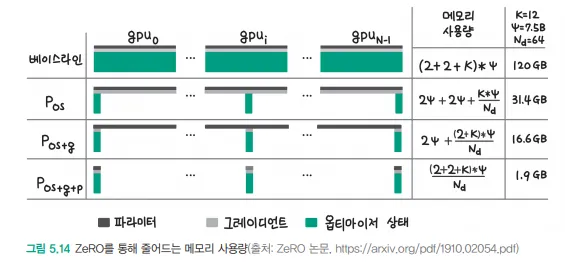
ZeRO (Zero Redundancy Optimizer)는 대규모 딥러닝 모델 학습을 위한 메모리 최적화 기술입니다. 이미지에서 보이는 것처럼 여러 단계의 파티셔닝을 통해 메모리를 효율적으로 사용합니다.
- ZeRO-1 (Optimizer State Partitioning)
- optimizer states (momentum, variance 등)를 데이터 병렬 프로세스들 간에 분할
- 예: Adam optimizer를 사용할 때, GPU1은 첫 번째 파라미터의 모멘텀/분산을, GPU2는 두 번째 파라미터의 모멘텀/분산을 저장
- ZeRO-2 (+ Gradient Partitioning)
- ZeRO-1의 장점에 더해 그래디언트도 파티셔닝
- 각 GPU는 특정 파라미터에 대한 그래디언트만 담당
- backward pass가 끝난 후 필요한 경우에만 그래디언트를 통신
- ZeRO-3 (+ Parameter Partitioning)
- 모델 파라미터까지 파티셔닝
- 가장 극단적인 메모리 절약이 가능
- forward/backward 중에 필요한 파라미터만 통신하여 가져옴
이미지에서 보이는 메모리 사용량 비교:
- 기본 방식: 120GB
- Pos (ZeRO-1): 31.4GB
- Pos+g (ZeRO-2): 16.6GB
- Pos+g+p (ZeRO-3): 1.9GB
실제 예시:
GPT-3와 같은 1750억 파라미터 모델을 학습한다고 가정해보겠습니다.
- 기본 방식: 한 GPU에서 불가능
- ZeRO-1: 여러 GPU에 optimizer states 분산으로 메모리 부담 감소
- ZeRO-2: gradient도 분산되어 더 적은 GPU로 학습 가능
- ZeRO-3: 파라미터까지 분산되어 최소한의 GPU로도 학습 가능
장점:
1. 메모리 효율성 극대화
2. 통신 오버헤드 최소화
3. 학습 속도 저하 최소화
4. 모델 규모 제약 완화

시리즈를 기반으로 작성하였습니다.