1. 구조
1) VGGNet backbone
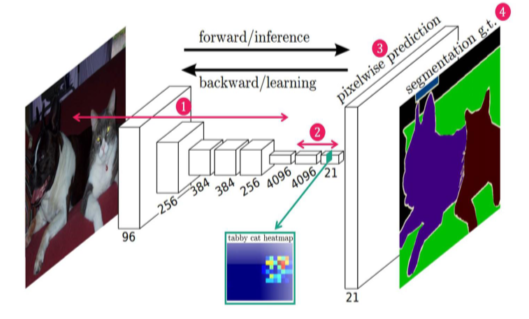
VGGNet backbone을 사용
Backbone: VGGNet, AlexNet, ResNet, EfficientNet 같은 feature extracting network
2) FC to Conv
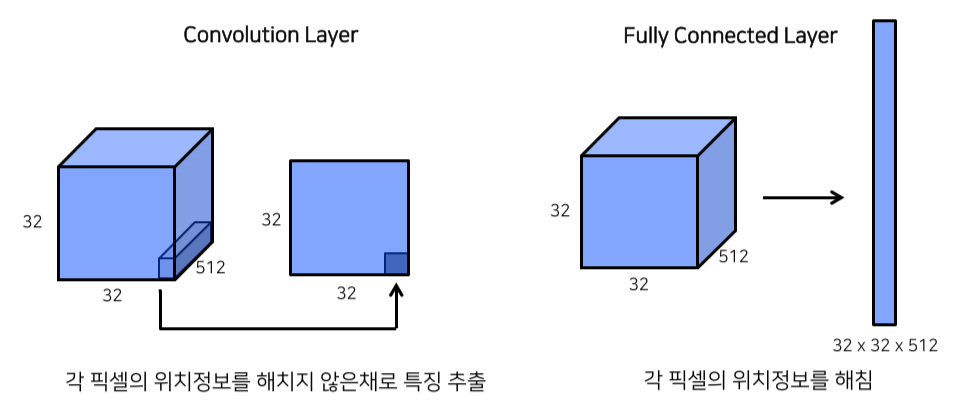
VGG network의 FC Layer(nn.Linear)를 convolution 으로 대체해서 positional information을 살림
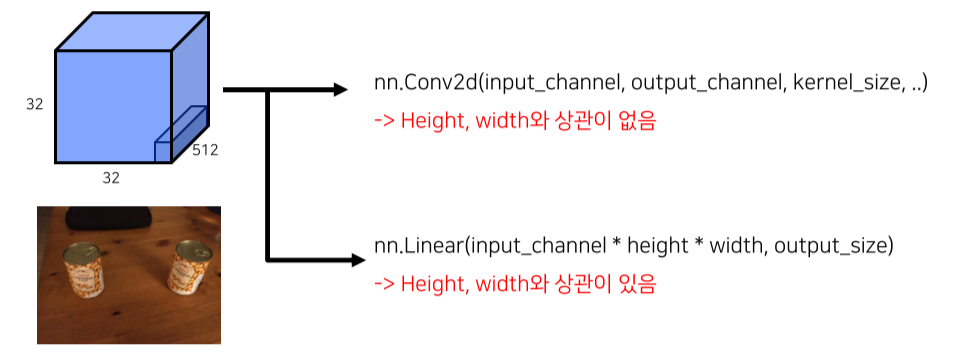
