###강화학습 개요
Reinforcement Learning(RL)
- 불확실성 하에서 의사 결정과 학습에 대한 과학과 공학
- 경험을 통해 학습하는 다양한 응용 분야에서 학습을 모델링하는 일종의 기계학습
강화학습의 특징
- vs 다른 머신러닝 패러다임
- 상호작용으로부터의 학습을 계산적으로 접근!(심층신경망)
- superivsor(감독)이 없고, 오직 보상 시그널만 있음- 피드백이 즉각적으로 오지 않고, 지연되어 전달된다
- 시간이 매우 중요함(시간의 흐름에 따라 데이터가 변화하는 상황)
- 에이전트의 Action이 그 다음에 에이전트가 받을 데이터에 영향을 미친다
강화학습의 형식
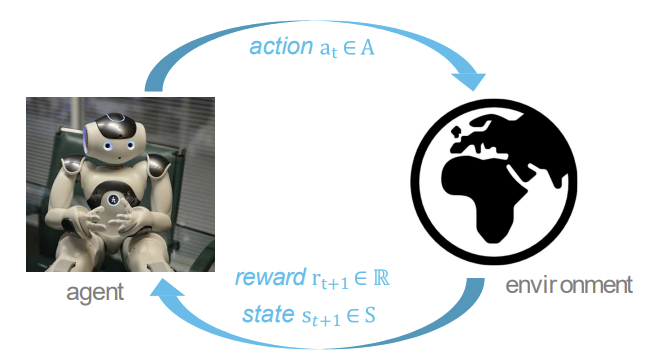
- 특정 environment에서, agent는 state를 제공받는다.
- agent는 주어진 state를 기반으로 어떤 action을 할 지 선택한다.
- agent의 action은 environment에 영향을 미쳐 특정 reward를 뱉는다.
강화학습의 기본 요소
Reward 보상
- reward 는 scalar 피드백 신호이다.
- step t에서, agent가 얼마나 잘 행동하는 지를 나타낸다.
- agent의 목표는 누적 보상의 합을 최대화하는 것이다.
Sequential Decision Making
- goal : 미래의 총 보상을 극대화하는 action을 선택하는 것
- action은 장기적인 결과를 가져올 수 있다. (즉각적 X)
- 보상이 지연될 수 있다.
- 미래에 더 큰 보상을 얻기 위해, 단기적인 보상을 포기할 수 있다.
- ex) 주식 투자 : 미래의 보상을 얻기 위해 현재 돈을 투자함
Agent and Environment
- 각각의 step t에서의 agent:
- obervation(관찰) 를 받는다.- scalar reward 를 받는다.
- action 를 행한다.
- environment :
- action 를 받는다.- observation 를 내보낸다.
- scalar reward 를 내보낸다.
- environment 단계마다 time step t가 증가한다.
History and State
- history는 observation, actions, rewards의 시퀀스이다.
- 시간 t까지의 모든 관찰 가능한 변수- = , , ,...,, ,
- State는 다음에 어떤 일을 행할지를 결정하는 데 사용되는 정보이다.
- state는 agent가 environment에서 겪었던 전체경험(history)에 기반해 정의된다.- = ()
Environment State
- Environment state 는 environment만의(관점의) 표현이다.
- 는 agent에게 보이지 않는다.
- 설령 이 가 agent에게 보이더라도, 관련 없는 정보를 포함한 형태일 것이다.
Agent State
- agent state 는 agent의 내적인(관점의) 표현이다.
- agent가 다음에 어떤 행동을 행할 지에 사용되는 데이터이다.
- 강화학습 알고리즘에서 사용되는 데이터이다.
Marcov State
Marcov State
- Marcov state는 history의 모든 유용한 정보를 포함한다. 즉, 과거의 모든 history를 요약해서, 현재 state만으로도 미래 예측과 의사결정을 할 수 있게 해준다.
- state == Marcov 상태 if and only if
- 현재 상태에서, 이전에 있었던 일들과는 별개로 미래가 존재한다.
- 현재 state가 주어져있으면, 과거는 어찌됐건 상관없음.
- 미래의 발생가능한 일에 대한 가능성을 따질 때에는 그냥 "현재 상태"만 보면 된다.
- 즉 현재 상태만으로도 미래의 행동을 결정하는 데 필요한 모든 정보를 제공하는 상태로, 현재의 상태가 과거의 모든 정보를 완벽하게 요약하고 있기 때문에 더이상 과거의 history를 따로 참고할 필요가 없음.
