Review: Neural Network
- weighted edges로 연결된 유닛들의 네트워크
- 각 유닛 계산 : z=h(wx+b)
- x : 인풋- z : 아웃풋
- w : 가중치(파라미터)
- b : bias
- h : activation function
Deep Reinforcement Learning
- dnn으로 다음과 같은 것들을 나타냄 :
- value function- policy
- model
- SGD로 loss function을 최적화시킴
Deep Q-Networks (DQNs)
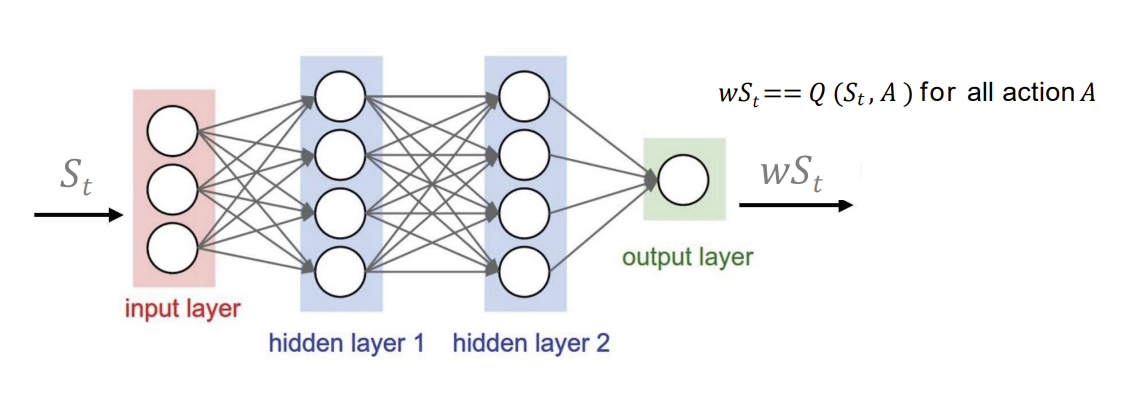
- 가중치 w로 Q 네트워크를 state-action value function으로 표현함
Deep Q-Network Training
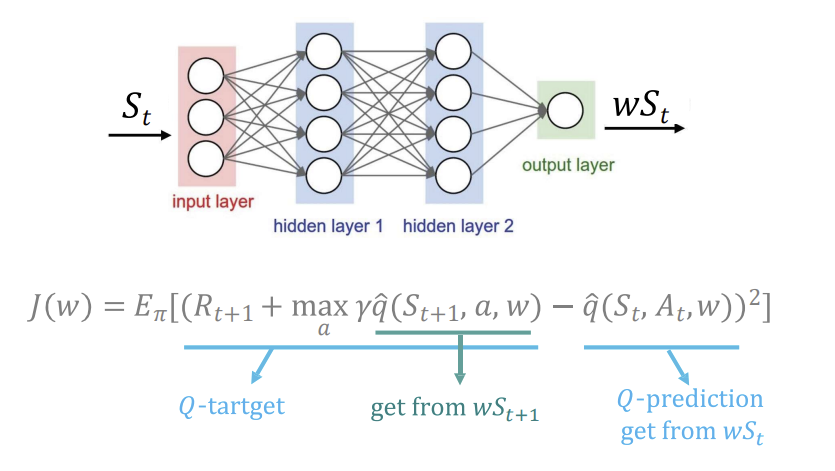
- 입력 상태 S : 신경망의 입력으로 현재 상태 s가 들어감. 이 상태는 신경망의 은닉층을 거쳐 모든 가능한 행동에 대한 Q값으로 매핑됨.
- 출력층에서의 Q 값 예측 : 상태 s에 대해 가능한 각 행동 a에 대한 Q값을 예측함. Q 예측은 현재 네트워크가 예측한 Q값으로, 이 값을 기반으로 학습함
- Q-타겟 계산 : Q 타겟은 강화 학습의 목표로, 미래의 보상을 반영하여 예측하는 값임.
- 손실 함수 : 타깃과 예측 사이의 오차 제곱임. 이 값을 최소화하도록 학습함.
Convergence issues

- 현재 Q함수 근사값
- ^q는 현재 신경망이 예측하는 상태-행동 가치 함수의 근사값을 의미함. - 손실함수 최소화
- Q 네트워크는 손실 함수를 최소화하는 방향으로 학습됨- 손실함수는 타겟값과 예측 값의 오차 제곱을 줄이는 방향으로 학습
- 수렴 문제
- 테이블 기반 표현을 사용할 때는 optimal q에 수렴할 가능성이 높지만, 신경망을 사용할 경우 발산할 수도 있음. why?
