
1. FCN의 한계

Object의 크기가 receptive field가 고정돼있어서 이보다 클 경우 한 object를 다른 여러가지 object로 인식하거나, 이보다 작을 경우 무시되는 경우가 발생
Max pooling, deep layer의 문제로 인해 무시되기도 함
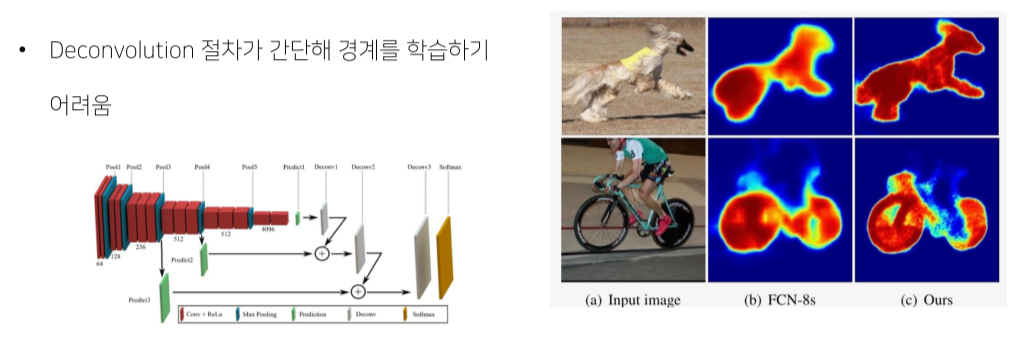
Deconvolution(upsampling)의 절차가 간단해서 detail한 정보를 살리지 못함
2. Decoder를 개선한 모델
1) DeconvNet
Architecture

Decoder와 encoder를 대칭으로 만듬
Convolution Network(backbone): VGG16을 사용, 각 conv layer는 conv-BN-ReLU로 구성
Deconvolution Network: unpooling, deconvolution, ReLU로 구성
