[U-stage] DeepLearning Basics
1.DL Basic 1강) 딥러닝 기본 용어 설명
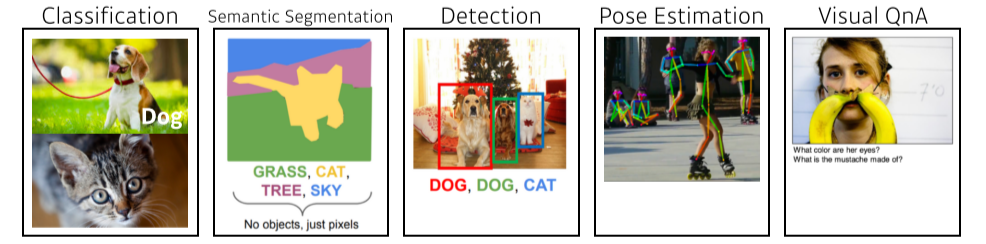
모델을 학습시킬 자료문제에 dependent데이터를 어떻게 가공할지loss (function): 모델의 badness를 측정, 이루고자 하는 것에 대한 근사치(proxy)data, model이 주어져있을때 model을 어떻게 학습할지를 결정algorithm: loss를
2.DL Basic 2강) 뉴럴 네트워크 - MLP (Multi-Layer Perceptron)
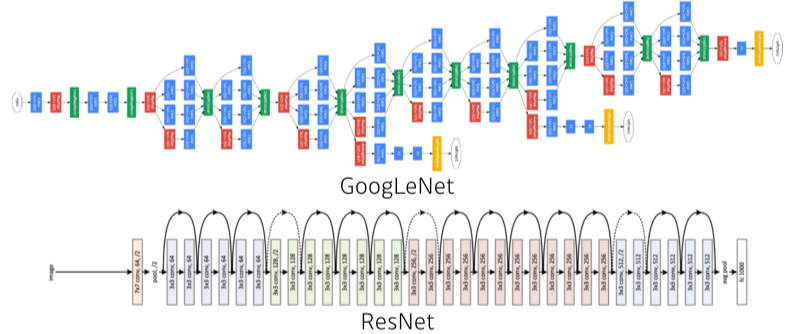
Artificial neural networks (ANNs), usually simply called neural networks (NNs), are computing systems inspired by the biological neural networks that
3.DL Basic 3강) Optimization
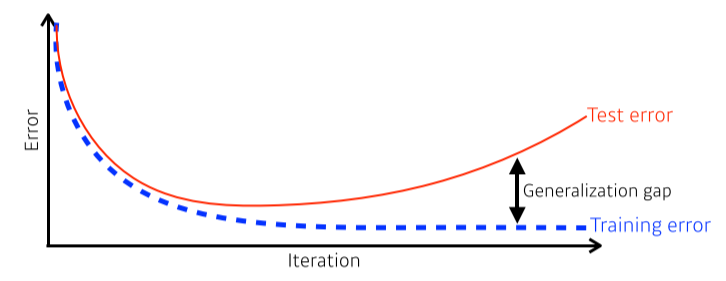
Good generalization: 이 네트워크의 성능이 unseen data(test)에서도 학습 data만큼 나올 것이다Overfitting: 학습 data에서는 잘 동작하지만 test data에서는 잘 동작하지 않음Underfitting: 학습 data에서도 잘
4.DL Basic 4강) CNN

Convolution filter에 따라 이미지에 다양한 변형을 할 수 있다 filter의 dimension은 input의 dimension과 같고 filter의 갯수는 output의 dimension과 같다  Modern CNN

