잘못 해석한 정보가 있을 수 있습니다. 피드백 주시면 수정하겠습니다.
Abstract
Dialogue-based relation extraction (RE)는 대화에 나타난 두 arguments 간의 관계를 추출하는 것을 목표로 한다. 대화에서는 정보가 여러 시점에 거쳐서 나타난다. Dialogue-based relation extraction에서는 대화의 문맥에 대한 이해가 필요하다. 이 논문에서는 사람이 대화를 이해하는 방식을 모방한 TUrn COntext awaRE Graph Convolutional Network (TUCORE-GCN)을 제안한다. 추가적으로 Emotion Recognition in Conversations (ERC)를 위한 새로운 접근법을 제안한다.
Introduction
대화에서 효과적으로 Relation extraction을 하기 위해서는 아래 문제들을 해결해야 한다.
1. 대화에는 화자(speaker)가 있다.
Subject와 object 간의 관계는 누가 어떤 말을 했는지에 따라 달라지기 때문에 이에 대한 정보가 필요하다.
예를 들어서 설명해보자.
Speaker 1: 오랜만이야. 잘 지냈어?
Speaker 2: 물론이지. 철수도 잘 지냈어?
위 대화에서 화자(speaker)와 발화문의 관계를 통해 Speaker 1이 철수라는 것을 알 수 있다.
2. 주변 turn의 발화문을 이해해야 한다.
대화에서 어떤 turn의 발화문을 이해하려면, 그 turn을 중심으로 이전 또는 이후의 발화문을 이해해야 한다.
예를 들어서 설명해보자.
Speaker 1: 걘 항상 늦어. 짜증나.
위와 같은 발화에서는 누가 항상 늦는 것인지 알 수가 없다.
Speaker 1: 어제 짱구를 만났어.
Speaker 2: 별일 없었어?
Speaker 1: 걘 항상 늦어. 짜증나.
그러나 위와 같이 발화가 나타난다면 이전 turn에 나타난 발화를 보고 짱구가 항상 늦는 것인지를 파악할 수 있다.
3. 대화는 순차적인 turn으로 이루어져있다.
Arguments는 서로 다른 turn에 나타날 수 있다. 결론적으로, arguments 간의 관계를 추출하기 위해서는 multi-turn information을 파악해야 한다.
Model
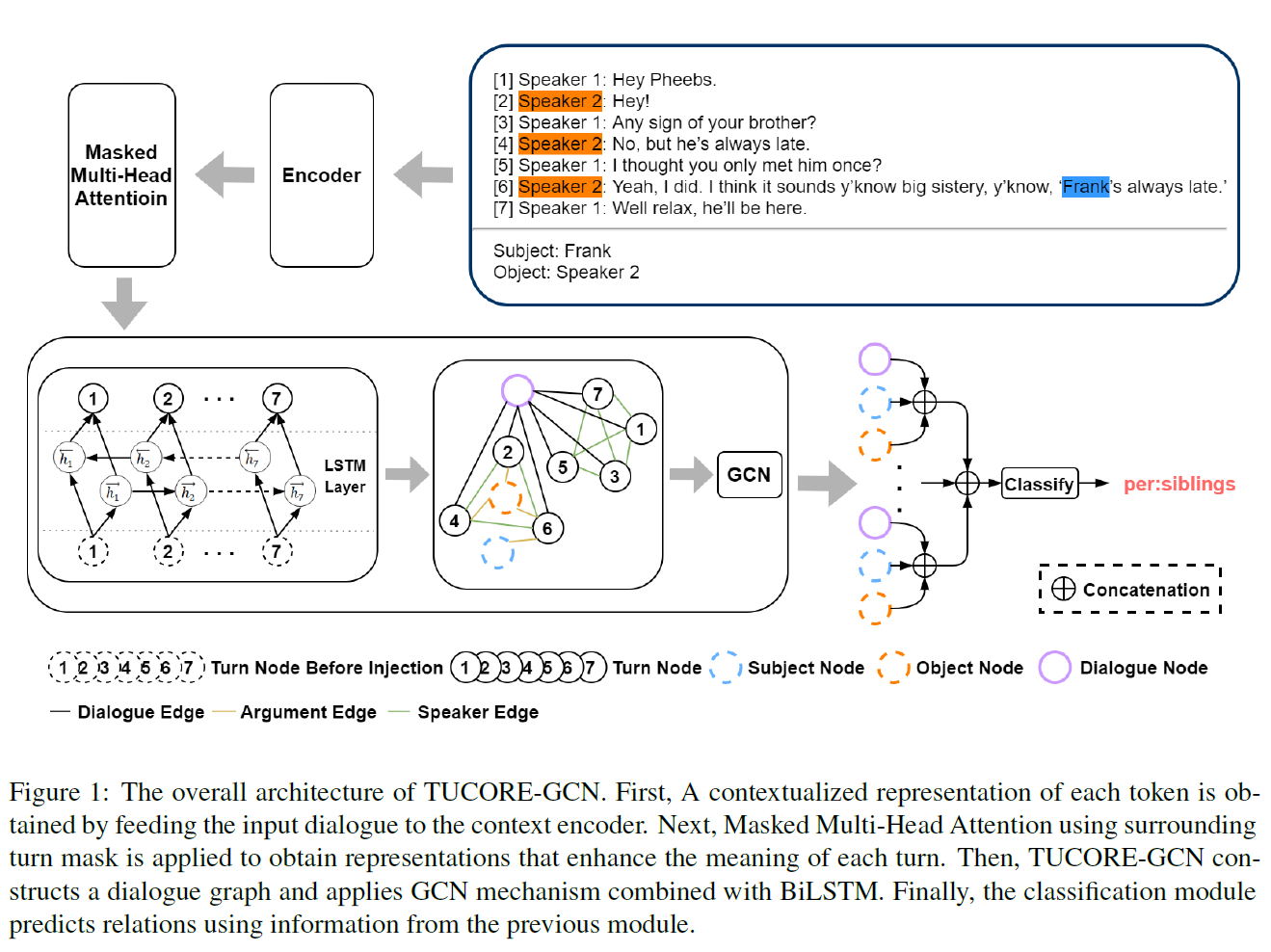
