이전의 Chapter들에서, #define과 #include 지시어(directive)에 대해 설명하지 않고 계속 사용하고 있었다. 이 지시어들은 전처리기(preprocessor)에 의해 조작된다. 전처리기는 컴파일 직전에 C프로그램을 편집하는 소프트웨어이다. 전처리기에 대한 의존은 C언어를 더욱 다른 프로그램 언어에 비해 구분되게 만들어주는 특징이다.
전처리기는 아주 강력한 도구이지만 동시에 버그를 찾기 어려운 원천이 되기도 한다. 그 이상으로 전처리기는 대부분 이해하기 불가능한 프로그램을 만드는 것에 쉽게 사용될 수 있다. 어떤 프로그래머들이 전처리기에 크게 의존하지만, 삶에서의 많은 것들과 똑같이 적당하게 사용하는 것을 추천한다.
1. How the Preprocessor Works
전처리 지시어(preprocessing directives)에 의해 전처리기의 행동이 제어된다. 이 지시어는 # 문자로 시작하는 커맨드(commands)이다. 지금까지 우리는 이 directives 주에 2개인 #define과 #include를 보았다.
#define directive는 macro를 정의한다. macro는 상수나 자주 사용되는 표현식과 같은 무엇인가를 표현하기 위한 이름이다. 전처리기는 macro의 이름을 정의와 함께 저장하는 것으로 #define 지시어에 응답한다(respond).
macro가 프로그램 안에서 나중에 사용될 때, 전처리기는 macro를 "확장"시켜 macro가 정의된 값으로 대체한다.
#include directive는 전처리기가 특정한 파일을 열도록 지시하고, 컴파일될 때 파일의 일부러써 열린 파일을 "포함(include)"하도록 한다.
#include <stdio.h>위의 행은, 전처리기가 stdio.h이라는 이름의 파일을 열고, 프로그램 내부로 stdio.h의 내용물을 가져오도록 지시한다.(stdio.h는 C언어의 표준 입력/출력 함수들을 포함한다.)
아래의 다이어그램은 컴파일 과정안에서의 전처리기의 역할을 보여준다.
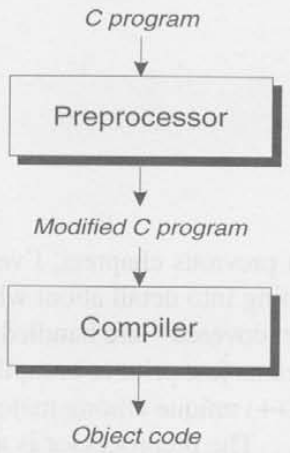
전처리기에 대한 입력값은 directives를 포함했을 수도 있는 C 프로그램이다. 전처리기는 이 directives를 실행하고, 그 과정에서 제거한다. 전처리기의 결과물은 또다른 C 프로그램이다. 원래의 프로그램의 수정된 version인데, 이는 directives를 포함하고 있지 않다. 전처리기의 결과는 컴파일러에게 직접적으로 보내지고, 컴파일러는 프로그램에 대한 에러를 체크하고 object code로 번역한다(machine instructions).
전처리기가 하는 것을 보기 위해서는, Section 2.6의 celsius.c에 적용시켜보자.
/* Converts a Fahrenheit temperature to Celsius */
#include <stdio.h>
#define FREEZING_PT 32.0f
#define SCALE_FACTOR (5.0f / 9.0f)
int main(void)
{
float fahrenheit, celsius;
printf("Enter Fahrenheit temperature: ");
scanf("%f", &fahrenheit);
celsius = (fahrenheit - FREEZING_PT) * SCALE_FACTOR;
printf("Celsius equivalent is: %.1f\n", celsius);
return 0;
}전처리과정 이후에, 프로그램은 아래와 같은 모습을 가질 것이다.
Blank line
Blank line
Lines brought in from stdio.h
Blank line
Blank line
Blank line
Blank line
int main(void)
{
float fahrenheit, celsius;
printf("Enter Fahrenheit temperature: ");
scanf("%f", &ffahrenheit);
celsius = (fahrenheit - 32.0f) * (5.0f / 9.0f);
printf("Celsius equivalent is: %.1f\n", celsius);
return 0;
}전처리기는 stdio.h의 내용물을 가져오는 것으로 #include directive에 대응한다. 전처리기는 또한 #define directives를 제거하고, 파일 안에 나중에 나타나는 FREEZING_PT와 SCALE_FACTOR를 대체시켰다. 전처리기는 directives가 포함된 행을 삭제하는 것이아니고, 대신에 빈공간으로 만든다는 것을 명심해야한다.
