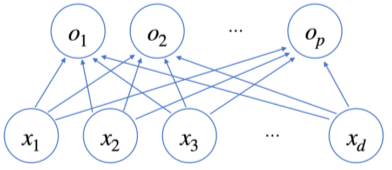

신경망(neural network)의 기본구조
출력벡터 O에 softmax를 적용하면 주어진 데이터가 어떤 특정 클래스에 속할 확률일지를 구할수 있음
- Softmax: 지수함수를 이용해 선형모델의 결과물을 확률벡터로 변환
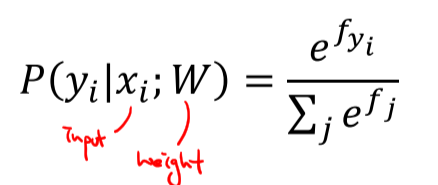
예시)
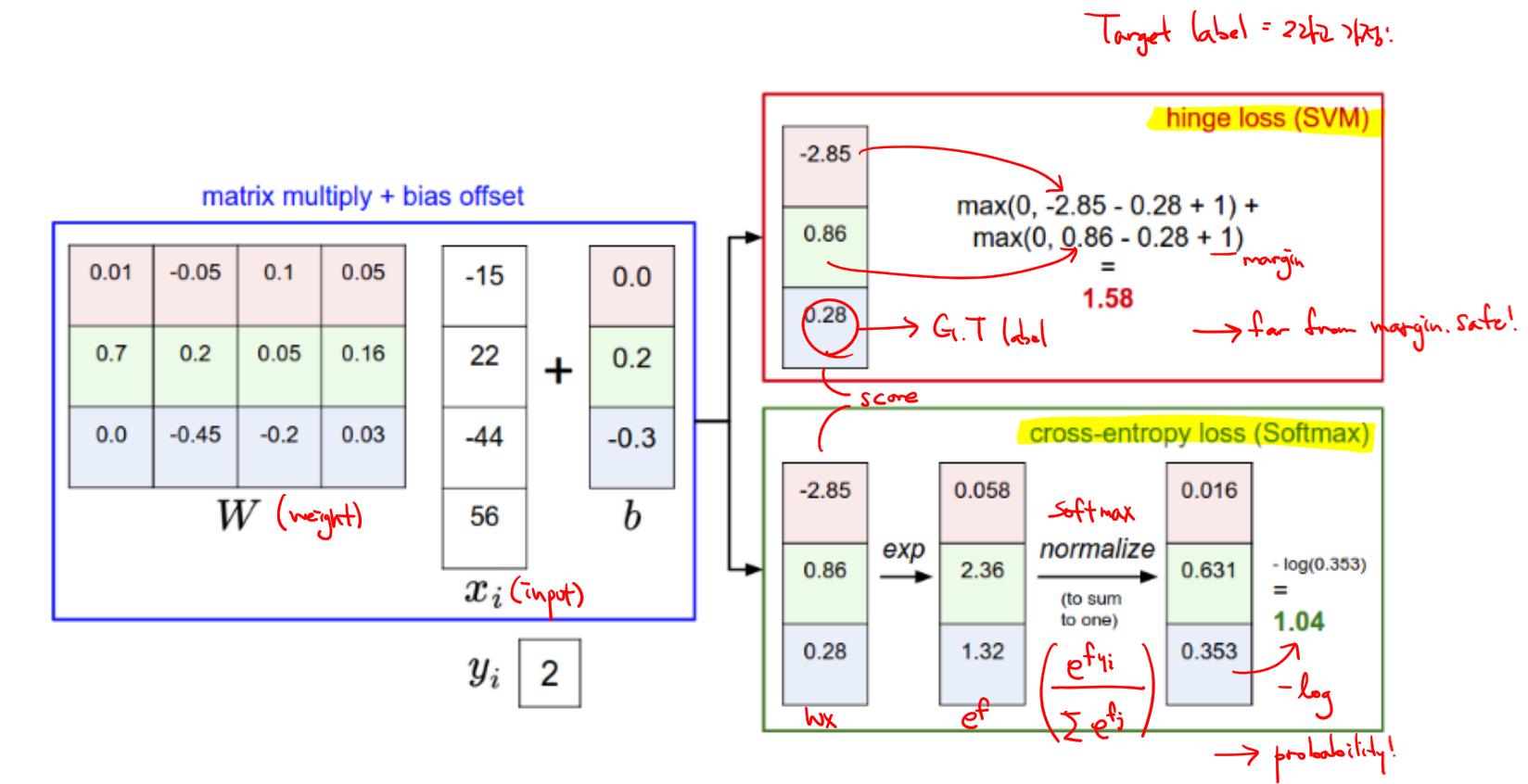
학습할 때는 softmax를 쓰지만 추론할 때엔 one-hot 벡터를 이용하기 때문에 softmax가 필요 없다.