Figure 1은 TUCORE-GCN의 전체적인 구조이다. 모델은 4개의 모듈(Encoding module, turn attention module, dialogule graph with sequential nodes module, classification module)로 이루어져있다.
1. Encoding Module
Input sequence는 BERT 모델을 따른다. Dialouge 와 argument pair 이 주어졌다고 하자. 이 때 와 는 각각 speaker ID와 번 째 text를 의미하고, 은 전체 turn의 수를 의미한다.
BERT의 입력으로 을 구성하는데, 이 때 는
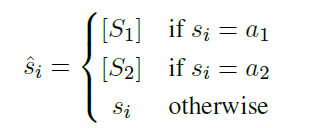 을 의미한다. 과 는 special token이며, 은 speaker id가 argument인 과 같을 때, 은 speaker id가 와 같을 때를 의미한다. 는 그 이외의 경우로, speaker id가 argument pair와 같지 않는 경우를 의미한다.
을 의미한다. 과 는 special token이며, 은 speaker id가 argument인 과 같을 때, 은 speaker id가 와 같을 때를 의미한다. 는 그 이외의 경우로, speaker id가 argument pair와 같지 않는 경우를 의미한다.
다음으로, 와 를 separator token [SEP]로 이어붙였는데, 여기서 과 는 가 어떤 speaker id 와 같을 경우 로 치환한 것을 의미하며, speaker id가 아닐 경우에는 그 자체를 의미한다.
최종적인 input sequence는 이다. Speaker
Speaker이 변하고 있다는 정보를 모델에 주기 위해서 token representations에 speaker embedding을 추가로 제공한다. Speaker Embedding은 는 speaker embedding layer을 표현한다. 은 인 token, 인 의 각 , 은 speaker embedding이 적용되지 않은 layer에 추가된다.
다음으로, speaker 정보를 포함하고 있는 token representations은 encoder의 input으로 들어가게 되어 speaker-sensitive token representations을 추출하는데 사용된다. Encoder은 BERT, 또는 BERT 계열 모델들이 사용된다.