https://www.image-net.org/challenges/LSVRC/이미지 인식 경진대회당시 GPU 성능이 부족했기 때문에 최대한 많은 parameter를 넣고 싶어서 GPU를 2개 사용하고, 그에 따라 모델을 2개로 분리ReLU를 사용해 gradie
6.DL Basic 6강) CV Applications

Semantic Segmentation image의 모든 pixel이 어떤 label에 속하는지 분류하는것 ![] (https://images.velog.io/images/hanlyang0522/post/259fa707-145f-462e-9f5c-0b3226a1e6
7.DL Basic 7강) Sequential Models & RNN
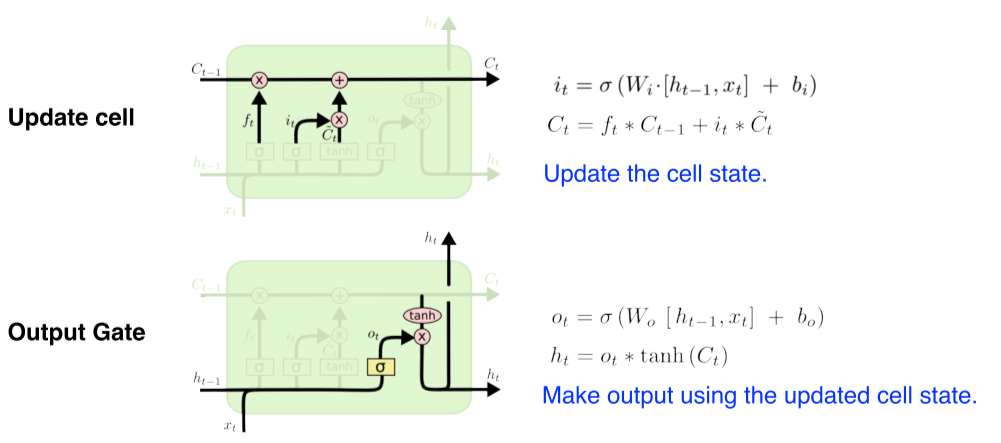
Sequential Model Naive sequence model Sequential data: 음성, 영상 등 데이터 집합 내의 객체들이 어떤 순서를 가진 데이터 Input의 길이가 어떻게 될지 누구도 모르는 것이 문제 고려해야하는 과거의 정보량이 점점 늘어남
8.DL Basic 8강) Transformer
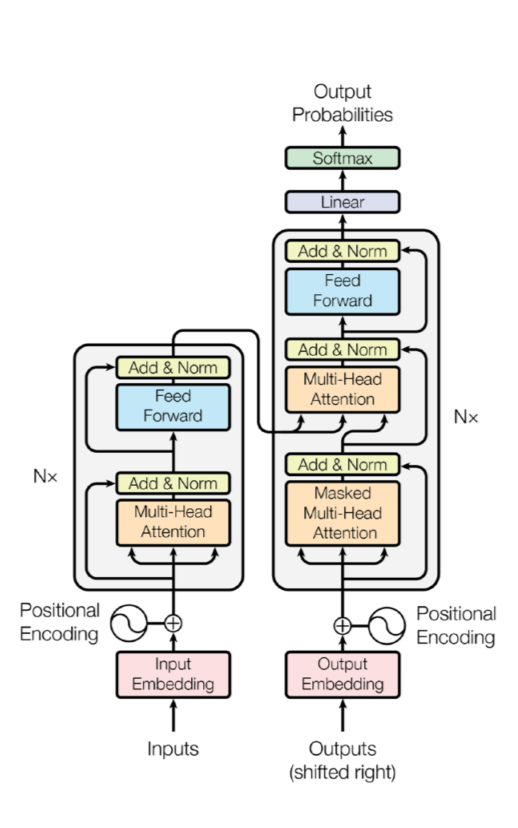
Sequential Model Why is it hard to train? 항상 data가 멀쩡하게 들어오지는 않기 때문에! Transformer
9.DL Basic 9강) Generative Models

Generative Model은 무엇인가? explicit model: 입력이 주어졌을때, 그것에 대한 확률값을 얻을 수 있는 모델 단순이 generate만 할 수 있는 모델은 implicit model이라 부름 그러면 $p(x)$는 어떻게 표현할 수 있을까? B
