번째 argument(복사된 문자의 개수)에는 포함되지 않는다. 이 예제에서, 3번째 argument는 str1안의 남은 공간의 총량을 계산한다(sizeof(str1) - strlen(str1)의 표현식). 그리고 null 문자가 들어갈 공간을 확보하기 위해서 1을 뺀다.
The strcmp(String Comparison) Function
strcmp 함수는 아래의 prototype을 가진다.
int strcmp(const char *s1, const char *s2);strcmp는 문자열 s1과 s2를 비교하는데, s1이 s2보다 작은지, 같은지, 큰지에 따라 0보다 작거나, 같거나, 큰 값을 반환한다. 예를 들어 str1이 str2보다 작은지 확인하려면 아래처럼 작성할 수 있다.
if (strcmp(str1, str2) < 0) /* is str1 < str2? */
...str1이 str2보다 작거나 같은지 확인하기 위해서는 아래처럼 작성할 수 있다.
if (strcmp(str1, str2) <= 0) /* is str1 <= str2? */
...적절한 관계 연산자(<, <=, >, >=)나 동등 연산자(==, !=)를 선택하는 것으로, 우리는 str1과 str2 사이에 가능한 어떠한 관계성이라도 검사할 수 있다.
strcmp는 사전(dictionary)에 단어들이 정렬된 방식과 비슷하게, 사전식 순서에 따라 문자열을 비교한다. 더 정확하게는, strcmp는 아래의 조건 중 하나라도 충족되면 s1이 s2보다 작다고 판단한다.
s1과s2의 첫i문자가 같고,s1의(i+1)번째 문자가s2의(i+1)번째 문자보다 작음. 예를 들어"abc"는"bcd"보다 작고,"abd"는"abe"보다 작음.s1과s2의 모든 문자들이 같지만,s1이s2보다 작음. 예를 들면"abc"는"abcd"보다 작음.
두 개의 문자열로부터 문자들을 비교하는 것처럼, strcmp는 문자들을 표현하는 숫자 코드를 확인한다. 문자 집합에 내제된 지식을 이해하는 것은 strcmp가 무엇을 하는지 예측하기 위해 도움이 된다. 예를 들어 ASCII 문자 집합의 중요한 특성이 아래에 있다.
- 문자들은 각각 A-Z, a-z, 0-9의 연속적인 문자를 가진다.
- 모든 대문자들은 모든 소문자보다 작다. (ASCII에서는, 65에서 90사이의 코드가 대문자를 표현하고, 97에서 1222사이의 코드가 소문자를 표현한다)
- 숫자는 영어문자(letter)보다 작다. (48에서 57사이의 코드가 숫자들을 표현한다)
- 공백은 모든 출력 문자들보다 작다.(공백(space) 문자는 ASCII에서 32의 값을 가진다)
6. String Idioms
문자열을 조장하는 함수는 특히 관용구(Idiom: 많이사용되는 것)로 많이 사용된다. 이 Section에서는 strlen과 strcat 함수를 사용한 가장 유명한 관용구들을 알아볼 것이다. 당연히, 이 함수들은 표준 라이브러리의 일부이기 때문에 이 함수들을 작성할 필요는 없지만, 비스한 함수를 작성할 수는 있어야 한다.
이 Section에서 사용할 간결한 스타일은 많은 C 프로그래머 사이에서 유명하다. 이것들을 자신만의 프로그램을 만들 때에 반드시 사용할 필요는 없지만, 다른 사람이 작성한 코드에서 이것들을 마주칠 수 있기 때문에 이것을 마스터해야한다.
Section 21.1에서도 설명하겠지만, 함수가 포함되어 있는 헤더를 포함하지 않더라도 표준 라이브러리 함수와 같은 이름의 함수를 작성하는 것은 허용되지 않는다. 소문자 str로 시작하는 모든 이름은 예약되어있다.(미래의 C 표준 version에 있는 <string.h>에 추가될 수 있는)
Searching for the End of a String
대부분 문자열의 작동에서 문자열의 끝부분을 검사하는 것이 필요하다. strlen함수는 주로 사용되는 예시이다. 아래의 strlen은 문자열의 길이를 추적하는 변수를 사용하여 문자열 argument의 끝을 찾는다.
size_t strlen(const char *s)
{
size_t n;
for (n = 0; *s != '\0'; s++)
n++;
return n;
}포인터 s가 문자열을 가로질러 왼쪽에서 오른쪽으로 이동하는데, 변수 n은 지나가면서 얼마나 많은 문자들이 있는지 추적한다. 마지막에 s가 null 문자를 가리킬 때, n은 문자열의 길이를 포함하게 된다.