Input Representation of TUCORE-GCN
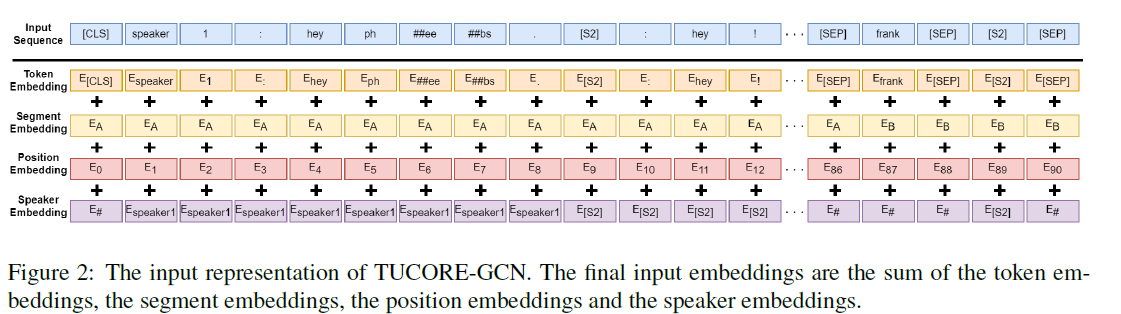
Input sequence는 다음과 같이 표현할 수 있다. BERT의 기본적인 input sequence에 각 speaker과 관련된 정보를 제공하기 위한 speaker embedding이 추가된다. 최종적인 input은 token embedding, segment embedding, position embedding, speaker embedding의 합이다.
Code
class TUCOREGCNDataset(IterableDataset):
def __init__(self, src_file, save_file, max_seq_length, tokenizer, n_class, encoder_type):
super(TUCOREGCNDataset, self).__init__()
.
.
.
if encoder_type == "BERT":
features = convert_examples_to_features(examples, max_seq_length, tokenizer)
else:
features = convert_examples_to_features_roberta(examples, max_seq_length, tokenizer)
TUCOREGCNDataset 에서 input sequence를 만드는 코드를 확인할 수 있다. convert_examples_to_features 또는 convert_examples_to_features_roberta 함수가 Encoder Module의 input sequence를 만드는 부분이다.
convert_examples_to_features 함수에는 tokenize 함수가 존재하는데, 이 함수를 살펴보자. 전체 코드는 아래와 같다.
def tokenize(text, tokenizer, start_mention_id):
speaker2id = {'[unused1]' : 11, '[unused2]' : 12, 'speaker 1' : 1, 'speaker 2' : 2, 'speaker 3' : 3, 'speaker 4' : 4, 'speaker 5' : 5, 'speaker 6' : 6, 'speaker 7' : 7, 'speaker 8' : 8, 'speaker 9' : 9}
D = ['[unused1]', '[unused2]', 'speaker 1', 'speaker 2', 'speaker 3', 'speaker 4', 'speaker 5', 'speaker 6', 'speaker 7', 'speaker 8', 'speaker 9']
text_tokens = []
textraw = [text]
for delimiter in D:
ntextraw = []
for i in range(len(textraw)):
t = textraw[i].split(delimiter)
for j in range(len(t)):
ntextraw += [t[j]]
if j != len(t)-1:
ntextraw += [delimiter]
textraw = ntextraw
text = []
speaker_ids = []
mention_ids = []
mention_id = start_mention_id
speaker_id = 0
for t in textraw:
if t in ['speaker 1', 'speaker 2', 'speaker 3', 'speaker 4', 'speaker 5', 'speaker 6', 'speaker 7', 'speaker 8', 'speaker 9']:
speaker_id = speaker2id[t]
mention_id += 1
tokens = tokenizer.tokenize(t+" ")
for tok in tokens:
text += [tok]
speaker_ids.append(speaker_id)
mention_ids.append(mention_id)
elif t in ['[unused1]', '[unused2]']:
speaker_id = speaker2id[t]
mention_id += 1
text += [t]
speaker_ids.append(speaker_id)
mention_ids.append(mention_id)
else:
tokens = tokenizer.tokenize(t)
for tok in tokens:
text += [tok]
speaker_ids.append(speaker_id)
mention_ids.append(mention_id)
return text, speaker_ids, mention_ids위 코드에서 text를 token으로 만들고, 각 발화의 speaker은 누구인지, 몇번 째 발화인지 표현하는 코드는
for t in textraw:block 이다. 하나씩 살펴보자.
for t in textraw:
if t in ['speaker 1', 'speaker 2', 'speaker 3', 'speaker 4', 'speaker 5', 'speaker 6', 'speaker 7', 'speaker 8', 'speaker 9']:
speaker_id = speaker2id[t]
mention_id += 1
tokens = tokenizer.tokenize(t+" ")
for tok in tokens:
text += [tok]
speaker_ids.append(speaker_id)
mention_ids.append(mention_id)
.
