📈 Crawling - Server DB 자동화 프로그램 구성하기
💡 회사 연수기간에 팀 프로젝트 개발을 진행하면서 Scheduling을 통해 데이터 크롤링 및 서버 DB 업데이트 자동화 프로세스를 구축하고 개발해보았습니다. 이에 대해 정리한 내용입니다.
신입 개발자로서 연수 기간에 개발 과제를 수행하는데 있어서 많은 제약이 있었고 아쉽지만 이번 내용에도 심도있는 기술 내용은 없습니다.
단지, 팀 프로젝트를 수행하면서 구축했던 내용들을 정리함으로써 제 걸로 만들고 싶었고 개발과제를 수행하면서 느꼈던 부족함에 대해서도 정리해보고자 작성하게 되었습니다.
프로젝트 주제는 Quant 투자 기반 종목 추천 서비스 입니다.
🔗Github Link
📌 Program Architecture
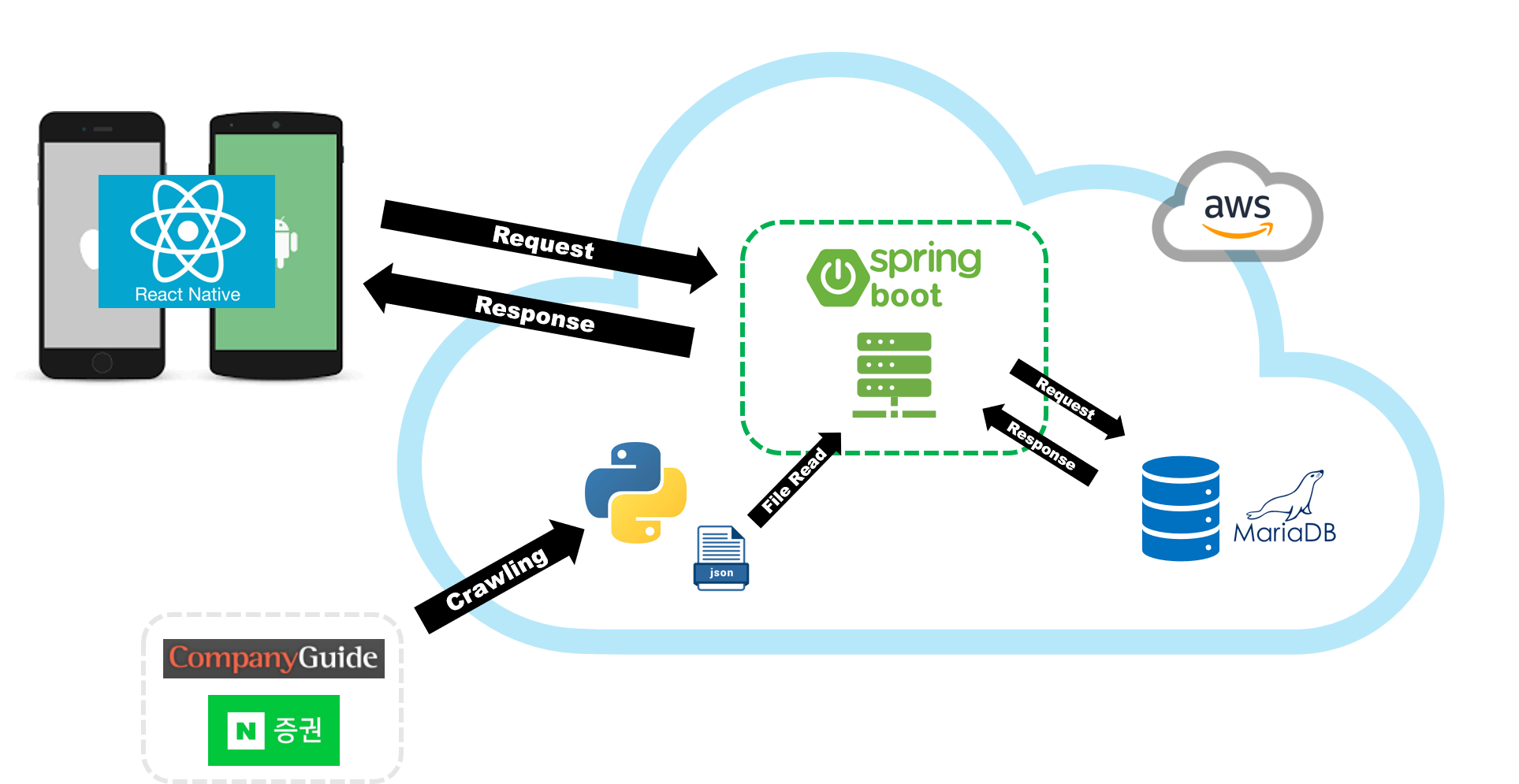
- ✔️ Front: React-Native
- ✔️ Back: Spring Boot
- ✔️ DB: MariaDB(AWS), h2 database(개발용)
- ✔️ Crawling: Python
- ✔️ Cloud: AWS EC2/RDS/S3
아키텍처에서 저는 주로 백엔드 개발을 맡았습니다. 백엔드 개발에 있어서 제가 그나마 다룰줄 아는 언어는 java였고 Spring Boot를 이용해 개발했습니다.