위의 strlen 함수를 더 압축할 수 있는지 확인해보자. 첫번째, 우리는 n의 초기화를 선언부로 옮길 수 있다.
size_t strlen(const char *s)
{
size_t n = 0;
for (; *s != '\0'; s++)
n++;
return n;
}다음으로, *s != '\0' 조건은 *s != 0과 동일하다는 점이다. null 문자의 정수값이 0이기 때문이다. 그러나 *s != 0 조건은 *s를 검사하는 것과 동일하다. *s의 값이 0이 아니라면 참(true)이기 때문이다. 지금까지 관찰한 것들을 통해 strlen을 수정하면 아래와 같다.
size_t srtlen(const char *s)
{
size_t n = 0;
for(; *s; s++)
n++;
return n;
}우리가 Section 12.2에서 보았듯, s를 증가시는 것과 *s를 검사하는 것은 하나의 표현식으로 가능하다.
size_t strlen(const char *s)
{
size_t n = 0;
for (; *s++;)
n++;
return n;
}for구문을 while 구문으로 대체하는 것으로, strlen을 더 압축할 수 있다.
size_t strlen(const char *s)
{
size_t n = 0;
while (*s++)
n++;
return n;
}비록 우리가 strlen을 조금 더 압축시켰지만, 속도를 증가시키지는 못한다. 아래의 strlen은 어떤 컴파일러에서는 조금 더 빠르게 작동한다.
size_t strlen(const char *s)
{
const char *p = s;
while (*s)
s++;
return s - p;
}위의 strlen은 null 문자의 위치에 따라 문자열의 길이를 계산하고, 그 후 문자열 안에서 첫번째 문자의 위치를 뺀다. 중가하는 n을 while 루프문에서 제거한 것으로 속도가 증가한다. p의 선언에서 const가 등장한 것을 주목해보자. 만약 const가 없다면, 컴파일러는 p에 s를 대입한다면 s가 가리키는 문자열이 위험에 처할수있다는 것을 알게될 것이다.
while (*s)
s++;
while (*s++)
;아래와 위의 구문은 "문자열의 끝에 있는 null 문자를 검사한다"라는 의미를 가지고 있어서 서로 관련이 있다. 전자의 version은 s가 null문자를 가리킨채로 남기지만, 후자의 version은 s가 null문자를 지나 다음을 가리킨채로 남긴다.
Copying a String
문자열 복사는 또다른 일반적인 작동이다. C언어의 "문자열 복사" 관용구를 도입하기 위해, 우리는 두 개의 version의 strcat 함수를 개발해야한다.
char *strcat(char *s1, const char *2)
{
char *p = s1;
while (*p != '\0')
p++;
while (*s2 != '\0')
{
*p = *s2;
p++;
s2++;
}
*p = '\0';
return s1;
}이 version의 strcat은 두 단계의 알고리즘을 사용한다. (1) 문자열 s1의 끝에 있는 null 문자을 탐색하고, p 가 그것을 가리키게 한다. (2) p가 가리키고 있는 곳에 s2의 문자를 하나씩 복사한다.
첫번째 while 구문은 단계 (1)을 구현한 것이다. p는 문자열 s1의 첫번째 문자를 가리키도록 설정되었다. s1이 문자열 "abc"를 가리킨다고 생각해보자. 우리는 아래와 같은 장면을 생각해볼 수 있다.
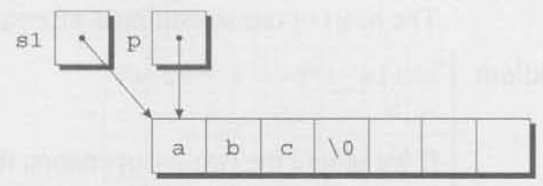
p가 null 문자를 가리키지 않는한 p는 계속 증가한ㄷ. 루프가 종료될 때, p는 반드시 null 문자를 가리켜야 한다.