- one-hot: 목표로 하는 인덱스만 1, 나머지는 0으로 만드는 벡터의 표현형식
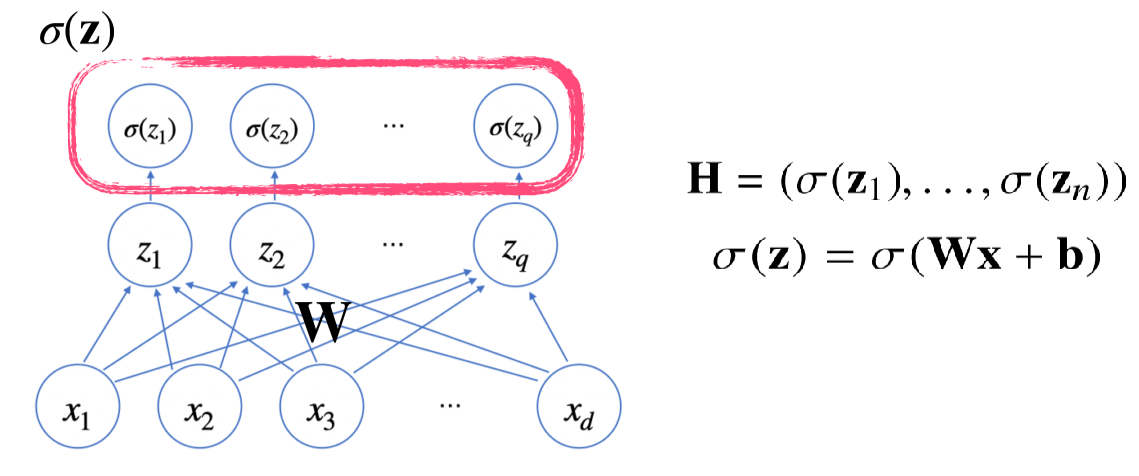
신경망: 선형모델+ 활성함수(activation function)
잠재벡터(z)에 활성함수를 적용해 새로운 잠재벡터(H)를 만든다.
softmax와 activation function의 차이: softmax는 출력물의 모든 값을 고려, activation function는 하나의 실수값만 갖고 변형시켜 새로운 잠재벡터(hidden vector)를 만듬
- Activation function: 선형모델을 비선형적으로 만들게해줌
Relu, tanh(x) 등
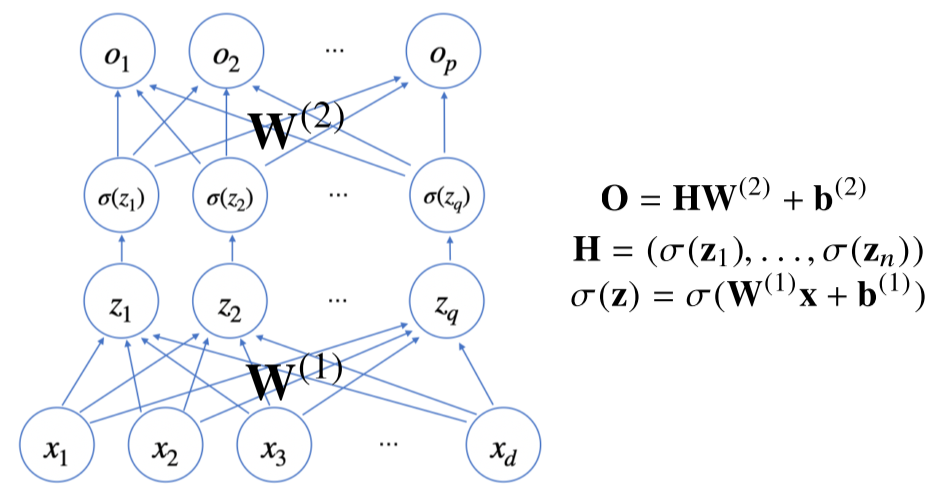
H에서 가중치 W, b를 통해 다시 한번 선형변환해 출력하면 2층(2-layers) 신경망이 된다.
