Sequential Model
Why is it hard to train?
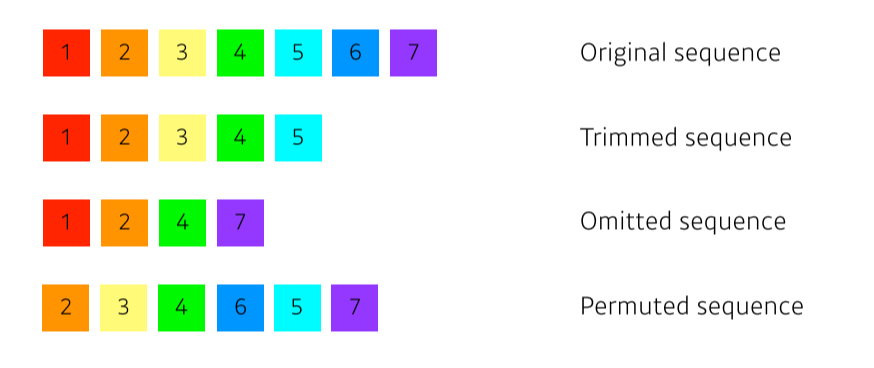
- 항상 data가 멀쩡하게 들어오지는 않기 때문에!
Transformer
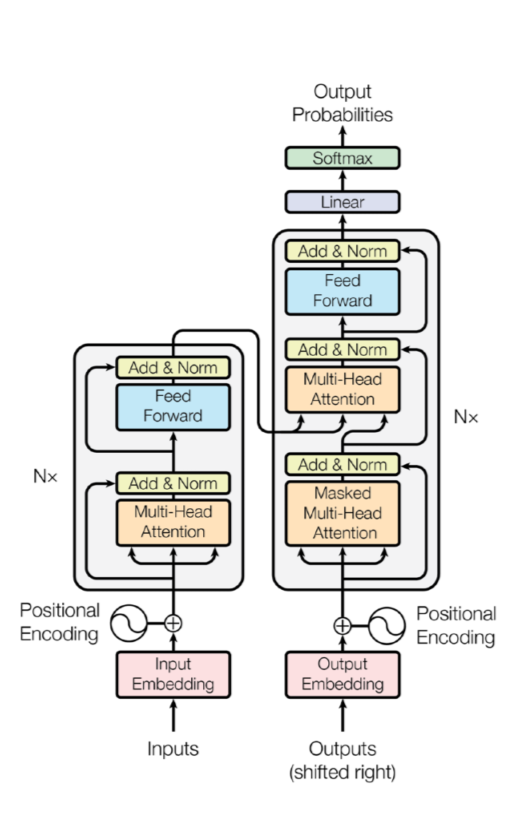
- attention을 처음으로 활용한 모델

- sequential한 data를 처리하고 encoding하는 방법이기 때문에 NMT(Neural Machine Translation)뿐만 아니라 이미지 분류, detection 등에도 사용됨
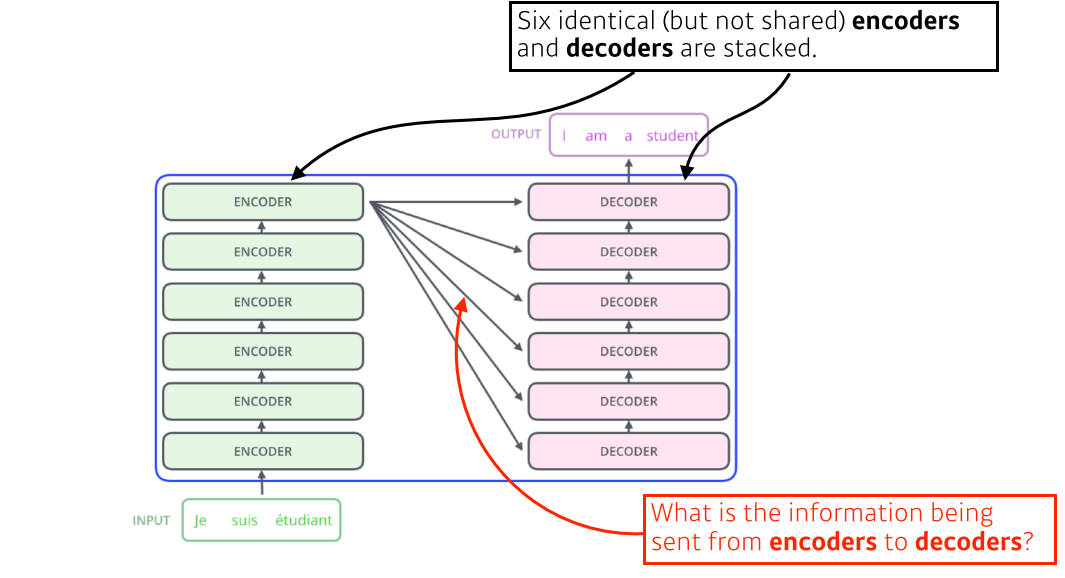
- Seq2seq(Sequence-to-Sequence): 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 다양한 분야에서 사용되는 모델
- Transformer구조에서는 재귀적으로 돌지 않음
Encoder
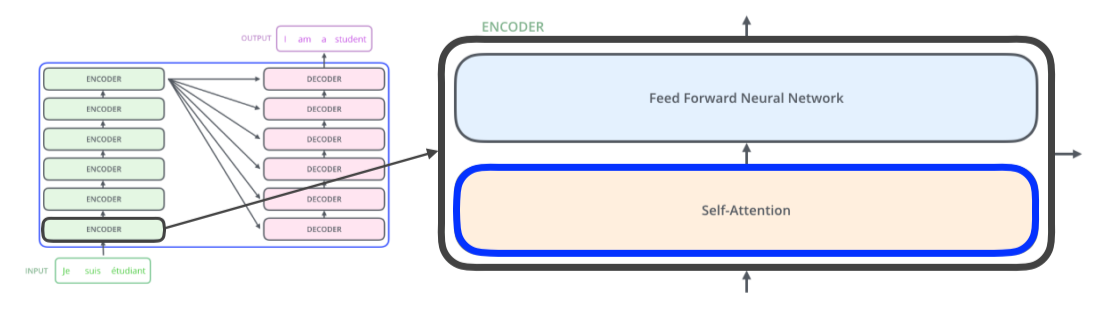
- 각 encoder는 Feed Forward NN와 Self-Attention로 이루어져있다
