- 기본 원리:
- 딥러닝 모델 학습 시 모든 중간 활성화값을 메모리에 저장하는 대신 일부만 저장
- 역전파(Backpropagation) 과정에서 필요한 중간값들은 저장된 체크포인트로부터 재계산
- 메모리 사용량과 계산 시간 사이의 트레이드오프를 조절할 수 있음
- 장점:
- 메모리 사용량을 크게 줄일 수 있음 (특히 대형 모델 학습 시 중요)
- GPU 메모리 한계를 극복하여 더 큰 배치 크기 사용 가능
- 더 깊은 네트워크 학습 가능
- 단점:
- 재계산으로 인한 추가 계산 비용 발생
- 학습 시간이 다소 증가할 수 있음
-
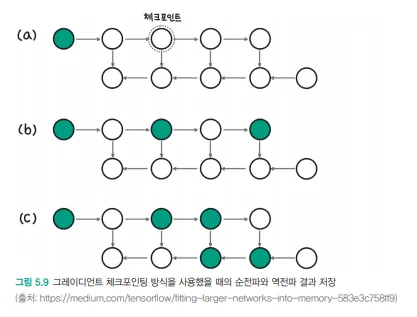
체크포인트 선택 전략(이미지의 세 가지 예시):
(a) 첫 번째 활성화값만 저장: 메모리 효율적이지만 많은 재계산 필요
(b) 균등한 간격으로 체크포인트 배치: 균형 잡힌 접근
(c) 동적 프로그래밍 기반 최적 체크포인트 배치: 메모리-계산 트레이드오프 최적화 -
실제 구현:
# PyTorch에서의 간단한 예시
from torch.utils.checkpoint import checkpoint
# 체크포인팅을 적용할 모듈
def custom_forward(x):
return model(x)
# 체크포인팅 적용
output = checkpoint(custom_forward, input)- 사용 시나리오:
- BERT, GPT 같은 대형 언어 모델 학습
- 고해상도 이미지 처리 네트워크
- 제한된 GPU 메모리로 큰 모델을 학습해야 하는 경우
그레디언트 체크포인팅은 메모리 제약 조건에서 딥러닝 모델을 효율적으로 학습하기 위한 중요한 기술입니다. 체크포인트 위치를 전략적으로 선택함으로써 메모리 사용량과 계산 비용 사이의 최적점을 찾을 수 있습니다.

시리즈를 기반으로 작성하였습니다.