Semantic Segmentation
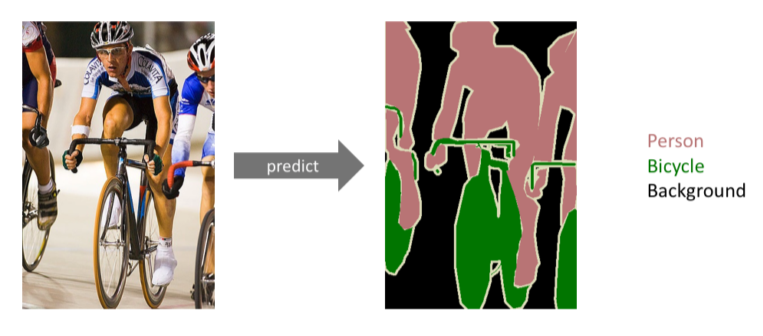
- image의 모든 pixel이 어떤 label에 속하는지 분류하는것

- 자율주행에 많이 활용이 됨
Fully Convolutional Network
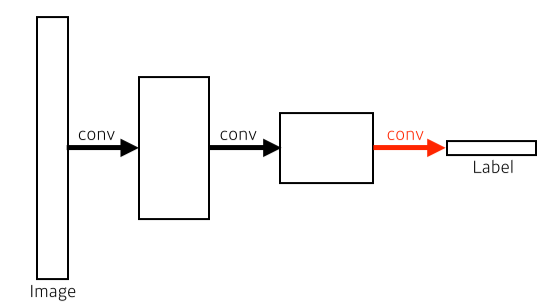
- dense(fully-connected) layer를 제거
하지만 parameter 수는 변하지 않는다
Convolutionalization

- left: 4*4*16*10 = 2560
- right: 4*4*16*10 = 2560
- 이를 convolutionalization이라 부른다
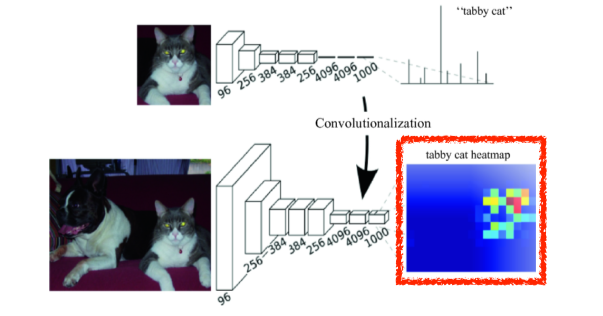
- Fully Convolutional Network는 input의 spatial dimension에 independent하다