이 예제가 보여주는 것처럼, 전처리기는 directives를 단지 실행시키는 것보다 조금 더 행동한다. 특히, 전처리기는 각 주석을 모두 단일 공백(space) 문자들을 대체한다. 어떤 전처리기들은 더 나아가 들여쓰기 된 행의 시작부분에 있는 공백들과 탭들을 포함한 불필요한 공백문자들을 제거하기도 한다.
C언어의 초창기때에는, 전처리기는 컴파일러에게 전처리기의 결과를 전달하는 분리된 프로그램이었다. 지금은, 전처리기는 보통 컴파일러의 일부이고 전처리기의 결과가 반드시 C 코드일 필요가 없을 수도 있다(예를 들어, <stdio.h>와 같은 표준 헤더를 포함(including)하는 것은 반드시 헤더파일의 내용물을 복사하여 프로그램의 소스코드로 넣지 않아도 헤더파일의 함수를 프로그램에서 이용가능하게 하는 효과가 있었다). 여전히, 대부분의 C 컴파일러는 전처리기의 결과물을 바라보는 관점을 제공한다. 어떤 컴파일러들은 특정한 옵션이 명시되었을 때(GCC의 경우는 -E 옵션이 사용되었을 때) 전처리기의 결과물을 생성한다. 컴파일러에 대한 문서를 읽어보면 더 자세한 정보를 얻을 수 있다.
주의할 점은 전처리기가 C의 지식에만 한정되어있다는 점이다. 결과적으로, directive를 실행할 때 규칙에 어긋난 프로그램을 만들 수도 있다. 원래의 프로그램이 종종 문제가 없는 것처럼 보여서 에러를 찾기 힘들게 만든다. 복잡한 프로그램에서는, 전처리기의 결과물을 검사하는 것은 많은 에러를 찾는 것에 유용함이 입증되어있다.
2. Preprocessing Directives
대부분의 전처리 directives는 3개의 카테고리로 나누어진다.
- Macro definition
#deinfedirective는 macro를 정의한다.#undefdirective는 macro definition을 제거한다. - File inclusion
#includedirective는 명시된 파일의 내용물을 프로그램 안에 포함시킨다. - Conditional compilation
#if,#ifdef,#ifndef,#elif,#else,#endifdirectives는 전처리기에 의해 검사되는 조건에 의해 text의 block을 프로그램에 포함시키거나, 프로그램으로부터 제외한다.
남은 directive들인#error,#line,#pragma는 더 특별하고, 그래서 자주 사용되지 않는다. 우리는 이 장의 남은 부분에서 전처리 directive들에 대해 심도있게 알아볼 것이다. 우리가 세부적으로 알아보지 않을 것은#include인데, 이는 Section 15.2에서 더 알아볼 것이다.
우리가 더 진행하기 전에, 모든 directive에 적용되는 규칙들에 대해서 알아보자. - directives는 언제나
#심볼로 시작해야한다.#심볼은 공백만이 앞에 있는 한, 행의 시작부분에 올 필요는 없다.#이 directive의 이름 앞에 온 이후에, directive가 필요로 하는 또다른 정보가 이어서 온다. - 얼마나 많은 개수의 문자이든, 수직 탭 문자이든 directive를 분리하는 token이 될 수 있다. 예를 들어 아래의 directive도 규칙에 맞다.
# define N 100- directives는 명시적으로 이어지지 않는한, 첫번째 개행 문자에서 항상 끝나야한다. directive를 다음 행으로 이어서 쓰기 위해, 우리는 반드시 현재 행을
\문자로 끝내야 한다. 예를 들어 아래의 directive는 하드 디스크의 용량을 byte의 형태로 표현하는 macro를 정의한 것이다.
#define DISK_CAPACITY (SIDS * \
TRACKS_PER_SIDE * \
SECTORS_PER_TRACK * \
BYTES_PER_SECTOR)- directives는 프로그램의 어디든 등장할 수 있다. 비록 우리가 일반적으로
#define과#includedirective를 파일의 시작부분에 넣긴 하지만, 다른 directives는 나중에 나오는 경향성이 있는데 심지어는 함수 정의의 중간에 등장하기도 한다. - 주석은 directive와 같은 행에 등장해야 한다. 사실 macro의 의미를 설명하기 위해 macro 정의의 끝부분에 주석을 넣는 것은 좋은 습관이다.
