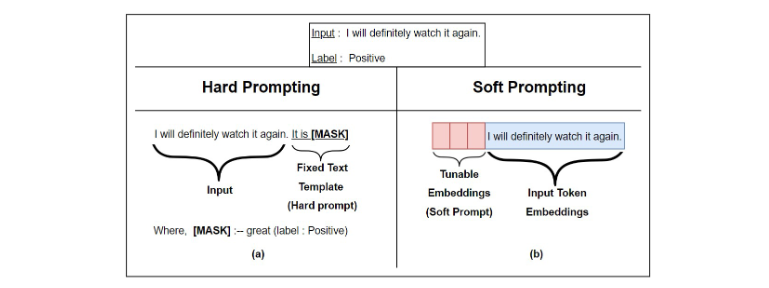
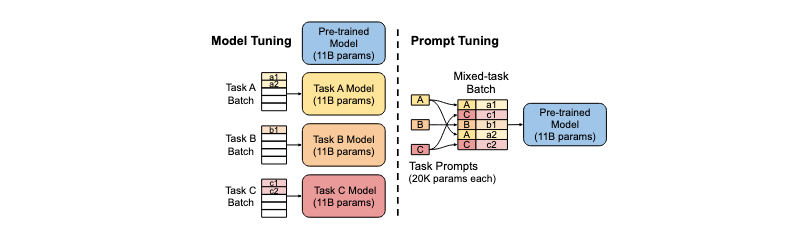
Prompt Tuning은 대규모 언어 모델을 효율적으로 특정 작업에 적응시키는 방법입니다. 기존의 fine-tuning 방식과 달리, 모델의 전체 파라미터를 조정하지 않고 입력 프롬프트만을 최적화합니다.
예를 들어, 영화 리뷰 감성 분석 태스크를 생각해봅시다:
-
기존 방식:
입력: "이 영화는 정말 훌륭합니다."
출력: "긍정" -
Prompt Tuning 방식:
입력: "[P1][P2] [P3][P4] [P5] 영화 리뷰: 이 영화는 정말 훌륭합니다. 감성:"
출력: "긍정"
여기서 [P1], [P2], [P3], [P4], [P5]는 학습 가능한 '소프트 프롬프트' 토큰입니다. 이들은 연속적인 벡터 공간에서 최적화됩니다.
Prompt Tuning의 학습 과정:
-
초기화: [P1]-[P5]를 랜덤한 벡터나 사전 정의된 단어의 임베딩으로 초기화합니다.
예: [P1] = [0.1, -0.3, 0.5, ...], [P2] = [-0.2, 0.4, 0.1, ...], ... -
입력 구성: 소프트 프롬프트를 실제 입력 텍스트 앞에 붙입니다.
-
모델 통과: 이 입력을 고정된 언어 모델에 통과시킵니다.
-
출력 및 손실 계산: 모델의 출력과 실제 레이블을 비교하여 손실을 계산합니다.
-
역전파: 계산된 손실을 사용해 [P1]-[P5]의 값만 업데이트합니다. 언어 모델의 다른 파라미터는 변경되지 않습니다.
-
반복: 최적의 [P1]-[P5] 값을 찾을 때까지 2-5 과정을 반복합니다.
학습이 완료된 후:
입력: "[최적화된 P1][최적화된 P2] [최적화된 P3][최적화된 P4] [최적화된 P5] 영화 리뷰: 이 영화는 지루했습니다. 감성:"
출력: "부정"
이 방식의 장점:
1. 효율성: 전체 모델(예: 175B 파라미터)이 아닌 소수의 프롬프트 파라미터(예: 5 * 768 = 3,840 파라미터)만 조정합니다.
2. 다중 작업 처리: 하나의 모델로 여러 작업을 수행할 수 있습니다. 각 작업마다 다른 프롬프트를 사용하면 됩니다.
3. 성능: 모델 크기가 충분히 큰 경우, 전체 fine-tuning에 준하는 성능을 낼 수 있습니다.
Prompt Tuning은 특히 GPT-3와 같은 대규모 언어 모델을 효율적으로 활용하는 데 유용합니다. 각 작업마다 전체 모델을 미세 조정하는 대신, 작은 프롬프트만을 학습함으로써 리소스를 크게 절약하면서도 좋은 성능을 얻을 수 있습니다.
Prompt Tuning과 P-tuning의 차이점
Prompt Tuning과 P-tuning의 차이점을 시각화한 그래프를 Mermaid 다이어그램으로 만들어보겠습니다. 이 그래프는 두 방법의 구조와 프로세스를 비교하여 보여줍니다.