.
.
위 block에서는 t가 speaker일 경우(에서 일 경우) tokenize 하는 과정을 나타낸다. speaker_ids는 현재 speaker의 정보(speaker 1의 경우에는 1), mentions_ids에는 turn(몇번 째 발화인지)에 대한 정보, text에는 input t를 tokenize 한 결과를 추가한다. 단, t를 tokenize 했을 때 여러 개의 token으로 표현될 수 있기 때문에, token의 개수만큼 text, speaker_ids, mention_ids에 값들이 추가된다.
for t in textraw:
.
.
.
elif t in ['[unused1]', '[unused2]']:
speaker_id = speaker2id[t]
mention_id += 1
text += [t]
speaker_ids.append(speaker_id)
mention_ids.append(mention_id)
.
.
.위 block은 t가 unused token인 경우이다. 무시할 발화라고 생각하자.
for t in textraw:
.
.
.
else:
tokens = tokenizer.tokenize(t)
for tok in tokens:
text += [tok]
speaker_ids.append(speaker_id)
mention_ids.append(mention_id)마지막은 t가 일반적인 텍스트인 경우이다. speaker_id와 mention_id는 위 두 block에서 이미 수정되었기 때문에 특별한 변화 없이 추가한다.
2. Turn Attention Module
Turn context을 잘 표현하는 representation을 얻기 위해서, Masked Multi-Head Self-Attention을 encoder의 output에 적용하였다. Mask로 surrounding turn mask을 활용했고, 이를 window라고 칭했다. Surround turn window size 는 hyper-parameter로, 어떤 turn의 발화를 살펴볼 때, 해당 turn을 중심으로 함께 살펴볼 앞, 뒤 turn의 수를 나타낸다.
이 논문에서는 surrounding turn mask을 아래와 같이 표현했다.
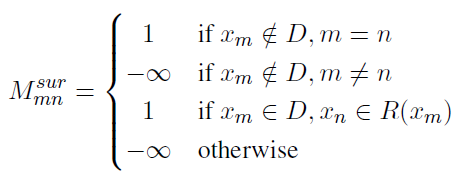
i번째 Token representations 는 token 에서 범위로 표현하며, 이 때 이다. 으로 의 모음으로 볼 수 있다.
1)
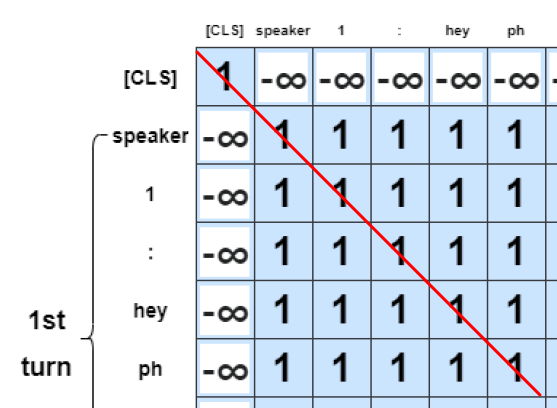
if
은 발화에 token이 포함되지 않지만, self-attention을 진행할 때 바라볼 또다른 token 이 서로 같을 때, 1이다.
2)
if
은 발화가 현재 바라보고 있는 token 에서 window size 만큼 앞 뒤의 발화에 token 이 속할 때를 말한다.
예를 들어서,

window size c = 1일 때를 가정하자. 현재 바라보고 있는 발화가 turn [2]의 발화인 "Hey!" 인 경우, 이 "Hey Peebs.", "Hey!", "Any sign of your brother?" 중 하나의 token이라면 조건 이 성립한다. 이를 수식 으로 표현한다.