#define FREEZING_PT 32.0f /* freezing point of water */3. Macro Definitions
우리가 Chapter 2부터 사용해온 매크로는 간단한(simple) macro로 알려져있는데, 왜냐하면 아무런 parameter를 가지지 않기 때문이다. 전처리기는 parameterized macro를 지원한다. 처음에는 simple macro를 먼저 본 후 그 이후에 parameterized macro를 볼 것이다.
Simple Macros
simple macro(또는 C표준에서는 object-like macro)의 정의는 아래의 형태를 가진다.
#define identifier replacement-listreplacement-list는 어떠한 전처리 토큰(preprocessing tokens)의 결과라도 가능하다. Section 2.8에서 논의한 것처럼 토큰은 "의미를 바꾸지 않고서는 쪼개지지 않는 문자의 그룹"이다. C프로그램은 일련의 토큰들로 구성되어있다고 생각할 수 있다. "token"이라는 말을 이 chapter에서 사용할 때마다, 이 token은 "preprocessing token"을 의미하는 것이다.
매크로의 replacement 목록은 식별자(identifiers), 키워드(keywords), 숫자형 상수(numeric constants), 문자형 상수(character constants), 문자열 리터럴(string literals), 연산자(operators), 부호(punctuation)를 포함할 수 있다. macro 정의를 마주쳤을 때, 전처리기는 identifier가 replacement-list를 표현하도록 만든다. identifier가 파일 안에서 나올 때마다, 전처리기는 replacement-list가 대체하도록 한다.
macro의 정의 내부에 추가적인 심볼을 넣으면 안된다. replacement-list의 일부로써 받아들여지기 때문이다. = 심볼을 macro 정의 내부에 넣는 것은 일반적인 에러이다.\
#define N = 100 /*** WRONG ***/
...
int a[N]; /* becomes int a[= 100]; */이 예제에서는, N은 한 쌍의 토큰(=과 100)으로써 정의되었다. macro의 정의를 세미콜론(;)으로 끝내는 것은 또다른 유명한 실수이다.
#define N 100; /*** WRONG ***/
...
int a[N]; /* becomes int a[100;]; */N은 100과 ;의 토큰으로 정의된다.
컴파일러는 macro 정의 내부에 추가적인 심볼로 인해 발견되는 대부분의 에러를 감지할 것이다. 불행하게도 컴파일러가 올바르게 사용되지 않은 각각의 macro를 표시할 것이다. 실질적인 범죄자(culprit)인 macro의 정의는 전처리기에 의해 사라졌기 때문에 확인되지 않기 때문이다.
simple macro는 주로 Kernighan과 Ritchie가 "명확한 상수(manifest constants)"라고 부르는 것을 정의하는 것에 사용된다. macro를 사용하면, 우리는 숫자, 문자, 문자열 값에 이름을 부여할 수 있다.
#define STR_LEN 80
#define TRUE 1
#define FALSE 0
#define PI 3.14159
#define CR '\r'
#define EOS '\0'
#define MEM_ERR "Error: not enough memory"#define을 사용하여 상수에 대한 이름을 생성하는 것은 몇가지 큰 이점을 가진다.
- 프로그램을 더 읽기 쉽게 만든다. 잘 선택된 macro의 이름은 독자가 상수의 의미를 이해하는 것에 도움이 된다. 반대로 "마법의 숫자(magic number)"로 가득찬 프로그램은 독자를 더 쉽게 신비롭게(mystify) 만든다.
- 프로그램을 더 쉽게 수정하도록 만든다. 우리는 하나의 macro 정의를 수정하는 것으로 프로그램의 전반에 걸친 상수의 값을 변경할 수 있다. "Hard-coded" 상수들은 더 바꾸기 어려운데, 특히 조금씩 수정된 형태를 가질 수 있기 때문이다(예를 들어, 100의 길이의 배열을 가진 프로그램은 0에서 99까지의 루프를 가질 수 있다. 만약 우리가 단순히
100을 프로그램 안에서 찾는다면, 우리는99를 놓치게 된다). - 불일치와 오타(typographical error)를 피하는 것에 도움이 된다. 만약
3.14159와 같은 상수가 프로그램 내에서 자주 등장한다고 한다면, 때때로 우연히3.1416이나3.14195와 같이 작성될 수 있다.
비록 simple macro가 상수에 대한 이름을 정의하는 것에 자주 사용되지만, 다른 방식의 적용도 가능하다.
- C의 문법을 조금 수정할 수 있다. 사실, 우리는 C 심볼의 다른 이름의 역할을 제공할 수 있는 macro를 정의하는 것으로 C의 문법을 수정할 수 있다. 예를 들어 Pascal의
begin과end를 C의{와}보다 더 선호하는 프로그래머가 있다면, macro를 아래와 같이 정의할 수 있다.