10.DL Basic 10강) Generative Models 2
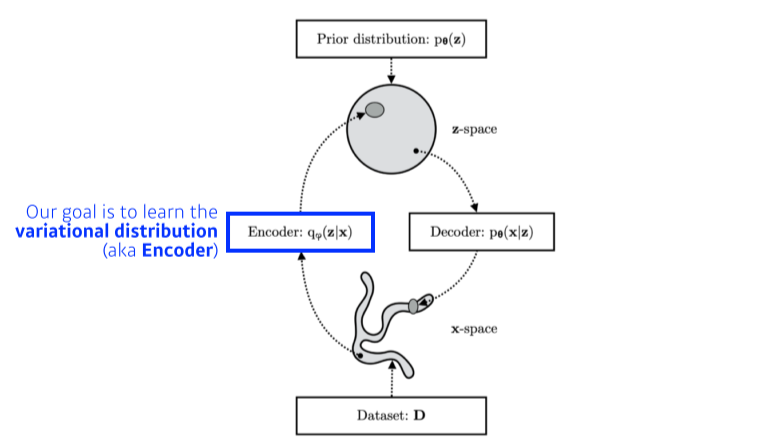
추가강의 1시간 만에 GAN 완전 정복하기 [An Introduction to Variational Autoencoders ](https://arxiv.org/abs/1906.02691)
11.DL Basic) 필수 & 선택과제
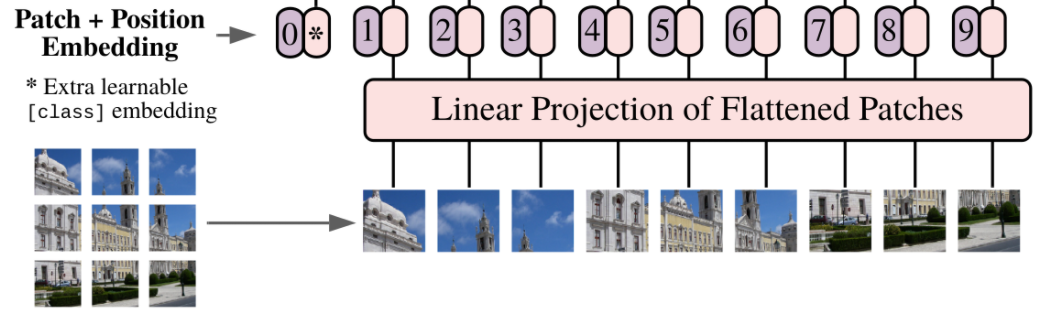
ViT: Vision Transformer https://arxiv.org/abs/2010.11929 리뷰: https://jeonsworld.github.io/vision/vit/ NLP에서 쓰이는 transformer를 CV에 적용
12.DL Basic 추가논의) Weight Initialize를 하는 이유?
torch는 tensor를 만들면 자동으로 난수를 넣어준다 그래서 init을 생략하기도.보통은 seed를 통일, 기타 오류를 제거하기 위해 init을 명시하는 편혹은 특정 initializer를 사용하기 위해보통 keras나 torch에서 nn.Parameter로 re
13.DL Basic 추가논의) What is best cross-validation method?
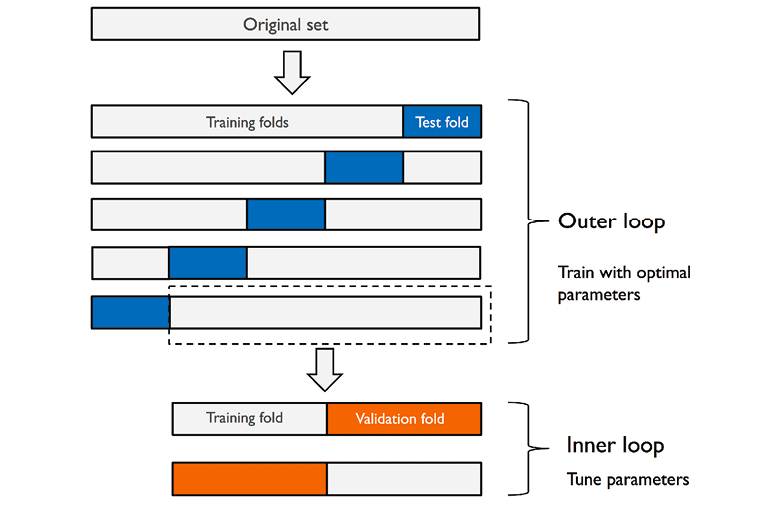
문제제기 여러 cross-validation 방법들이 있는데 가장 효과가 좋은 방법은 무엇일까?에 대한 의문이 들어서 조사하기 시작함 Cross Validation methods Holdout 70:30, 80:20 정도로 2개로 나눔 K-fold Cross Va