- 샘플 간의 상관관계 : 심층 신경망은 인접한 샘플 간의 상관관계 때문에 학습이 불안정해질 수 있음. 이는 일반적으로 replay buffer를 사용하여 해결
- 비정상 타겟 : 학습 도중 Q 타깃이 지속적으로 변화하는데, 이러한 변화로 인해 네트워크가 안정적으로 수렴하지 못할 수 있음. 이를 위해 타겟 네트워크를 별도로 두어 일관된 타겟을 제공하는 방법이 사용됨.
Correlations between samples
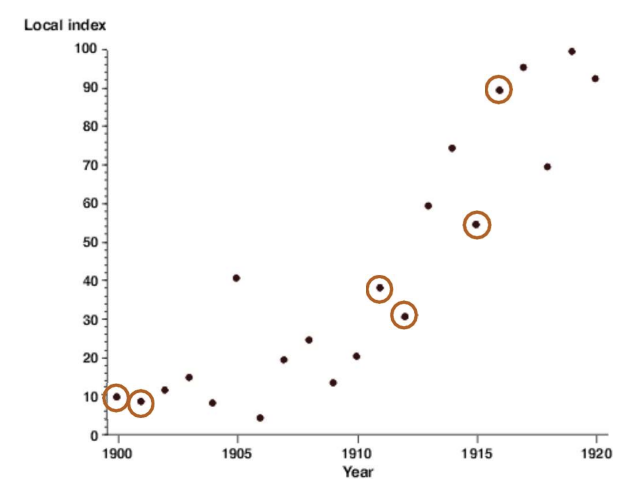
- 샘플 간 상관관계
- 강화학습에서 샘플이 연속적인 상태-행동-보상 시퀀스에서 생성되는 경우, 데이터 간 상관관계가 높아질 수 있음- 그래프에서 시간(연도)에 따른 지표의 변화를 나타내며, 특정 패턴을 따르는 점들이 상관관계가 있다는 것을 보여줌. 연속된 샘플이 서로 비슷한 패턴을 가지면 네트워크가 이를 독립적인 데이터로 간주하지 못해 학습의 불안정성이나 편향이 생길 수 있음
- 경험 재생의 필요성
- 이러한 샘플 간 상관관계를 줄이기 위해 Experience replay라는 기법을 자주 사용함.- 경험 재생은 네트워크가 샘플을 무작위 순서로 학습하게 하여 인접한 샘플 간 상관관계를 줄이고 데이터를 더 독립적으로 학습할 수 있도록 도와줌
- 의미
- 상관관계가 높은 샘플을 학습하는 경우 네트워크가 특정 경향에 치우쳐 학습할 수 있어 수렴이 어려워질 수 있음- 무작위 샘플링을 통해 신경망이 더 다양한 경험을 학습함으로써 더 안정적이고 일반화된 학습이 가능함
Non-stationary targets
- 아래쪽 식에서는 목표가 R + 감마 곱해진 max로 바뀜. 이는 시간 단계가 지나면서 목표값이 계속 갱신 되는 것을 보여줌. - 현재 추측 값을 이용하여 또 다른 추측을 업데이트함. 즉 target과 prediction이 모두 불완전한 추정치임을 강조
- prediction Q를 업데이트할 때 target Q도 영향을 받게 되어 비정상적인 학습 목표가 발생.
- 안정적인 학습을 위해 target Q와 prediction Q를 분리해야 함.

당근을 보고 따라가는 당나귀의 모습으로, 당근은 끊임없이 앞에 있고 당나귀는 도달할 수 없는 목표를 향해 움직이는 상황임. 이는 Non-stationary target의 개념을 비유적으로 표현한 것임. 당나귀가 목표를 향해 계속 나아가지만, 목표가 고정되지 않고 계속 변화하는 상황은 학습 목표가 끊임없이 바뀌는 딥러닝의 상황과 유사함.