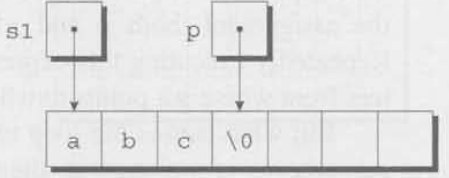
두번째 while 구문은 단계 (2)를 구현한 것이다. 루프의 body는 s2가 가리키는 곳으로부터 p가 가리키는 곳으로 문자를 하나 복사하도록 하고, p와 s2를 증가시킨다. s2는 원래 문자열 "def"를 가리킨다. 첫번째 루프 반복 후 문자열의 모습을 아래에 표현했다.
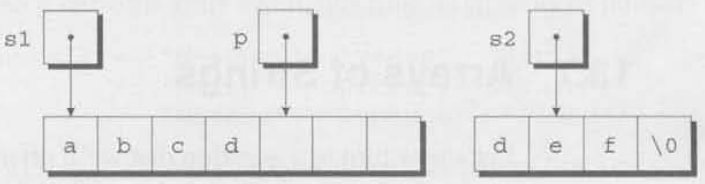
루프는 s2가 null 문자를 가리킬 때 종료된다.
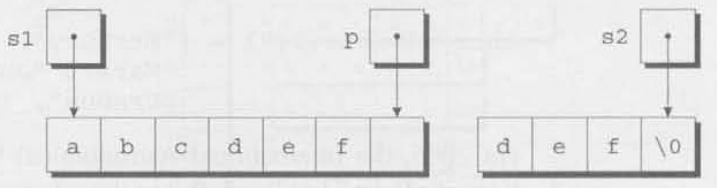
p가 가리키는 곳에 null 문자를 넣은 후, strcat가 반환된다.
strlen에 사용했던 것과 비슷한 과정을 거치는 것으로, 우리는 strcat의 정의를 압축시킬 수 있다. 아래의 version을 보자.
char *strcat(char *s1, const char *s2)
{
char *p = s1;
while (*p)
p++;
while (*p++ = *s2++)
;
return s1;
}간소화된 strcat 함수의 중심(heart)은 "문자열 복사" 관용구이다.
while (*p++ = *s2++)
;우리가 두 개의 ++ 연산자들을 무시한다면, 괄호안의 표현식은 일반적인 대입문으로 간단해질 것이다.
*p = *s2;이 표현식은 s2가 가리키는 곳으로부터 p가 가리키는 곳으로 문자 하나를 복사한다. 이 대입이 끝난 후, ++ 연산자 덕분에 p와 s2는 둘다 증가할 것이다.
이 표현식의 반복적인 실행은 s2가 가리키는 곳으로부터 p가 가리키는 곳으로 일련의 문자들을 복사하는 효과를 가진다.
근데 어떻게 루프가 종료되는 것일까? 괄호 내부의 중심인 표현식이 대입이기 때문에, while 구문은 대입의 값을 검사한다. 즉 복사된 문자를 검사한다. null 문자를 제외한 모든 문자들은 참(true)으로 검사되고, 그래서 null 문자까지 루프가 끝나지 않고 복사될 것이다. 그리고 대입 이후에 루프가 종료하기 때문에, 우리는 새로운 문자열의 끝에 null 문자를 집어넣는 분리된 구문을 필요로 하지 않는다.
7. Arrays of Strings
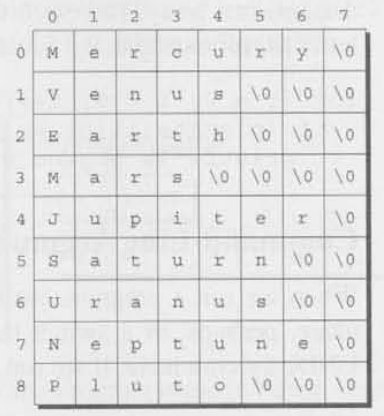
우리가 주로 마주하는 문제들에 대해서 생각해보자. 문자열의 배열을 저장하는 가장 좋은 방법은 무엇일까? 명백한 해결책은 two-dimensional 문자 배열을 만들고, 그 후 하나의 row마다 문자열을 저장하는 것이다. 아래의 예시를 생각해보자.
char planets[][8] = {"Mercury", "Venus", "Earth",
"Mars", "Jupiter", "Saturn",
"Uranus", "Neptune", "Pluto"};initializer안에서 요소의 개수가 명백하기 때문에 planets 배열 안에서 row의 개수를 생략하는 것이 허용되었다는 것을 주목해야 한다. 그러나 C언어는 column의 개수를 명시하는 것을 필요로 한다.