이 그래프는 Prompt Tuning과 P-tuning의 주요 차이점을 시각적으로 보여줍니다. 각 방법의 특징을 설명하겠습니다:
-
Prompt Tuning:
- 입력 텍스트에 직접 프롬프트 토큰을 추가합니다.
- 이 프롬프트 토큰은 LLM의 임베딩 레이어에 들어가기 전에 추가됩니다.
- 프롬프트 토큰 자체가 학습 가능한 파라미터입니다.
- LLM은 수정된 입력을 처리하여 최종 출력을 생성합니다.
-
P-tuning:
- 입력 텍스트는 먼저 LSTM 모델을 통과합니다.
- LSTM 모델은 연속적인 프롬프트 임베딩을 생성합니다.
- 이 연속적인 임베딩이 LLM의 임베딩 레이어에 추가됩니다.
- LSTM 모델의 파라미터가 학습 가능한 부분입니다.
- LLM은 LSTM이 생성한 프롬프트 임베딩이 포함된 입력을 처리하여 최종 출력을 생성합니다.
주요 차이점:
- Prompt Tuning은 이산적인 토큰을 사용하지만, P-tuning은 연속적인 임베딩을 사용합니다.
- Prompt Tuning은 프롬프트 토큰 자체를 학습하지만, P-tuning은 LSTM 모델의 파라미터를 학습합니다.
- P-tuning은 입력에 따라 동적으로 프롬프트를 생성할 수 있어 더 유연합니다.
이 그래프를 통해 두 방법의 구조적 차이와 각각의 특징을 한눈에 파악할 수 있습니다. 두 방법 모두 LLM의 성능을 향상시키는 데 효과적이지만, 구현 방식과 학습 과정에서 차이가 있음을 알 수 있습니다.
예시
예시 데이터:
1. "This movie was fantastic! I loved every minute of it."
2. "The plot was confusing and the acting was terrible. Waste of time."
- Prompt Tuning
Prompt Tuning에서는 이산적인 프롬프트 토큰을 사용합니다. 예를 들어, [POS]와 [NEG]라는 두 개의 프롬프트 토큰을 사용할 수 있습니다.
입력 형식:
[프롬프트 토큰] + 실제 리뷰 텍스트
예시 1 (긍정적 리뷰):
입력: "[POS] This movie was fantastic! I loved every minute of it."
여기서 [POS]는 학습 가능한 프롬프트 토큰입니다.
예시 2 (부정적 리뷰):
입력: "[NEG] The plot was confusing and the acting was terrible. Waste of time."
여기서 [NEG]는 학습 가능한 프롬프트 토큰입니다.
학습 과정:
1. 초기에 [POS]와 [NEG] 토큰은 랜덤한 임베딩 값을 가집니다.
2. 학습이 진행되면서 이 토큰들의 임베딩 값이 조정됩니다.
3. 예를 들어, [POS] 토큰은 점차 "좋다", "훌륭하다", "즐겁다" 등의 단어와 유사한 임베딩 값을 가지게 될 수 있습니다.
4. [NEG] 토큰은 "나쁘다", "실망스럽다", "지루하다" 등의 단어와 유사한 임베딩 값을 가지게 될 수 있습니다.
결과적으로, 모델은 이 프롬프트 토큰을 보고 리뷰의 전반적인 감성을 빠르게 파악할 수 있게 됩니다.
- P-tuning
P-tuning에서는 연속적인 임베딩을 사용하며, 이를 생성하기 위해 작은 LSTM 모델을 사용합니다.
입력 형식:
[LSTM 생성 임베딩] + 실제 리뷰 텍스트
예시 1 (긍정적 리뷰):
LSTM 입력: "positive sentiment"
LSTM 출력: [0.7, -0.2, 0.5, ...] (연속적인 벡터)
최종 입력: "[0.7, -0.2, 0.5, ...] This movie was fantastic! I loved every minute of it."
예시 2 (부정적 리뷰):
LSTM 입력: "negative sentiment"
LSTM 출력: [-0.6, 0.3, -0.4, ...] (연속적인 벡터)
최종 입력: "[-0.6, 0.3, -0.4, ...] The plot was confusing and the acting was terrible. Waste of time."
학습 과정:
1. LSTM 모델은 초기에 랜덤한 파라미터 값을 가집니다.
2. 학습이 진행되면서 LSTM 모델의 파라미터가 조정됩니다.