Deep Q-Networks (DQN)
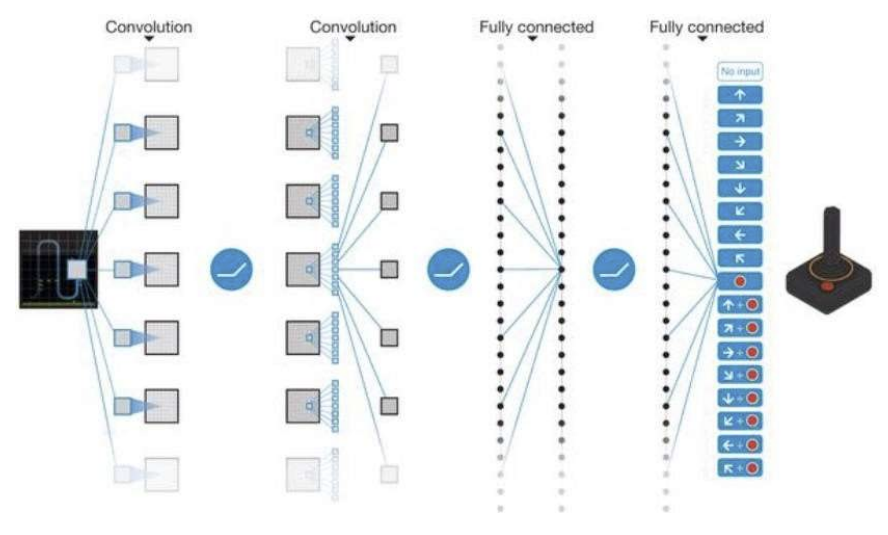
- DNN :
- DQN은 딥러닝을 활용한 강화학습 알고리즘으로 Q 함수를 근사하기 위해 깊은 신경망을 사용함. 이로 인해 복잡한 상태 공간에서도 효율적으로 Q 값을 계산할 수 있음 - Experience Replay
- 경험 재생은 학습 과정에서 발생하는 샘플 간 상관관계를 줄이기 위해 도입된 기법이다. 에이전트가 겪은 경험을 일정량 저장해두었다가 랜덤으로 샘플링하여 학습에 사용하는 방식으로, 샘플 간의 상관성을 줄여 안정적인 학습이 가능하도록 함- 학습에 사용되는 샘플들이 독립적이고 고르게 분포되도록 하여 강화학습의 성능을 향상시킴
- Fixed Target
- 비정상적인 학습 목표를 해결하기 위한 방법임. 학습하는 동안 목표가 계속 바뀌는 문제를 해결하기 위해 일정 기간 고정된 Q 타깃 값을 사용하여 학습의 안정성을 높임- 예측과 목표의 변화가 줄어들어 비정상적인 목표로 인한 학습 불안정 문제를 해결할 수 있음
1) Deep Neural Networks
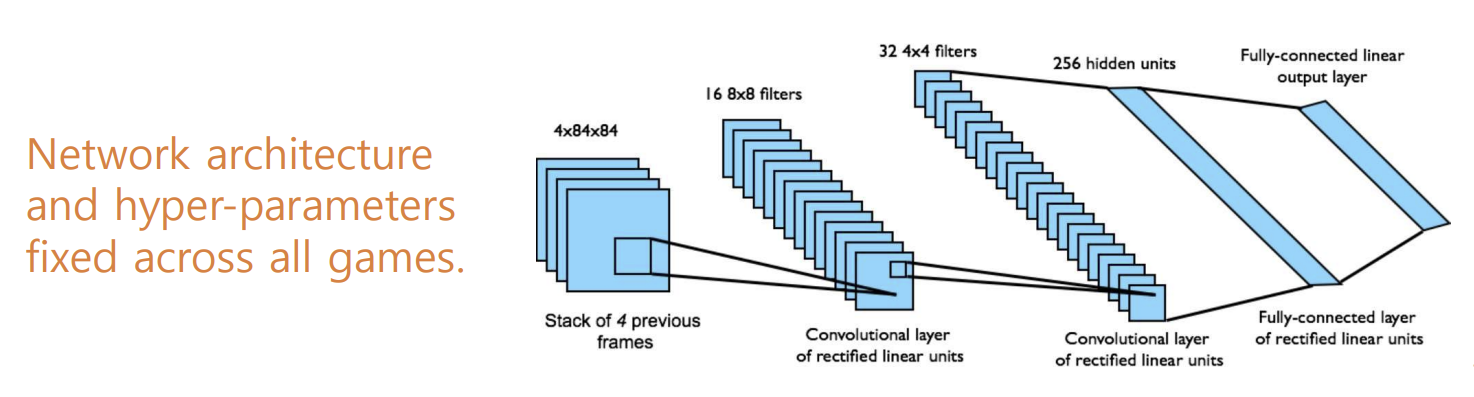
- End-to-End Learning
- 픽셀 상태(s)에서 Q값을 학습하는 엔드투엔드 방식으로 설계됨. 즉 입력된 원시 픽셀 데이터를 통해 바로 Q 값을 예측할 수 있도록 하는 구조임 - 인풋 state
- 입력 상태는 과거 네 개의 프레임을 스택으로 쌓아 하나의 입력으로 사용함. 이렇게 하여 시간의 흐름에 따른 정보를 신경망이 파악할 수 있도록 도와줌. - 아웃풋
- 출력은 Q(s,a)로, 이는 18개의 조이스틱/버튼 조합에 대한 Q 값을 나타냄. 즉, 각 행동에 대한 가치를 추정하여, 현재 상태에서 가장 적합한 행동을 선택할 수 있도록 함 - 리워드
- 보상은 각 스텝에서 점수의 변화를 기반으로 함. 이를 통해 네트워크가 행동의 결과에 따라 보상을 학습하여 더 나은 행동을 선택하게 됨.