또한 FC는 flatten하기 때문에 image, layer의 크기에 영향을 받지만 convolution은 kernel size에 영향을 받기 때문에 1x1 conv를 사용할 경우 input size와 무관
3) Transposed Convolution

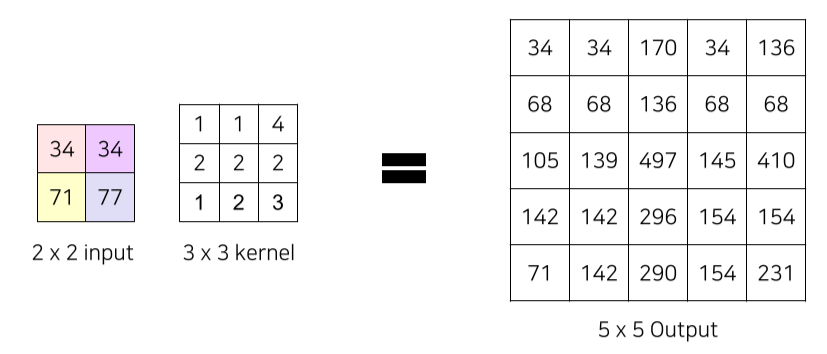
줄어든 image size를 transposed convolution으로 upsampling
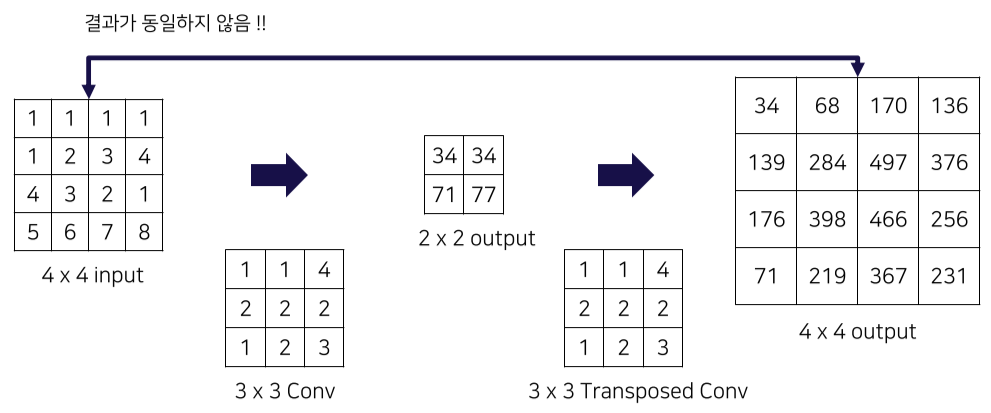
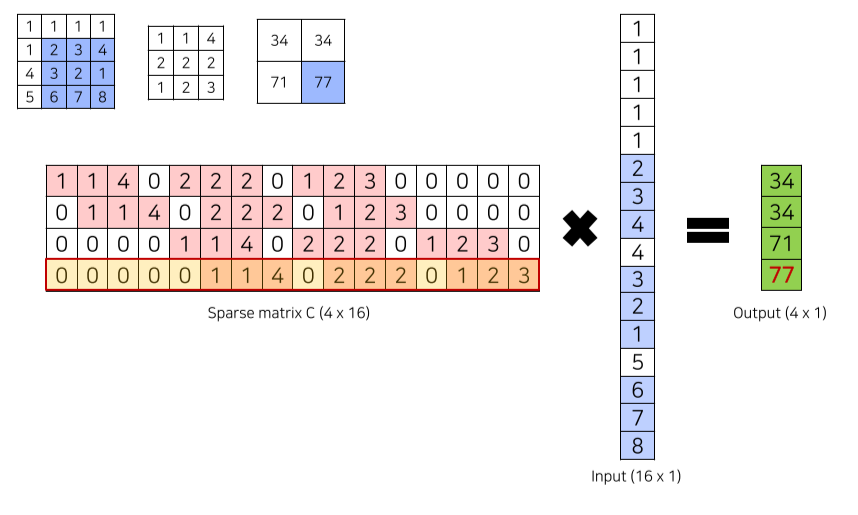
