양자화
1.Post-Quantization (양자화)

포스트 퀀타이제이션(Post-Quantization)은 딥러닝 모델의 크기를 줄이고 추론 속도를 높이기 위해 사용되는 기술입니다.가중치 표현 변환:원래 모델은 32비트 부동소수점(floating-point)으로 가중치를 표현합니다.양자화 후에는 2비트 부호있는 정수(s
2.양자화 종류
동적 양자화(Dynamic Quantization, DQ): 이 방법은 모델 실행 중에 동적으로 가중치와 활성화 함수의 비트 수를 줄입니다. 런타임 시 양자화가 이루어지며, 입력 데이터에 따라 양자화 크기가 조절됩니다. 장점은 구현이 간단하고 유연하다는 것입니다. 단점으로는 연산 시 추가적인 오버헤드가 발생할 수 있어 추론 속도가 느려...
3.QLoRA (양자화 과정)
양자화 과정을 구체적으로 설명해드리겠습니다.실제 예시를 통해 단계별로 설명하겠습니다:원본 가중치 분석예를 들어 한 레이어의 가중치 일부가 다음과 같다고 가정해봅시다:오차 분석실제 저장 형식메모리 사용량 비교실제 성능 영향원본 모델 추론 시 평균 오차: 0.01차 양자화
4.비츠앤바이츠(Bits and Bytes) 양자화
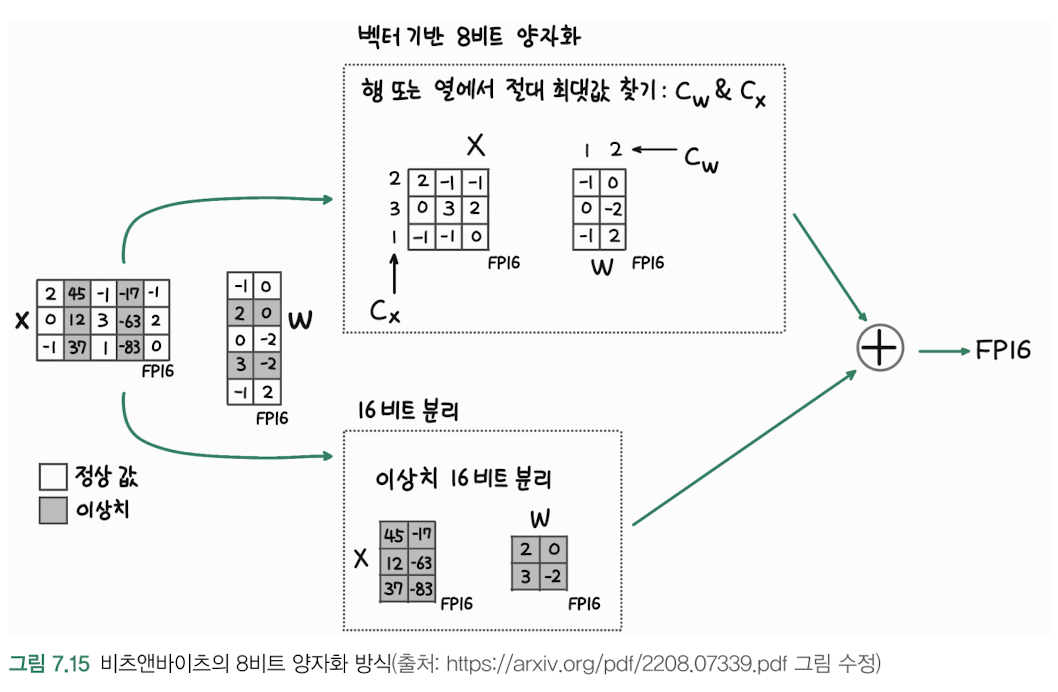
영점 양자화 (Zero-point Quantization, 그림 a)절대 최댓값 양자화 (Absolute Max Quantization, 그림 b)실제 딥러닝 모델에서의 적용 예시:1\. 컨볼루션 레이어의 가중치가 -2.1, 1.5, -0.8, 2.0 있다고 가정2\.
5.AWQ(Activation-aware Weight Quantization)
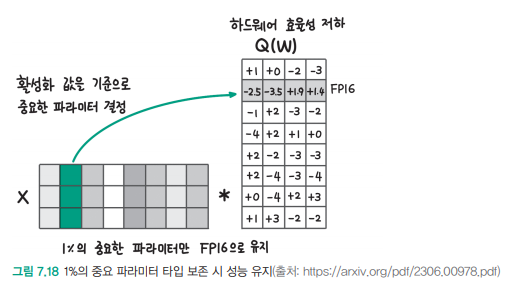
AWQ의 기본 개념AWQ는 2023년 MIT에서 개발한 LLM 압축과 가속을 위한 양자화 기법입니다모델의 성능을 최대한 유지하면서 특별히 중요한 파라미터의 정보를 보존하는 방식입니다주요 특징과 작동 방식활성화 값을 기준으로 상위 1%에 해당하는 모델 파라미터를 찾고,
6.GPTQ(GPT Quantization)
개요GPTQ는 2022년 Elias Frantar가 개발한 양자화 기법입니다정식 명칭: "GPTQ: Accurate Post-Training Quantization for Generative Pre-Trained Transformers"논문 출처: https: