[U-stage] Computer Vision
1.CV 1강) Image Classification
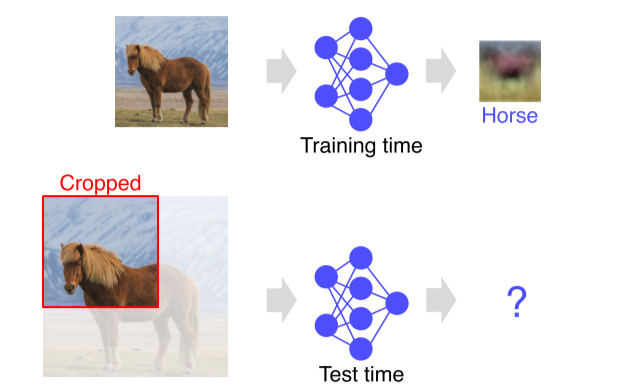
Computer Vision이란? High-level description은 representation이라고도 불림 CV는 Computer Graphic가 하는 일의 반대 사람의 시각 구조도 불완전하기 때문에 이를 어떻게 보완해야 할지도 생각해야함  Annotation Data Efficient Learning

Training dataset은 거의 다 biasedReal data는 training dataset만큼 명확하게 구분돼있지 않아 분류하기 어려움그래서 data augmentation을 통해 차이를 줄여나감rotatecropaffine trasformcutmixRand
3.CV 3강) Image Classification 2
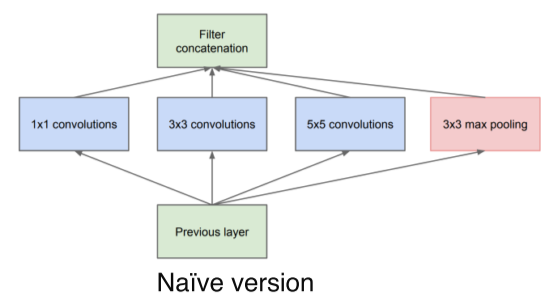
AlxeNet --> VGGNet에서 layer를 깊게 쌓을수록 성능이 높아진다는 것을 확인함larger receptive fieldmore capacity and non-linearity하지만 deeper layer는 harder to optimizergradient
4.CV 4강) Semantic Segmentation

Image classification을 영상 단위가 아니라 pixel 단위로 시행같은 class는 모두 같은 물체로 판단영상 컨텐츠에 대한 이해특정 object에 대한 처리(computational photography)DeepLab
5.CV 5강) Object Detection
Detection with Transformer
6.CV 6-1강) CNN Visualization
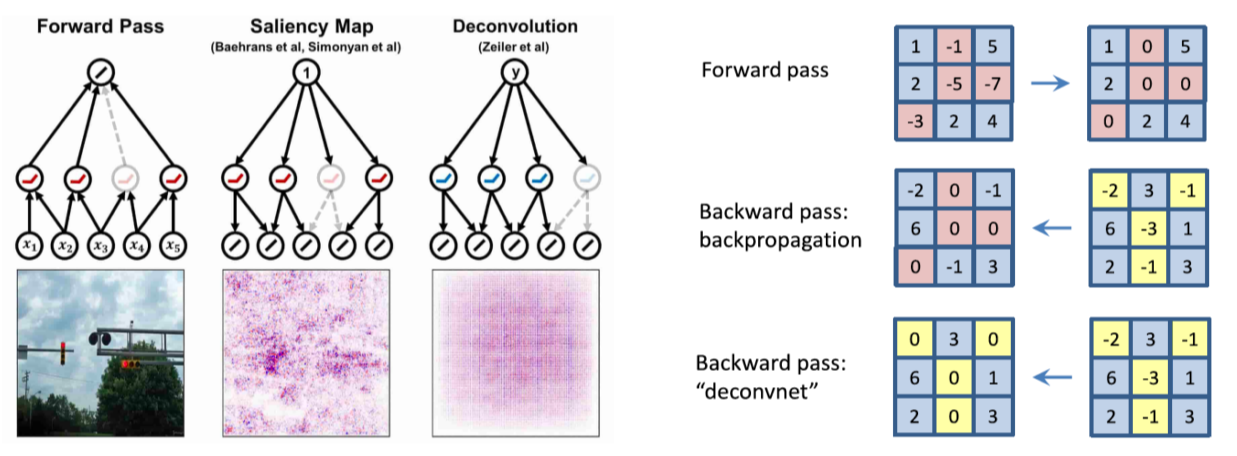
CNN 시각화 CNN은 non-linear activation function이 이어진 연산기 하지만 black box라고 불릴만큼 해석이 어려움 CNN을 시각화 한다는 것은 디버깅 도구를 갖는다는 것과 같은 의미 안에 뭐가 들어있고, 왜 좋은 성능이 나오고, 어떻
7.CV 6-2강) AutoGrad
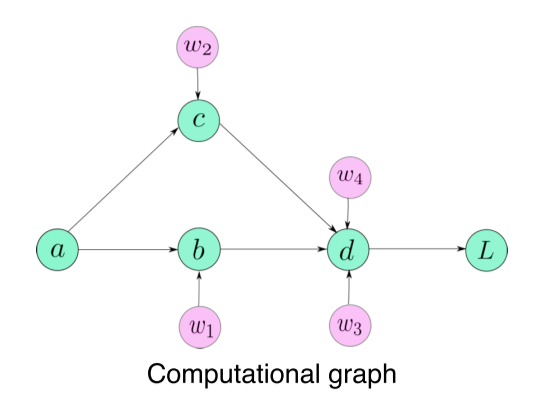
Exercise Saliency map을 구하기 위해서 필요한 기본적인 구현 디테일을 익힘 Autograd: Automatic gradient API 대부분의 DL library의 고유한 기능 행렬 연산 뿐만 아니라 Forward, backward pass 계산을 가능하게 해줌 Computational graph라는 구조를 이용해 automa...
