Data Augmentation

- NN은 data를 통해 패턴을 분석하는 것이기 때문에 training dataset은 거의 다 biased 돼있어서 real data와는 다른 분포를 띄는 경향이 있음
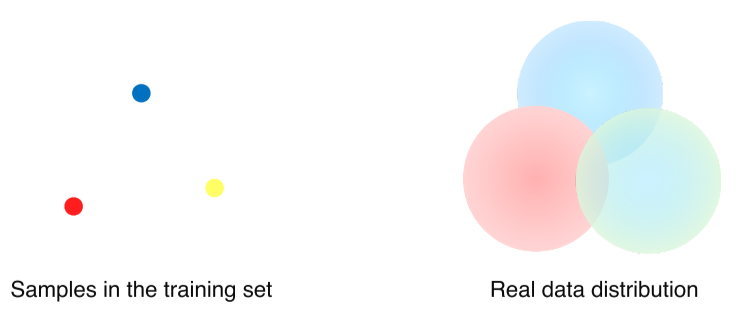
- 또한 real data는 training dataset만큼 명확하게 구분돼있지 않아 분류하기 어려움
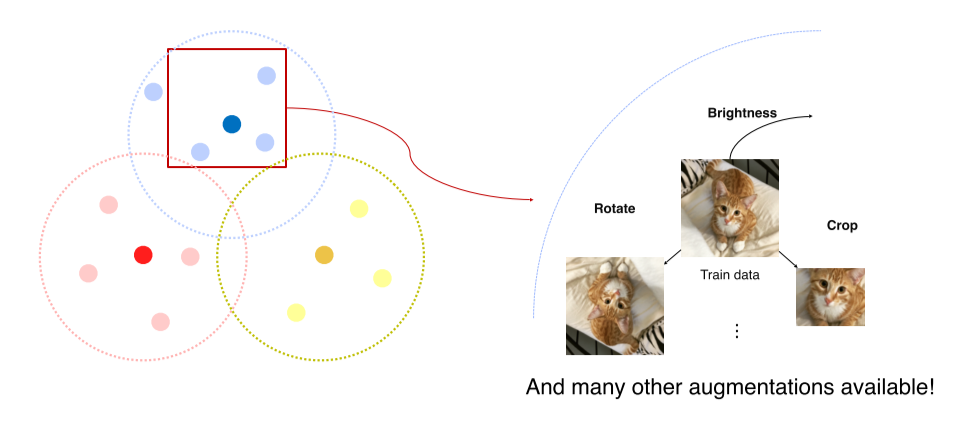
- 이를 해결하기 위해 data augmentation을 통해 train-real data간의 차이를 줄여나감
Augmentation의 종류
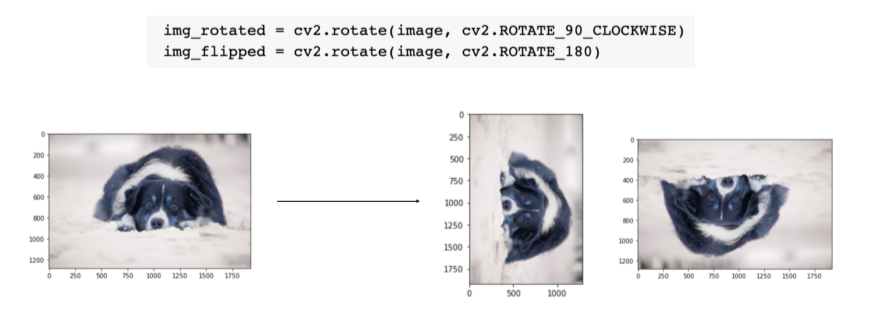
- rotate
- crop

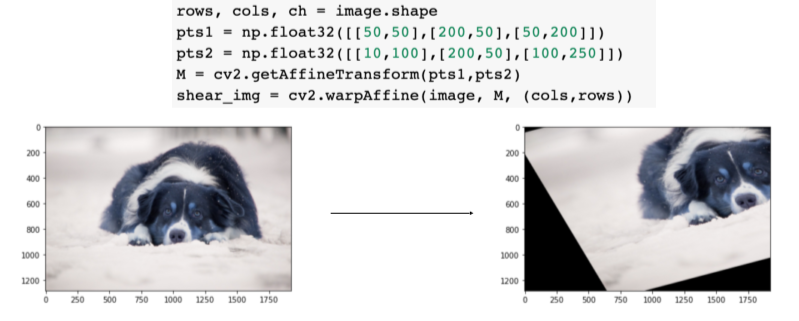
- affine trasform
- cutmix
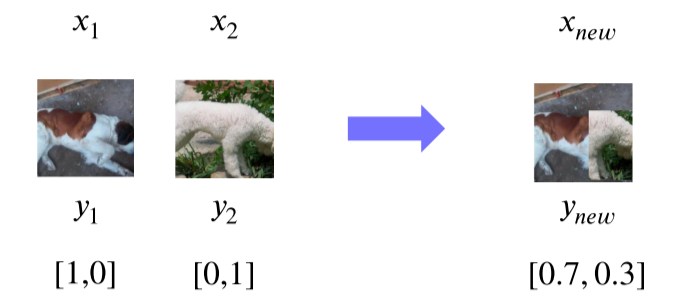
RandAug
-
랜덤하게 적용시키고 그 중 성능이 잘 나오는 것을 사용
Parameter로는 1) 어떤 방법을 적용할 것인지, 2) 얼마나 세게 적용할 것인지 가 있음 -
RandAug의 종류

-
RandAug를 이용해 성능을 손쉽게 높일 수 있음
