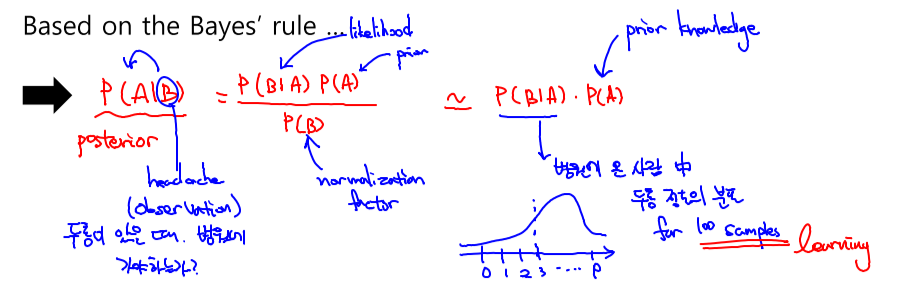
조건부확률
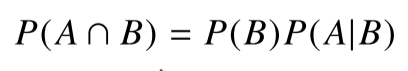
P(A|B): 사건 B가 발생한 상황에서, 사건 A가 발생할 확률(A given B)
-> A와 B가 발생할 확률 = B가 발생할 확률 x B가 발생한 상황에서, A가 발생할 확률
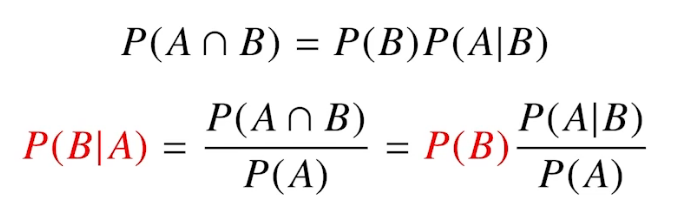
베이즈 정리: A라는 새로운 정보가 주어질 경우 P(B)로부터 P(B|A)를 계산할 수 있게 해줌. 데이터를 통해 정보를 갱신하는 것이 가능하다는 의미.

-
D: 새로 관찰하는 데이터
-
θ: hypothesis, 모수(parameter)
-
P(D|θ): 현재 주어진 parameter에서 이 data가 관찰될 확률, 사전확률이 없을 경우 분석하기 어렵다. 임의로 설정하는 경우도 있음.
-
P(D): data 전체의 분포
-
P(θ|D): data를 관찰했을 때, 이 parameter(θ)가 성립할 확률, 측정 이후의 확률이기 때문
-
P(θ): prior distribution, data에 대해 측정하기 전에 가정한 확률
예시) 병의 발병률이 10%, 병에 걸렸을 때 검진될 확률이 99%, 걸리지 않았을 때 오검진될 확률이 1%라고 할 때, 병에 걸렸다고 검진됐을 때 실제 병에 걸렸을 확률은?
