Abstract
일반적인 sentiment analysis는 text의 전반적인 sentiment를 분류하지만, 어떤 entity나 aspect에 대해 sentiment를 갖고 있는지는 알 수 없다. Aspect-based sentiment analysis (ABSA)는 sentiment와 aspect를 모두 분류하는 task이다. 이 논문에서는 pre-trained language model BERT를 활용하여 ABSA를 해결하고자 한다.
Introduction
Problems & Causes
전통적인 sentiment analysis는 어떤 대상에 대해 갖는 sentiment인지와 관계없이 전반적인 sentiment 분류하는데 집중한다. 그러나 하나의 텍스트에 서로 다른 topic이나 entity에 대한 sentiment가 나타날 수 있다. (e.g. 가격은 비싸지만 디자인은 예뻐요)
이 논문에서는 pre-trained language model인 BERT를 base model로 사용하는데, 이를 활용하여 text와 aspect 간의 semantic similarity를 sentence pair classification model로 찾고자 한다.
Previous work
BERT
Input Representation
BERT는 wordpiece tokenization을 사용한다. 2개의 specialized token이 존재하는데 classifier token [CLS]는 input의 가장 앞 부분에 추가되는 token이다. [SEP]는 seperation token으로 문장의 끝을 표현한다.
Sentence Pair Classifier Task
Sentences 간의 semantic relations을 결정하기 위해 사용한다. Model은 2개의 sentences를 [SEP] token으로 이은 값을 input으로 받는다. Output은 sentence 간의 관계를 나타낸다.
-
Aspect-Based Sentiment Analysis
-
ABSA without BERT
-
ABSA with BERT
Methods
1. Data preprocessing
SemEval-2016 dataset은 "ENTITY#ASPECT" 구조로 되어있다. 이 논문에서는 모델이 데이터를 잘 이해할 수 있도록 문장과 유사한 구조를 갖도록 ASPECT를 수정하였다.
(e.g. "FOOD#STYLE_OPTIONS" ➡ "food, style options")
2. Aspect Category Classifier
Aspect(entity#property)가 text와 연관이 되어있는지 판단한다. 이를 통해, out-of-domain aspects를 처리할 수 있다.
- BERT를 이용한 Sentence pair classifier
- Input: [CLS] {text} [SEP] {entity},{property} [SEP]
(e.g. "[CLS] 비싸지만 맛있어요 [SEP] 음식,가격 [SEP]") - Output: Related, Unrelated
3. Sentiment Classifier
Aspect 관점에서 text의 sentiment를 판단한다.
- sentiment label (positive, negative, neutral, conflict) 을 결정하기 위해 학습된 sentence pair classifier
- Input: [CLS] {text} [SEP] {entity},{property} [SEP]
- Output: positive, negative, neutral, conflict(positive, negataive가 모두 혼재)
4. Combined Model for Both Aspect and Sentiment Classification
- aspect와 sentiment를 동시에 예측하는 multi-class classifier
- Sentence pair classifier
- Input: [CLS] {text} [SEP] {entity},{property} [SEP]
- Output: positive, negative, neutral, conflict, unrelated
Sentiment Classifier과 Aspect Category Classifier의 기능을 합친 모델로 text와 aspect이 연관되어있으면 sentiment label을, 연관되어 있지 않으면 unrelated label을 출력한다.
Experiments & Result
Data
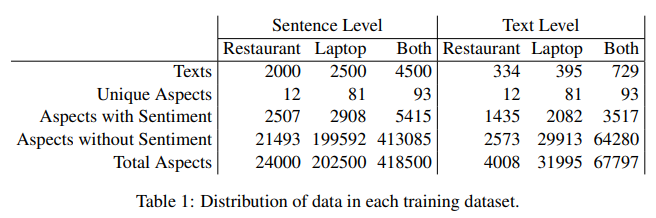
데이터로는 SemEval-2016 Task 5의 subtasks를 사용
1. Aspect Category Models
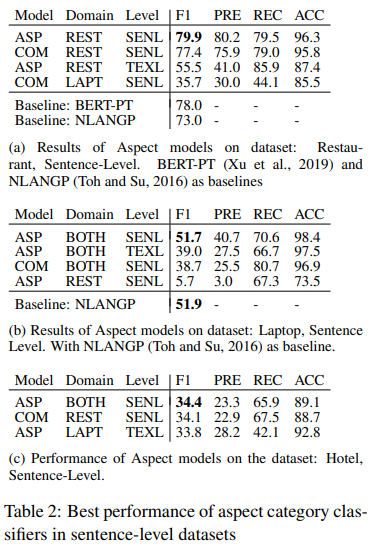
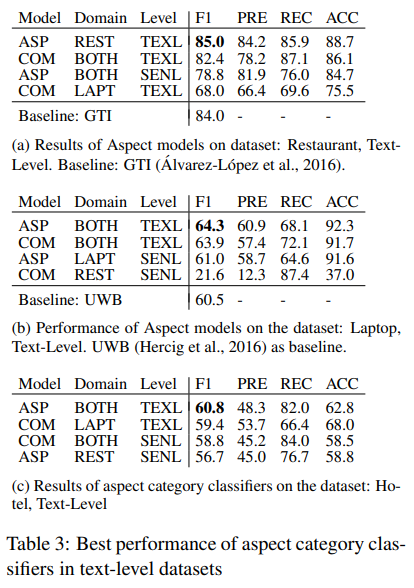
"COM"은 combined model, "ASP"는 Aspect Category Classifier을 나타낸다. ASP가 COM보다 항상 성능이 좋았다. 또한, Sentence Level 에서 Text Level 보다 높은 성능을 보였다.