- input image가 spatail하게(width, height가) 커지든 작아지든 상관없이 동일한 convolution filter가 찍기 때문에 result만 같이 커지지 여전히 동작시킬 수 있다
--> heatmap*과 같은 효과
* heatmap: 많은 양의 다차원 데이터를 시각화하는 데 적합하며 유사한 값의 행 클러스터를 유사한 색 영역으로 표시하여 식별하는 데 사용할 수 있다
Deconvolution(conv transpose)
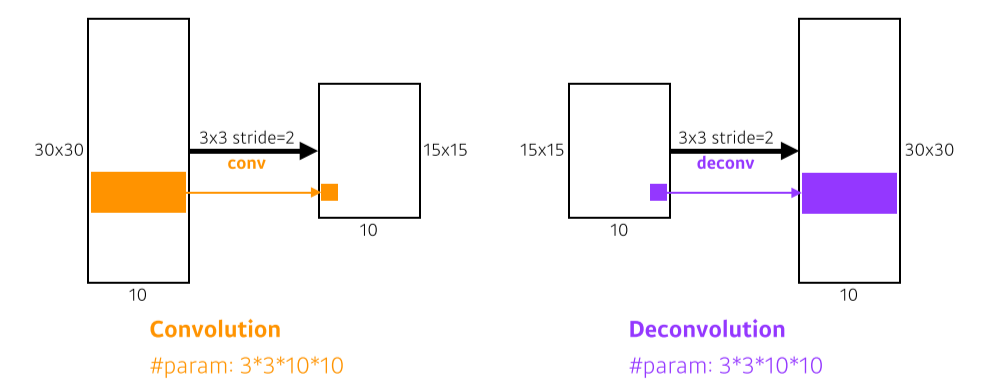
- 엄밀히 말해 convolution의 역은 아니지만 동작 방법이나 input/output의 관점에선 똑같다
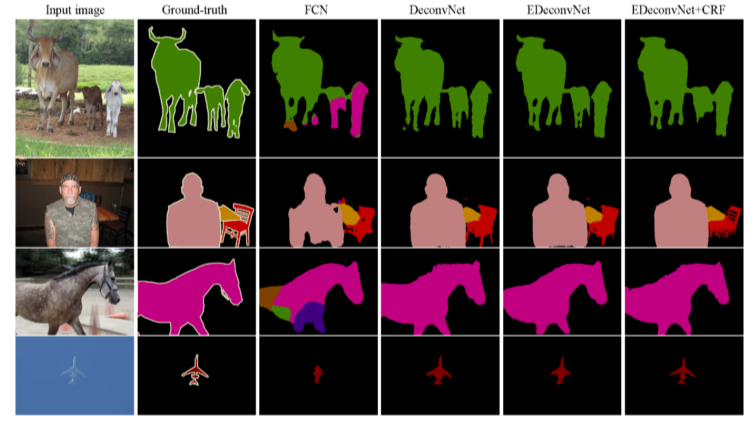
Result
Detection
R-CNN
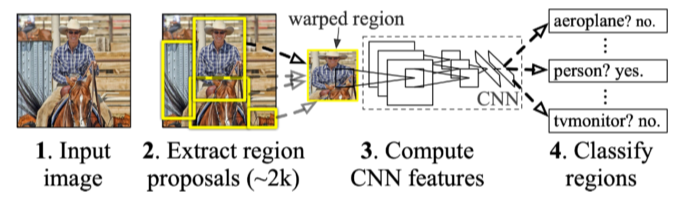
- 2000개의 region을 뽑아냄
- 똑같은 크기로 맞춤(CNN을 돌리기 위해서)
- CNN을 2000번 돌림
- linear SVM으로 분류
Result