#define BEGIN {
#define END }우리는 우리만의 언어를 더 만들 수 있다. 예를 들어 우리는 무한 루프를 수행하는 LOOP 구문을 만들 수 있다.
#define LOOP for (;;)그렇지만 C의 문법을 수정하는 것은 좋은 생각이 아닌데, 왜냐하면 다른 사람이 이해하기 어렵게 만들기 때문이다.
- 자료형의 이름을 다시 정할 수 있다. Section 5.2에서, 우리는
int의 이름을 다시 수정하는 것으로 Boolean 자료형을 만들었었다.
#define BOOL int비록 어떤 프로그래머들이 이러한 의도로 macro를 만든다고 하더라도, 자료형 정의는 자료형을 이름을 정하는 가장 좋은 방법이다.
- 조건 컴파일을 제어할 수 있다. macro는 조건 컴파일을 제어할 수 있는 중요한 역할을 하는데, 이는 Section 14.4에서 볼 것이다. 예를 들어 프로그램 내부에 존재하는 행이 "debuggging mode"에서 컴파일되도록 나타내려면, debuging 결과를 생성하는 추가적인 구문을 포함해야한다.
#define DEBUG우연히, macro의 replacement-list를 빈 공간으로 작성할 수 있는데 이는 규칙에 어긋나지 않는다.
macro가 상수로써 사용되었을 때, C 프로그래머들은 관습적으로 그 이름들을 모두 대문자로 한다. 그러나 다른 의도로써 사용된 macro를 어떻게 대문자로 할 것인지에 대한 합의는 없다. macro(특히 parameterized macros)는 버그의 원천(source)이기 때문에, 여기에 관심이 있는 프로그래머들은 macro의 이름을 정할 때 모두 대문자를 사용하기도 한다. 소문자 이름을 선호하는 사람은 Kernighan and Ritchie의 The C Programming Language의 스타일을 따른다.
Parameterized Macros
parameterized macro(function-like macro로도 알려진)의 정의는 아래의 형태를 가진다.
#define identifier( x1 , x2 , ... , xn ) replacement-listx1, x2, ..., xn은 식별자들(매크로의 parameters)이다. parameter는 replacement-list의 의도대로 나타날 것이다.
macro 이름과 소괄호 사이에는 공백이 절대로 없어야 한다. 만약 공백이 남아있다면, 전처리기는 우리가 simple macro를 정의했다고 가정할 수도 있다. (x1, x2, ..., xn)을 replacement-list의 일부로 처리할 것이다.
전처리기가 parameterized macro의 정의를 마주쳤을 때, 전처리기는 나중에 사용하기 위해 이 정의를 저장할 것이다. identifier(y1, y2, ..., yn)의 형태의 macro invocation이 프로그램에 등장할 때마다, 전처리기는 이를 replacement-list로 대체하는데 x1을 y1로, x2를 y2로, 이러한 방식으로 계속 나아가면서 대체한다.
예를 들어, 우리가 아래의 macro를 정의했다고 생각해보자.
#define MAX(x, y) ((x)>(y)?(x):(y))
#define IS_EVEN(n) ((n)%2==0)(macro 내부의 괄호의 숫자가 과도하게 많은 것처럼 보이지만, 여기에는 이유가 있고, 이에 대해선 이 Section에서 알아볼 것이다.) 이제 우리가 두 개의 macro를 아래와 같이 불렀다고(invoke) 가정해보자.
i = MAX(j+k, m-n);
if (IS_EVEN(i)) i++;전처리기는 이 행들을 아래와 같이 대체할 것이다.
i = ((j+k)>(m-n)?(j+k):(m-n));
if (((i)%2==0)) i++;이 예제가 보여주는 것처럼, parameterized macro는 간단한 함수의 역할을 할 수 있다.MAX는 두 개의 값 중 큰 값을 계산하는 함수처럼 행동한다. IS_EVEN은 짝수이면 1, 아니면 0을 반환하는 함수처럼 행동한다.
아래에 함수처럼 작동하는 더 복잡한 macro가 있다.
#define TOUPPER(c) ('a'<=(c)&&(c)<='z'?(c)-'a'+'A':(c))이 macro는 문자 c가 'a'와 'z'사이에 있는지 검사한다. 만약 그렇다면, 문자 c에 'a'를 빼고 'A'를 더하여 c를 대문자로 만든다. 만약 그렇지 못한다면 c를 바꾸지 않은채로 놔둔다. (<ctype.h> 헤더는 toupper와 더 이식성 좋고 간단한 함수를 제공한다.)
parameterized macro는 빈 parameter-list를 가질 수 있다. 아래는 예시이다.