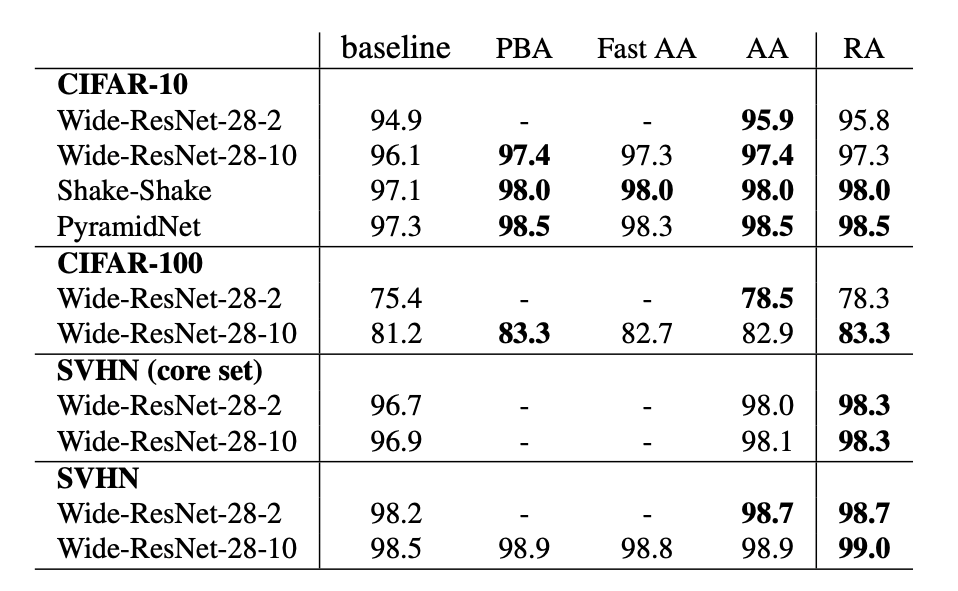
Leveraging pre-trained information
Transfer learning
- 좋은 퀄리티의 dataset을 얻는 것은 비용이 많이 들고, 구하기도 어려움
그래서 한 dataset에서 얻은 정보를 다른 dataset에 적용해보기로 함

- 위 사진에서 보듯 서로 다른 dataset이라도 공, 동물 등 비슷한 정보가 많기 때문에 사용 가능
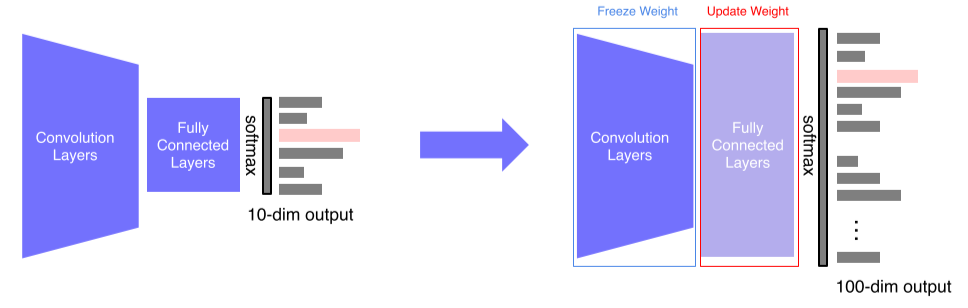
- 방법1: FC layer만 새로 추가
FC layer만 바꿨기 때문에 적은 parameter로도 잘 작동
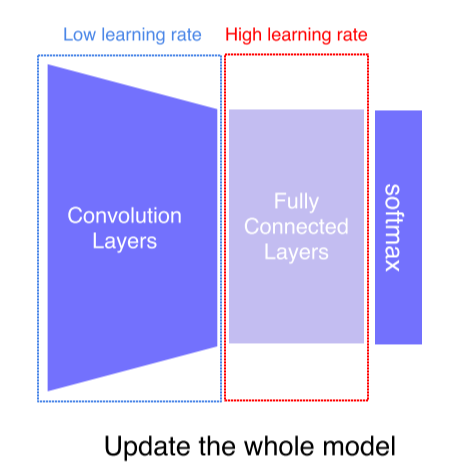
- 방법2: conv layer는 lr을 낮게, fc layer는 lr을 높게 설정해서 학습시킴
첫번째 방법에 비해 조금 더 많은 data가 필요할 수는 있으나 성능은 더 좋음
Knowledge distillation
"미리 잘 학습된 큰 네트워크(Teacher network) 의 지식을 실제로 사용하고자 하는 작은 네트워크(Student network) 에게 전달하는 것"
-