배열의 row를 채울만큼 문자열이 충분하지 않다면, C언어는 남은 공간을 null 문자로 채운다. 이 배열에서는 낭비되는 공간이 조금 있는데, 3개의 planet만 null 문자를 포함해 8글자 만큼의 충분한 공간을 가지기 때문이다. 낭비되는 공간의 총량은 많다.
이 예제에서 발견되는 비효율성은 문자열이 작동할 때 일반적인데, 대부분의 문자열의 모음이 짧은 문자열과 긴 문자열의 혼합으로 이루어져 있기 때문이다. 우리가 필요한 것은 비정형 배열(ragged array)이다. 이 비정형 배열은 row가 다른 길이를 가질 수 있는 two-dimensional array를 말한다. C언어는 "비정형 배열 자료형"을 제공하지 않지만, 이를 흉내낸 도구를 제공한다. 비밀은 문자열을 가리키는 포인터를 요소로 가진 배열을 만드는 것이다.
이번에는 아래의 planets가 문자열을 가리키는 포인터의 배열이다.
char *planets[] = {"Mercury", "Venus", "Earth",
"Mars", "Jupiter", "Saturn",
"Uranus", "Neptune", "Pluto"};별로 변하지 않은 것같지만, 우리는 한쌍의 대괄호를 지우고 planets앞에 별표(*)를 붙였다. 그러나 planets이 어떻게 저장되는지에 대한 효과는 드라마틱하다.
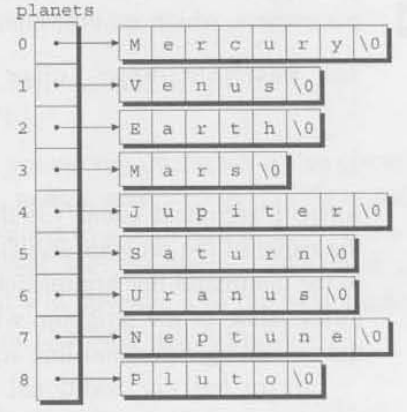
planets의 각각의 요소는 null로 끝나는 문자열을 가리키는 포인터이다. 비록 planets 배열 안에 포인터를 위한 공간을 할당해야 하지만, 문자열 안에서의 낭비되는 문자는 더이상 없다.
planet 이름 중 하나에 접근하기 위해서는, 우리가 필요한 것은 planets 배열에 subscript하는 것이다. 포인터와 배열 사이의 관계성 때문에, planet 이름 안의 문자에 접근하는 것은 two-dimensional array의 요소에 접근하는 방법과 동일하다. planets 배열에 있는 문자열 중 문자 M으로 시작되는 문자열을 검색하기 위해서는 아래의 루프를 사용할 수 있다.
for (i = 0; i < 9; i++)
if (planets[i][0] == 'M')
printf("%s begins with M\n", planets[i]);Command-Line Arguments
우리가 프로그램을 실행할 때, 우리는 정보를 제공해야 할 필요가 있을 때가 있다. 파일 이름이나 프로그램의 행동을 수정할만한 스위치와 같은 것들이다. UNIX의 ls 커맨드를 생각해보자. 우리가 ls를 실행시키기 위해 커맨드라인(Command-Line)에 아래와 같이 타이핑할 것이다.
ls이 명령어는 현재 디렉토리에 있는 파일의 이름을 출력할 것이다.
ls -l대신에 위처럼 타이핑한다면, ls는 "긴"(detailed) 파일의 목록을 출력할 것인데 각 파일의 크기, 파일의 소유자, 파일이 마지막에 수정된 날짜, 등등이 보여진다. 이 이상으로 ls의 동작을 수정하고 싶다면, 우리는 단지 하나의 파일의 세부사항을 표시하기 위해 명시할 수도 있다.
ls -l remind.cls는 remind.c의 이름을 가진 파일에 대한 세부 정보를 출력할 것이다.
Command-line information은 운영체제 커맨드 뿐만 아니라 모든 프로그램에 이용가능하다. command-line arguments(C표준에서는 program parameter)에 대한 접근을 위해서는, 우리는 반드시 main 함수에 관습적으로 argc와 argv의 이름의 두 개의 parameter를 정의해야 한다.
int main(int argc, char *argv[])
{
...