- Feed Forward NN: MLP와 동일
- Self-Attention이 가장 중요한 부분
Self-Attention
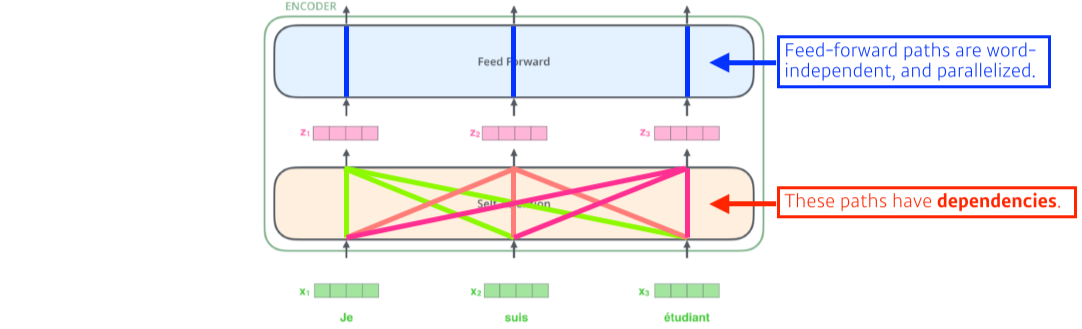
- x1벡터를 z1벡터로 변환할 때 나머지 x2,3벡터도 같이 고려하는게 특징
예시)

- 단어를 학습할 때 it이 animal과 높은 관계가 있다는 것을 알아서 학습한 것을 확인할 수 있다
Self-Attention의 과정
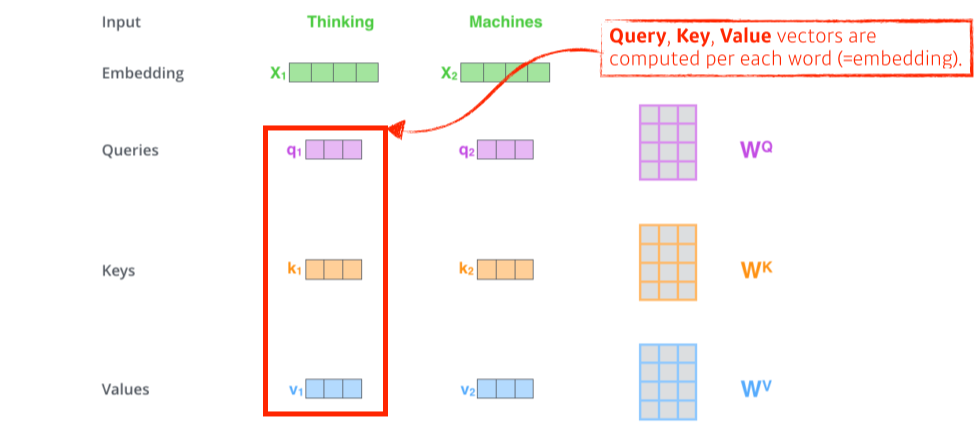
- self-attention은 학습할 때 1가지 단어(input)에 대해 embedding 벡터로 3가지 벡터(query, key, value)를 만들어냄(== 3개의 neural network)
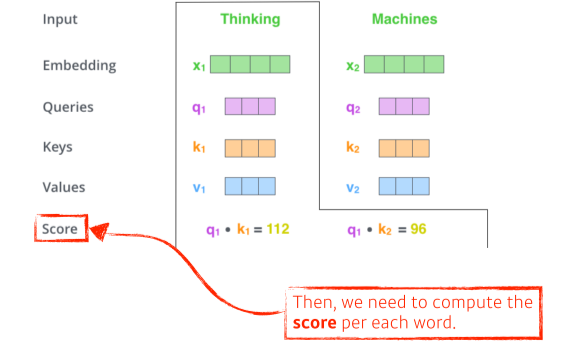
- 그리고 encoding하고자 하는 단어의 query 벡터와 (자기자신을 포함한)나머지 모든 단어의 key 벡터를 내적해서 score를 구함
--> 두 단어가 얼마나 align되어있는지(유사도)를 구함
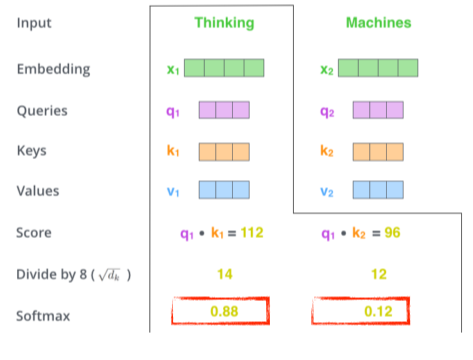