Unpooling vs Deconvolution
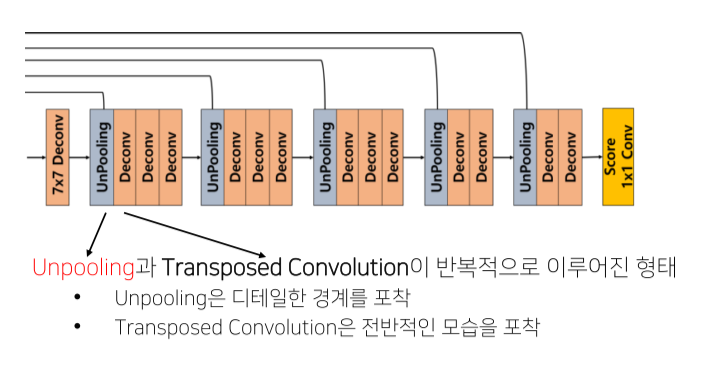
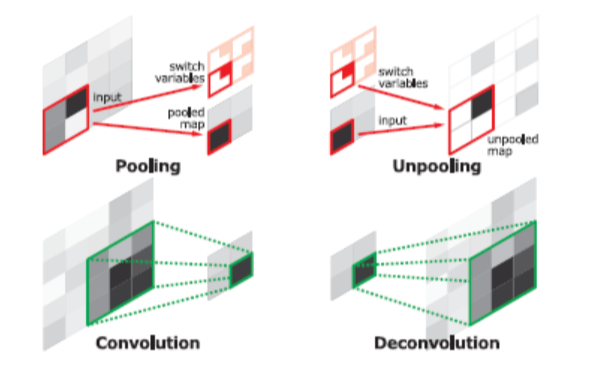
- Unpooling은 pooling시 지워진 경계에 대한 정보를 기록했다가 복원
- 학습이 필요없기 때문에 속도가 빠름
- 객체의 외곽(detail), example-specific
- Deconvolution은 다양한 resolution 의 모양을 잡아냄
- Low(shallow) layer: local feature, 직선, 곡선, 색상 등의 낮은 수준의 특징
- High(deep) layer: global feature, 복잡하고 포괄적인 객체 정보가 활성화
- Class-specific
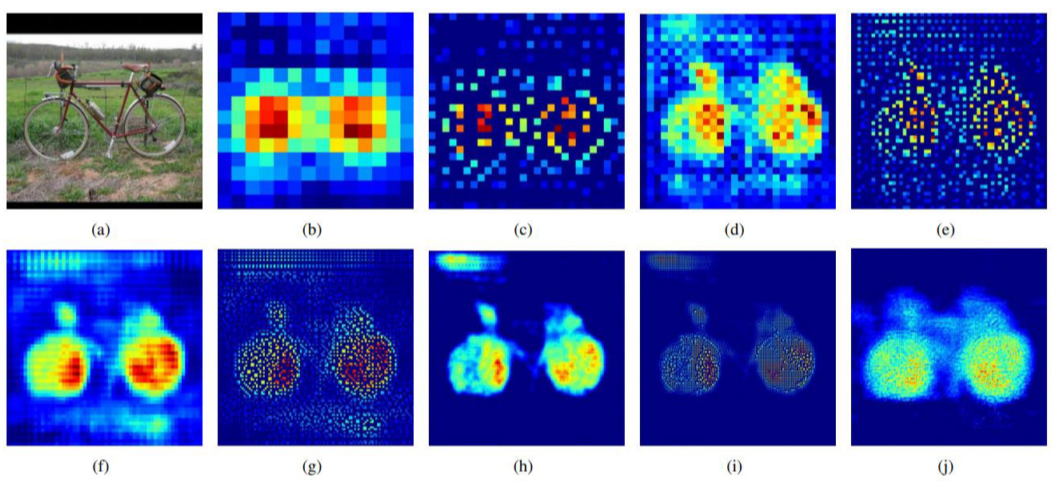