NIPS 2014 workshop에서 발표한 논문 “Distilling the Knowledge in a Neural Network”에서 처음으로 등장한 개념
-
앙상블과 같은 복잡한 모델이 학습한 generalization 능력을 단순한 모델에 transfer해주는 좀 더 일반적인 방법
-
원래는 큰 모델(teacher model)에서 작은 모델(student model)로 지식을 주입해서 학습하는데 주로 쓰였음
-
요즘은 teacher model을 이용해 unlabeled data의 pseudo-label(가짜 label)를 자동 생성하는 방법을 사용
-
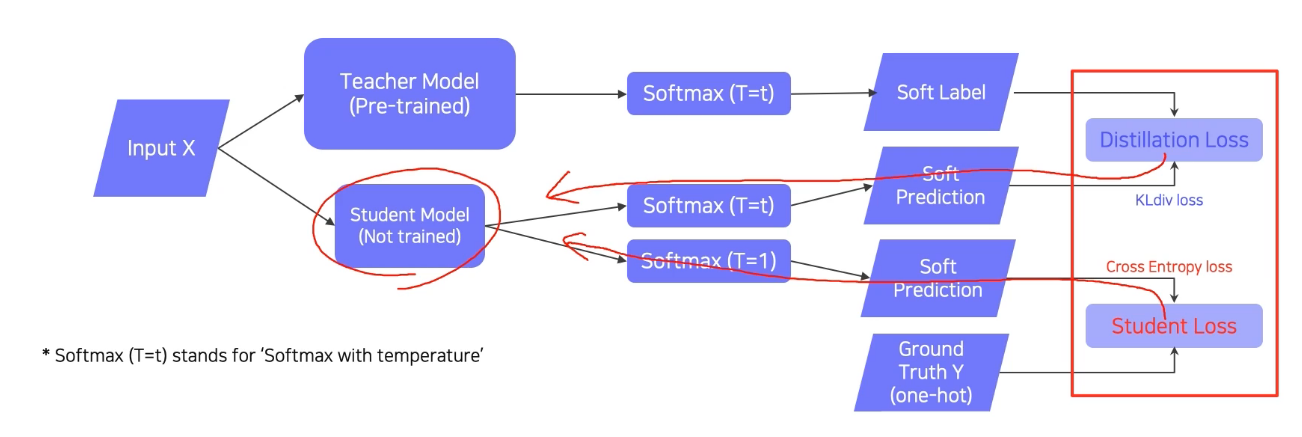
동일한 input에 대해서 student model만 학습시켜서 student가 teacher을 따라하게 되는 학습법
-
Soft label은 pre-trained에 사용된 이전의 task들과 연관이 되어있긴 하지만 label을 공유하지 않는다던가, 카테고리가 겹치지 않는다던가 하는 이유로 GT와 큰 연관이 없을수도 있다
-
따라서 각각의 값이 중요한 의미를 갖고있다기 보다는 전체적인 개형을 나타내고, student model이 그것을 따라하게 만든다는 것이 중요하다
-> semantic information is not considered in distillation
