-
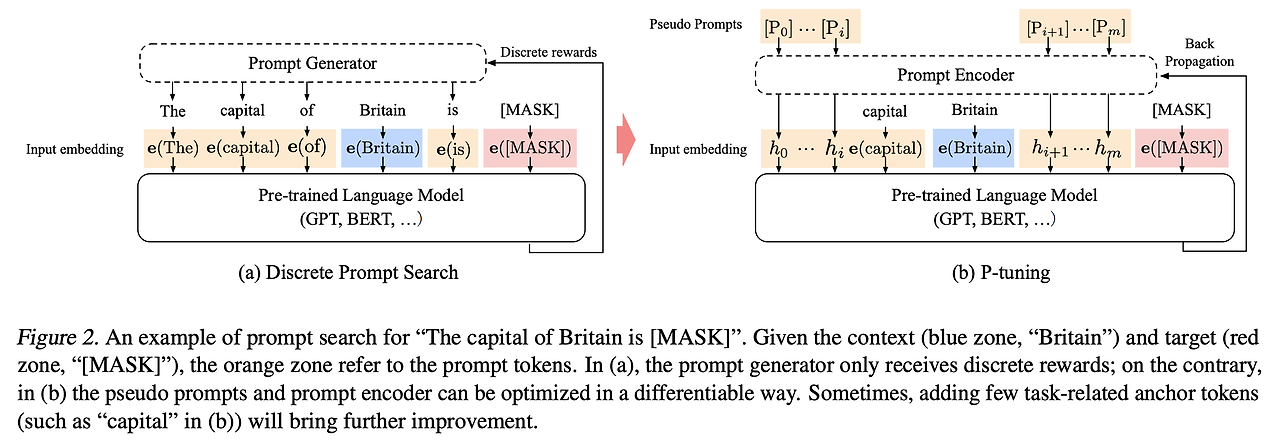
전통적인 프롬프트 방식 (이미지의 (a) 부분):
전통적인 방식에서는 "The capital of Britain is [MASK]"와 같은 고정된 프롬프트를 사용합니다. 여기서 각 단어는 개별적으로 임베딩되어 언어 모델에 입력됩니다. 이 방식의 한계는 프롬프트가 이산적(discrete)이며, 최적의 프롬프트를 찾기 위해서는 trial-and-error 방식의 탐색이 필요하다는 점입니다.
-
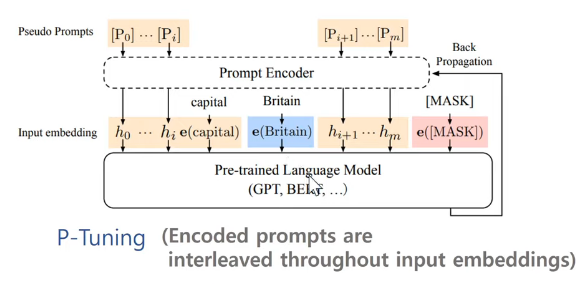
P-tuning의 기본 개념 (이미지의 (b) 부분):
P-tuning은 이러한 한계를 극복하기 위해 '의사 프롬프트(Pseudo Prompts)'라는 개념을 도입합니다. 이 의사 프롬프트는 [P0], [P1], ... [Pm]과 같은 형태로 표현되며, 연속적인(continuous) 벡터 공간에서 최적화됩니다.
-
프롬프트 인코더:
P-tuning의 핵심은 프롬프트 인코더입니다. 이 인코더는 의사 프롬프트 토큰들을 입력받아 연속적인 벡터 h0, h1, ..., hm으로 변환합니다. 이 과정에서 LSTM이나 MLP와 같은 신경망이 사용될 수 있습니다.
-
입력 구성:
최종 입력은 다음과 같이 구성됩니다:
[h0, h1, ..., hi, e(capital), e(Britain), hi+1, ..., hm, e([MASK])]여기서 e()는 원래 언어 모델의 임베딩 함수를 나타냅니다. 'capital'과 'Britain'같은 주요 단어들은 원래의 임베딩을 유지하면서, 나머지 부분은 학습 가능한 연속 벡터로 대체됩니다.
-
학습 과정:
- 프롬프트 인코더의 파라미터만 학습되며, 언어 모델의 파라미터는 고정됩니다.
- 손실 함수는 언어 모델의 출력과 목표 출력 간의 차이를 최소화하도록 설정됩니다.
- 역전파(Back Propagation)를 통해 프롬프트 인코더의 파라미터가 업데이트됩니다.
-
P-tuning의 장점:
- 연속 공간에서의 최적화: 이산적인 단어 선택 대신 연속적인 벡터 공간에서 최적의 프롬프트를 찾을 수 있습니다.
- 효율성: 전체 언어 모델을 미세조정하는 것보다 훨씬 적은 파라미터만 학습합니다.
- 유연성: 다양한 태스크에 쉽게 적용할 수 있습니다.
-
실제 적용 예시:
질문-답변 태스크에 적용할 경우:
입력: "[P0][P1] [P2] capital Britain [P3][P4] [MASK]"프롬프트 인코더는 [P0], [P1], [P2], [P3], [P4]를 연속 벡터로 변환하고, 이를 'capital', 'Britain', '[MASK]'의 원래 임베딩과 결합하여 언어 모델에 입력합니다.
-
추가 개선:
이미지의 설명에서 언급된 대로, "capital"과 같은 태스크 관련 앵커 토큰을 추가하면 성능을 더욱 향상시킬 수 있습니다. 이는 모델이 태스크의 본질을 더 잘 이해하도록 돕습니다.
P-tuning은 프롬프트 엔지니어링의 한계를 극복하고, 대규모 언어 모델을 효율적으로 특정 태스크에 적응시키는 강력한 방법입니다. 연속 공간에서의 최적화를 통해, 더 유연하고 효과적인 프롬프트 학습이 가능해집니다.