}argc("argument count")는 command-line argument의 개수이다(프로그램의 이름을 포함하여). argv("argument vector")"는 문자열 형태로 저장될 command-line arguments를 가리키는 포인터의 배열이다. argv[0]은 프로그램의 이름을 가리키고, argv[1]에서 argv[argc-1]로 갈 수록 남은 command-line arguments를 가리킨다.
argv는 하나의 추가적인 요소인 argv[argc]를 가지는데, 이는 항상 아무것도 가리키지 않는 특별한 포인터인 null 포인터이다. 나중에 null 포인터에 대해 다룰 것이다. 지금은 null 포인터를 표현하는 매크로 NULL에 대해서만 알면 된다.
ls -l remind.c사용자가 위와 같은 command line을 입력한다면, argc는 3이 될 것이고, argv[0]은 프로그램의 이름을 포함하는 문자열을 가리키고, argv[1]은 문자열 "-l"을 가리킬 것이고, argv[2]는 "remind.c"를 가리킬 것이고, argv[3]은 null 포인터일 것이다.
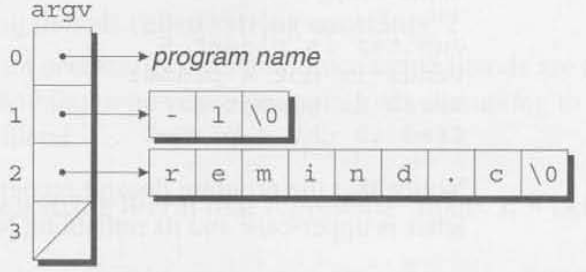
이 형태는 프로그램 이름을 세부적으로 보여주진 않는데, 왜냐하면 운영체제에 따라 경로(path)나 다른 정보를 포함할 수도 있기 때문이다. 프로그램 이름이 이용가능하지 않다면, argv[0]은 빈 문자열을 가리킨다.
argv가 포인터의 배열이기 때문에, command-line arguments에 접근하는 것은 간단하다. 전형적으로, command-line arguments를 요구하는 프로그램은 각각의 argmunet를 돌아가면서 검사하는 루프를 설정해놓았다. 이러한 루프를 작성하는 하나의 방법은 argv 배열을 index하는 정수형 변수를 사용하는 것이다. 예를 들어, 아래의 루프는 command-line arguments를 한 줄씩 출력하는 루프이다.
int i;
for (i = 1; i < argc; i++)
printf("%s\n", argv[i]);또다른 기술은 argv[1]을 가리키는 포인터를 설정하고, 그 후 포인터를 반복적으로 증가시키는 것으로 배열의 남은 부분을 단계적으로 통과하는 것이다. argv의 마지막 요소가 언제나 null 포인터이기 때문에, 루프는 배열 내부의 null 포인터를 찾았을 때 종료될 수 있다.
char **p;
for (p = &argv[1]; *p != NULL; p++)
printf("%s\n", *p);p가 문자를 가리키는 포인터를 가리키는 포인터이기 때문에, 주의를 기울여 사용해야 한다. p를 &argv[1]과 같게 하는 것은 이치에 맞다. argv[1]이 문자를 가리키는 포인터이기 때문에, &argv[1]은 포인터를 가리키는 포인터가 된다. *p != NULL의 검사는 옳은데, *p와 NULL은 둘다 포인터이기 때문이다. p를 증가시키는 것은 좋다. p가 배열 요소를 가리키기 때문에, p를 증가시키는 것은 다음 요소로 나아가게 할 것이다. *p를 출력하는 것은 좋은데, *p가 문자열의 첫번째 문자를 가리키기 때문이다.
planet.c example
input
planet Jupiter venus Earth fred
output
Jupiter is planet 5
venus is not a planet
Earth is planet 3
fred is not a planetCode
#include <stdio.h>
#include <string.h>
#define NUM_PLANETS 9
int main(int argc, char *argv[])
{
char *planets[] = {"Mercury", "Venus", "Earth",
"Mars", "Jupiter", "Saturn",
"Uranus", "Neptune", "Pluto"};
int i, j;
for (i = 1; i < argc; i++)
{
for (j = 0; j < NUM_PLANETS; j++)
if (strcmp(argv[i], planets[j] == 0)
{
printf("%s is planet %d\n", argv[i], j + 1);
break;
}
if (j == NUM_PLANETS)
printf("%s is not a planet\n", argv[i]);
}
return 0;
}Others
문자열 리터럴은 얼마나 길 수 있는가?