- b, d, f, h, j: transposed conv, low layer에서는 색상 같은 정보를 위주로 잡아냄, class-specific
- c, e, g, i: unpooling, 경계 위주의 detail한 정보, example-specific
2) SegNet
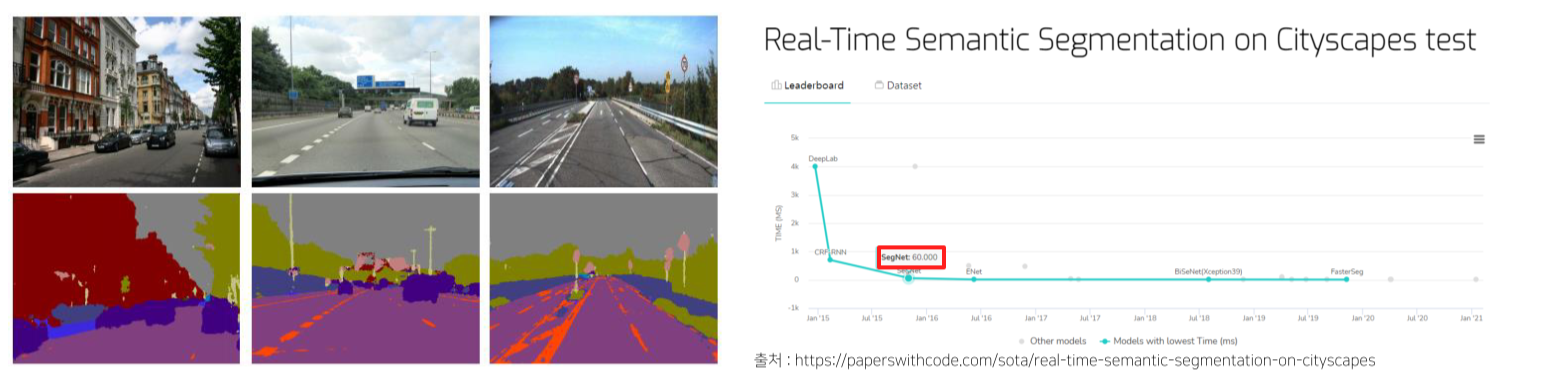
Real time(특히 자율주행)에서 segmentation을 하기 위해 차량, 도로, 차선, 보도, 하늘 등의 class를 빠르고 정확하게 구분하기 위해 등장
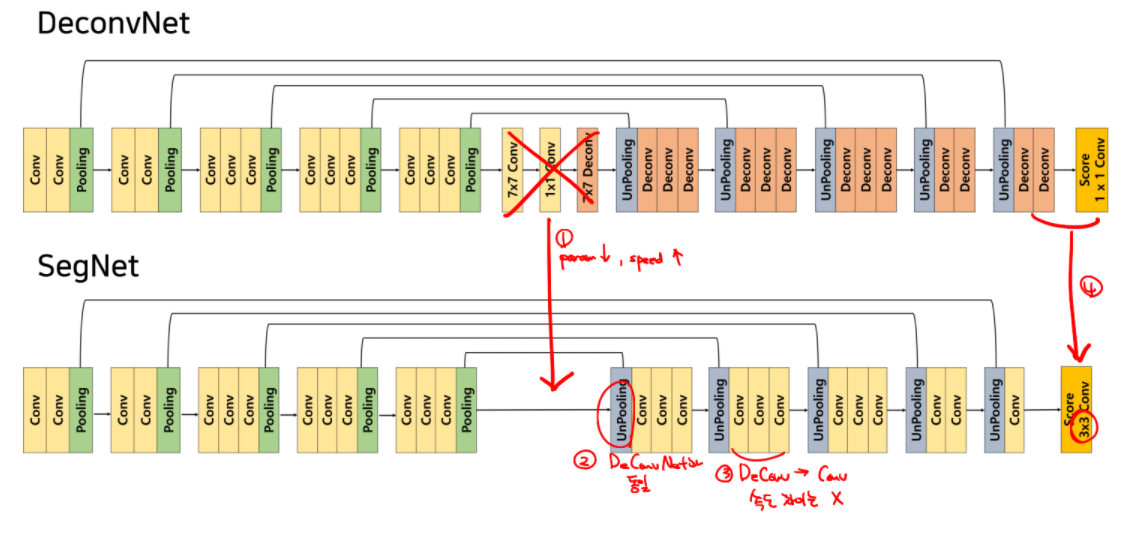
DeconvNet에서 중간의 1x1 conv를 제거하고, 마지막 deconv layer를 제거하고 3x3 conv로 역할을 대신해 weight parameter를 감소시켜 train/test 시간이 감소