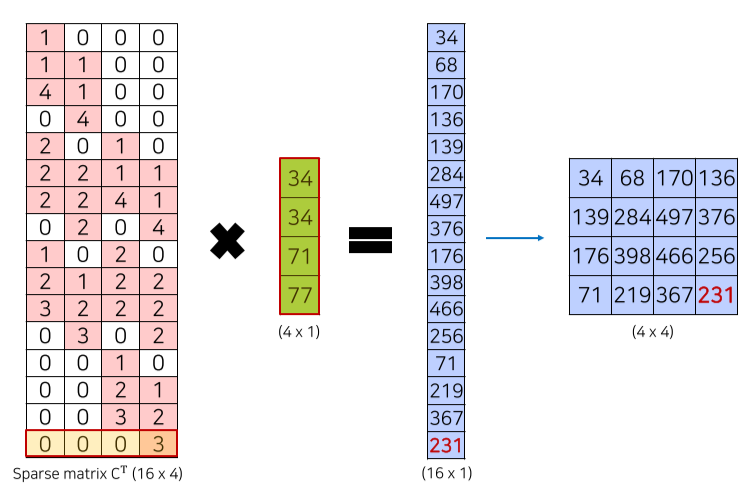
Deconvolution이라고도 불리나 수학적으로 정확한 표현은 아님
2. Tricks

기존에는 input image를 5번의 max pooling으로 1/32로 줄인 후 unpooling을 했기 때문에 detail한 정보(positional information)가 많이 죽음
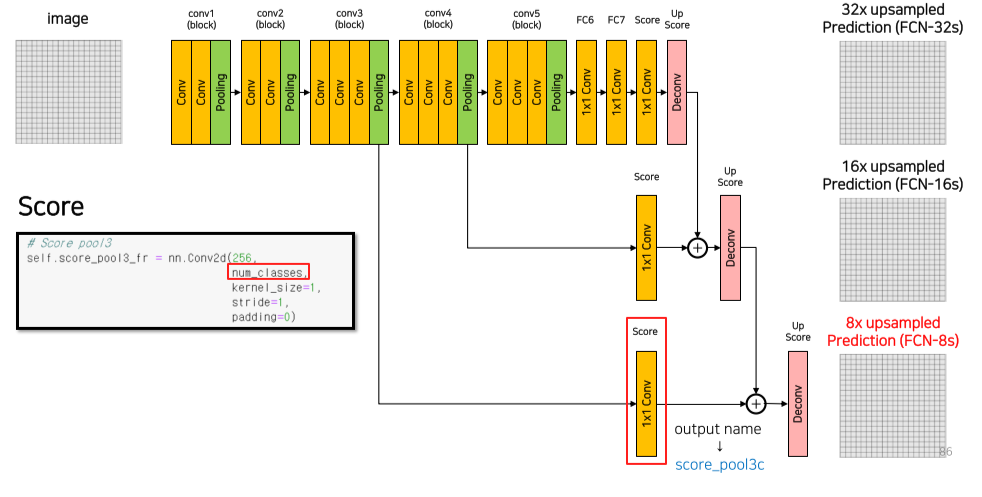
이를 개선하기 위해 상위 layer의 feature를 channel만 num_classes와 맞춰서 sum
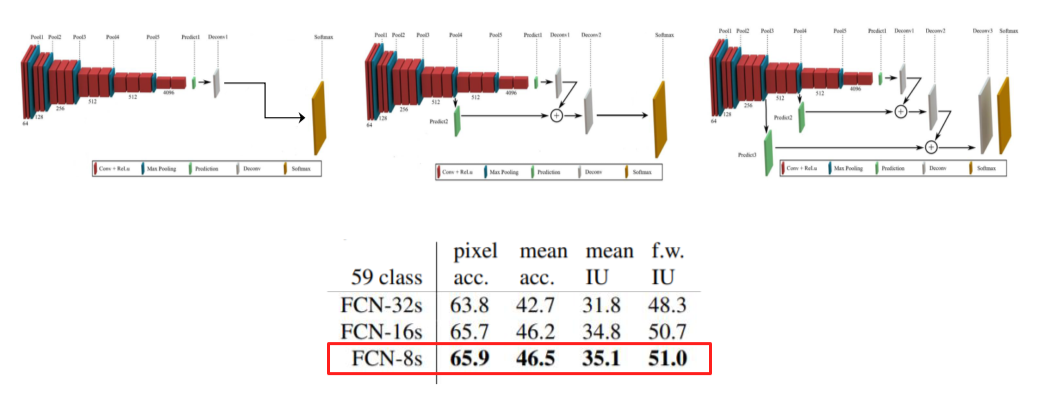
