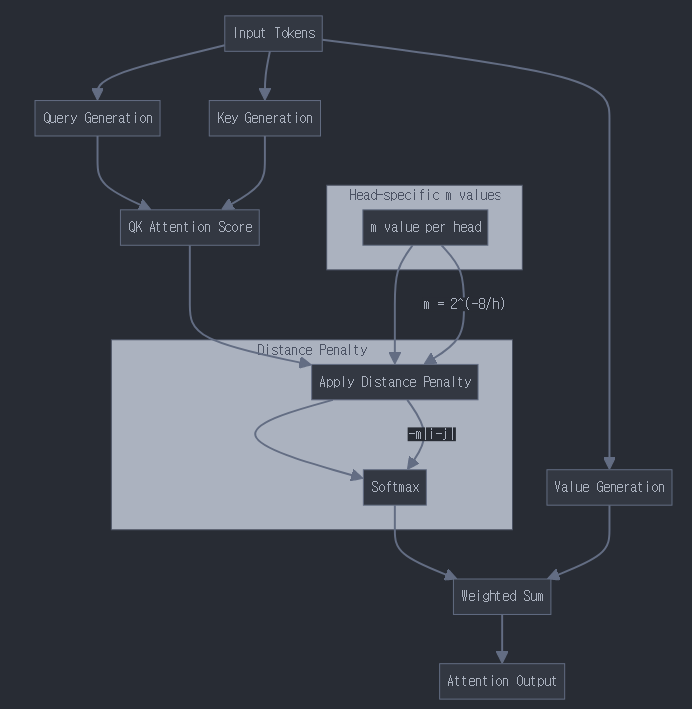
- ALiBi의 기본 개념
- 기존 positional encoding을 대체하는 방식
- attention score에 직접적으로 거리에 비례하는 벌점(페널티)을 부여
- 학습된 position embedding 없이도 위치 정보를 반영
- 핵심 수식
기본 attention score 계산:
score(q,k) = (q·k)/√d
ALiBi가 적용된 attention score:
score_alibi(q,k) = (q·k)/√d - m|i-j|
여기서:
- q: 쿼리 벡터
- k: 키 벡터
- d: 어텐션 헤드의 차원
- m: 기울기 값 (head별로 다름)
- |i-j|: 토큰 간의 상대적 거리
- 실제 예시 계산
토큰 시퀀스 "나는 학교에 간다"가 있다고 가정해봅시다.
위치: i=0("나는"), i=1("학교에"), i=2("간다")
m값을 -0.2라고 가정하면:
-
"나는"-"학교에" 거리: |0-1| = 1
페널티 = -0.2 × 1 = -0.2 -
"나는"-"간다" 거리: |0-2| = 2
페널티 = -0.2 × 2 = -0.4
- 헤드별 m값 설정
- 각 어텐션 헤드마다 다른 m값 사용
- 일반적인 m값 시퀀스:
m = [2^(-8), 2^(-7), 2^(-6), ..., 2^(-1)]
- ALiBi의 장점
- 긴 시퀀스에도 잘 일반화됨
- 학습 시퀀스 길이보다 긴 시퀀스에도 적용 가능
- 추가 학습 파라미터가 필요 없음
- 실제 어텐션 스코어 예시
q·k/√d = 5.0 이라고 가정할 때:
첫번째 토큰이 다른 토큰들을 참조할 때:
- score(0,0) = 5.0 - 0 = 5.0
- score(0,1) = 5.0 - 0.2 = 4.8
- score(0,2) = 5.0 - 0.4 = 4.6
이처럼 거리가 멀어질수록 점진적으로 어텐션 스코어가 감소하게 됩니다.
이런 방식으로 ALiBi는:
1) 위치 정보를 명시적으로 인코딩하지 않고도 반영
2) 거리에 따른 선형적인 페널티 부여
3) 직관적이고 단순한 구현 가능
4) 확장성이 뛰어난 장점들을 가지게 됩니다.

시리즈를 기반으로 작성하였습니다.