#define getchar() getc(stdin)빈 parameter-list가 실제로 필요하진 않지만 getchar를 함수와 비슷하게 만든다.(생각하고 있는 것이 맞다. 이는 <stdio.h>에 속해있는 getchar와 동일하다. getchar가 보통 함수뿐만 아니라 macro로도 구현된다는 것을 Section 22.4에서 알아볼 것이다.)
parameterized macro를 실제의 함수 대신에 사용하는 것은 두 가지의 이점을 가진다.
- 프로그램이 조금 더 빨라질 수 있다. 함수 호출은 프로그램 실행 동안에 조금의 오버헤드(overhead)를 필요로 한다. context information이 반드시 저장되어야 하고, argument들이 저장되는 등의 것들이 있다. 그렇지만 macro invocation은 실행중의 오버헤드가 존재하지 않는다. (그렇지만 C99의 inline 함수는 매크로의 사용 없이 이러한 오버헤드를 피할 수 있는 방법을 제공한다는 점을 주목해야 한다.)
- macro는 "generic"이다. macro parameter는 함수 parameter와는 다르게 특정한 자료형이 없다. 결과적으로, 전처리과정 후의 결과인 프로그램이 유효하다면 macro는 어떤 자료형의 argument도 받아들일 수 있다. 예를 들어 우리는 자료형이
int,long,float,double등의 두 개의 값 중 더 큰 것을 찾는MAXmacro를 사용할 수 있다.
그러나 parameterized macro는 단점또한 가진다. - 컴파일 코드가 더 커질 수 있다, 각각의 macro invocation은 매크로의
replacement-list의 삽입을 발생시키는데, 그러므로 소스 프로그램(컴파일 코드)의 크기가 증가한다. macro가 더 자주 사용될수록, macro invocations가 이 효과가 더 명백해진다. 문제는 mcaro invocation이 중첩될 때 복합적으로 변한다. 우리가 3개의 숫자 중 가장 큰 것을 찾는MAX를 사용했을 때 무엇이 일어나는지 생각해보자.
n = MAX(i, MAX(j, k));전처리과정을 거친 후의 구문이다.
n = ((i)>(((j)>(k)?(j):(k)))?(i):(((j)>(k)?(j):(k))));- argument의 자료형이 체크되지 않는다. 함수가 호출되었을 때, 컴파일러는 argument가 적절한 자료형을 가지는지 보기 위해 각각의 argument를 체크한다. 그렇지 못하다면, argument 는 적절한 자료형으로 변환되거나 컴파일러가 에러메시지를 발생시킨다. macro argument는 전처리기에 의해 체크되지 않고, 변환되지도 않는다.
- macro를 가리키는 포인터는 불가능하다. 나중에 볼 Section 17.7처럼, C언어는 특정한 프로그래밍 상황안에서 유용한 개념인 함수를 가리키는 포인터를 허용한다. macro는 전처리과정에서 제거되기 때문에, "macro를 가리키는 포인터"에 대응하는 개념이 존재하지 않으므로 macro는 이러한 상황에서 사용될 수 없다.
- macro는 arguments를 한 번보다 더 많이 계산할 수 있다. 함수는 argument를 딱 한번만 계산한다. macro는 두 번 또는 더 많이 argument를 계산한다. 만약 argument가 side effect를 가질 때 argmuent를 한 번보다 더 많이 계산하는 것은 예상하지 못한 행동(unexpected behavior)을 야기한다.
MAX의 argument가 side effect를 가지는 argument를 가졌을 때 무슨 일이 일어날 지 생각해보자.
n = MAX(i++, j);전처리과정 이후의 같은 행을 생각해보자.
n = ((i++)>(j)?(i++):(j));i가 j보다 크다면, i는 (부적절하게)두 번 증가할 것이고, n에 대입된 값은 예상할 수 없는 값이다.
macro argument를 한 번보다 더 많이 평가하여 발생하는 에러는 찾기 어려울 수 있는데, macro invocation은 함수의 호출과 동일하게 보이기 때문이다. 설상가상으로, side effect를 가진 특정한 argument들에만 실패하고, macro는 대부분 적절하게 작동하는 것처럼 보인다. 자기 보호를 위해 arguement 내부의 side effect를 피하는 것은 좋은 생각이다.
parameterized macro는 함수를 시뮬레이션하는 것 이상으로 좋다. 특히, 반복하는 코드에 대한 패턴에 종종 사용된다. 아래의 구문을 쓰는 것에 싫증이 난다고 생각해보자.
printf("%d\n", i);우리가 정수 i를 출력할 때 위의 구문을 항상 사용할 수도 있다. 우리가 아래의 macro를 정의하는 것으로 정수들을 출력하기 더 쉽게 만들 수 있다.