- score를 normalize해줌(몇으로 나눌지는 key vector에 dependent)
key vector가 몇 차원을 만들지는 hyperparameter
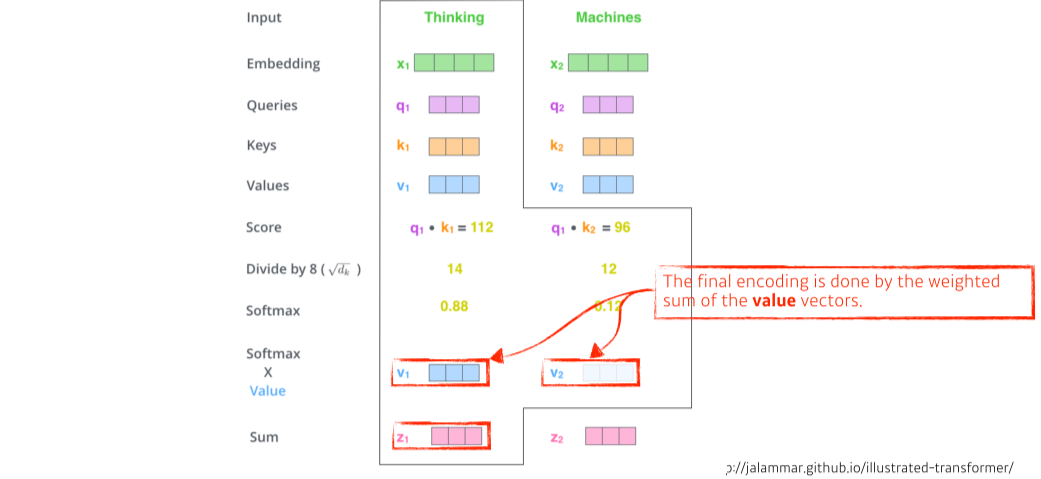
- softmax로 score를 normalize한 scalar 값과 value를 곱한 value 벡터의 weighted sum이 output
query와 key는 차원이 같아야하나(for 내적) value는 scalar를 곱하기 때문에 차원이 상관없음
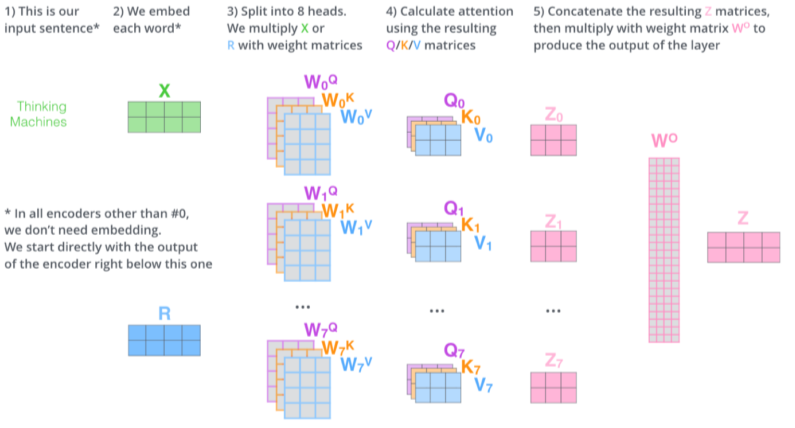
- embedding된 벡터(input)의 dimension과 encoding돼서 self-attention으로 나오는 벡터(output)의 dimension이 항상 같아야됨
그래서 그림에서 5)에서 input, output의 dim을 맞추기 위해서 matrix WO를 곱해줌
이를 MHA(Multi-headed attention)이라고 부른다
Positional encoding
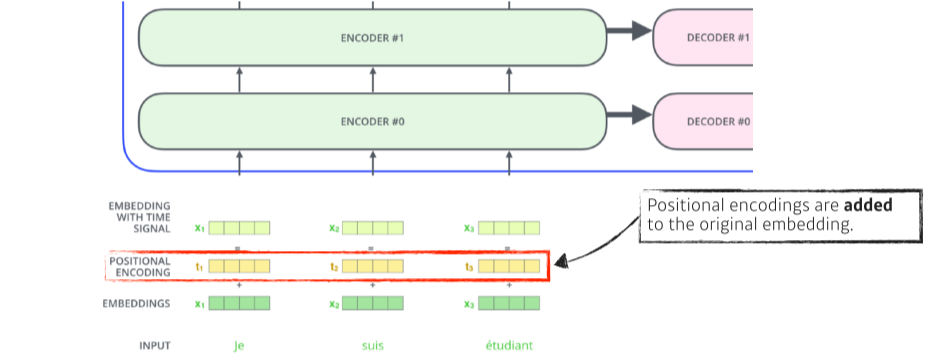
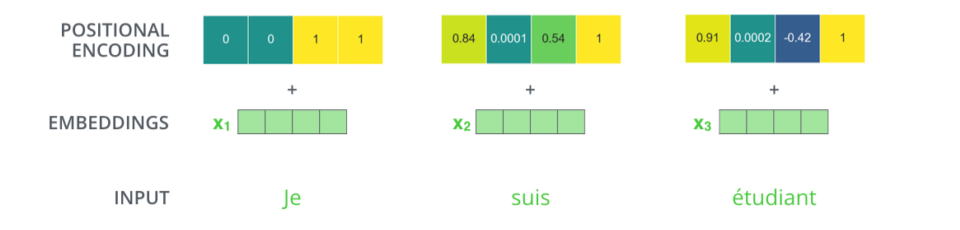