발병률 10%: P(θ) = 0.1
걸렸을 때 검진될 확률 99%: P(D|θ) = 0.99
걸리지 않았을 때 오검진될 확률 1%: P(D|¬θ) = 0.01
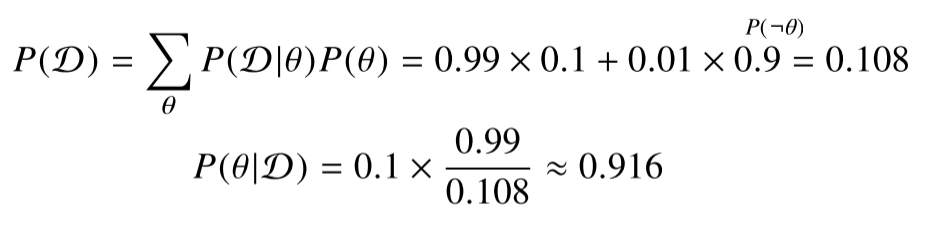
P(D)를 marginal distribution과 조건부확률의 정의를 이용해 구하는 방법
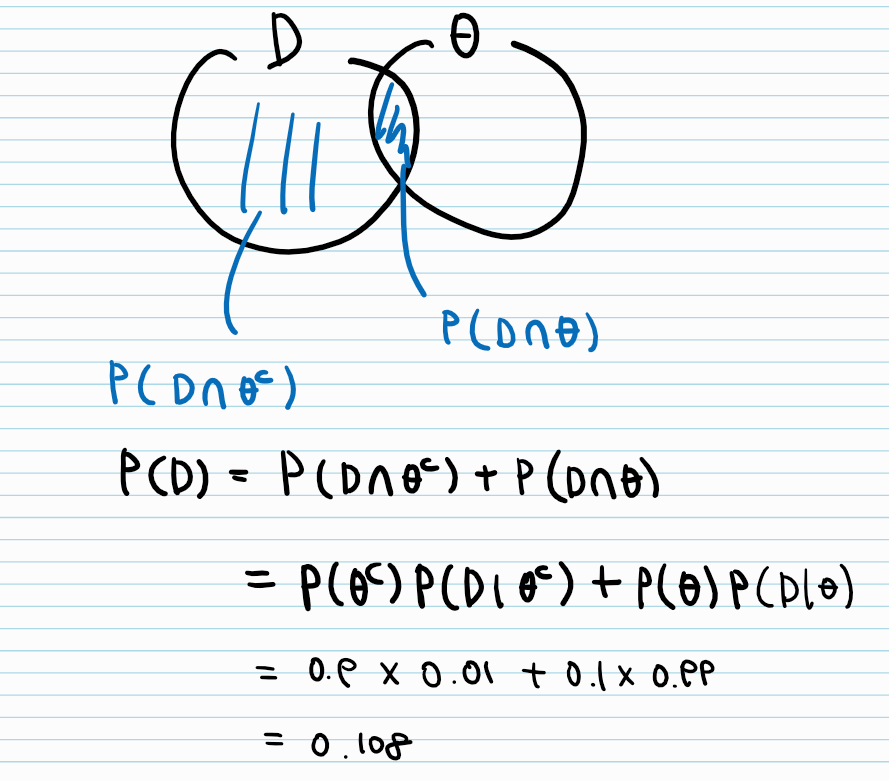
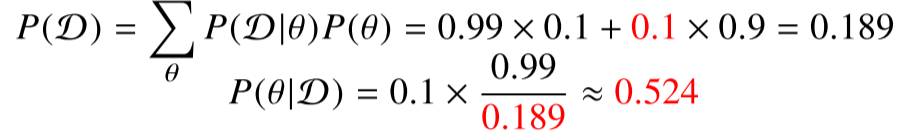
오탐률이 10% 오르면 정밀도가 굉장히 떨어지는 것을 확인할 수 있음.
만약 검사를 2번 했을 경우의 정확도는?
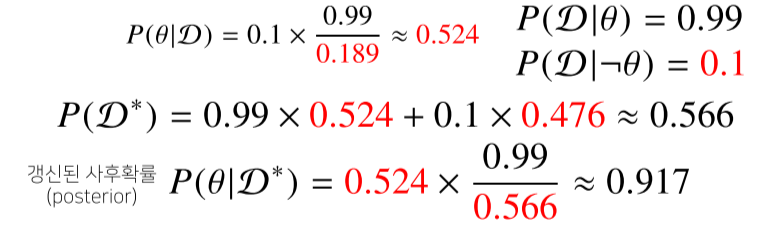
이렇게 데이터가 들어올 때마다 사후확률을 업데이트할 수 있다.
조건부확률의 시각화
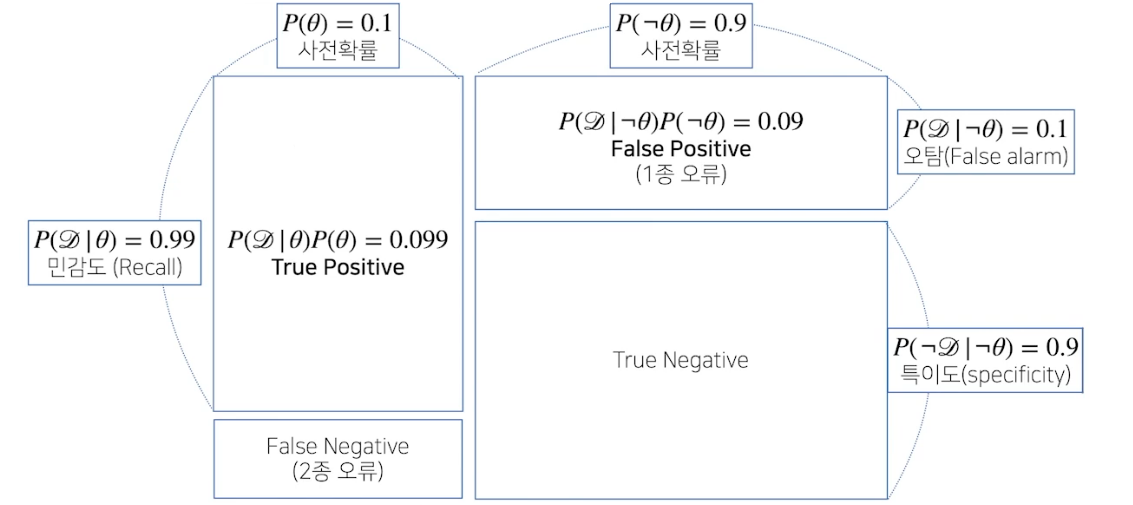
정밀도 P(θ|D): TP / (TP+FP) = 0.916
의료문제 같은 경우 2종오류가 굉장히 중요함(질병인데 아니다라고 판단하기 때문)
조건부확률과 인과관계(causality)

인과관계: 데이터 분포에 강건한 예측모형을 만들때 쓰임. 하지만 인과관계만으로는 높은 예측도를 담보할 수 없다.
