
ILSVRC

- https://www.image-net.org/challenges/LSVRC/
- 이미지 인식 경진대회
AlexNet
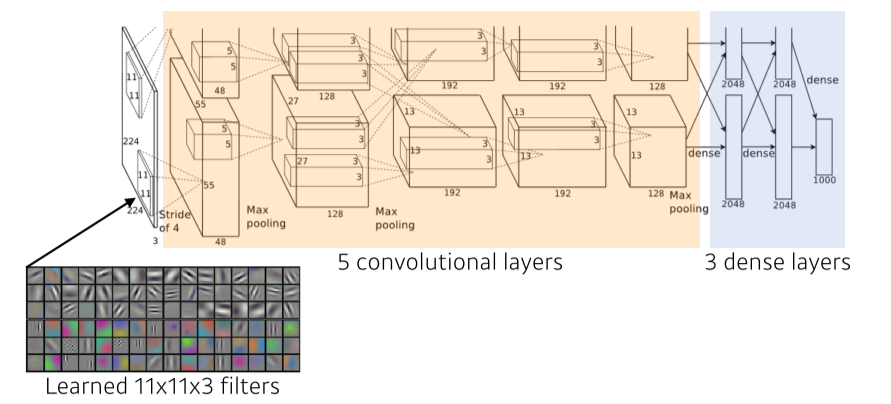
- 당시 GPU 성능이 부족했기 때문에 최대한 많은 parameter를 넣고 싶어서 GPU를 2개 사용하고, 그에 따라 모델을 2개로 분리
- ReLU를 사용해 gradient vanishing을 해결
- Data augmentation, Dropout 사용
VGGNet
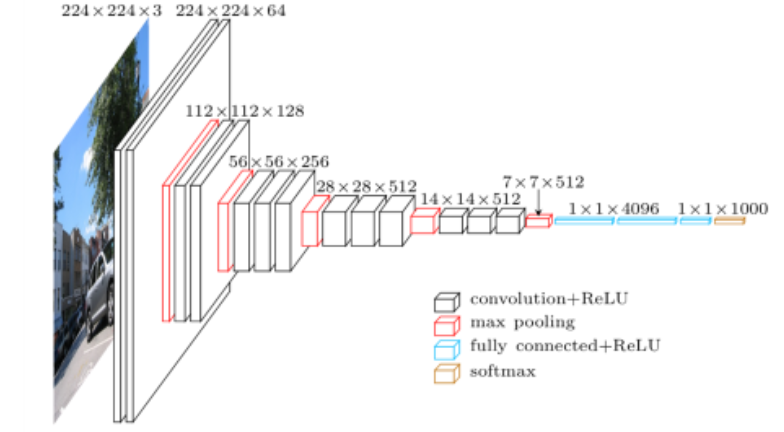
- 3x3 filter만 사용
- 1x1 convolution for fully-connected layer
그러나 parameter를 줄이려고 사용한건 아니라 중요x - Dropout(p=0.5)
- VGG16, VGG19
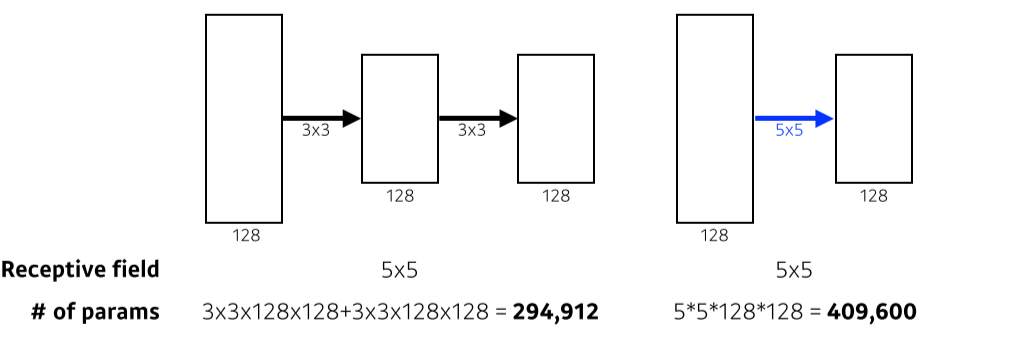
- Receptive field: 1개의 convolution pixel이 고려하는 input의 크기
