실습하기 앞서,
지도 학습 알고리즘에는 2가지로 나눌 수 있다.
분류: 샘플 데이터를 클래스 중 하나로 분류하는 것회귀: 샘플 데이터를 통해 어떤 숫자를 예측하는 것
쉽게 말해,
k-최근접 이웃 분류 알고리즘은
빙어 클래스와 도미클래스를 학습시켜 샘플데이터를 둘 중 1개의 클래스로 분류하는 것이다.
k-최근접 이웃 회귀 알고리즘은
생선 특성(길이, 높이, 두께) 데이터를 가지고 임의의 수치(무게)를 도출하는 것이다.
실습하기
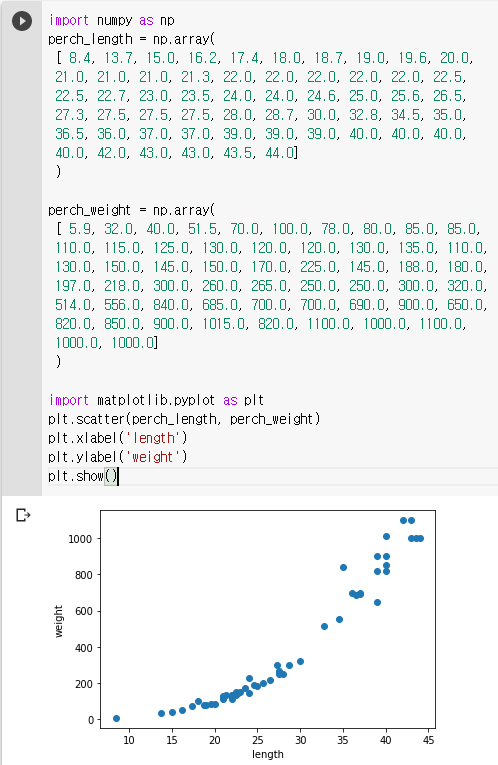
<perch_length, perch_weight> 는 🔗http://bit.ly/perch_data 를 참고했다.
1) 데이터 준비하기
2) 훈련세트와 테스트세트 나누기
- 랜덤 시드 42로 설정하여 train_test_split을 통해 세트를 나눈다.

💡 여기서 잠깐! 사이킷 런의 훈련 세트는 2차원 배열이어야한다는 사실을 알아두어야 한다.
3) 1차원 배열을 2차원 배열로 변환하기
- reshape ➡ 활용하여 배열의 크기를 바꾼다.

4) 훈련하기
-
사이킷 런의 k-최근접 이웃 회귀 알고리즘 구현 클래스는
KNeighborsRegressor이다.

-
테스트 점수 확인

💡 여기서 잠깐! 분류 클래스의 경우 score는 정확도이였고, 회귀 클래스의 경우 score는 결정계수 라고 한다.
🚀 결정계수(coefficient of determination) == R^2
- 계산식
R^2 = 1- [{(타깃-예측)^2 의 합} / {(타깃-평균)^2 의합}]
R^2의 숫자가 0에 가까울수록 ~회귀식의 정확도는 낮다~ 라고 볼 수 있으며, 반대로 1에 가까울수록 ~회귀식의 정확도가 높다~라고 볼수 있다.
5) 훈련세트와 테스트세트의 점수 비교
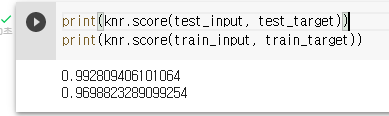
- 위의 결과를 보면 훈련세트의 값이 낮아진 것을 확인 할 수 있다.
😰 왜 값이 다르지? 과대 적합과 과소 적합
- 과대 적합(Overfitting): 훈련세트 점수 >>>> 테스트 세트 점수
훈련세트 점수가 테스트세트 점수보다 현저하게 높으면 과대적합이라고 한다. - 과소 적합(Underfitting) : 훈련세트 점수 <<<< 테스트 세트 점수
훈련세트 점수가 테스트세트 점수보다 현저하게 낮으면 과소적합이라고 한다.
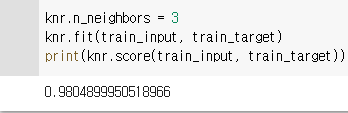
6) 과소 적합을 해소하기
- n_neighbors ➡ 활용하여 과소 적합을 해소하기
확인문제
- k-최근접 이웃 회귀에서는 새로운 샘플에 대한 예측을 어떻게 만드나요?
① 이웃 샘플 클래스 중 다수인 클래스
② 이웃 샘플의 타깃값의 평균
③ 이웃 샘플 중 가장 높은 타깃값
④ 이웃 샘플 중 가장 낮은 타깃값
답: ② 이웃 샘플의 타깃값의 평균
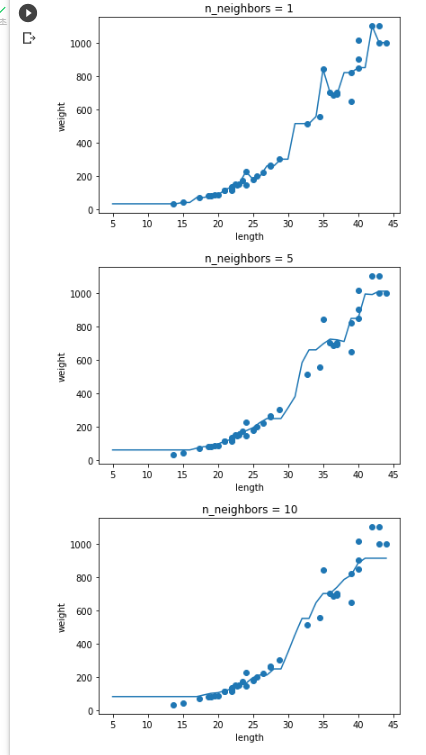
- 과대적합과 과소적합에 대한 이해를 돕기 위해 복잡한 모델과 단순한 모델을 만들겠습니다.
앞서 만든 k-최근접 이웃 회귀 모델의 k 값을 1, 5, 10으로 바꿔가며 훈련해 보세요. 그다
음 농어의 길이를 5에서 45까지 바꿔가며 예측을 만들어 그래프로 나타내 보세요. n이 커짐
에 따라 모델이 단순해지는 것을 볼 수 있나요?
답: