-
핵심 내용: 용량이 작고 빠른 GPU의 SRAM에서 계산할 수 있도록 블록처리
-
SRAM (Static Random-Access Memory):
- 특징:
- GPU 내부에 위치한 고속 캐시 메모리
- 매우 빠른 읽기/쓰기 속도
- 전력 소비가 많고 비용이 높음
- 플래시 어텐션의 블록 단위 계산이 여기서 수행됨
- 역할:
- 현재 처리 중인 Q,K,V 블록 저장
- 중간 계산 결과 임시 저장
- 블록 단위 어텐션 스코어 계산
- 특징:
-
HBM (High Bandwidth Memory):
- 특징:
- GPU의 주 메모리
- SRAM보다 훨씬 큰 용량
- SRAM보다 상대적으로 느린 접근 속도
- 전체 모델 가중치와 입력 데이터 저장
- 역할:
- 전체 시퀀스 데이터 저장
- 최종 어텐션 결과 저장
- 모델 파라미터 저장
- 특징:
플래시 어텐션의 메모리 계층 활용:
1. 입력 시퀀스와 모델 가중치 → HBM에 저장
2. 블록 단위로 데이터를 SRAM으로 이동
3. SRAM에서 고속 어텐션 계산 수행
4. 결과를 다시 HBM에 저장
이를 통해:
- 메모리 대역폭 병목 현상 감소
- 캐시 히트율 증가
- 전체적인 계산 속도 향상
- GPU 메모리 사용량 최적화
실제 처리 과정:
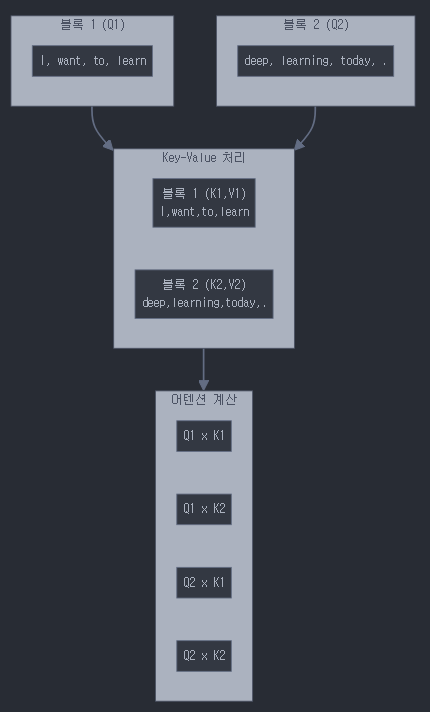
- 블록 1 (Q1) 처리:
# Step 1-1: Q1 x K1 계산
I → [I, want, to, learn] 와의 어텐션
want → [I, want, to, learn] 와의 어텐션
to → [I, want, to, learn] 와의 어텐션
learn → [I, want, to, learn] 와의 어텐션
# Step 1-2: Q1 x K2 계산
I → [deep, learning, today, .] 와의 어텐션
want → [deep, learning, today, .] 와의 어텐션
to → [deep, learning, today, .] 와의 어텐션
learn → [deep, learning, today, .] 와의 어텐션- 블록 2 (Q2) 처리:
# Step 2-1: Q2 x K1 계산
deep → [I, want, to, learn] 와의 어텐션
learning → [I, want, to, learn] 와의 어텐션
today → [I, want, to, learn] 와의 어텐션
. → [I, want, to, learn] 와의 어텐션
# Step 2-2: Q2 x K2 계산
deep → [deep, learning, today, .] 와의 어텐션
learning → [deep, learning, today, .] 와의 어텐션
today → [deep, learning, today, .] 와의 어텐션
. → [deep, learning, today, .] 와의 어텐션메모리 효율적 처리:
# 의사 코드
def flash_attention(Q, K, V, block_size):
N = Q.shape[1] # 시퀀스 길이
for i in range(0, N, block_size):
q_block = Q[:, i:i+block_size] # 현재 쿼리 블록
# 각 키-값 블록과의 어텐션 계산
for j in range(0, N, block_size):
k_block = K[:, j:j+block_size]
v_block = V[:, j:j+block_size]
# 현재 블록 어텐션 계산
S_ij = q_block @ k_block.transpose(-2, -1) # 블록 어텐션 스코어
P_ij = softmax(S_ij) # 부분 소프트맥스
O_ij = P_ij @ v_block # 부분 출력
# 누적 결과 업데이트 (올바른 스케일링 적용)
update_accumulated_attention(O_ij, i, j)주요 포인트:
- 전체 어텐션 계산:
- 모든 Q는 모든 K,V와 상호작용
- 블록 단위로 나누어 처리하지만, 전체 컨텍스트 유지
- 메모리 최적화:
- 한 번에 하나의 블록만 GPU 메모리에 로드
- 중간 결과는 점진적으로 누적
- 전체 어텐션 행렬을 저장하지 않음
- 정확성 보장:
최종 어텐션 스코어 행렬 (8x8):
I want to learn deep learn today .
I 1.0 0.8 0.6 0.7 0.5 0.6 0.4 0.2
want 0.8 1.0 0.7 0.8 0.6 0.7 0.5 0.3
to 0.6 0.7 1.0 0.8 0.5 0.6 0.4 0.2
... (전체 토큰 간 어텐션 값)- 수치적 안정성:
- 블록별 최대값 추적
- 적절한 스케일링 적용
- 정확한 소프트맥스 계산
따라서, 플래시 어텐션은 메모리 효율성을 높이면서도 전체 시퀀스에 대한 완전한 어텐션 계산을 수행합니다. 블록 처리는 단순히 계산을 나누는 것이지, 어텐션의 범위를 제한하는 것이 아닙니다.

시리즈를 기반으로 작성하였습니다.