논문
Abstract
Pretrain 된 Language model을 domain corpus로 pretrain (domain-adaptive pretraining) 하였을 때 자원의 크기와 무관하게 모델의 성능이 향상되었다. 또한, domain-adaptive pretraining 이후에 fine-tuning task에서 사용할 unlabeled data로 pretrain (task-adaptive pretraining)을 다시 진행했을 때도 모델의 성능이 향상됐다. 마지막으로 논문에서는 Domain-adaptive pretraining이 불가능할 때 task corpus에 대해 간단한 selection strategies를 적용하여 데이터를 증강 시키는 기법을 보였다.
전반적으로, multi-phase adaptive pretraining은 task performance의 향상을 가능하게 했다.
Introduction
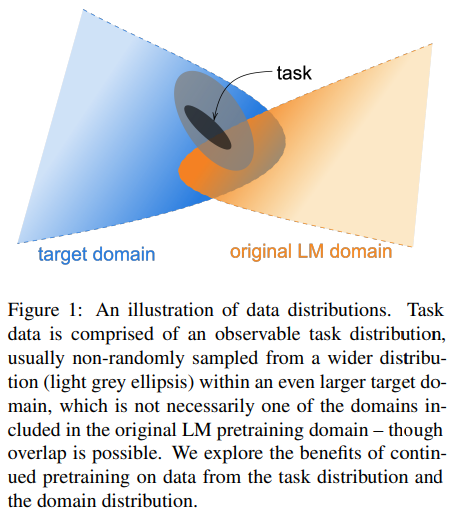
Target domain과 Original LM domain은 data distribution 상에서 차이가 있다. 따라서, Original LM domain이 task를 모두 포함하지 못하기 때문에 특정한 도메인에서는 Original LM 의 성능이 떨어질 수 있다.
이 논문에서는 4개의 domain(biomedical, computer science, publications, news, reviews)에 대해 8 개의 classification task를 진행했다.
high, low resource setting에 관계없이 DAPT(domain-adaptive pretraining)은 일관성 있게 task performance를 향상 시켰다.
다음으로, 이 논문에서는 task에 맞게 LM을 further pretrain 하는 것을 실험했다. TAPT(task-adaptive pretraing)은 label이 되어있지 않은 task dataset을 corpus로 활용하여 진행했다. TAPT는 ROBERTa에서 성능 향상을 보였다. DAPT 이후에 further train을 진행했을 때도 performance 향상을 관찰 할 수 있었다.
마지막으로 사람이 직접 작성한 task distribution을 따르는 추가적인 unlabeld data가 있을 때 TAPT의 장점이 극대화 되는 것을 확인했다.
위 실험으로부터 아이디어를 얻어, 이 실험에서는 추가적인 task와 관련된 unlabeled text를 자동으로 선택하는 아이디어를 제안한다.
Background
ROBERTa는 Transformer을 기반으로 한 pretrained LM으로 BERT와 구조가 같다. 이는 랜덤하게 masked 된 token을 예측하도록 학습되었다.
Domain-Adaptive Pretraining
DAPT의 목표는 ROBERTa를 domain에 특화된 large corpus로 학습 시키는 것이다. 실험을 진행할 도메인으로 BioMed, CS, Reviews, News로 설정했다.
Analyzing Domain Similarity

DAPT를 수행하기 전에, ROBERTa의 pretrain domain과 target domain의 유사도를 검사했다. 위 표에서 PT는 ROBERTa의 pretraining corpus와 유사한 corpus이다. CS와 BioMed가 PT와 유사도가 가장 낮은 것을 관찰 할 수 있는데, 유사도 값이 작을수록 DAPT를 통해 더 많은 성능 향상을 기대할 수 있다.
Experiments

위 실험을 통해 PT와 유사도 값이 작을수록 DAPT를 진행했을 때 masked LM loss가 ROBERTa의 loss보다 더 많이 낮아진다는 것을 증명했다.