조건부확률로 인과관계를 판단할 수는 없다.
인과관계를 판단하기 위해서는 중첩요인(confounding factor) 의 효과를 제거하고 원인에 해당하는 변수만의 인과관계를 계산해야 한다.
예제) 어느 연구에서 키가 클수록 지능지수가 높은 경향이 나타났다.
--> 나이라는 중첩요인을 제거하지 않았기 때문(나이가 많을수록 키도 크고 지능도 높기 때문)
심슨의 역설
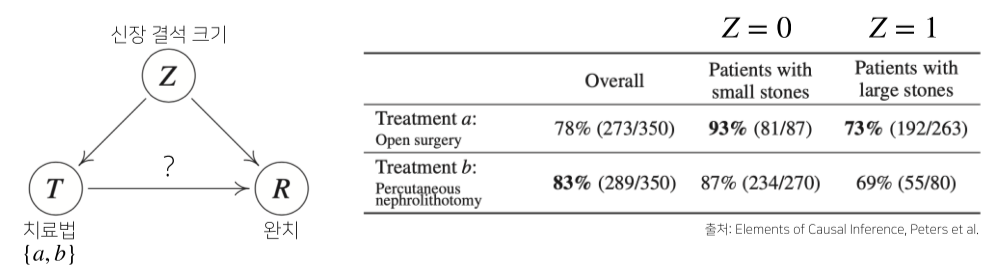
a, b는 신장결석에 대한 치료법이라고 할 때, 각각의 경우엔 a가 완치율이 높으나, 전체적으로 보면 b가 더 완치율이 높다고 나온다.
전체 환자 대비 a, b한테 완치된 숫자로 단순하게 확률을 메겼기 때문.
--> 각 부분에 대한 확률이 크다고 해서 전체에 대한 확률까지 크지는 않다
이를 해결하기 위해 조정효과(intervention)를 통해 Z의 개입(중첩효과)을 제거한다.
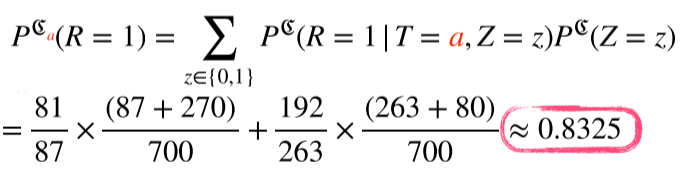
- z=0에 대한 a의 완치율 * 모든 환자 중 z=0일 확률 + z=1에 대한 a의 완치율 * 모든 환자 중 z=1일 확률
다시말해, 모든 환자가 a를 선택했을 때 완치될 확률
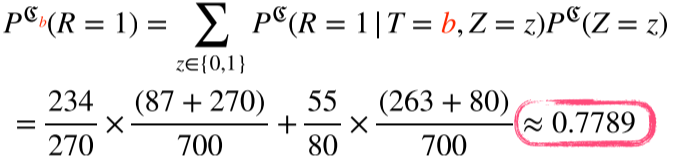
- z=0에 대한 b의 완치율 * 모든 환자 중 z=0일 확률 + z=1에 대한 b의 완치율 * 모든 환자 중 z=1일 확률
다시말해, 모든 환자가 b를 선택했을 때 완치될 확률
중첩효과를 제거 후 모든 환자들이 치료법 a, b를 받을 확률을 계산해보면 a의 확률이 더 높은 것을 확인할 수 있다.
원래는 a의 완치율 * a를 선택한 환자 중 z=0,1일 확률로 단순하게 비교했던 것을 a의 완치율 * 전체 환자 중 z=0,1일 확률로 변경해 계산했기 때문에 올바른 계산을 할 수 있었다.
이를 통해 더 안정적인(robust) 분석이나 예측모형 설계가 가능하다.