C89 표준에 따르면, 컴파일러는 최소 509글자 이상을 허용해야 한다. C99는 이를 증가시켜 최소 4095 문자를 허용해야 한다.
왜 문자열 리터럴은 "문자열 상수(string constants)"로 불리지 않는가?
왜냐하면 반드시 상수가 아니기 때문이다. 문자열 리터럴은 포인터를 통해 접근될 수 있기 때문에, 프로그램이 문자열 리터럴 내부의 문자들을 수정하는 시도를 방지하는 것이 없다.
"\xfcber"이 작동하지 않는다면, "über"을 표현하기 위해 어떻게 문자열 리터럴을 작성해야 하는가?
비법은 두 개의 인접한 문자열 리터럴을 작성하고, 컴파일러가 이를 하나로 합치게(join)하는 것이다. 이 예제에서는 "\xfc""ber"를 사용하는 것이 "über"를 표현하는 문자열 리터럴을 제공할 것이다.
문자열 리터럴을 수정하는 것은 충분히 해롭지 않은 것처럼 보인다. 왜 이것은 undefined behavior를 일으키는가?
어떤 컴파일러들은 메모리 필요량을 감소시키는 시도로 동일한 문자열 리터럴의 복사본을 저장한다. 아래의 예시를 보자.
char *p = "abc", *q = "abc";컴파일러는 "abc"를 하나 저장하고, p 와 q가 "abc"를 가리키도록 한다. 만약 우리가 포인터 p를 통해 "abc"를 수정한다면, q가 가리키는 문자열에도 영향을 줄 것이다. 말할 필요도 없이 이는 짜증나는 버그들을 일으킬 것이다. 또다른 잠재적인 문제는 문자열 리터럴은 메모리의 "read-only" 영역에 저장될 수 있따는 것이다. 프로그램이 이러한 리터럴을 수정하려고 시도한다면 간단하게 충돌이 일어날 것이다.
모든 문자의 배열은 null 문자를 포함할 공간을 확보해야 하는가?
필수적이지는 않은데, 왜냐하면 모든 문자 배열이 문자열로써 사용되지 않기 때문이다. null 문자열을 위한 공간을 포함하는 것은 null로 끝나는 문자열을 필요로 하는 함수에 이 배열을 전달할 계획이 있을 때만 필요하다.
만약 각각의 문자들에 대한 연산을 수행한다면 null 문자가 필요하지 않다. 예를 들어, 하나의 문자 집합을 또다른 문자 집합으로 번역하기 위해 문자 배열을 사용하는 프로그램이 있다고 생각해보자.
char translation_table[128];프로그램이 이 배열에 수행하는 연산은 오직 subscripting 뿐이다.(translation_talbe[ch]의 값은 문자 ch의 version으로 번역될 것이다) 우리는 translation_table이 문자열이 되도록 고려하지 않을 것이다. null 문자를 포함할 필요가 없고, 어떠한 문자열 연산도 수행되지 않을 것이다.
printf와 scanf가 첫번째 argument로써 char *자료형을 요구한다면, 이는 argument가 문자열 리터럴이 아닌 문자열 변수여도 된다는 것을 의미하는가?
맞다. 아래의 예시가 이를 보여준다.
char fmt[] = "%d\n";
int i;
...
printf(fmt, i);이 능력은 입력값으로써 서식 문자열을 읽는 것에 어떤 흥미로운 가능성에 문을 열어두었다.
printf가 문자열 str을 쓰도록 하고 싶은데, 아래의 예시처럼 str을 서식 문자열로써 전달할 수 있나?
printf(str);가능하지만, 리스크가 조금 있다. 만약 str이 %문자를 포함하고 있다면, 아마 요구했던 결과를 얻지 못할 것인데, printf가 이를 변환 명시자의 시작으로써 가정하기 때문이다.
read_line은 getchar가 문자를 읽는 것을 실패했는지 감지할 수 있나?