- 3x3을 2번 사용하면 5x5 영역을 다루면서, 5x5 filter를 쓴것보다 parameter 수를 줄일 수 있다
GoogLeNet
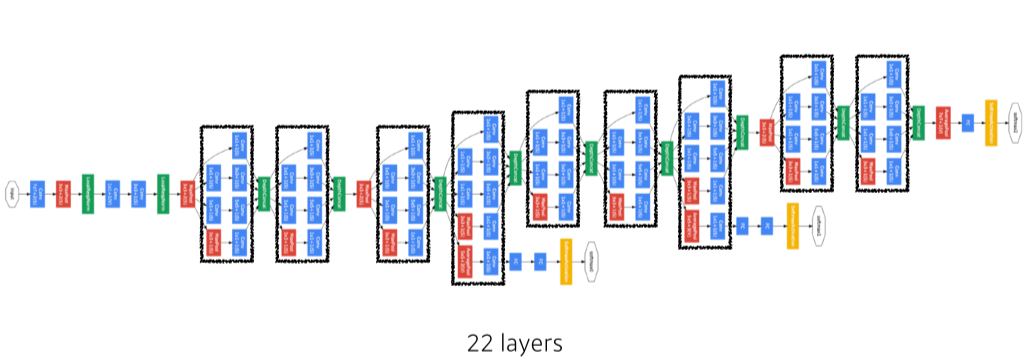
- NiN: Network in Network
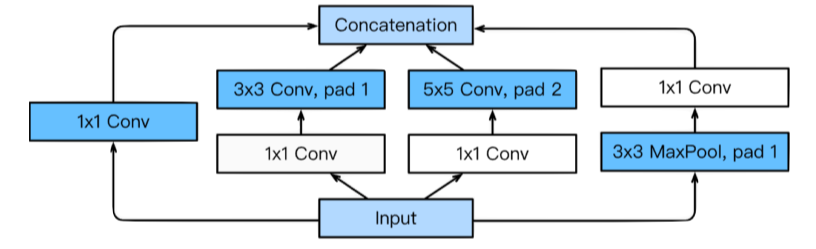
- Inception Block: patameter 수를 줄일 수 있음
- 1x1 conv가 channel 방향 dimension을 줄일 수 있다
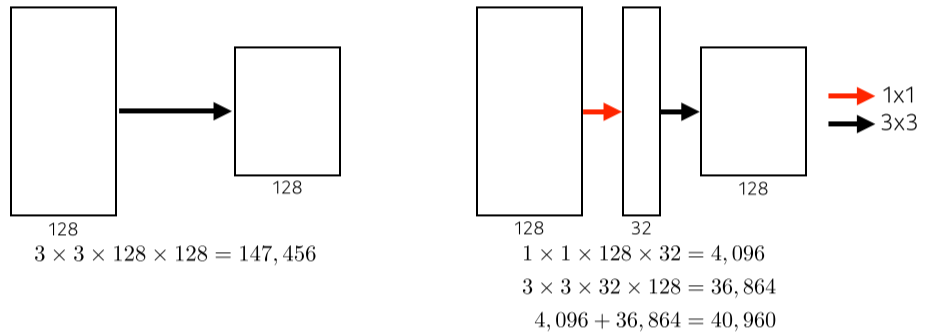
- 1x1 conv가 parameter 수를 30% 정도 줄일 수 있음
ResNet
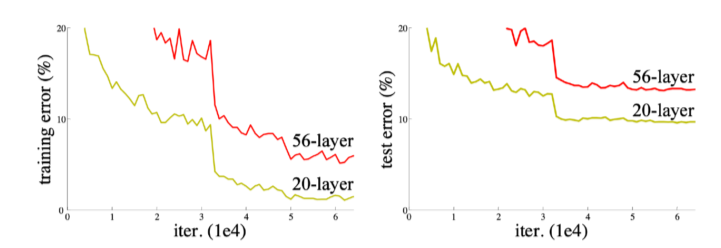
- 기존의 DNN은 깊게 쌓을수록 gradient vanishing/exploding에 의한 degradation이 일어남
(56-layer가 error가 더 큼)
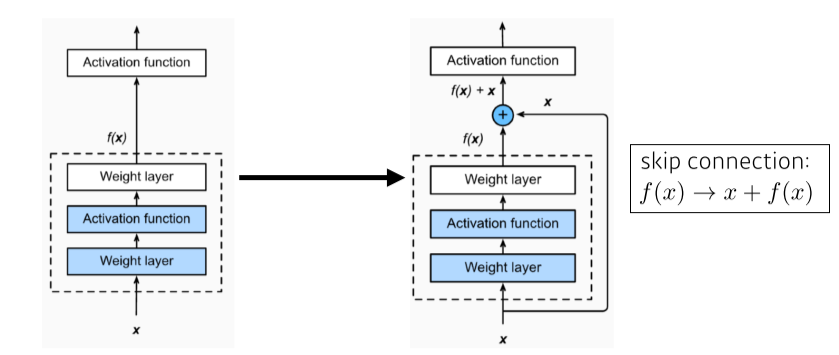