Table 3의 NEWS에서 AGENEWS는 DAPT를 했을 때 성능이 하락했지만, HYP에서는 성능이 향상되었다. 이를 통해, task domain과 ROBERTa의 source domain이 유사해도 DAPT가 효과적일 수 있다는 것을 알 수 있다.
Domain Relevance for DAPT
DAPT로 인한 성능 향상이 domain에 관계없이 data 양의 증가로 인한 것은 아닌지 실험했다. Figure 2에 따라서 유사도가 낮은 도메인을 ¬DAPT의 도메인으로 설정했다. 각 task에 대해 DAPT는 domain과 무관하게 높은 성능을 보였지만, ¬DAPT는 ROBERTa보다 task에 대해 일반적으로 성능이 떨어졌다. Task에 따라서 domain에 무관한 DAPT가 효과적일 수는 있지만, domain과 무관한 데이터에 많이 노출되면 end-task performance가 하락할 수 있으므로 주의해야 한다.
Domain Overlap
Domain 간의 경계는 어느정도 서로 침범한다. 예를 들면 Figure 2에서 REVIEWS와 NEWS는 40%의 유사도를 갖는다. 이와 같은 경우, 서로 domain이 다름에도 performance에 대한 영향이 크지 않았는데, 이를 활용해 효율적인 pretrain 방법을 고안할 수는 없을지 고민해보려 한다.
Task-Adaptive Pretraining
Task-adaptive pretraining(TAPT)는 task에 대한 unlabeled dataset으로 pretrain 하는 것을 말한다. DAPT와 비교했을 때, TAPT는 DAPT보다 훨씬 더 적은 pretraining corpus를 사용하지만, task에 더 직접적으로 연관되어 있다. 이로 인해 TAPT는 DAPT보다 경제적이고, DAPT의 Performance를 넘어서기도 한다.
Experiments
DAPT와 마찬가지로, TAPT는 ROBERTa의 second phase pretraining이다. 다만, task-specific training data만을 사용한다. 랜덤하게 각 데이터셋에 15%를 masking 하여 pretrain 하였고, 마지막 layer의 [CLS] token을 classification을 위한 feedforward layer에 활용하였다.

Hyper parameter는 Table 13과 같이 설정했다.

Table 5는 Additional Pretraining Phase에 따른 학습 결과이다. HYPERPARTISAN, HELPFULNESS, IMDB, RCT에서는 TAPT가 DAPT 보다 성능이 좋았다.
Combined DAPT and TAPT
이번에는 DAPT와 TAPT를 모두 사용해보았다. 먼저, ROBERTa에 DAPT를 적용하고, 그 위에 TAPT로 pretrain을 진행했다. DAPT+TAPT로 3-phase pretrain 했을 때 모든 task에 대해 가장 높은 성능을 보였다. TAPT+DAPT는 task와 관련된 corpus를 망각할 가능성이 높다고 짐작된다.
Cross-Task Transfer
같은 domain에 속하는 TAPT로 transfer 하는 실험을 진행했다. 예를 들면 RCT unlabeled data로 LM을 further pretrain 하고, CHEMPROT labeled data로 fine-tune 하는 식이다. 이를 Transfer-TAPT로 명명하였다.

Transfer-TAPT의 결과를 Table 6에서 살펴볼 수 있다. 같은 domain에 속했음에도 Transfer-TAPT를 했을 때 성능이 떨어졌다. 이를 통해, data distribution이 동일한 domain에서도 다를 수 있다는 것을 알 수 있다. 더 나아가서 broad domain으로 학습된 LM을 사용하는 것만으로는 부족하고, 왜 DAPT+TAPT가 효과적인지를 증명했다.
Augmenting Training Data for Task-Adaptive Pretraining
지금까지 TAPT에서는 supervised task에 활용되는 training data를 활용하여 further pretrain을 진행했다. 이번에는, 사람이 만들었고 task distribution을 따르는 방대한 양의 unlabeled data가 존재하는 경우에 대한 학습 시나리오를 연구했다. 먼저, (RCT, HYPERPARTISAN, IMDB) 세가지 task에 대한 human curated unlabeled corpus를 사용했다. 다음으로, TAPT를 위한 human curated unlabeled data를 이용할 수 없는 경우, domain-corpus에서 어떻게 related unlabeled data를 찾을 수 있는지 알아보았다.
Human Curated-TAPT