Decoder에서 deconvolution을 convolution으로 대체한 이유는 나와있지 않으나 속도에서 큰 차이는 없을것
3. Skip connection을 적용한 모델
1) FC DenseNet
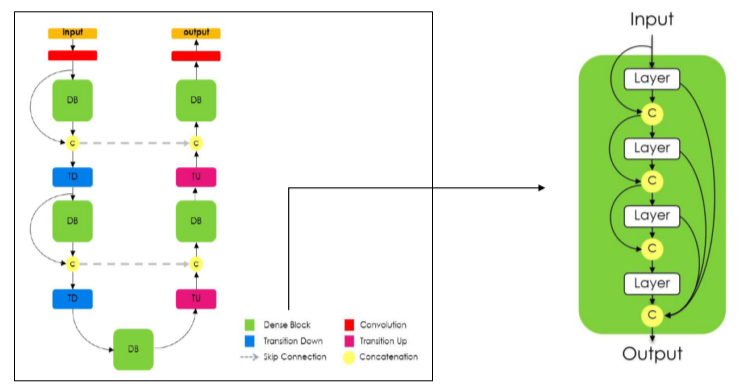
Block 내부에서 이전 모든 layer의 정보를 넘겨서 concat
2) UNet
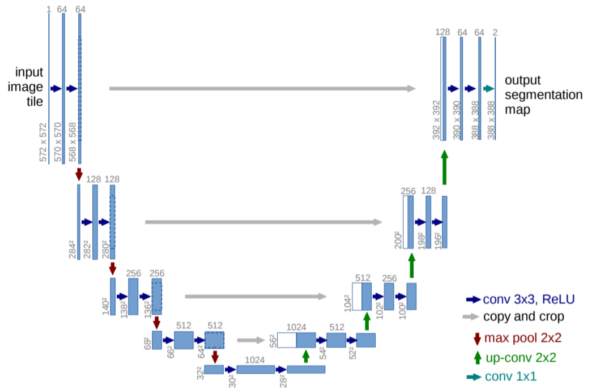
4개의 skip connection
자세한 내용은 이후 UNet에서 다룸
4. Receptive field를 확장시킨 모델
1) Deeplab v1

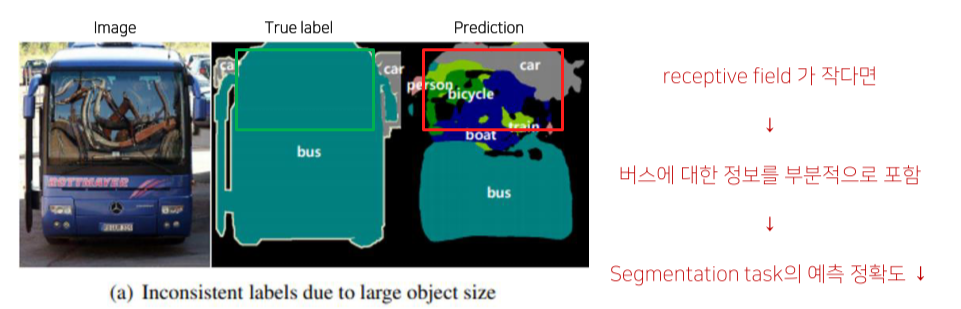
Receptive field가 작으면 semantic information을 고려하지 못하는 문제가 있음
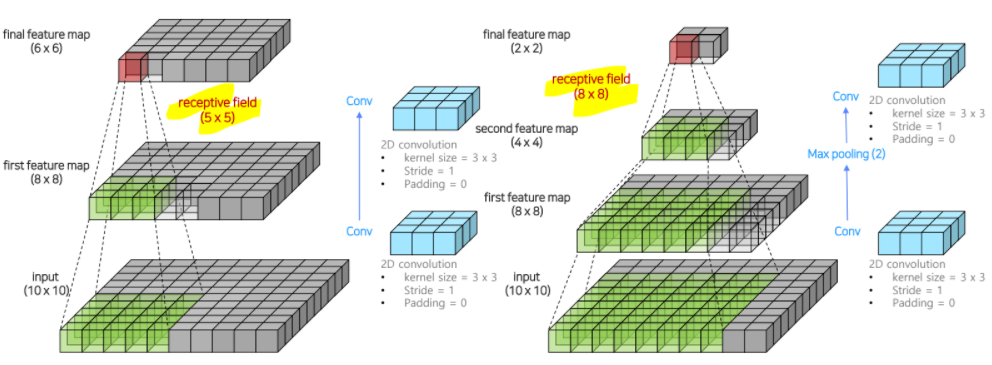