- encoder는 order independent하기 때문에 positional encoding을 input에 더해줌
(key/query에서 자신을 포함한 다른 모든 input을 곱해버리기 때문에 abc, bac, cab, cba 모두 똑같은 값을 가짐) - 어디에 얼마나 더할지는 pre-defined
- positional encoding 방법에 대한 설명
https://skyjwoo.tistory.com/entry/positional-encoding%EC%9D%B4%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80
Layer-Norm
- Layer Normalization에서 제시한 방법
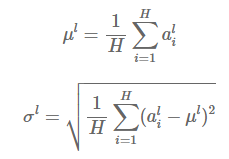
- 같은 layer에 있는 hidden unit은 동일한 와 를 공유
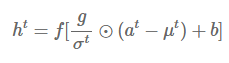
- 현재 input , 이전의 hidden state , , parameter 로 위와 같이 normalize해준다
- gradient exploding/vanishing 문제를 완화하고 안정적인 값을 가져 더 빨리 학습시킬 수 있다
Feed Forward Neural Network
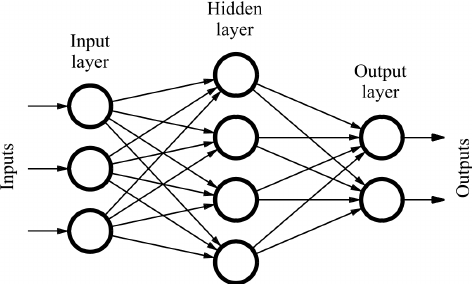
- 각 input마다 fully-connected network를 지남
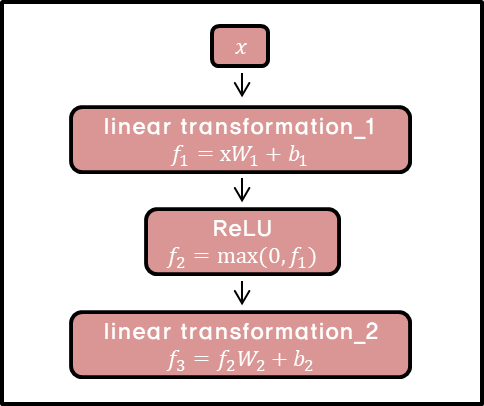
- linear transform -> ReLU -> linear tranform을 거쳐 score가 나온다
Decoder
구조
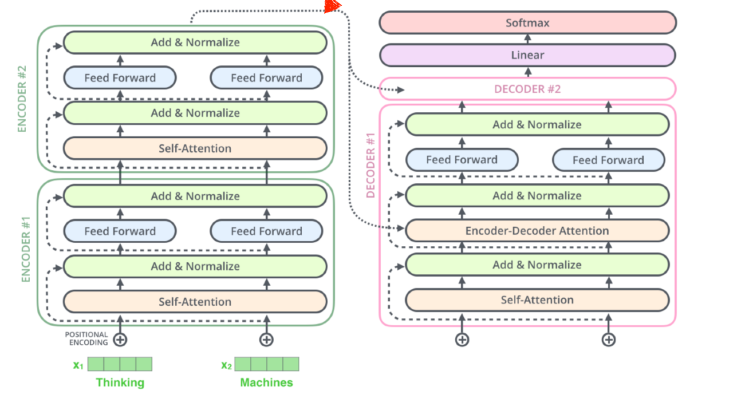
작동원리
![]()
![]()
- 최상위 encoder의 key, value가 decoder를 거쳐 output이 나온다
- initial output이 나오면 그걸 posidional encode해준 후 decoder에 넣어서 다음 output을 출력한다
이걸 decoder가 동작을 complete했다는 special symbol을 출력할 때까지 반복
Teacher Forcing
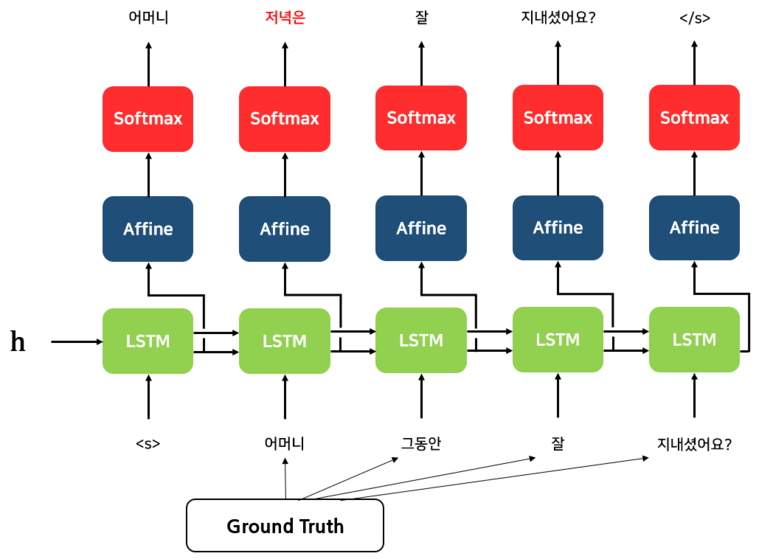