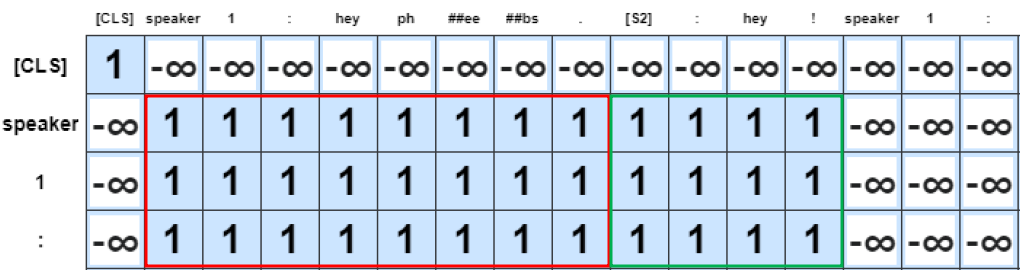
그림으로 표현하면 위와 같다.
3)
1)과 2)에 속하지 않는 경우에는 이다.
Code
class MultiHeadAttention(nn.Module):
''' Multi-Head Attention module '''
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(temperature=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6)MaskedMultiHeadAttention module은 일반적인 MultiHeadAttention과 같았다.
class ScaledDotProductAttention(nn.Module):
''' Scaled Dot-Product Attention '''
def __init__(self, temperature, attn_dropout=0.1):
super().__init__()
self.temperature = temperature
self.dropout = nn.Dropout(attn_dropout)
def forward(self, q, k, v, mask=None):
attn = torch.matmul(q / self.temperature, k.transpose(2, 3))
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = self.dropout(F.softmax(attn, dim=-1))
output = torch.matmul(attn, v)
return output, attn
다만, attention 과정에서 mask가 씌여지는 연산이 이루어진다.
def mention2mask(mention_id):
slen = len(mention_id)
mask = []
turn_mention_ids = [i for i in range(1, np.max(mention_id) - 1)]
for j in range(slen):
tmp = None
if mention_id[j] not in turn_mention_ids:
tmp = np.zeros(slen, dtype=bool)
tmp[j] = 1
else:
start = mention_id[j]
end = mention_id[j]
if mention_id[j] - 1 in turn_mention_ids:
start = mention_id[j] - 1
if mention_id[j] + 1 in turn_mention_ids:
end = mention_id[j] + 1
tmp = (mention_id >= start) & (mention_id <= end)
mask.append(tmp)
mask = np.stack(mask)
return mask음.. mask 생성 과정은 해석이 안 된다.
3. Dialogue Graph with Sequential Nodes Module
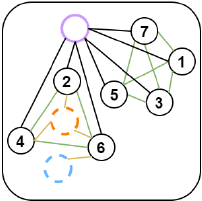
Dialogue-level information(대화 문맥 정보, e.g. 각 turn과 arguments, turn간의 상호작용)을 표현하기 위해서 Dialogue Graph를 구성하였다.
1) Node
-
Dialogue node
- 전체적인 Dialogue information을 포함.
- Turn attention module의 [CLS] token을 feature로 사용 -
Turn node
- Dialogue 내에서 각 turn의 정보 (turn의 개수만큼 생성)
- turn feature은 Turn attention module의 output에서 에 해당하는 token representations의 평균값을 사용 -
Subject node
- argument 1
- Turn attention module의 에 해당하는 token representations의 평균값을 사용 -
Object node
- argument 2
- Turn attention module의 에 해당하는 token representations의 평균값을 사용
2) Edge
-
Dialogue edge
Turn node와 dialogue node를 연결하는 edge이다. Dialogue node가 turn-level 정보를 활용하여 학습할 수 있게 한다. -
Argument edge
Turn과 arguments 간의 상호작용을 표현하기 위해서 argument가 발화 ()에 포함되어 있다면 turn node와 argument node ( subject node, object node)를 연결한다. -
Speaker edge
같은 speaker가 다른 turn에 말한 것을 표현하기 위해, speaker가 같은 turn node들을 speaker edge로 모두 연결한다.
다음으로, Graph Convolutional Network (GCN)을 적용하여, neighbors node의 정보를 활용해 각 node의 값을 갱신했다.
