강화학습
1.Reinforcement Learning Overview
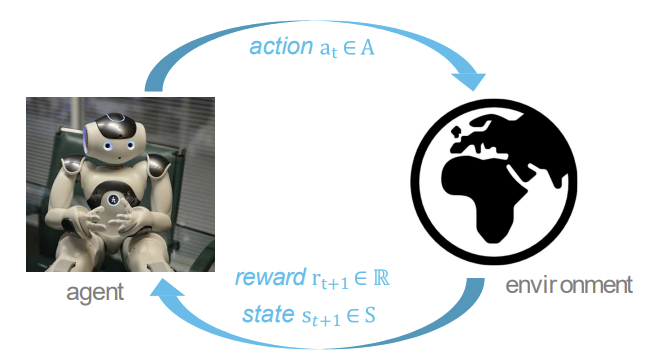
불확실성 하에서 의사 결정과 학습에 대한 과학과 공학 경험을 통해 학습하는 다양한 응용 분야에서 학습을 모델링하는 일종의 기계학습vs 다른 머신러닝 패러다임 \- 상호작용으로부터의 학습을 계산적으로 접근!(심층신경망) \- superivsor(감독)이 없고, 오직
2.Markov Decision Process
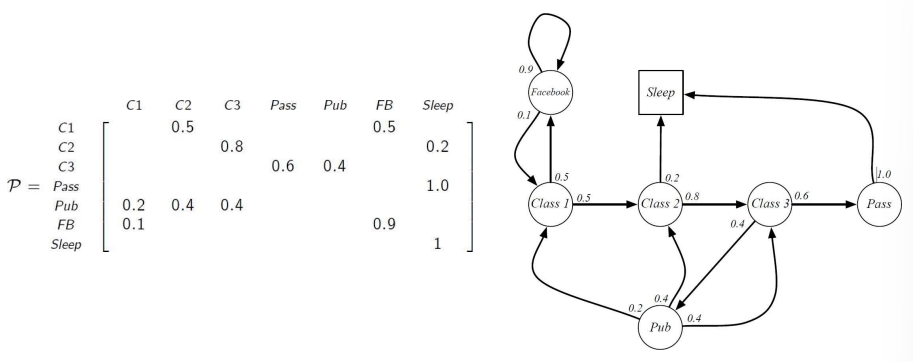
MDP는 강화학습에서 환경을 설명한다. 환경은 fully observable하고, 대부분의 RL problems는 MDP로 표현할 수 있다. optimal control(최상의 정책 만들기)은 MDP로 제어하고, Partially observable problems도
3.Model-based Planning
Planning and Learning sequential decision making의 two problems Planning : environment의 model이 알려져 있음 외적인 상호작용 없이 agent가 model을 통해 계산을 진행한다. 즉 에이전
4.Model-free Prediction

MDP 모델이 알려져 있지 않는 상황에서 특정 정책에 따른 기대되는 return을 측정해보자!Model-free Prediction (evaluation) \- 알려져있지 않은 MDP의 value function을 측정주어진 policy가 얼마나 좋은가? Model
5.Model-free Control
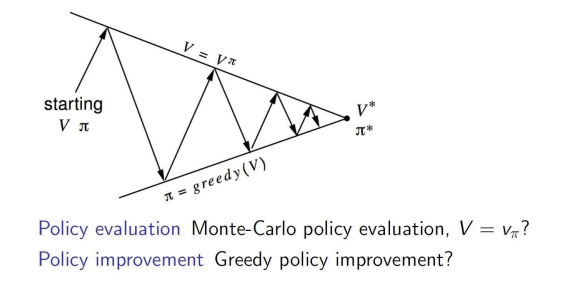
Model-free control은 MDP를 모르는 상황에서, value function을 최적화 시키는 것!MDP 모델링으로 많은 적용이 가능함 \- 장기, 헬리콥터 비행, 로봇 축구 등등... 이러한 문제들에 대해 적용가능 \- MDP 모델을 모름, but 경험
6.Value function Approximation
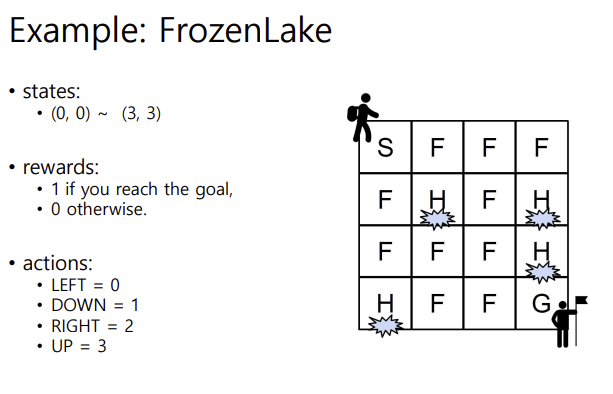
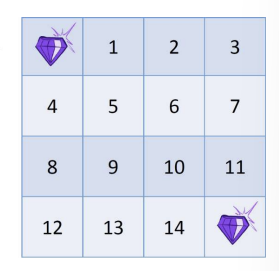
small size map의 경우에는 Q 테이블을 정하는 것이 가능함. 예를 들어 이러한 프로즌레이크 문제에서는 Q 테이블이 4 곱하기 4 (그리드) \* 4(행동) 으로, 64개의 저장공간이 필요함. 그런데 이것보다 더 커지면 어케됨???이렇게 열라 큰 문제들을 맞닥
7.Deep Reinforcement Learning
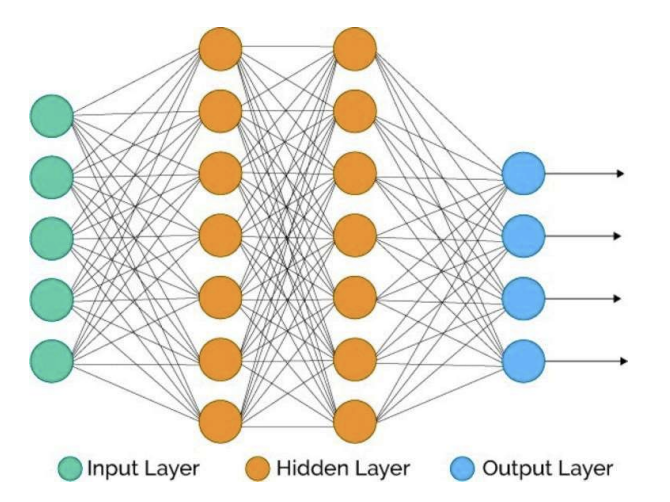
weighted edges로 연결된 유닛들의 네트워크 각 유닛 계산 : z=h(wx+b) \- x : 인풋z : 아웃풋w : 가중치(파라미터)b : biash : activation function dnn으로 다음과 같은 것들을 나타냄 : \- value funct