PEFT(LLM)
1.PEFT(Parameter Efficient Fine-Tuning)

예를 들어, 65B 파라미터의 LLaMA 모델(교사 모델)이 있다고 가정해봅시다. 이 모델의 지식을 7B 파라미터의 더 작은 LLaMA 모델(학생 모델)로 전달하는 과정이 지식 증류입니다. 구체적인 과정:대량의 텍스트 데이터에 대해 65B LLaMA로 다음 단어 예측을
2.LoRA(Low Rank Adaptation)
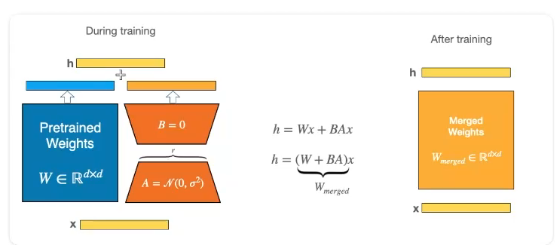
LoRA(Low-Rank Adaptation)는 대규모 언어 모델(LLM)을 효율적으로 미세 조정하는 기술입니다. 이 방법의 핵심 아이디어는 모델의 가중치를 직접 업데이트하는 대신, 낮은 순위(low-rank) 행렬을 사용하여 모델을 조정하는 것입니다. 이를 통해 적은
3.Prefix tuning
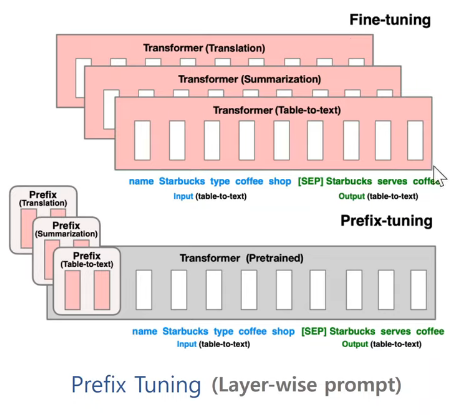
분홍생: 학습되는 부분prefix의 경우 각 트랜스포머 레이어의 앞부분에 레이어를 붙여 해당 부분만 학습한다.Prefix Tuning의 기본 개념:Prefix Tuning은 사전 학습된 LLM의 대부분의 매개변수를 고정한 채로, 각 레이어의 시작 부분에 학습 가능한 연
4.P-tuning
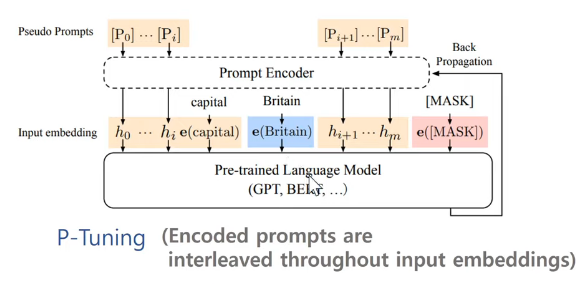
전통적인 프롬프트 방식 (이미지의 (a) 부분):전통적인 방식에서는 "The capital of Britain is MASK"와 같은 고정된 프롬프트를 사용합니다. 여기서 각 단어는 개별적으로 임베딩되어 언어 모델에 입력됩니다. 이 방식의 한계는 프롬프트가 이산적(di
5.Prompt tuning
Prompt Tuning은 대규모 언어 모델을 효율적으로 특정 작업에 적응시키는 방법입니다. 기존의 fine-tuning 방식과 달리, 모델의 전체 파라미터를 조정하지 않고 입력 프롬프트만을 최적화합니다.예를 들어, 영화 리뷰 감성 분석 태스크를 생각해봅시다:기존 방식