GCN을 적용하기 전, turn node에 순서 정보를 부여하기 위하여 turn node는 bi-LSTM layer을 통과했다. GCN layer의 node 가 주어졌을 때, 와 는 각각 node에 순서 정보를 넣기 전과 후를 표현한다.
는 아래와 같은 식으로 표현할 수 있다.
여기서 는 turn node를 의미하고, 는 양방향의 hidden states를 concate하여 순서 정보가 추가된 turn node feature이다.
, 이다. 이 때, 는 차원을 의미한다. 그렇다면, graph convolution operation은 아래와 같이 정의한다.
여기서 는 각각의 type을 갖는 edge를, 는 type dege로 연결된 node 의 neighbors를 의미한다. 이 때, , 의 차원을 갖는다.
Code
graph_big = dgl.batch(graphs)
output_features = [features]
for layer_num, GCN_layer in enumerate(self.GCN_layers):
start = 0
new_features = []
for idx in num_batch_turn:
new_features.append(features[start])
lstm_out = self.LSTM_layers[layer_num](features[start+1:start+idx-2].unsqueeze(0))
new_features += lstm_out
new_features.append(features[start+idx-2])
new_features.append(features[start+idx-1])
start += idx
features = torch.stack(new_features)
features = GCN_layer(graph_big, {"node": features})["node"]
output_features.append(features)LSTM layer을 통과하고 GCN layer을 통과하는 것을 볼 수 있다. 근데, 한 줄 한줄은 해석이 안 된다...
4. Classification Module
Dialogue node, subject node, object node를 concatenate 하였다. 더 나아가서, GCN의 각 abstract level features를 활용하기 위해 GCN layer의 hidden states 또한 concatenate 했다.
수식으로 아래와 같이 표현한다.
G늰 GCN layer의 수이고, d, s, o는 각각 dialogue node, subject node, object node를 나타낸다. 차원을 갖는다고 할 때, argument 간의 각 relation type 이 존재할 확률은 이다.
Classification loss를 계산하기 위하여 Cross-entropy loss를 활용하였다.
fea_idx = 0
for i in range(len(graphs)):
node_num = graphs[i].number_of_nodes('node')
intergrated_output = None
for j in range(self.gcn_layers + 1):
if intergrated_output == None:
intergrated_output = output_features[j][fea_idx]
else:
intergrated_output = torch.cat((intergrated_output, output_features[j][fea_idx]), dim=-1)
intergrated_output = torch.cat((intergrated_output, output_features[j][fea_idx + node_num - 2]), dim=-1)
intergrated_output = torch.cat((intergrated_output, output_features[j][fea_idx + node_num - 1]), dim=-1)
fea_idx += node_num
graph_output.append(intergrated_output)
graph_output = torch.stack(graph_output)
pooled_output = self.dropout(graph_output)
logits = self.classifier(pooled_output)
logits = logits.view(-1, self.num_labels)
if labels is not None:
loss_fct = BCEWithLogitsLoss()
labels = labels.view(-1, self.num_labels)
loss = loss_fct(logits, labels)
return loss, logits
else:
return logits
Experiment
Emotion Recognition in Conversations
Result
대화에서 발화가 서로 인접해있을 때, 비슷한 emotion을 보이는 경향이 있다. 이를 emotional consistency라고 한다.
TUCORE-GCN 모델에서 encoder module의 speaker embedding을 제거했을 때, F1 score이 하락했다. 이러한 성능 하락은 dialogue를 encoding 할 때, speaker가 변화는 정보를 제공하는 것이 더 좋은 representation을 만드는 것을 알 수 있다.
다음으로, turn attention module을 제거했다. 즉, encoder module의 output에 dialogue graph를 바로 적용한 case이다. Turn attention이 존재하지 않을 때도 F1 score이 하락했는데, 이를 통해 turn attention module이 turn의 representation을 포착하는데 도움을 주는 것을 알 수 있었다.
마지막으로, turn node를 위한 turn-level BiLSTM을 제거했다. 구체적으로, turn node에 순서 정보를 제공하지 않고 GCN을 적용했다. 이 또한 성능이 하락하였는데, 이를 통해 sequential node의 특성을 반영하였을 때 graph가 학습하는데 도움이 되는 것을 알 수 있었다.