연수 과정에 있어서 메인은 React-Native였기 때문에 이를 이용해 모바일 화면 페이지 중 수치 적용 페이지 등 몇몇 페이지를 맡아서 개발했습니다. (지금은 JS 메인 언어로 공부하고 개발해볼 정도로 매력적이고 재밌더라구요. 향후 node.js 개발도...)
이번 프로젝트 개발에서 백엔드 개발에 있어서 가장 중요한 점은 주식 및 재무 데이터의 수집 및 서버DB 적재의 자동화였습니다. 시가, 종가 등 매일 변화하는 데이터와 분기, 반기, 연마다 실적발표로 데이터가 주기적으로 변하는데 이를 매일 수동으로 python 코드 돌리고 DB에 적재한다고 생각하면 정말 OMG! 입니다.
팀원들과 상의하면서 그리고 나름 혼자 고민해보면서 이를 자동화하는 프로세스를 구축하였고 이대로 클라우드 서버에 배포하기로 결정했습니다. 프로세스는 이렇습니다.
- ✔️ CompanyGuide, 네이버증권 등 웹사이트에서 필요한 데이터를 크롤링하는 python 코드 작업 수행 > 결과값으로 JSON 형식 파일 반환
- ✔️ 서버에서 JSON 파일을 읽어들여 DB에 저장 (Spring Boot 개발)
- ✔️ RESTful API을 통해 Front에 요청/응답
📌 Crawling 프로그램 구성
Crawling 자체에 대한 코드는 Github Repo에 있습니다. (위 링크 참고)
백엔드 프로세스 자동화에 초점을 맞춰 글을 작성하였기에 코드에 대한 자세한 언급은 생략하겠습니다. 🙏🙏
def JsonWrite(fn, data):
#json 파일로 저장
with open(fn, 'w', encoding='UTF-8-sig') as make_file:
json.dump(data,
make_file,
indent="\t",
cls=NpEncoder,
ensure_ascii=False)
# 날짜 지정(파일명 설정을 위해)
now = datetime.datetime.now()
nowDate = now.strftime('%Y_%m_%d')
nds = str(nowDate)
# 파일명(위치까지) 설정 - *절대경로 주의*
fn1 = '/home/ec2-user/app/diq/data/' + str(nds) + '/dailyUpdateData.json'
# 디렉토리 생성 - *절대경로 주의*
dn = '/home/ec2-user/app/diq/data/' + str(nds)
if os.path.isdir(dn):
shutil.rmtree(dn)
os.mkdir(dn)
#json 파일로 저장
JsonWrite(fn1, result)여기서 중요한 것은 Cloud Server에 코드를 배포할텐데 Cloud Server는 Linux 기반이라 개발환경과 다르게 작성해야 하는 곳이 있습니다.
특히 파일경로를 지정해주는 곳입니다. Linux 환경에서는 절대경로로 지정해줘야 프로그램이 돌아가기 때문에 이 점 유의해야 합니다.
📌 Back-End 개발
마찬가지로 Back-End 자체에 대한 개발 코드는 Github Repo에서 참고하시면 됩니다. 여기에선 Scheduling에 관한 내용만 언급합니다. 🙏🙏
Spring에서 Scheduling을 적용해주는 라이브러리를 제공해주고 있습니다. Linux의 crontab과 사용법이 비슷합니다.