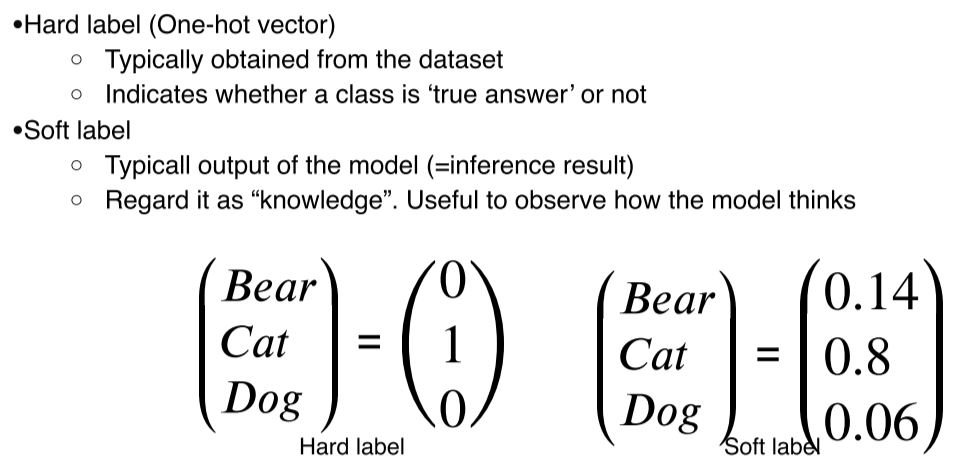
Soft label: inference result의 softmax값으로, model이 input을 어떻게 보고 있는지에 대한 확률값을 나타냄
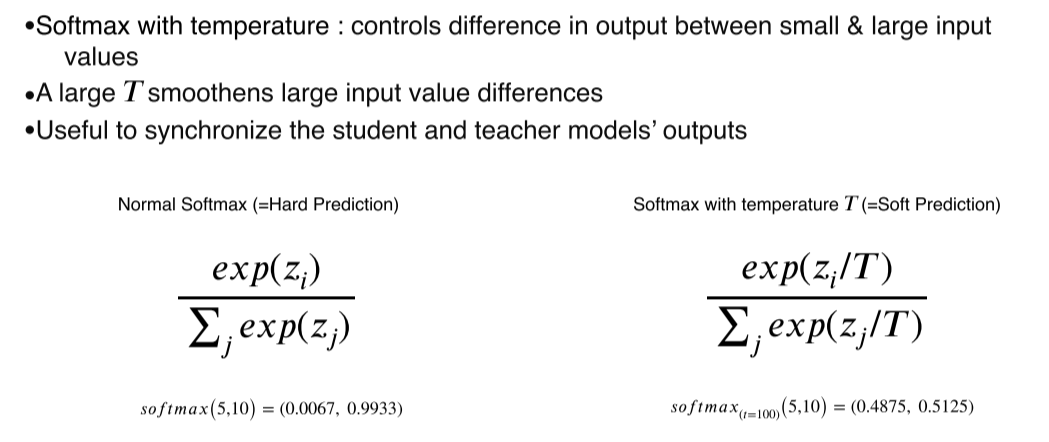
- 그냥 softmax를 하면 입력값의 차가 극단적으로 커지게 된다
그래서temperature라는 큰 값으로 나눠서 softmax하면 출력을 smooth하게 만들 수 있음

- Distillation loss에 KL-div를 쓰는 이유
- teacher model의 soft label이 one-hot vector처럼 categorical하게 나오지는 않고,
- soft label의 특징 (ground truth와 같은 정확한 정답이 아니라 teacher model이 판단하는 값이라는 것)을 모방하려고 KL div를 쓰는거라서
- 최종적으로 backpropagation은 distillation loss, student loss를 모두 고려해 진행됨
Leveraging unlabeled dataset for training
Semi-supervised learning
