실습하기 앞서,
앞서 배운 것은 샘플링 편향을 막고자 numpy index를 통한 랜덤한 순서로 배치시켜 훈련세트와 테스트 세트를 나누어 훈련했다.
해당 모델에서 타겟 기준의 중간 지점에 있는 데이터들은 이웃의 거리와 상관 없이 단순 인덱스만 보고 예측을 하기 시작했다.
그래서 인접한 이웃들의 거리를 고려하여 가장 가까운 이웃을 판별하는 방법을 알아보자.
실습하기
<fish_length, fish_weight> 는 🔗http://bit.ly/bream_smelt 를 참고했다.
1) 각 특성을 가진 numpy 배열 연결하기
- numpy.column_stack ➡ 활용하여 입력데이터 생성
 (..중략..)
(..중략..)
- numpy.concatenate ➡ 활용하여 타겟데이터 생성


2) 훈련 세트와 테스트 세트 만들기
- train_test_split ➡ 활용하여 random하게 훈련세트와 테스트세트로 나누기
💡 ramdom_state 매개변수를 통해 random seed 지정하여 세트를 나누었다.
- stratify ➡ 활용하여 타깃 데이터 비율에 맞게 세트 나누기

💡 stratify 매개변수를 통해 세트 비율을 클래스 비율에 맞게 나누었다. (샘플링 편향 일부 해소 효과)
3) 훈련하기
-
k-최근접 이웃 알고리즘을 통한 훈련

-
정답 샘플(도미) 넣고 예측값 확인

샘플 값으로만 보면 정답 샘플이므로 1.0 이 나와야하는데 빙어로 인식함
-
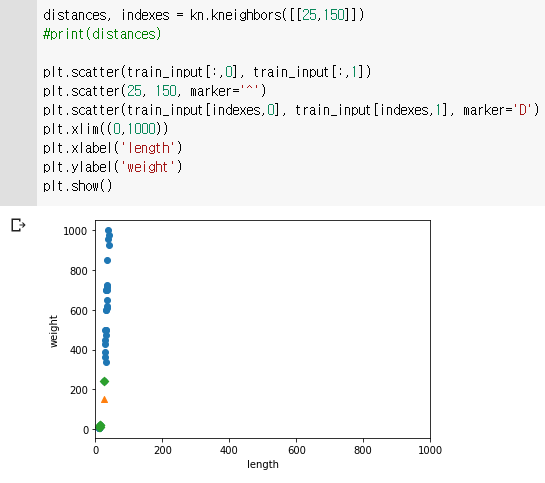
샘플과 이웃 데이터 확인

도미데이터에 더 가까운데 빙어로 인식함
-
이웃 샘플까지의 거리 확인

4) [전처리1] 스케일 맞추기
🌝 x축 범위와 y축 범위의 기준을 맞춰주자.
Point ① ❗
특성의 값의 범위가 다른 것을스케일이 다르다라고 포현한다. 스케일의 기준을 일정한 값으로 맞추기 위한 작업을데이터 전처리라고 한다.
- xlim ➡ 활용하여 x축 범위를 y축 범위와 동일하게 설정하기
4) [전처리2] 표준 점수 활용하기
- 표준 점수: 각 특성값이 평균에서 표준편차 상 어디 위치에 있는지를 나타내는 지표,
z값또는z점수라고 한다. - 표준 편차: 분산의 정도 및 자료의 산포도를 나타내는 수치이다.
Point ② ❗
표준점수를 활용하는 방식도데이터 전처리의 방법중 하나이다.
-
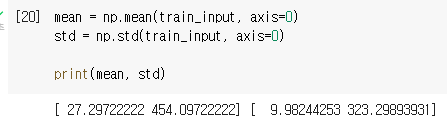
훈련 세트의 평균과 표준편차 계산하기
-
표준 점수 구하기
🔎 표준 점수 = (원본데이터 - 평균) / 표준편차

Point ③ ❗
넘파이는 train_input에 있는 모든 행에서 위의 계산을 수행하는 똑똑한..라이브러리이다!! 해당 기능을브로드캐스팅(broadcasting)이라고 한다.
5) 전처리 데이터로 모델 훈련하기
- 전처리 데이터와 샘플 데이터 확인하기
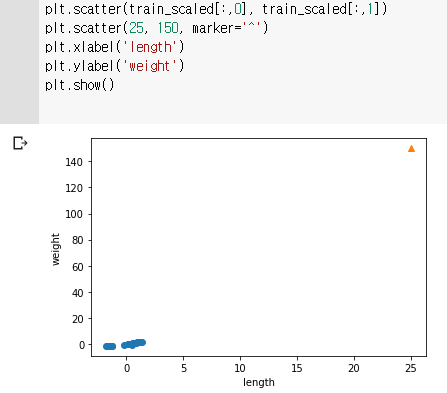
당연히, 훈련 세트는 표준점수로 변환하였지만 샘플 데이터는 변환하지 않았으므로 아예 샘플은 표준점수 공식이 반영되지 않는 raw 데이터이다.
-
전처리 데이터의 표준 점수 기준으로 샘플 데이터 변환하기
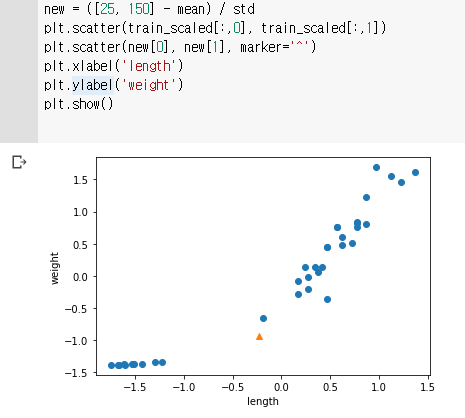
-
테스트 세트도 훈련 세트와 동일한 기준으로 표준 점수 계산하기

6) 학습된 모델로 예측하기
-
정답 샘플(도미) 넣고 예측값 확인하기

-
학습된 모델 확인하기
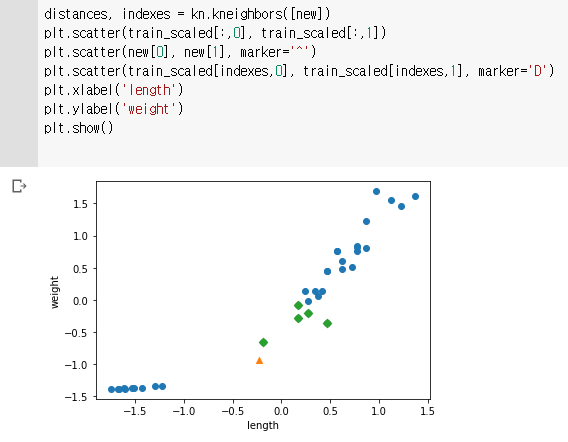
확인문제
- 이 방식은 스케일 조정 방식의 하나로 특성값을 0에서 표준편차의 몇 배수만큼 떨어져 있는지로 변환한 값입니다. 이 값을 무엇이라 부르나요?
① 기본 점수
② 원점수
③ 표준점수
④ 사분위수
답: ③ 표준점수
- 테스트 세트의 스케일을 조정하려고 합니다. 다음 중 어떤 데이터의 통계 값을 사용해야 하나요?
① 훈련세트
② 테스트 세트
③ 전체 데이터
답: ① 훈련세트