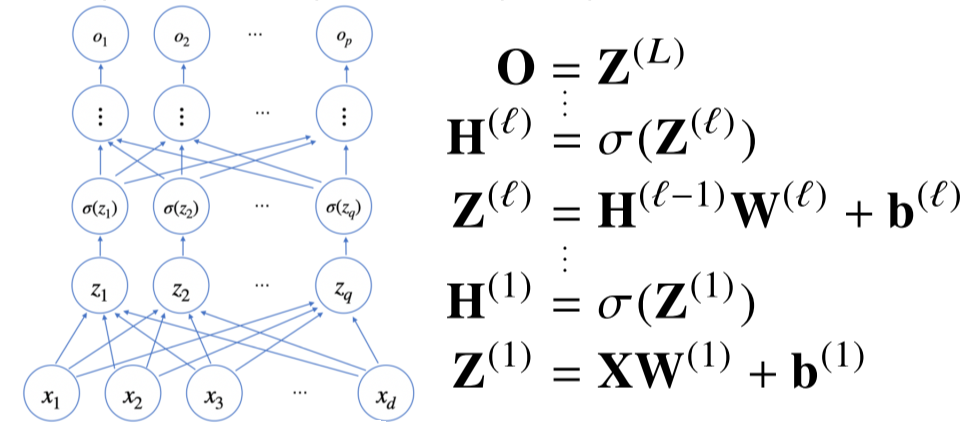
다층 퍼셉트론(MLP)은 신경망이 여러층 합성된 함수 중 대표적 예.
층이 깊을수록 필요한 노드의 숫자가 줄어들어 효율적인 학습 가능.
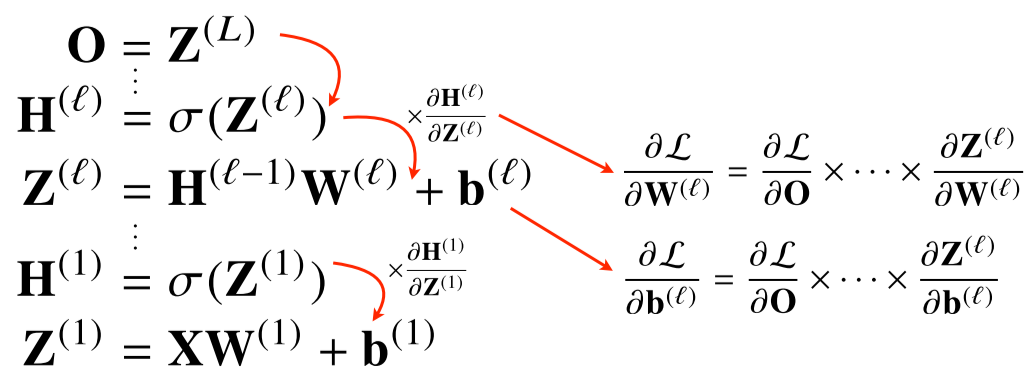
딥러닝은 backpropagation을 이용해 각 층에 사용된 패러미터(W, b)를 학습한다.

즐겁게 개발하기