@SpringBootApplication
@EnableScheduling
public class QuantApplication {
public static void main(String[] args) {
SpringApplication.run(QuantApplication.class, args);
}
}먼저 프로그램을 구동시켜주는 Application 클래스에 @EnableScheduling를 적용합니다.
// 1. QuantDataController.java, CompanyDetailController.java
@Scheduled(cron = "0 30 0 * 2,5,7,11 *", zone = "Asia/Seoul")
public ResponseEntity<String> bulkUpdate()
throws JsonParseException, JsonMappingException, IOException {
//해당 Logic...
}
// 2. DailyPriceController.java
@Scheduled(cron = "0 30 16 * * 1-5", zone = "Asia/Seoul")
public ResponseEntity<String> bulkUpdate()
throws JsonParseException, JsonMappingException, IOException {
//해당 Logic...
}Controller에 해당 메서드에 @Scheduled을 적용해 스케줄링 시간을 정하면 됩니다.
- 첫번째 재무데이터에 대한 크롤링을 위해 매분기마다 실적 발표 시점을 기준으로 자동화시점을 지정하였습니다. (2, 5, 7, 11월에 새벽0시 30분에 메서드가 실행되도록 설정하였습니다.)
- 두번째 종가 데이터 크롤링을 위해 장마감 시간을 기준으로 여유있게 지정하였습니다. (
1-5: 거래일인 월~금요일/* *: 일 월 상관없이 /0 30 16: 오후 4시 30분 설정) - 자세한 문법은 아래 링크 걸어두었습니다!
여유있게 시점을 잡은 이유는 2000개가 넘는 주식 종목을 크롤링하는데 30분 정도 소요되기 때문입니다. 이 소요시간을 고려해 Crawling 스케줄링 시점과 WAS 동작 시점 간에 30분 차이를 두었습니다.
Linux
crontab과 사용법에 있어서 차이점이 있으니 주의해주세요.
📌 Cloud Server에서 프로그램 연동
Cloud Server로 AWS를 사용했습니다.
Github에 소스코드를 push하면 Github - Travis CI - CodeDeploy - EC2로 이어지는 CI/CD 자동화 프로세스를 통해 EC2내 미리 지정해둔 디렉토리로 배포가 진행이 되고 Spring Boot가 실행이 됩니다.
$crontab -e (scheduling할 명령어 설정, vim형식)
$crontab -l (scheduling했던 설정 내용들 확인)
0 0 15 2,5,8,11 * python3 /home/ec2-user/app/diq/web_crawling_general.py
0 16 * * 1-5 python3 /home/ec2-user/app/diq/web_crawling_Jongga.pycrontab -e 명령어를 입력하면 vim 편집기 형식으로 스케줄링할 명령어를 지정할 수 있습니다.
주의할 점은, python을 실행할 때 python v3이 설치되어 있다면 python 대신 python3을 입력해야 python코드가 실행됩니다.
여기까지 설정이 완료되면 자동 크롤링 및 DB 적재 프로세스가 완료됩니다.
종가 데이터를 예시로 들면
- 1-5(월-금) 16:00에 종가데이터 크롤링 프로그램 자동 실행
- 크롤링 완료되면
dailyUpdateData.json파일 반환 - 1-5(월-금) 16:30에 Spring Boot Scheduling에 의해 자동으로 JSON파일을 읽고 DB 저장
📌 정리
- 서버단에서 Scheduling을 통해 원하는 작업을 자동화 가능.
- Linux:
crontab, Spring:@ScheduledAnnotation을 통해 설정 가능 - OS 환경에 따라 경로 설정 등 다르게 적용해야 하는 부분 고려
- Linux:
- python 기반 웹프레임워크를 이용해 한번에 적용 가능하지 않을까 하는 생각(Django, Flask 등)
📖 Reference
.jpg)
3개의 댓글

좋은 내용 감사합니다 멋지네요! 저도 퀀트 공부하는 중인데, https://quantpro.co.kr/ 해당 사이트 퀀트 내용 어떤지 의견주시면 감사하겠습니다!

초보자 입니다 궁금한점이 파이썬에서 크롤링 데이터를 바로 DB에 저장하고 spring에서 가져오는식으로
하지 않는 이유가 궁금합니다.
리눅스 스크립트로 파이썬 크롤링을 매일 자동화 시키면 되는거 아닌가요?