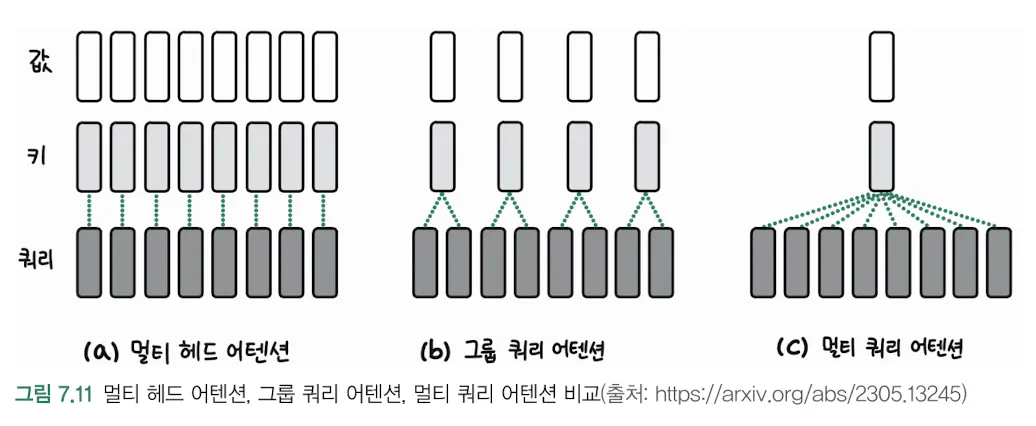
- 구조적 특징:
- 기존 멀티헤드 어텐션과 달리 쿼리(Q)의 수가 키(K)와 값(V)의 수보다 적습니다
- 중간 단계에서 4개의 쿼리가 8개의 키/값 쌍과 상호작용하는 것을 볼 수 있습니다
- 작동 방식:
# 예시 코드로 살펴보는 그룹 쿼리 어텐션
def group_query_attention(queries, keys, values):
# queries: [batch_size, num_queries, d_model] # 예: (32, 4, 256)
# keys: [batch_size, seq_length, d_model] # 예: (32, 8, 256)
# values: [batch_size, seq_length, d_model] # 예: (32, 8, 256)
# 1. 어텐션 스코어 계산
attention_scores = torch.matmul(queries, keys.transpose(-2, -1))
attention_scores = attention_scores / math.sqrt(d_model)
# 2. 소프트맥스 적용
attention_weights = F.softmax(attention_scores, dim=-1)
# 3. 가중치 적용 및 출력 계산
output = torch.matmul(attention_weights, values)
return output- 장점:
- 연산 효율성: 쿼리의 수가 적어 계산량이 줄어듭니다
- 메모리 효율성: 어텐션 맵의 크기가 작아져 메모리 사용량이 감소합니다
- 정보 압축: 여러 토큰의 정보를 효과적으로 요약할 수 있습니다
- KV 캐시 메모리 감소.
- 실제 예시:
문장 "나는 오늘 공원에서 산책을 했다"를 처리하는 경우:
- 입력 토큰 8개: ["나는", "오늘", "공원", "에서", "산책", "을", "했다", ""]
- 쿼리 토큰 4개로 압축하여 처리
- 각 쿼리는 관련된 토큰들의 정보를 종합적으로 수집
- 활용 사례:
- 긴 문서 요약
- 효율적인 언어 모델링
- 대규모 시퀀스 처리
그룹 쿼리 어텐션은 특히 긴 시퀀스를 처리할 때 효율적이며, transformer 모델의 성능을 유지하면서도 계산 비용을 크게 줄일 수 있는 장점이 있습니다. multi-head attention의 변형으로서, 실제 적용 시에는 모델의 크기와 태스크의 특성에 따라 적절한 쿼리 수를 선택하는 것이 중요합니다.
예시
예문 "나는 오늘 공원에서 산책을 했다"
- 토큰화 과정:
입력 토큰들 (8개):
["나는", "오늘", "공원", "에서", "산책", "을", "했다", "<pad>"]- 쿼리 그룹화:
쿼리 토큰들 (4개):
Q1: 주체/시간 관련 쿼리 # "나는", "오늘" 정보 수집
Q2: 장소 관련 쿼리 # "공원", "에서" 정보 수집
Q3: 행동 관련 쿼리 # "산책", "을" 정보 수집
Q4: 문장 완성 쿼리 # "했다" 정보 수집- 정보 종합:
- Q1은 "누가"와 "언제"에 관한 정보를 주로 수집
- Q2는 "어디서"에 관한 정보를 주로 수집
- Q3는 "무엇을"에 관한 정보를 주로 수집
- Q4는 문장의 종결 정보를 주로 수집
- 장점:
- 8개의 토큰을 4개의 쿼리로 처리하여 계산량 감소
- 관련된 정보들을 그룹화하여 효율적으로 처리
- 중요한 정보는 보존하면서 중복/불필요한 정보는 압축
이렇게 처리된 정보는 다음 층으로 전달되어 추가 처리가 이루어집니다. 실제로는 더 복잡한 계산이 이루어지지만, 이런 방식으로 토큰들의 정보가 쿼리를 통해 효율적으로 처리됩니다.

시리즈를 기반으로 작성하였습니다.