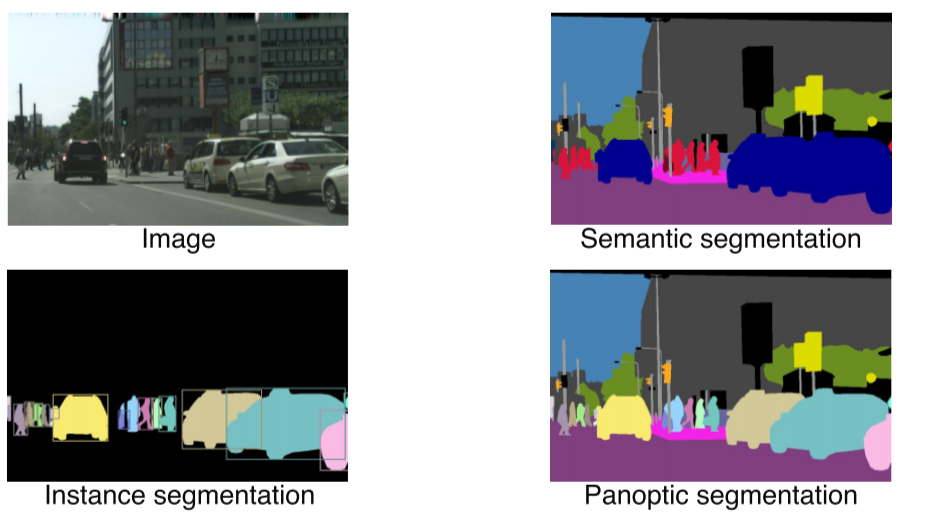
8.CV 7강) Instance/Panoptic Segmentation and Lankmark Localization
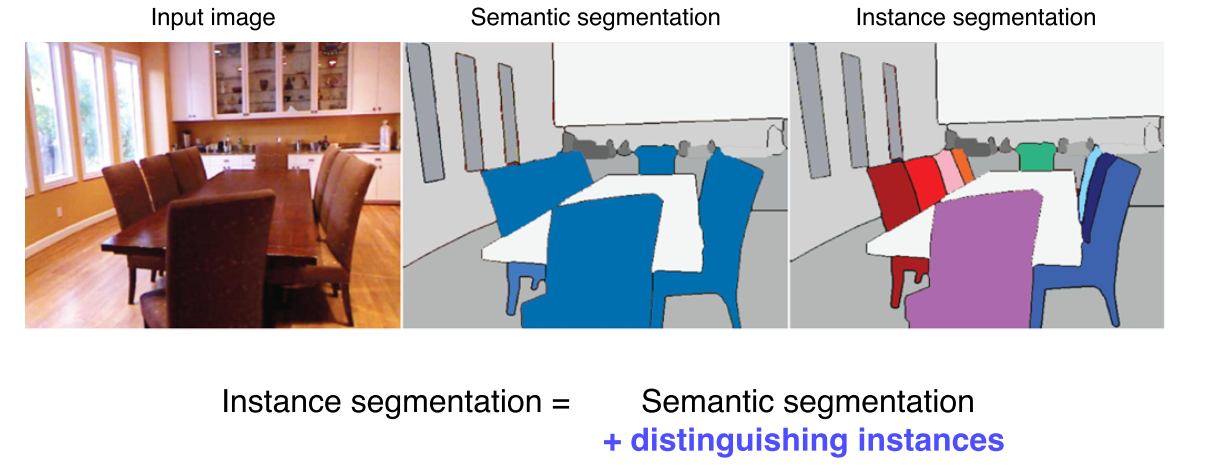
같은 물체라도 instance에 따라 구분Semantic segmentation + Digtingushing instances기존의 Faster R-CNN과 거의 동일한 구조RoIAlign이라는 새로운 pooling layer를 제안, interpolation을 통해
9.CV 8강) Conditional Generative Model
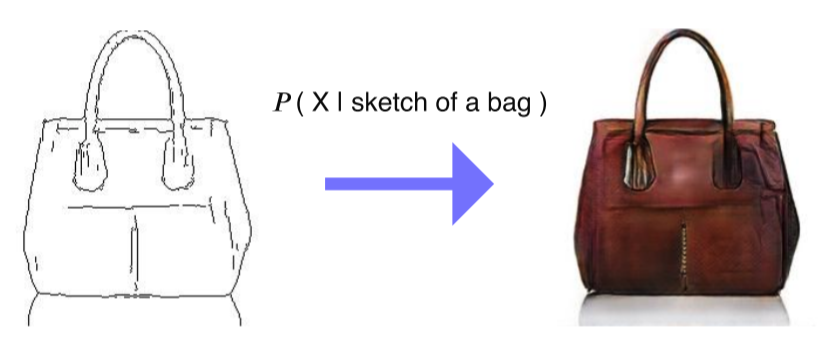
Condition이 주어졌을 때, 조건에 해당하는 결과가 나오는 형태기존 generative model은 image나 sample을 생성할 수는 있지만, 조작은 할 수 없었음Conditional generative model은 user의 의도를 반영해 응용 가능성을 높
10.CV 9-1강) Multi-modal Learning
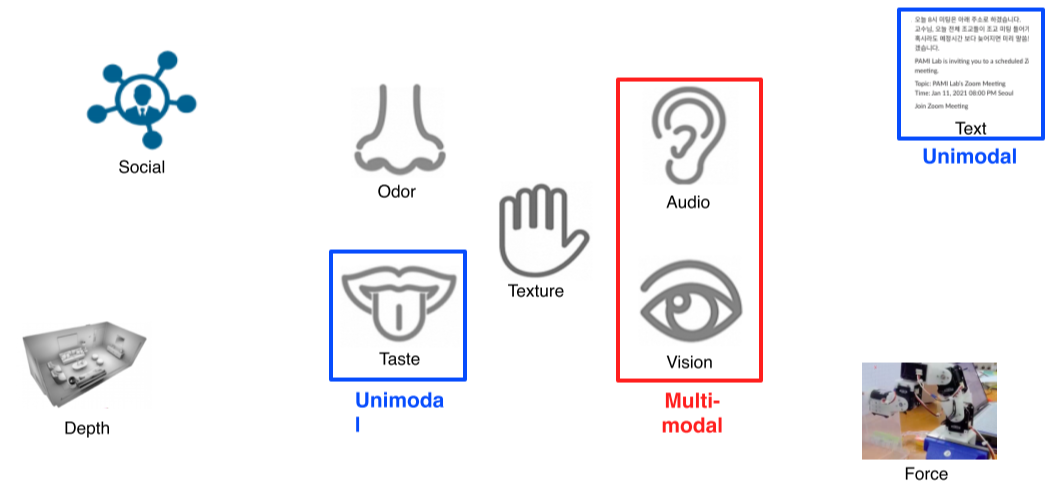
Multi-modal Learning 한가지 타입의 data가 아니라 여러가지 타입의 data를 함께 사용하는 방법 CV라 vision centric하게 다룰 예정 Challenges Data 표현 형태가 제각각이라 다루기가 어려움 정보의 양과 feature s
11.CV 9-2강) Image Captioning

Image captioning 구현 구조 분석Pre-trained CNN을 사용Resnet101의 마지막 2개 layer는 linear, pooling layer로, logit을 출력하기 때문에 제외우리가 필요한 것은 spatial feature를 유지하는 tenso
12.CV 10강) 3D Understanding
현실은 3D라 현실 관련 task는 모두 3D를 다룸AR/VR, 3D printing, medical application 등 다양한 application이 존재Image는 3D를 2D로 투사(projection)한 형태Triangulation(삼각측량법)으로 2D i
13.CV 과제 관련 이슈

https://stackoverflow.com/questions/59013109/runtimeerror-input-type-torch-floattensor-and-weight-type-torch-cuda-floatteinput, label, model 중 일부