#define PRINT_INT(n) printf("%d\n", n)PRINT_INT(i/j);
printf("%d\n", i/j);PRINT_INT가 정의되고 나면, 전처리기는 위의 행을 아래의 행으로 바꾼다.
The # Operator
macro 정의는 두 개의 특별한 연산자들을 포함하는데, #과 ##이다. 두 개의 연산자 모두 컴파일러에 의해 인식되지는 않는다. 대신에, 전처리과정에 실행된다.
# 연산자는 macro argument를 문자열 리터럴로 변환시킨다. 이는 오직 parameterized macro의 replacement-list에서만 발견할 수 있다(#에 의해 수행되는 작용은 "문자열화(stringization)으로도 알려져있고, 이 용어는 사전을 찾아봐도 나오지 않을 것이다).
#의 사용처는 많다. 하나를 생각해보자. 정수형 변수와 표현식의 값을 출력하는 편리한 방법으로 디버깅을 하는 중에 PRINT_INT macro 를 사용하기로 결정했다고 가정해보자. # 연산자는 PRINT_INT를 출력하는 각각의 값에 대한 라벨을 만든다. 아래의 PRINT_INT를 보자.
#define PRINT_INT(n) printf(#n " = %d\n", n)n의 앞에 있는 # 연산자는 전처리기가 PRINT_INT의 argument로부터 문자열 리터럴을 만들도록 지시를 내린다.
PRINT_INT(i/j);
printf("i/j" " = %d\n", i/j);그래서 위의 행의 invocation은 아래의 행이 된다.
우리는 Section 13.1에서 컴파일러가 자동적으로 인접한 문자열 리터럴을 합친다는 것을 보았고, 그래서 위의 구문은 아래와 동일하다.
printf("i/j = %d\n", i/j);프로그램이 실행되었을 때, printf는 i/j 표현식과 그 값을 출력한다. 예를 들어 만약 i가 11이고 j가 2라면 출력결과는 아래와 같다.
i/j = 5The ## Operator
##연산자는 두개의 토큰(예를 들면 identifiers)을 하나의 토큰으로 "붙여넣는다(paste)"(놀랍지 않은것은, ## 연산이 "token-pasting"으로도 불린다는 것이다). 만약 피연산자 중 하나가 macro parameter라면, parameter가 대응하는 argument에 의해 대체되고 난 뒤에 붙여넣기가 발생한다는 점이다. 아래의 macro를 생각해보자.
#define MK_ID(n) i##nMK_ID가 불렸을 때(invoked)(MK_ID(1) 처럼), 전처리기는 parameter n을 argument(이 경우에는 1)로 대체한다. 다음에 전처리기는 i와 1을 단일 토큰(i1로 합친다. 아래의 선언은 MK_ID를 사용하여 세 개의 identifiers를 만들도록 한다.
int MK_ID(1), MK_ID(2), MK_ID(3);전처리과정 이후 위의 선언은 아래처럼 된다.
int i1, i2, i3;## 연산자는 전처리기의 특징으로 자주 사용되는 것은 아니다. 사실, 이것을 필요로 하는 많은 상황을 생각하는 것은 어렵다. ##의 진정한 적용을 찾기 위해, 우리는 일찍이 이 Section에서 언급된 MAX macro를 다시 생각해봐야한다. 우리가 보았던 것처럼, MAX는 argument가 side effect를 가진다면 적절한 동작을 하지 못한다. MAX macro를 사용하는 것의 대안은 max 함수를 작성하는 것이다. 불행하게도 하나의 max 함수로는 충분하지 않을 수도 있는데, 우리는 int형 argument를 가지는 함수, float형 argument를 가지는 함수 등의 더 많은 함수가 필요할 수 있다. 이 max의 모든 version은 argument의 자료형과 return type을 제외하고는 동일하다. 그래서 처음부터 하나씩 정의하는 것은 부끄러운 일(shame)처럼 보일 수 있다.