- Conv layer output에 input을 더해서, model이 residual(input과의 차이)만 학습하게 만듬
- 이러면 backpropagation에서 x 때문에 gradient가 최소 1이 돼서 vanishing을 방지할 수 있음
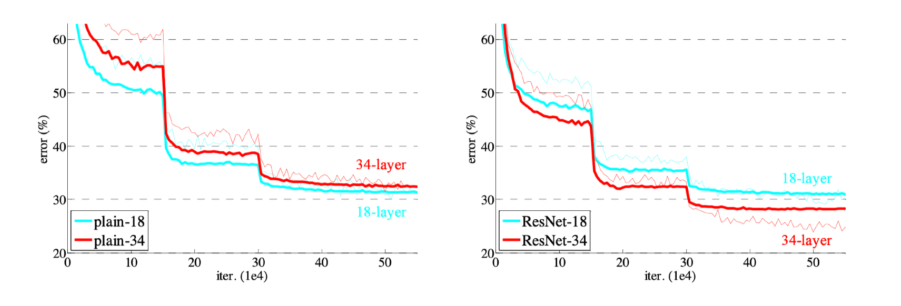
- layer를 많이 쌓아도 overfitting 되지 않는걸 볼 수 있다
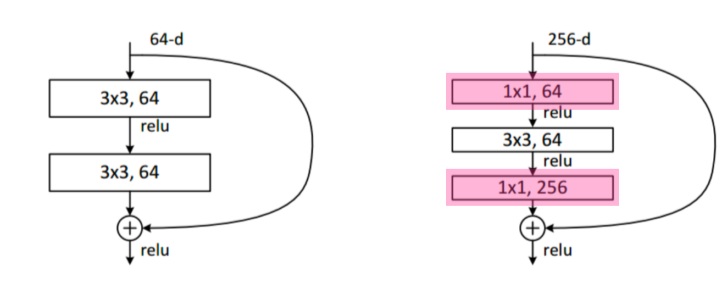
- Bottleneck Architecture
3x3 conv 앞뒤로 1x1 conv 넣어서 input, output channel을 줄임
DenseNet
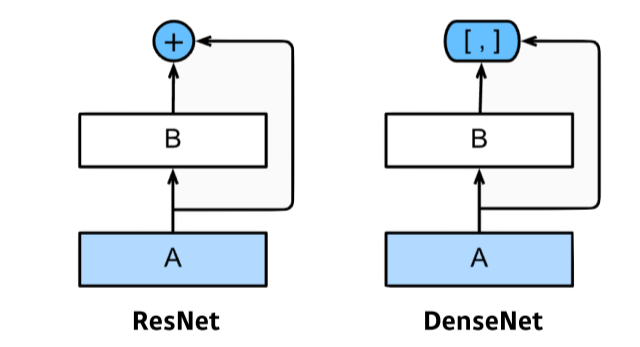
- addition 말고 concat
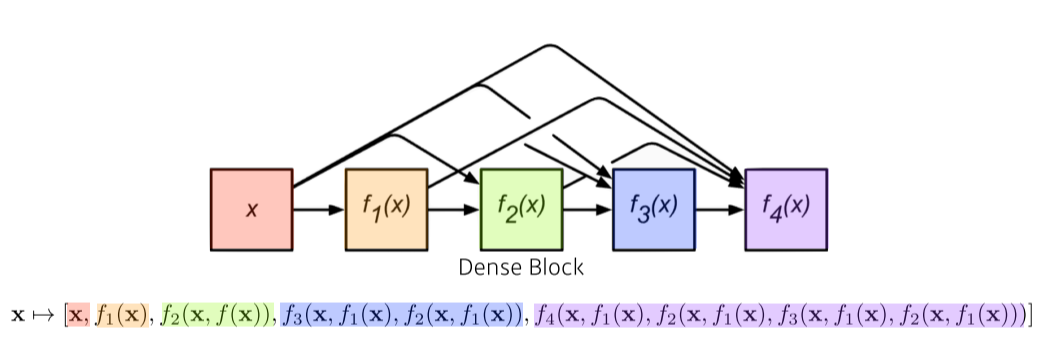
- 하지만 계속 concat하면 channel 수가 늘어난다는 단점이 있음
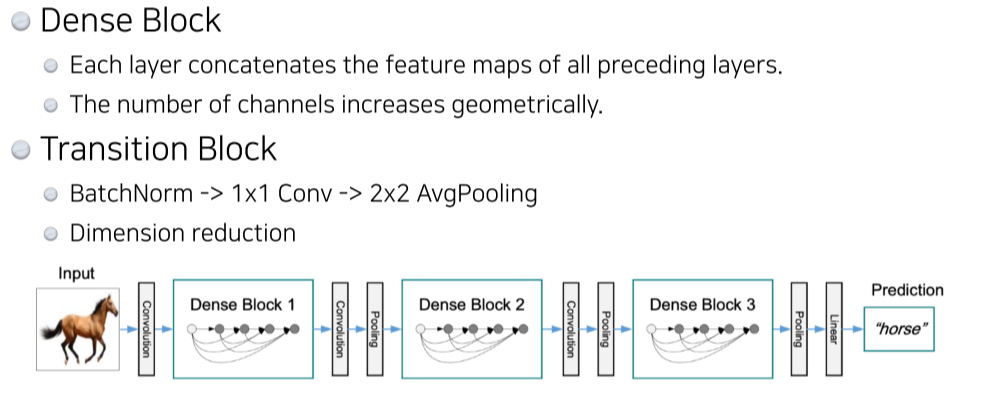
정리


즐겁게 개발하기