- Supervised data는 구축하는데 한계가 있기 때문에 unlabeled data를 사용하기 위한 방법
- 많은 수의 unlabeled data와 적은 수의 labeled data를 둘 다 활용
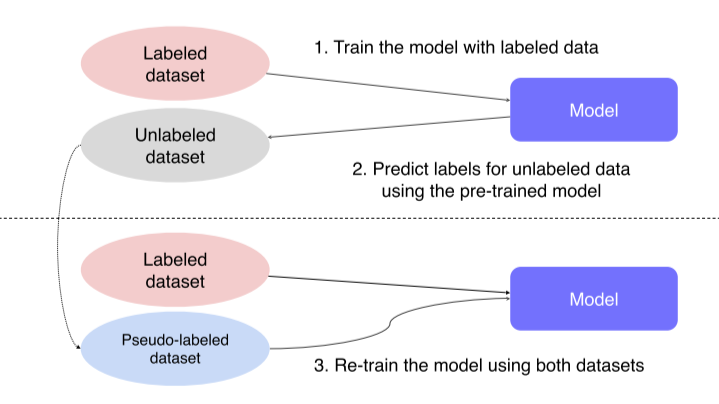
- 적은 양의 labeled data로 model을 학습
- Unlabeled data를 labeling해서 pseudo-labeled data로 만듬
- Labeled data, pseudo-labeled data로 다시 model을 학습
Self-training
Self-training with Noisy Student improves ImageNet classification에서 처음 등장한 방식
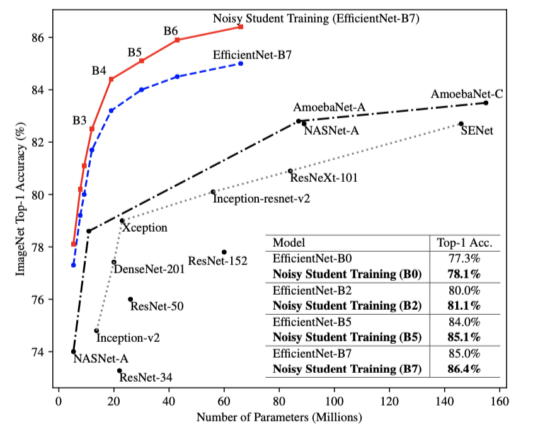
- Augmentation + Teacher-Student networks + semi-supervised learning
- 2019년 imagenet 분류 태스크에서 SOTA를 달성
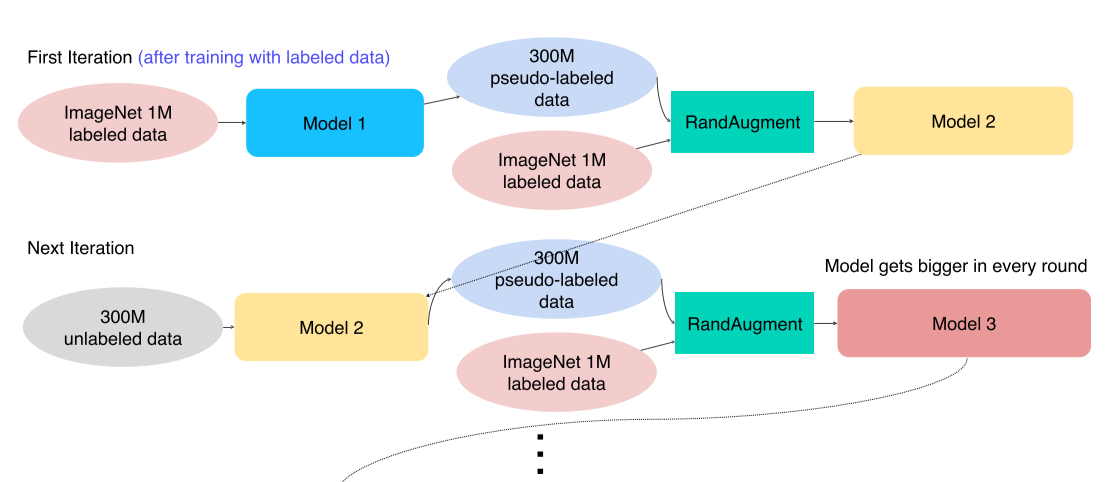
- Labeled data로 teacher model을 학습
- Unlabeled data를 labeling해서 pseudo-labeled data로 만듬