- Teacher Forcing: 훈련시에는 golden sentence, 즉 정답 문장이 있기 때문에 각 디코더에 ground truth를 넣어준다
입력을 ground truch로 넣어주면 더 정확한 예측이 가능하고, 학습속도도 빨라진다 - Exposure Bias Problem: 추론(inference) 단계에서는 ground truth를 사용할 수 없기 때문에 전 단계의 자신의 출력값을 기반으로 예측을 이어나가야 한다
이런 학습-추론단계에서의 차이(discrepancy)가 존재해 모델의 성능과 안정성을 떨어뜨릴 수 있다
하지만 노출편향이 생각보다 큰 영향을 미치지 않는다는 결과도 있다
Quantifying Exposure Bias for Neural Language Generation
(Masked) Self-attention
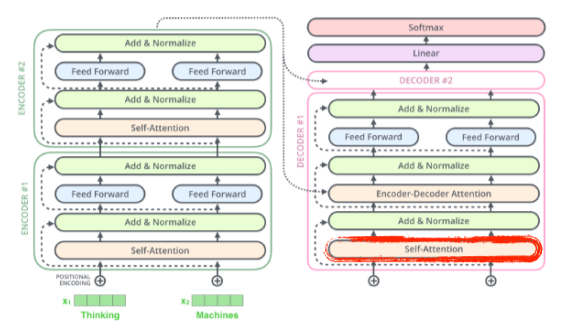
- Decoder에서 token을 기반으로 다음 단어를 추론할 때 뒤쪽 단어를 참고하는 것은 cheating
- 따라서 self-attention은 이전 단어들만 dependent하고 뒤쪽 단어들엔 independent하게 만들어줌
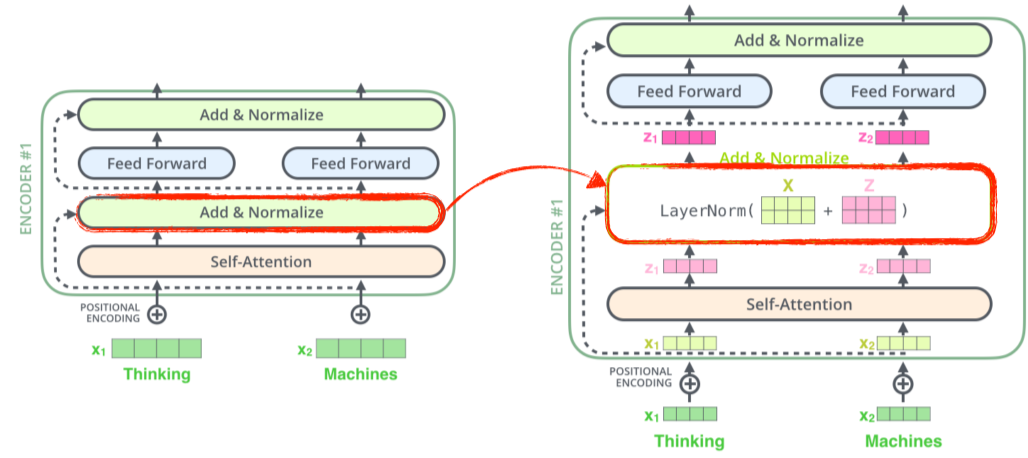