성능이 올라간걸 확인할 수 있음
3. Metric
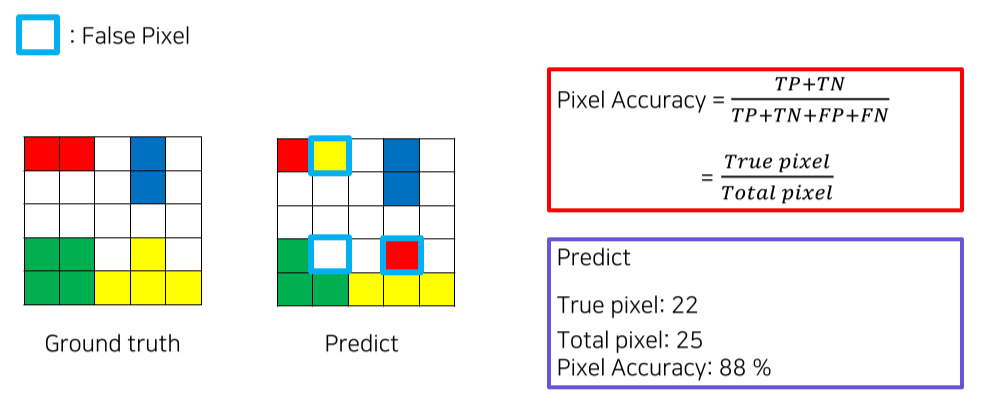
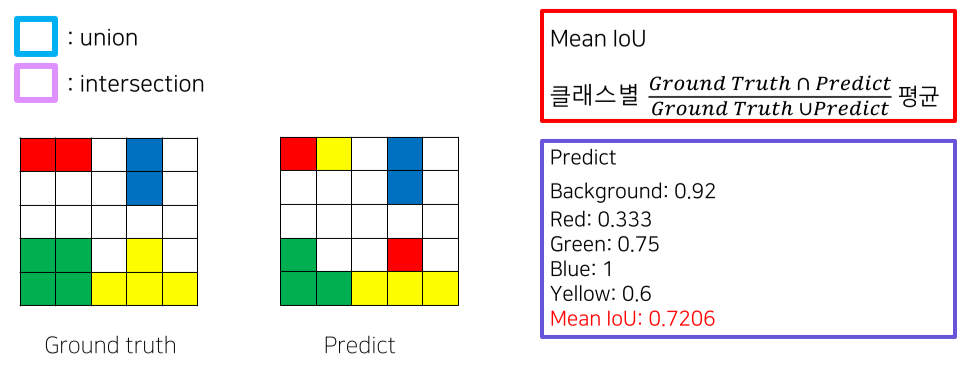
클래스별 True Pixel / Total Pixel로 IOU를 계산 후 mIOU를 사용
4. 구현
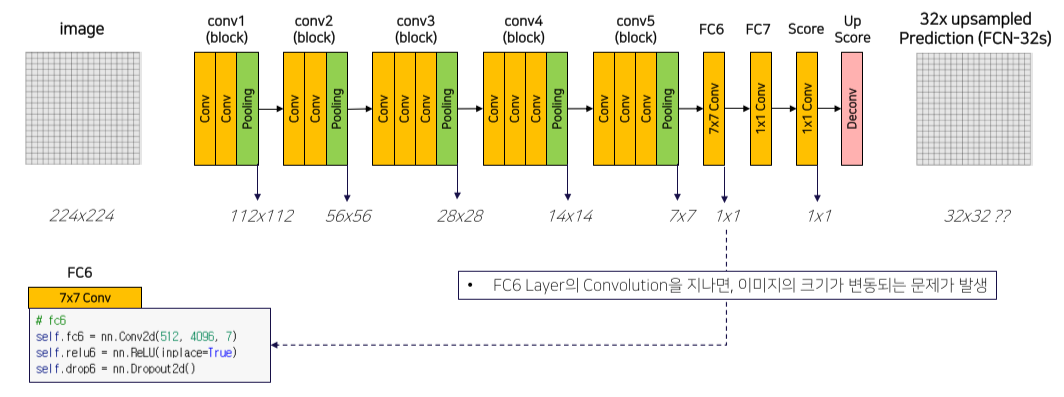
실제 구현에서는 VGG backbone을 그대로 가져왔기 때문에 FC6에서 1x1 conv가 아니라 7x7 conv를 사용해서 output이 1x1가 돼버리는 문제가 발생