해결책은 max 함수의 정의를 확장하는 macro를 작성하는 것이다. macro는 단일 parameter인 type을 가질 것인데, 이는 argument의 자료형과 return type을 표현한다. 걸림돌이 하나 있다. 만약 우리가 하나보다 더 많은 max 함수를 macro를 사용해 만들게 된다면, 프로그램은 컴파일되지 않을 것이다. (C언어는 같은 파일안에 정의된 같은 이름을 가진 2개의 함수를 허용하지 않기 때문이다.) 이 문제를 해결하기 위해 우리는 ## 연산자를 사용해 max의 각각 다른 이름을 가진 version을 만들 수 있다.
#define GENERIC_MAX(type) \
type type##_max(type x, type y) \
{ \
return x > y ? x : y; \
}어떻게 type이 _max와 합쳐져 함수의 이름을 만드는지 확인해보자.
우리가 float 값으로 작동하는 max 함수를 필요로 한다고 가정해보자. 그러면 우리는 GENERIC_MAX를 사용하여 함수를 정의해야 한다.
GENERIC_MAX(float)전처리기는 이 행을 아래와 같은 코드로 확장시킨다.
float float_max(float x, float y) { return x > y ? x : y; }General Properties of Macros
지금까지 우리는 simple macro와 parameterized macro에 대해 알아보았다. 양쪽 macro에 모두 적용되는 규칙이 있는데, 이를 한번 보자.
- macro의
replacement-list는 다른 macro의 invocations을 포함할 수 있다. 예를 들어 우리가 macroPI의 측면에서 macroTWO_PI를 정의할 수 있다.
#define PI 3.14159
#define TWO_PI (2*PI)TWO_PI가 나중에 프로그램 안에서 발견되면, 전처리기는 그것을 (2*PI)로 대체한다. 전처리기는 그 후 다른 macro의 invocation을 포함하는지 확인하기 위해(이 경우에는 PI) replacement-list를 다시 스캔한다(rescan).
- 전처리기는 오직 전체의 token을 대체하고, token의 일부를 대체하지는 않는다. 결과적으로 전처리기는 identifiers, character constants, string literal 안에 내제된 macro의 이름은 무시한다. 예를 들어 아래의 행들을 포함한 프로그램을 생각해보자.
#define SIZE 256
int BUFFER_SIZE;
if (BUFFER_SIZE > SIZE)
puts("Error: SIZE exceeded");전처리과정 이후, 위의 행들은 아래와 같은 모습으로 바뀔 것이다.
int BUFFER_SIZE;
int (BUFFER_SIZE > 256)
puts("Error: SIZE exceeded");식별자(identifier) BUFFER_SIZE와 문자열 "Error: SIZE exceeded"는 양쪽 모두 SIZE 단어를 포함했음에도 전처리과정에 영향을 받지 않았다.
- macro 정의는 일반적으로 파일의 끝까지 효과가 남아있다. macro가 전처리기에 의해 조작되기 때문에, 일반적인 scope 규칙에 따르지 않는다. 함수의 body 내부의 macro 정의는 함수에 한정되지(local) 않는다. 파일의 끝까지 정의된 채로 남아있는다.
- 새로운 macro의 정의가 이전 macro의 정의와 동일하지 않다면, macro는 두 번 정의될 수 없다. 간격(spacing)의 차이는 허용되지만, 매크로의
replacement-list내부의 토큰은 반드시 동일해야 한다. - Macro는
#undefdirective에 의해 "undefined"될 수 있다.#undefdirective는 아래와 같은 형태를 가진다.
#undef identifieridentifier은 macro의 이름이다.
#undef N위의 행은 macro N의 현재 정의를 제거한다. (만약 N이 macro로써 정의되지 않았따면, #undef는 어떠한 효과도 가지지 않는다.) #undef의 사용은 macro의 존재하는 정의를 제거하고, 새로운 정의가 주어질 수 있도록 한다.
Parentheses in Macro Definitions
macro 정의에서 replacement-lists는 괄호로 꽉차있었다. 실제로 이렇게 많은 괄호가 필요할까? 정답은 아주 그렇다. 만약 우리가 적은 괄호를 사용하게 된다면, macro는 예상치 못한, 바람직하지 못한 결과를 낼 수 있다.
macro 정의에서 괄호를 어디에 넣는지 결정할 때 따라야할 두 개의 규칙이 있다. 첫번째, 만약 macro의 replacement-list가 연산자를 포함하고 있다면, 항상 괄호로 replacement-list를 둘러싸야한다.
#define TWO_PI (2*3.14159)두번째, 만약 macro가 parameter를 가지고 있다면, replacement-list안에서 parameter가 나타날 때마다 괄호를 넣어야 한다.