2. Sentiment Models
아래 Table에서 F1 score은 각 label에 대한 weighted average를 나타낸다. "COM"은 combined model, "SEN"은 Sentiment Classifier 이다.
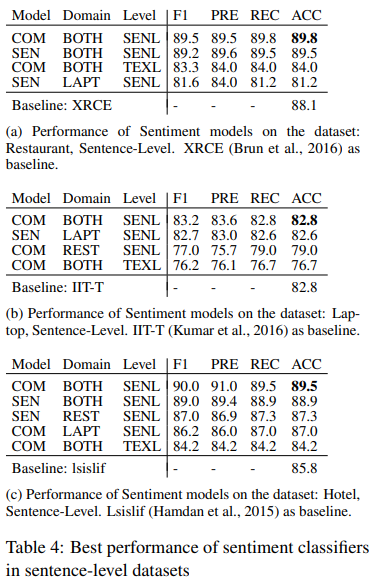
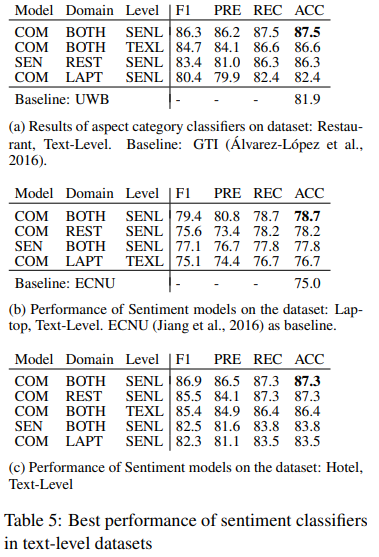
Table4와 Table5 모두에서 COM이 SEN 보다 성능이 좋았다. 또한, sentence-level datasets로 학습된 classifier이 text-level datasets으로 학습된 모델보다 성능이 좋다.
Discussion
Combined model이 모든 도메인에 대해 sentiment model 보다 좋은 성능을 보였는데, 이는 unrelated data로 combined model이 redundant features를 무시하도록 학습되었기 때문으로 보인다. 반면, Combined model은 aspect model보다 낮은 성능을 보이는데, 이는 combined model은 4가지 sentiment 와 aspect와의 관련성을 한 번에 분류하여야 하기 때문에 모델의 복잡성이 증가했기 때문에 그런 것으로 보인다.
Conclusion
- ABSA task를 pre-trained language model BERT를 활용하여 해결
- sentence pair classification을 사용. TEXT#ASPECT (e.g. 가격은 비싸지만 맛있어요.,가격)
Development
- BERT 모델을 domain에 맞는 corpus로 further pre-training을 진행하면 ABSA에 대한 performance 향상을 기대할 수 있지 않을까?
- Example of aspect-based sentiment analysis
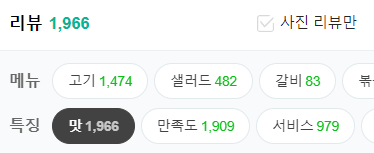
네이버에서 볼 수 있는 식당 리뷰이다. 이 논문의 ABSA에서 더 나아간 분석 기능을 제공하는데, 특징을 Aspect 로 볼 수 있을 것이다.
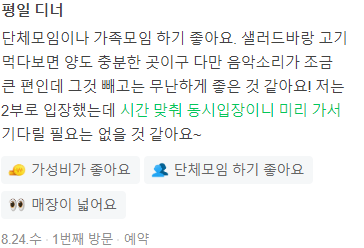
특정 ASPECT 관점으로 리뷰를 분석할 뿐만 아니라, 어떤 token이 aspect 와 연관되어있는지 그 위치도 제공한다.