Dataset은 large unlabeled corpus의 일부를 downsample 하여 사용한다. 이 때, corpus는 task training dataset과 유사한 분포를 갖고 있다. Table 7을 보면 Curated-TAPT는 DAPT + TAPT 보다 performance가 좋거나 비슷하다. 또한, DAPT + Curated-TAPT는 전체 Pretraining Phase 중에 가장 높은 성능을 보였다. 이를 통해 task distribution을 따르는 방대한 양의 데이터로 LM을 pretrain 했을 때, end-task performance가 상당히 향상되는 것을 알 수 있었다.
Automated Data Selection for TAPT

Table9는 각 Pretraining 방법에 따른 Computational requirements를 나타낸다. TAPT를 수행하기 위한 unlabeled data가 부족하거나, DAPT를 위한 학습 자원이 부족한 경우가 있을 것이다. 어떻게 해야할까?
논문에선 도메인에 관한 대용량 corpus로부터 task distribution을 따르는 unlabeled text를 비지도학습으로 뽑아내는 방법을 제안했다. 방법은 아래와 같다.
합리적인 시간에 많은 corpus를 embedding 시키기 위해 어느정도 가벼운 모델을 domain corpus로 학습 시킨다. (실험에서는 약 1M sentences) 다음으로, Embedding 차원에서 task sentence에 대한 k개의 candidates를 domain으로부터 선택한다. 이 때, Candidates는 K-NN (kNN-TAPT) 이나 랜덤하게 (RAND-TAPT) 선택한다.
위와 같이 선택된 candidates를 task data와 함께 LM을 pretrain 한다.
RESULTS

kNN-TAPT는 TAPT의 performance를 능가했다. RAND-TAP는 일반적으로 kNN-TAPT보다 performance가 좋지는 않았다. kNN-TAPT의 k를 증가시킬수록 DAPT의 performance에 근사했다.
Computational Requirements

TAPT는 DAPT보다 학습속도가 약 60배 빨랐다. 또한, DAPT가 TAPT보다 5.8M 배의 storage가 필요로 한다. DAPT+TAPT는 performance가 뛰어나지만 비용이 너무 비싸다. 그러나, 한번 LM이 domain에 대해 학습되면 추가적으로 TAPT 할 때 재사용이 가능하다는 장점이 있다. Curated-TAPT는 전반적으로 높은 성능을 보이지만 domain data가 많이 필요하다는 단점이 있다. Auitomatic method인 kNN-TAPT는 DAPT 보다 비용이 작다.
Conclusion
이 논문에서는 실험을 통해 수억 개의 parameter를 갖는 모델도 범용 언어 모델은 고사하고, single textual domain을 encoding 하는 것도 어렵다는 것을 확인했다. 또한, Language Model을 특정한 task나 corpus로 pretrain을 시키면 performance 상에서 이득이 있는 것을 확인했다.
결론
기존에 BERT를 활용한 classification 모델을 생성할 때는 BERT 모델을 freezing 하거나, 단순하게 BERT와 classifier를 모두 학습 시켰었다.
이 논문을 읽으면서 Pretrain과 dataset의 중요성을 알게되었다. 만약, 뉴스 기사 댓글의 감정을 분류하는 모델을 만든다고 한다면 해당 댓글과 관련된 corpus 는 감성 corpus와 뉴스 corpus 일 것이다. 먼저, 두 corpus를 합쳐서 모델을 pretrain 하고 나서, task dataset으로 pretrain을 진행하고 freezing 하여 classifier을 학습시키면 모델이 더 높은 성능을 보일 것으로 예상된다.
이제 필요한 것은 실험이다.
REFERENCE
https://arxiv.org/abs/2004.10964