#define SCALE(x) ((x)*10)괄호가 없다면, 컴파일러가 replacement-list와 argument를 전체 표현식으로 처리한다고 보장할 수 없다. 컴파일러는 우리가 예상할 수 없는 연산자 우선순위와 associativity의 규칙을 적용시킬 수도 있다.
macro의 replacement-list에 괄호를 붙이는 것에 대한 중요성을 설명하기 위해서, 괄호가 없는 아래의 macro 정의를 생각해보자.
#define TWO_PI 2*3.14159
/* needs parentheses around replacement list */conversion_factor = 360/TWO_PI;
conversion_factor = 360/2*3.14159;전자 구문은 전처리과정을 거치고 후자의 구문이 된다.
곱셈이 일어나기 전 나눗셈이 먼저 수행될 것이고, 의도했던 결과와 다른 결과를 발생시킨다.
macro가 parameters를 가졌다면 replacement-list에 괄호를 넣는 것만으로는 충분하지 않다. 각각의 parameter의 등장에도 괄호가 필요하다. 예를 들어 SCALE이 아래와 같이 정의되었다고 가정해보자.
#define SCALE(x) (x*10) /* needs parentheses around x */j = SCALE(i+1);
j = (i+1*10);전자의 구문은 전처리과정을 거쳐 후자의 구문이 된다.
곱셈이 덧셈보다 더 높은 우선순위를 가지기 때문에, 위의 구문은 아래와 같다.
j = i+10;당연하게도 우리는 이 구문이 아니고 아래의 구문을 원했을 것이다.
j = (i+1)*10;macro 정의 내부에서 괄호의 없음은 C언어의 가장 짜증나는 에러를 발생시킬 수 있다. 프로그램이 일반적으로 컴파일되고, macro가 작동하는 것처럼 보이지만 실패할 수 있다.
Creating Longer Macros
콤마(,) 연산자는 replacement-list가 일련의 표현식을 만드는 것을 가능하게 하여 더 정교한 macro를 만드는 것에 도움이 된다. 예를 들어 아래의 macro는 문자열을 읽어 출력하는 macro이다.
#define ECHO(s) (gets(s), puts(s))gets와 puts의 호출은 표현식이고, 그래서 콤마 연산자를 사용하여 이 두개를 결합하는 것은 완벽하게 규칙에 맞다. 우리는 마치 함수인것처럼 ECHO를 부를(invoke) 수 있다.
ECHO(str); /* becomes (gets(str), puts(str)); */불행하게도, 이 방법은 잘 동작하지 않는다. 우리가 ECHO를 if 구문 안에서 사용한다고 가정해보자.
if (echo_flag)
ECHO(str);
else
gets(str);ECHO를 대체하는 것은 아래의 결과를 낸다.
if (echo_flag)
{ gets(str); puts(str); };
else
gets(str);컴파일러는 첫번째 2개의 행을 완성된 if 구문으로써 처리할 것이다.
if (echo_flag)
{ gets(str); puts(str); }컴파일러는 뒤에 오는 세미콜론(;)을 null 구문으로 처리하고, else 절에 대해 에러 메시지를 발생시키는데, else절이 어떠한 if구문에도 속하지 않기 때문이다. 우리는 ECHO의 invocation에서 세미콜론을 넣지 않는 것을 기억하는 것으로 이 문제를 해결할 수 있다. 하지만 프로그램이 이상하게 보일 것이다.
콤마 연산자는 ECHO에 대한 이 문제를 해결하는데, 모든 macro에 대해서 해결이 가능한 것은 아니다. macro가 일련의 표현식이 아니라 일련의 구문을 필요로 한다고 가정해보자. 콤마 연산자는 어떠한 도움도 줄 수 없다. 콤마 연산자는 표현식을 붙일(glue) 뿐이지 구문을 붙이지는 않기 때문이다.
해결책은 조건이 거짓(false)인 do 루프 내부에 구문을 감싸는 것이다(이는 한번만 실행될 것이다).
do { ... } while (0)do 구문이 완벽하지 않다는 것을 생각해야한다. do 구문은 끝에 세미콜론을 필요로 한다. 이 트릭이 동작하는 것을 보기 위해서는, ECHO macro에 이것을 포함시켜보자.
#define ECHO(s) \
do { \
gets(s); \
puts(s); \
} while (0)ECHO가 사용되었을 때, do 구문을 완성하기 위해 반드시 세미콜론이 뒤따라야한다.
ECHO(str);
/* becomes do { gets(str); puts(str); } while (0); */