- 대략 어느 위치에 어떤 물체가 있는지 나오긴 하지만 정확하지는 않다
SPPNet
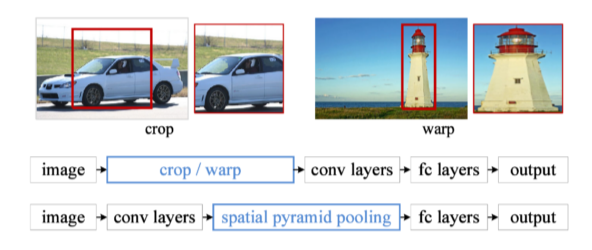
- image를 일단 다 뽑아서 image 전체에 대한 convolutional feature map을 만든 후, 뽑힌 bounding box에 해당하는 feature map의 tensor만 끌고오자
- convolutional layer는 1번 돌고 tensor를 끌고오는 작업만 region별로 하기 때문에 R-CNN보다 빨라짐
--> 이전에는 region마다 conv layer에 넣기 위해 동일한 크기로 맞췄는데, 이젠 그냥 크기 상관없이 conv layer에 넣고 f-c layer 통과 전에 feature map을 통일한 크기로 조절하는 pooling을 적용하자!
Fast R-CNN
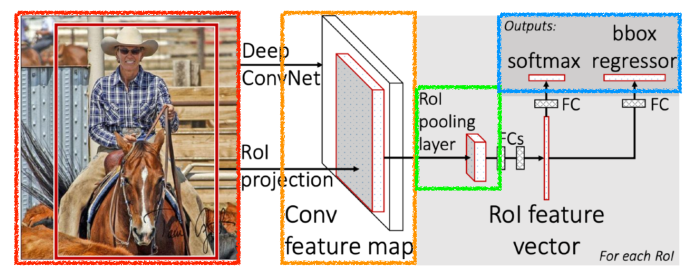
- SPPNet과 동일하나 RoI feature vector(NN)을 통해 bounding box regression과 classification했다는게 차이
Faster R-CNN
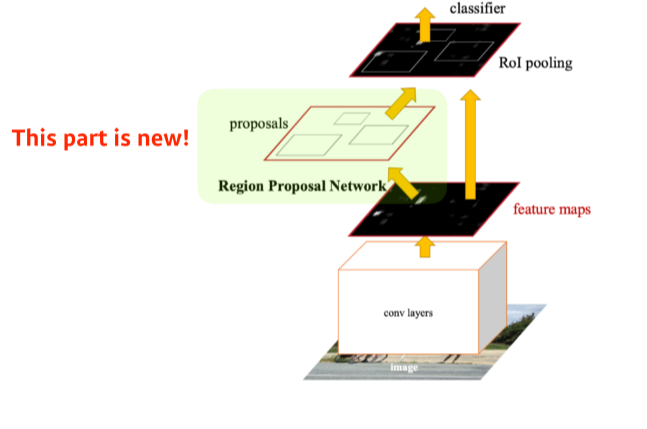
- bounding box를 뽑아내는 region proposal도 학습을 시키자
(Region Proposal Network)
Region Proposal Network
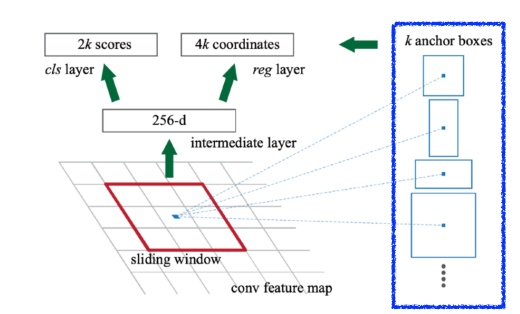
- image에서 특정 영역이 bounding box로써의 의미가 있을지 없을지(안에 물체가 있을지 없을지)를 판정
그 물체가 무엇인지는 나중에 구별 - anchor box: detection boxes with predefined sizes(template)
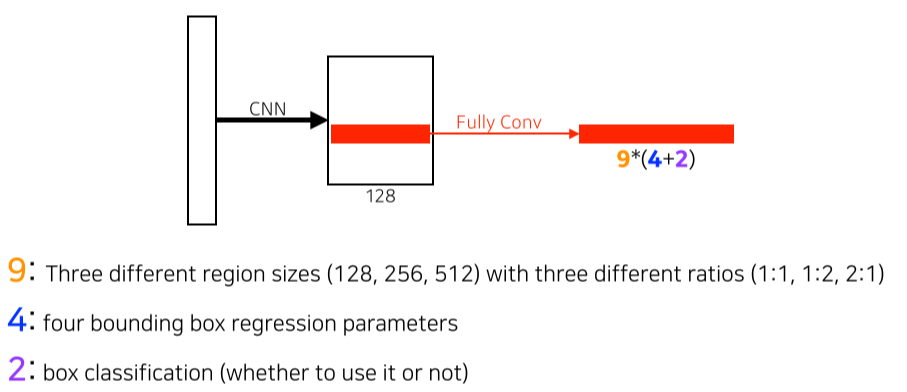
- 9: 3 sizes * 3 ratios
- 4: 2 offset(x, y) * 2(늘릴지 줄일지)
- 2: 쓸지 안쓸지
Result

YOLO

- 굉장히 빠른 성능을 자랑
동작원리

- 이미지를 SxS개의 grid로 나눔

- 각각의 cell은 B개의 bounding box를 예측
- 셀마다 box의 x, y, width, height + 쓸모 있는지/없는지를 예측

- 각 bounding box 혹은 grid에 속하는 object가 어떤 class인지 예측

- 결국 box와 box의 정보를 예측할 수 있다
Result


즐겁게 개발하기