Rat Example
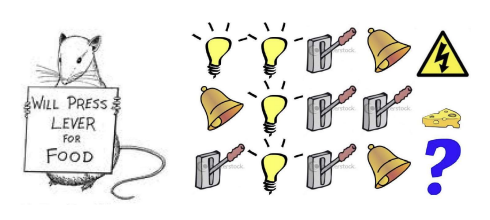
다음 그림은 상태가 어떻게 정의되느냐에 따라 agent의 학습과 행동 방식이 크게 달라진다는 것을 표현한 그림이다.
1. agent의 상태가 마지막 3개의 항목인 경우
agent가 환경에서 최근에 관찰한 마지막 3개 정보만을 state로 가정한다. 전체 정보는 알지 못하고, 최근에 일어난 이벤트 3개만을 기반으로 의사결정한다. 이 경우, 정보가 제한적이며 과거에 발생한 모든 기록을 잊어버린다.
2. agent의 상태가 불빛, 벨, 레버의 횟수인 경우
agent의 상태가 각 불빛, 벨, 레버가 얼마나 켜졌는지의 횟수로 표현된다. agent는 각 사건이 언제 일어났는지는 모르고, 오직 몇 번 발생했는지만 알고있다. 이 경우 특정 이벤트가 몇 번 발생했는지에 관한 누적 정보에만 의존하며, 순차적인 정보는 잃어버렸지만 빈도를 파악하는 데에 중점을 둔 상태이다.
3. agent의 상태가 전체 시퀀스인 경우
환경에서 발생한 모든 이벤트의 전체 시퀀스를 알고 있다. 시간에 따른 모든 기록을 상태로 저장하고 있으며 과거의 어떤 사건이 언제 발생했는지도 알고 있다. 모든 기록을 기억하고, 학습할 수 있는 매우 강력한 상태로, Marcov state에 가장 가까운 상태이다.
Fully Observable Environments
- Full observability : agent가 environment state를 바로 알고 있음
- Environment state == Agent state == Marcov state
- this is Markov Decision Process(MDP)
Partially Observable Environments
- partial observability : agent가 environment를 완전히 알지는 못한다.
- ex) 포커를 플레이하는 agent는 오직 public한 카드만 관찰한다 - 즉 agent state와 environment state는 다르다. environment state는 모든 걸 알고 있는 상황, agent state는 현재 자신의 관점에서의 정보만 알고있는 상황
- 이러한 상황을 Partially Observable Markov Decision Process(POMDP)라고 부른다.
- agent는 본인만의 state 표현을 구성해야 한다.
Major Components of an RL Agent
- RL agent는 다음과 같은 요소들 중 하나 또는 그 이상을 포함한다.
- Policy : agent의 행동 function- Value Function : 각 state or action이 얼마나 좋은지를 정의
- Model : environment에서 agent의 표현
Policy
- policy는 agent의 행동이다.
- 어떤 state가 주어지면 특정 action을 내뱉는 function이다.
- Deterministic policy :
특정 state가 들어오면 특정 action을 직진으로 뱉는다.- Stochastic policy :
특정 state가 들어오면 어떠한 action들이 발생할 지에 대한 확률 분포를 뱉는다.
- Stochastic policy :
Value function
- value function은 미래의 축적된 reward에 대한 예측을 내뱉는 function이다.
- state의 좋음/나쁨을 평가하는 데에 사용될 수 있다.
- value function을 사용하여 특정 상태에서 가능한 행동의 가치를 비교한 후, 가장 좋은 행동을 선택하는 방식.
Model
- Model은 environment가 다음에 무엇을 할 지 예측한다.
- P는 다음 상태를 예측한다.
- R은 다음의 즉각적인 reward를 예측한다.
Example Maze

- state : agent의 방향
- action : 위, 아래, 오른쪽, 왼쪽
- rewards : -1 per time step
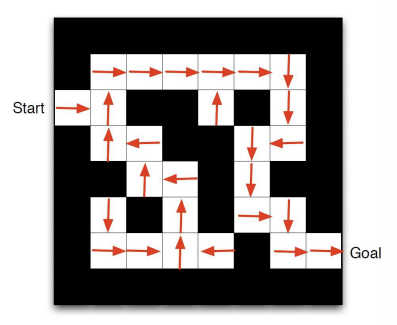
- 각 state s에서 화살표는 policy 를 나타낸다.