Add & Normalize
- Residual connection이랑 값을 normalize해주기 위해 사용
Encoder-Decoder Attention
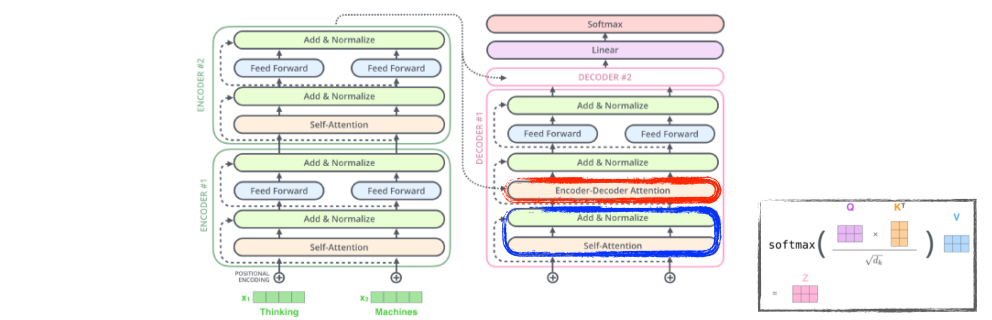
- Encoder에서 나온 K, V와, decoder에서 target input을 이용해 첫 MHA에서 나온 Q를 MHA에 넣음
--> Q, K를 dot product해서 유사성을 찾기 위하여!
Train
Test
ViT(Vision Transformer)
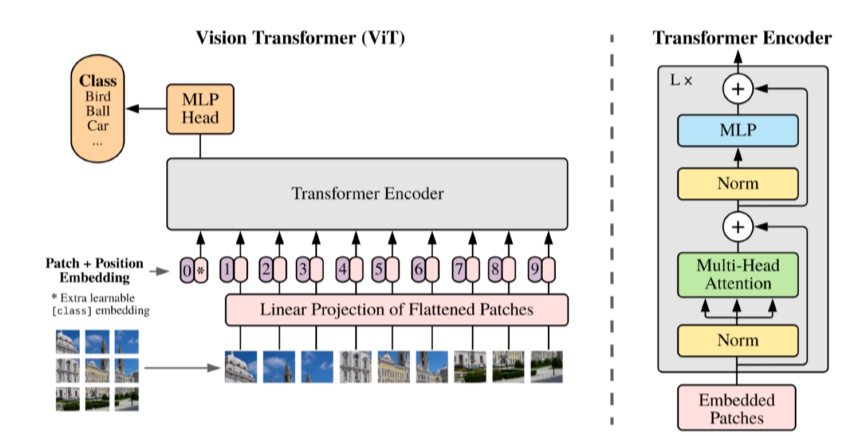
- 이미지 분류할 때 encoder만 활용
- NMT와의 차이: 문장 대신 이미지를 input으로 쓰기 때문에 이미지의 sub-patch를 만들어 linear layer를 통과시킨 결과를 하나의 입력인 것처럼 사용(positional encoding도 사용)
DALL-E

- 문장을 주면 그에 맞는 image를 만들어냄
- decoder만 활용, image는 16x16 grid로 만들고, 문장도 단어들의 sequence로 집어넣는다고 함
- GPT-3를 이용

즐겁게 개발하기