만약 getchar가 문자를 읽지 못했다면, 에러때문이거나 end-of-file 때문이기 때문에 getcahr는 int자료형인 EOF라는 값을 반환한다. 아래의 예시는 getchar의 반환값이 EOF인지 검사하는 read_line이다. 변화된 점은 && ch != EOF의 검사식이 붙은 것이다.
int read_line(char str[], int n)
{
int ch, i = 0;
while ((ch = getchar()) != '\n' && ch != EOF)
if (i < n)
str[i++] = ch;
str[i] = '\0';
return i;
}strcmp가 0보다 작거나, 같거나, 큰 숫자를 반환하는 이유가 무엇인가? 또, 실제의 반환값에는 어떠한 의미가 있는가?
strcmp의 반환값은 아마도 함수가 전통적으로 작성되는 방법으로부터 유래된 것이다. Kernighan and Ritchie's The C Programming Language 내부의 version을 생각해보자.
int strcmp(char *s, char *t)
{
int i;
for (i = 0; s[i] == t[i]; i++)
if (s[i] == '\0')
return 0;
return s[i] - t[i];
}s와 t 문자열 안에서 첫번째로 "불일치한" 문자들 사이의 차이가 반환값이다. 만약 s가 t보다 "작은" 문자열이라면 음수일 것이고, 만약 s가 더 "큰" 문자열이라면 양수일 것이다. strcmp가 실제로 이러한 방식으로 작성되었다는 보장은 없지만, strcmp의 반환값이 어떠한 특별한 의미를 가진다고 생각하지 않는 것이 좋다.
while 구문 내부의 strcat 함수를 컴파일하려고 시도할 때 컴파일러가 경고메시지를 발생시킨다. 무엇이 잘못된 것인가?
while (*p++ = *s2++)
;아무것도 잘못된 것이 없다. 많은 컴파일러가 일반적으로 ==가 사용될 곳에 =를 사용했을 때 경고 메시지를 발생시킨다. 이러한 오류는 시간의 최소 95%정도 유효하고, 여기에 주의를 기울이면 디버깅 시간을 절약할 수 있다. 불행하게도, 이 경고는 이 특별한 예제와 관련이 없다. 우리는 실제로 ==가 아닌 =를 의미하기 위해 사용하였다. 이 오류를 지우기 위해서는 while루프문을 아래와 같이 재작성하면 된다.
while ((*p++ = *s2++))
;strlen과 strcat 함수는 실제로 Section 13.6에서 보여진 방식대로 작성되었는가?
컴파일러 공급업체(vendor)가 일반적으로 C언어가 아닌 어셈블리 언어로 많은 문자열 함수들을 작성하는 것이 일반적이지만, 가능성은 있다. 문자열 함수는 가능한 빨라야할 필요가 있는데, 왜냐하면 이 함수들은 자주 사용되고, 자의적인(arbitrary) 길이의 문자열들을 다루어야하기 때문이다. 이러한 함수를 어셈블리 언어로 작성하는 것으로 CPU가 제공할 수 있는 특별한 문자열 조작 인스트럭션(instruction)을 이용하는 것을 통해 좋은 효율성을 달성하는 것이 가능하다.
왜 C 표준은 "command-line arguments" 대신에 "program parameter"라는 용어를 사용했는가?
프로그램은 언제나 command-line으로부터 실행되지는 않는다. 전형적인 그래픽 유저 인터페이스(GUI)를 예로 들면, 프로그램이 마우스 클릭으로 실행된다. 이러한 환경에서는 전통적인 커맨드 라인이 없고, 프로그램에게 정보를 전달할 수 있는 또다른 방법들이 존재한다. "program parameters"라는 용어는 이러한 대안들에 대한 가능성을 열어둔 것이다.
main의 parameter에 대해 argc와 argv를 반드시 사용해야 하는가?
아니다. argc와 argv는 단순히 관습이고, 언어적인 필요는 아니다.
argv가 *argv[] 대신에 `argv`로써 선언되는 것을 보았는데, 이는 규칙에 맞는가?
틀림없다. parameter를 선언할 때, *a를 작성하는 것은 a의 요소의 자료형에 상관없이 a[]를 작성할 때와 언제나 동일하다.
우리는 요소들이 문자열 리터럴을 가리키는 포인터로써 작동하는 배열을 설정하는 방법에 대해 알아보았다. 그러면 포인터의 배열을 또다른 곳에 적용할 곳이 있는가?
그렇다. 비록 우리가 문자열을 가리키는 포인터의 배열에 초점을 두었지만, 이것만이 포인터의 배열을 적용할 수 있는 방법은 아니다. 배열의 형태든 아니든, 어떤 데이터의 자료형이든 가리킬 수 있는 요소를 가진 배열을 쉽게 만들 수 있다. 포인터의 배열은 동적 공간 할당(dynamic storage allocation)과 함께 결합되면 특히 유용하다.