- Pseudo-labeled data에 noise를 첨가해 student model을 학습시킴
1) input noise : RandAugment를 사용한 data augmentation
2) model noise : dropout, stochastic depth - 이전 teacher network를 날리고, student를 teacher로 올림
새로운 student는 조금씩 더 커짐
-
Unlabeled data는 300M의 고정된 unlabeled data를 매번 pseudo-labeling
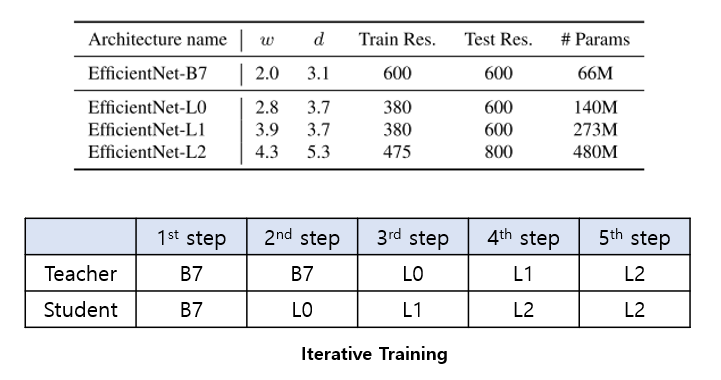
-
Teacher와 Student 모두 EfficientNet-B7 로 학습을 진행
-
Teacher는 EfficientNet-B7, Student는 EfficientNet-L0로 학습을 진행
-
Teacher는 EfficientNet-L0, Student는 EfficientNet-L1으로 학습을 진행
-
Teacher는 EfficientNet-L1, Student는 EfficientNet-L2로 학습을 진행
-
Teacher는 EfficientNet-L2, Student는 EfficientNet-L2로 학습을 진행
Reference