- 각 state s에서 숫자는 value 를 나타낸다.
agent 분류
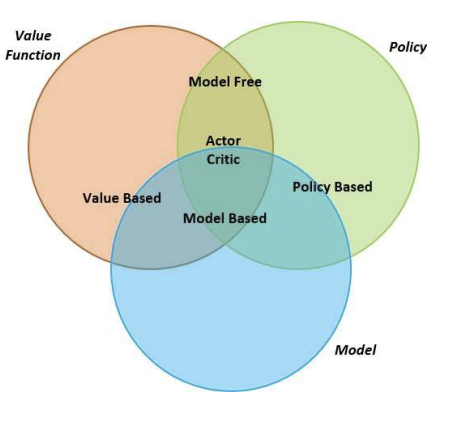
-
Value-Based (가치 기반)
- No policy(implicit) : 명시적인 정책을 사용하지 않고, value function을 통해 상태의 가치를 평가하고 이를 바탕으로 행동을 결정함. 여기서의 정책은 암묵적으로 가치 기반 행동 선택 매커니즘에 의해 결정됨- Value Function : 상태 또는 상태-행동 쌍의 가치를 나타내는 value function을 사용함. agent는 미래 보상을 최대화하는 방향으로 행동을 선택함.
-
Policy-Based (정책 기반)
- Policy : agent가 명시적으로 정책을 사용하여 각 상태에서 어떤 행동을 할 지 결정함. 정책은 확률적으로 각 행동을 선택하는 함수임.- No Value Function : 정책 기반은 value function을 사용하지 않고, 행동 선택을 직접적으로 최적화 함.
-
Actor-Critic (액터-크리틱)
- Policy : 액터-크리틱 방식은 정책 기반 학습을 사용함. agent는 actor 역할로, 어떤 행동을 선택할 지를 결정하는 정책을 학습함.- value function : 동시에 크리틱이라는 역할을 통해 value function을 학습하여 현재 정책의 행동이 얼마나 좋은지를 평가함. 즉 정책과 value function을 모두 사용함. 정책을 개선하는 동시에, 가치 평가를 통해 학습을 더 효율적으로 함.
-
Model-free
- Policy and/or Value Function : 정책 또는 value function을 통해 행동을 학습하지만, 환경에 대한 모델은 사용하지 않는다. 환경의 동작 방식(상태 전이나 보상 구조)를 미리 예측하거나 고려하지 않는다.- No model : 환경에 대한 명시적인 모델이 존재하지 않으며, agent는 순전히 경험을 통해 학습함.
-
Model-based
- Policy and/or Value Function : model-based도 정책 또는 value function을 사용해 행동을 학습할 수 있지만, 그 외에도 모델을 사용한다.- Model : 모델 기반 강화학습은 agent가 환경의 동작 방식을 학습하거나 미리 알고 있는 경우에 적용된다. 상태가 어떻게 전이되고, 보상이 어떻게 발생할 지에 대한 모델을 가지고 있으며, 이를 바탕으로 행동을 예측하고 최적의 행동을 선택한다. 예를 들어, agent는 환경의 모델을 사용해 미래 상태를 시뮬레이션하고 그 결과에 따라 최적의 정책을 결정한다.
Learning and Planning
- 시퀀셜한 decision making에서는 두 근본적인 문제가 있다.
- Planning :
- model의 environment는 알려져 있다.- agent는 model과 계산을 수행한다.
- agent는 policy를 개선한다.
- Learning :
- environment는 초반에 알려져 있지 않다.- agent는 environment와 상호작용한다.
- agent가 policy를 개선한다.
Exploration and Exploitation
- Exploitation
강화학습은 trial-and-error learning이다. 즉 agent는 주어진 환경에서의 경험을 바탕으로 시행착오를 통해 좋은 policy를 찾아야 한다. - Exploration
exploration은 환경에서 더 많은 정보를 찾는 과정이다. 내가 경험했던 맛집만 가면, 내가 모르는 맛집은 찾을 수 없듯이 가끔 모험도 해줘야 더 높은 reward를 기대할 수 있게 된다. - exploration과 exploitation을 적절히 섞는 것이 중요하다.
Prediction and Control
- Prediction
주어진 정책에 따라 미래를 평가하는 과정으로 특정 정책이 주어졌을 때 그 정책이 각 상태에서 얼마나 좋은지를 평가하는 작업이다. 여기서 중요한 것은 정책이 고정되어 있다는 것으로 현재의 정책에 따라 미래의 보상 기대치를 계산하는 것으로 이 과정에서 정책을 업데이트 하지는 않는다. - Control
미래를 최적화하는 과정으로 어떤 행동이 가장 큰 보상을 가져올지 찾아 정책을 최적화하는 것을 목표로 한다.