3. LSTM은 "positive sentiment"와 "negative sentiment"라는 입력에 대해 각각 다른 임베딩을 생성하도록 학습됩니다.
4. 이 임베딩은 연속적인 벡터 공간에서 표현되므로, 단순히 긍정/부정의 이진 구분뿐만 아니라 더 미묘한 감정 차이도 표현할 수 있습니다.
결과적으로, 모델은 LSTM이 생성한 연속적인 임베딩을 통해 리뷰의 감성을 더 섬세하게 파악할 수 있게 됩니다.
주요 차이점:
1. 표현력: P-tuning은 연속적인 벡터를 사용하므로 더 다양한 감성 상태를 표현할 수 있습니다. 반면 Prompt Tuning은 이산적인 토큰을 사용하여 제한된 수의 상태만 표현할 수 있습니다.
-
동적 생성: P-tuning의 LSTM 모델은 입력에 따라 동적으로 임베딩을 생성할 수 있습니다. 예를 들어, "somewhat positive"나 "very negative" 같은 입력에 대해서도 적절한 임베딩을 생성할 수 있습니다. Prompt Tuning은 미리 정의된 토큰만 사용할 수 있습니다.
-
학습 대상: Prompt Tuning에서는 프롬프트 토큰 자체의 임베딩을 학습합니다. P-tuning에서는 LSTM 모델의 파라미터를 학습합니다.
-
복잡성: P-tuning은 LSTM 모델을 사용하므로 구조적으로 더 복잡하지만, 더 유연한 프롬프트 표현이 가능합니다. Prompt Tuning은 상대적으로 단순하지만, 표현력에 제한이 있을 수 있습니다.
이렇게 예시 데이터를 통해 살펴보면, 두 방법의 차이점과 각각의 장단점을 더 구체적으로 이해할 수 있습니다.
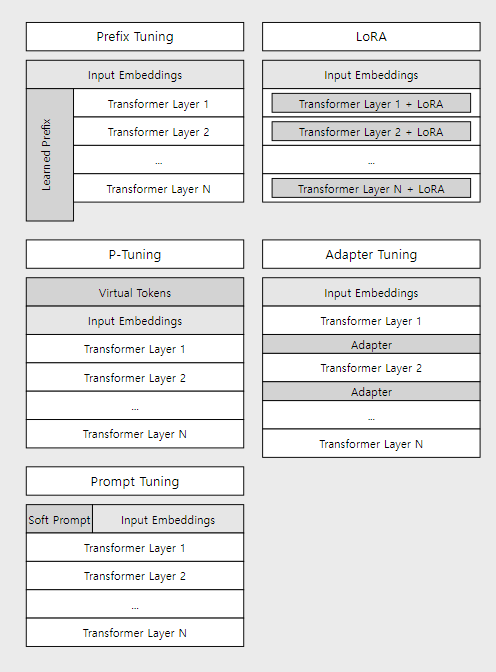
-
Prefix Tuning:
- 입력 임베딩 다음에 학습 가능한 접두사(prefix)가 추가됩니다.
- 접두사와 임베딩된 입력이 결합되어 트랜스포머 레이어로 전달됩니다.
-
P-Tuning:
- 가상 토큰이 입력 시퀀스의 앞에 추가됩니다.
- 가상 토큰과 실제 입력이 함께 임베딩 레이어를 통과합니다.
-
Prompt Tuning:
- 소프트 프롬프트가 입력 임베딩과 병렬로 추가됩니다.
- 소프트 프롬프트와 입력 임베딩이 결합되어 트랜스포머 레이어로 전달됩니다.
-
LoRA:
- 입력 임베딩은 변경되지 않습니다.
- LoRA 업데이트는 각 트랜스포머 레이어 내부의 가중치에 적용됩니다.
-
Adapter Tuning:
- 입력 임베딩은 변경되지 않습니다.
- 어댑터 레이어가 각 트랜스포머 레이어 사이에 삽입됩니다.
이 다이어그램을 통해 각 방법이 입력 임베딩과 어떻게 상호작용하는지, 그리고 모델의 어느 부분에 변경을 가하는지를 더 명확하게 볼 수 있습니다. Prefix Tuning, P-Tuning, Prompt Tuning은 입력 부분을 직접적으로 수정하는 반면, LoRA와 Adapter Tuning은 입력 임베딩을 그대로 유지하면서 모델의 내부 구조를 변경합니다.