2) Experience Replay

- 목적 : 학습 샘플 간 상관관계를 줄이고 데이터의 독립성을 확보하는 기법
- 과정 :
- 행동 성택 : -greedy 정책을 사용하여 행동을 선택함. -greedy 는 탐험과 활용을 균형있게 조절하는 정책으로 에이전트가 새로운 행동을 시도할 확률을 설정함- 경험 저장 : 에이전트가 수행한 경험 을 리플레이 메모리 D에 저장함.
- 미니배치 샘플링 : 리플레이 메모리 D에서 랜덤 미니배치로 샘플을 뽑아 학습에 사용. 이를 통해 데이터 상관성을 줄이고 더 독립적인 샘플로 학습을 진행할 수 있음
- 손실 최적화 : Q 예측값과 Q 타깃 값 간의 MSE를 최적화하여 학습을 진행함. 이 과정에서 J(w)는 Q 값 예측 오차를 최소화하는 목적 함수임.
- 손실 함수 J(w)
- MSE를 나타내며 이 오차를 최소화하는 방향으로 학습이 진행됨.
- 오른쪽 그림은 리플레이 메모리에 저장된 경험들의 형식을 나타냄. 각각의 경험은 랜덤하게 샘플링됨
3) Fixed Target
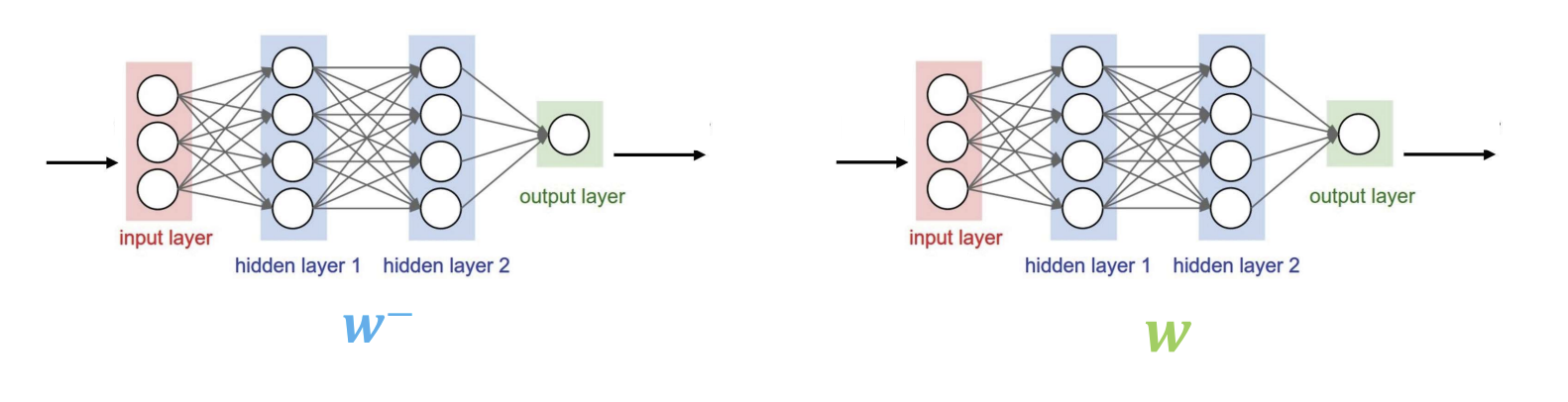
-
목적
- 진동 방지 : 목표와 예측이 동시에 변할 경우 학습이 불안정해지면서 진동이 발생할 수 있음. fixed target은 이를 방지하기 위해 고안됨 -
Q 타깃 네트워크 :
- 타깃 네트워크의 Q 값을 계산할 때 오래된 파라미터 를 사용하여 계산함. 이렇게 하면 학습이 안정화 되고, 목표 값이 갑작스럽게 변하지 않도록 함.
- 타깃 Q 값:
- 는 예측 네트워크의 파라미터 w와는 별도로 유지됨
-
손실함수 최적화
- 손실 함수는 예측 네트워크 Q 값과 타겟 네트워크 Q 값 간 MSE를 최소화하는 방향으로 최적화됨.
-
타깃 네트워크 업데이트 : 타깃 네트워크의 파라미터 는 주기적으로 예측 네트워크 파라미터 w로 업데이트됨. 이는 학습이 어느정도 진행된 후에 목표값을 변경하여 더 안정적으로 학습을 진행하도록 함
-
그림에서 왼쪽은 타깃 네트워크 , 오른쪽은 예측 네트워크 w를 나타냄. 예측 네트워크가 지속적으로 학습되는 동안 타깃 네트워크는 일정 기간 동안 고정되어있다가 주기적으로 업데이트됨


빠른 은퇴 희망