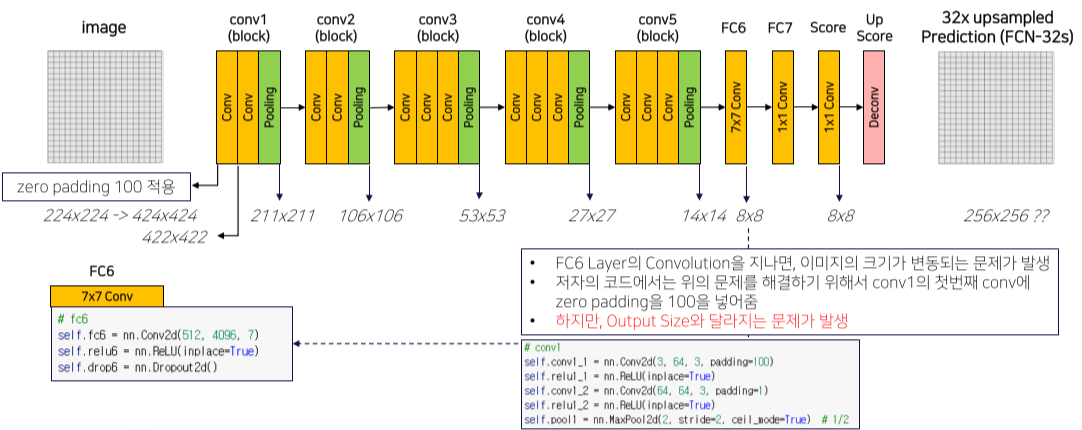
이를 해결하기 위해 conv1에서 zero padding = 100을 넣어줬지만 output size가 달라지는 문제가 발생
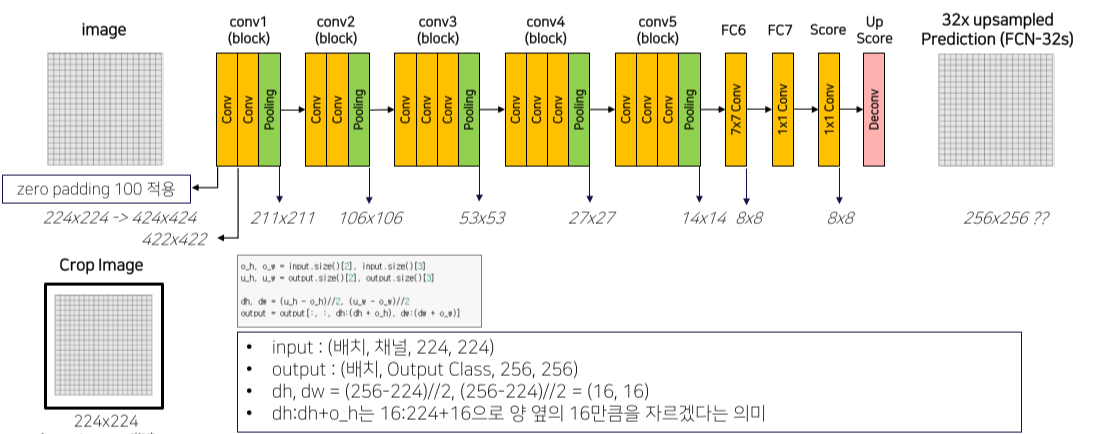
그래서 upsampling 후 원본 size만큼 crop해서 해결함
원래 가장자리는 zero padding을 했기 때문에 crop해도 정보 손실이 적음
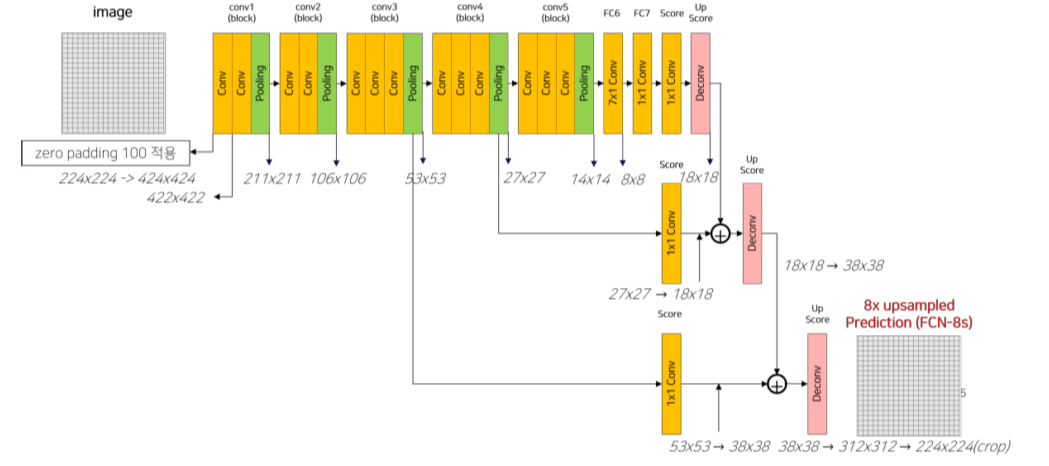
FCN8s 같이 skip connection을 사용할 때도 size에 맞게 crop해서 해결
