- 개요
- GPTQ는 2022년 Elias Frantar가 개발한 양자화 기법입니다
- 정식 명칭: "GPTQ: Accurate Post-Training Quantization for Generative Pre-Trained Transformers"
- 논문 출처: https://arxiv.org/pdf/2210.17323.pdf
- 목적과 특징
- 기존 모델의 파라미터들을 더 적은 용량을 사용하는 데이터 타입으로 변환하기 위한 기법
- 양자화 이전의 모델에 입력 X를 넣었을 때와 양자화 이후의 모델에 입력 X를 넣었을 때의 오차를 최소화하도록 설계됨
- 작은 데이터셋을 준비하고 그 데이터셋을 활용해 모델 연산을 수행하면서 양자화를 진행
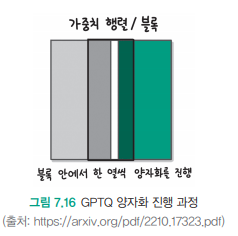
- 프로세스 (양자화 진행 과정):
- 회색 영역: 아직 양자화되지 않은 파라미터들
- 검정색 영역: 현재 양자화를 진행 중인 파라미터
- 녹색 영역: 이미 양자화가 완료된 파라미터
양자화는 왼쪽에서 오른쪽으로 순차적으로 진행됩니다:
- 왼쪽 녹색 부분: 이미 양자화가 완료된 영역
- 중앙 검정색 부분: 현재 양자화를 수행 중인 영역
- 오른쪽 회색 부분: 아직 양자화를 시작하지 않은 영역
이러한 방식으로 전체 모델의 파라미터들을 순차적으로 양자화하여 점진적으로 모델 전체를 압축합니다.
GPTQ의 주요 장점은 모델의 크기를 크게 줄이면서도, 특히 4비트 양자화의 경우 원래 성능을 거의 그대로 유지할 수 있다는 점입니다. 이는 큰 언어 모델을 더 효율적으로 배포하고 운영하는 데 매우 중요한 기술적 진보를 의미합니다.
GPTQ, AWQ, 비트앤바이츠를 정확도와 속도 측면에서 비교
정확도 비교 (높을수록 좋음):
1. AWQ > GPTQ > 비트앤바이츠
- AWQ: 활성화 정보를 고려한 양자화로 정확도 손실 최소화
- GPTQ: 상대적으로 안정적인 정확도 유지
- 비트앤바이츠: 8비트 양자화로 인한 정확도 손실이 가장 큼
추론 속도 (빠를수록 좋음):
1. 비트앤바이츠 > AWQ > GPTQ
- 비트앤바이츠: CUDA 커널 최적화로 가장 빠른 속도
- AWQ: 효율적인 하드웨어 활용으로 준수한 속도
- GPTQ: 상대적으로 가장 느린 추론 속도
특징 및 트레이드오프:
- AWQ: 정확도와 속도의 균형이 가장 좋음
- GPTQ: 높은 정확도를 원하지만 속도가 덜 중요한 경우 적합
- 비트앤바이츠: 빠른 속도가 필요하고 약간의 정확도 손실을 감수할 수 있는 경우 적합
선택 기준:
1. 정확도가 매우 중요한 경우: AWQ 또는 GPTQ
2. 빠른 추론이 필요한 경우: 비트앤바이츠
3. 둘 다 중요한 경우: AWQ
- 비트앤바이츠:
- NVIDIA가 직접 개발하여 하드웨어에 최적화
- 8비트 연산에 특화된 커널 구현
- GPU 아키텍처에 맞춘 저수준 최적화
- AWQ:
- CUDA 커널 사용
- 활성화 기반 양자화에 맞춘 커널 최적화
- 비트앤바이츠보다는 덜 최적화됨
- GPTQ:
- 기본적인 CUDA 커널 사용
- 범용적인 구현으로 최적화 수준이 낮음
- 상대적으로 덜 효율적인 메모리 접근
즉, 모두 CUDA를 사용하지만 최적화 수준에서 차이가 있습니다:
비트앤바이츠 > AWQ > GPTQ (최적화 수준)
NVIDIA 비트앤바이츠를 직접 최적화했기 때문

시리즈를 기반으로 작성하였습니다.