Conv -> max pooling -> conv를 반복하면 receptive field를 효율적으로 늘릴 수 있음
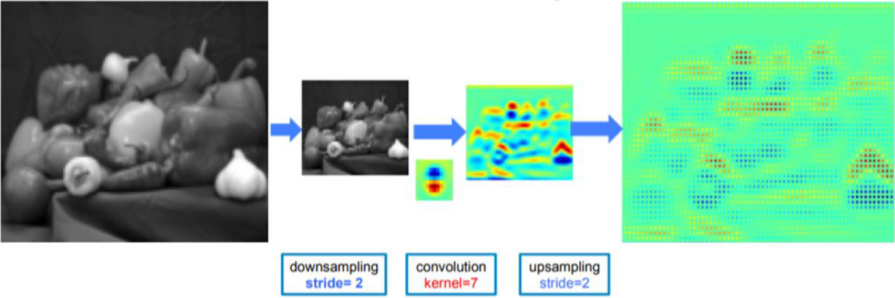
하지만 resolution 측면에서는 반복할수록 feature의 해상도가 떨어진다는 단점이 있음
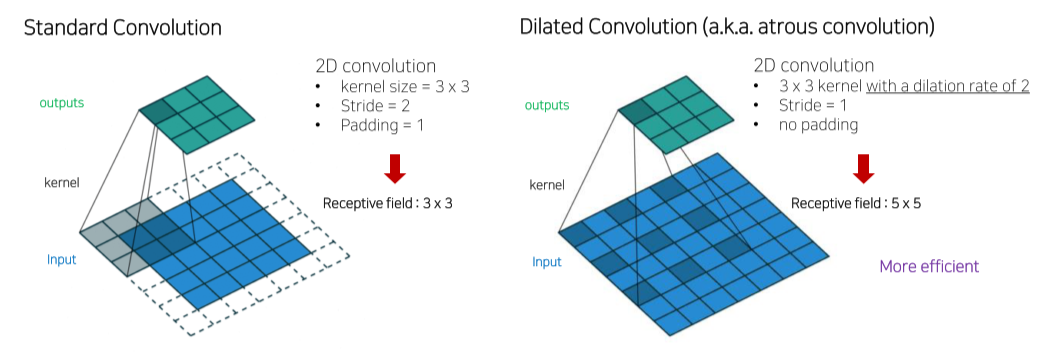
이를 개선하기 위해 기존 convolution에 dilation rate를 줘서 receptive field를 늘림
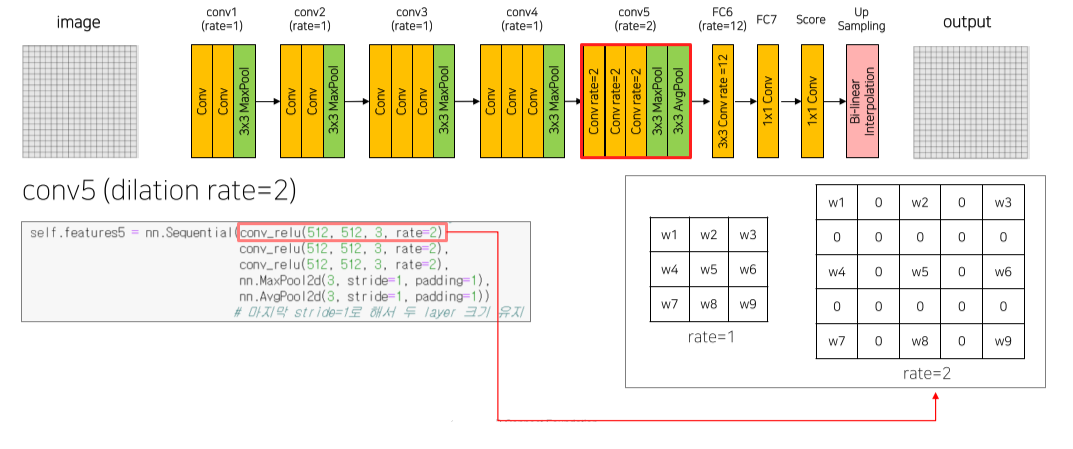
DeeplabV1에서는 conv5 block에서 rate = 2, FC6에서 rate = 12를 줌
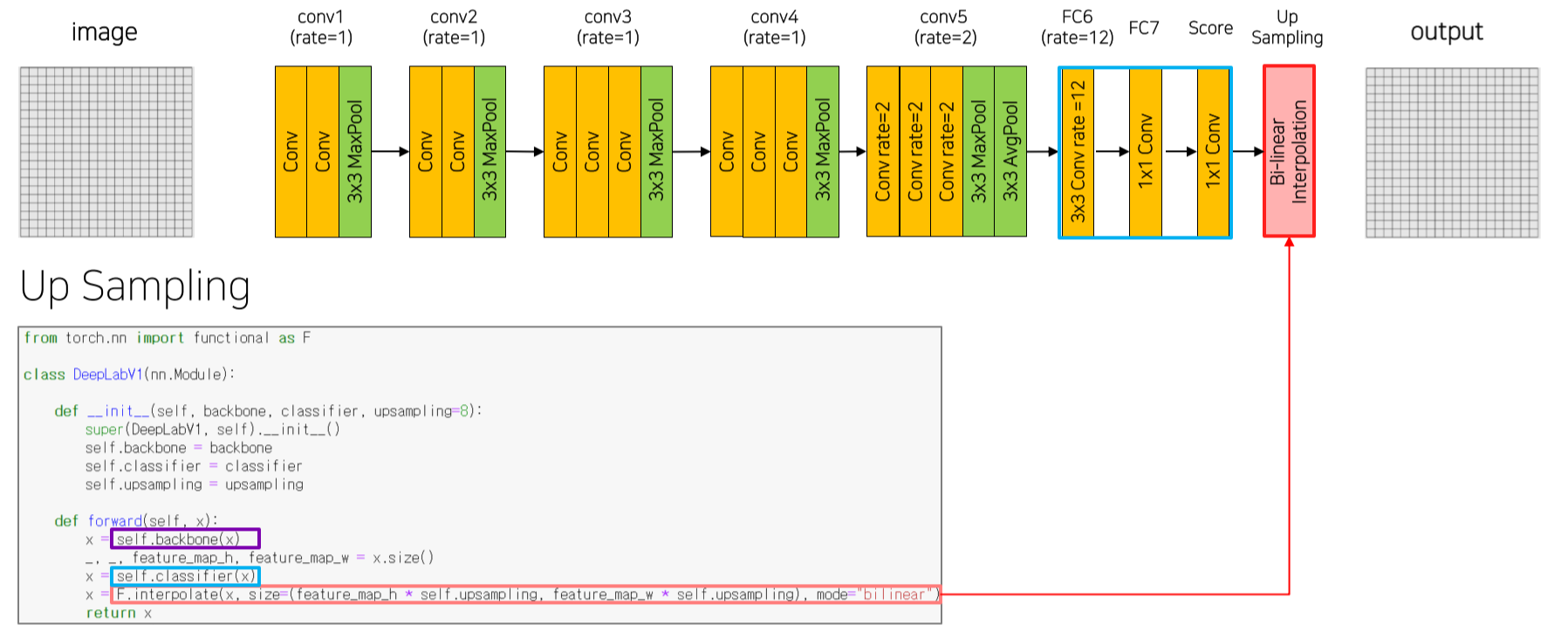
마지막 upsampling은 bilinear interpolation을 사용
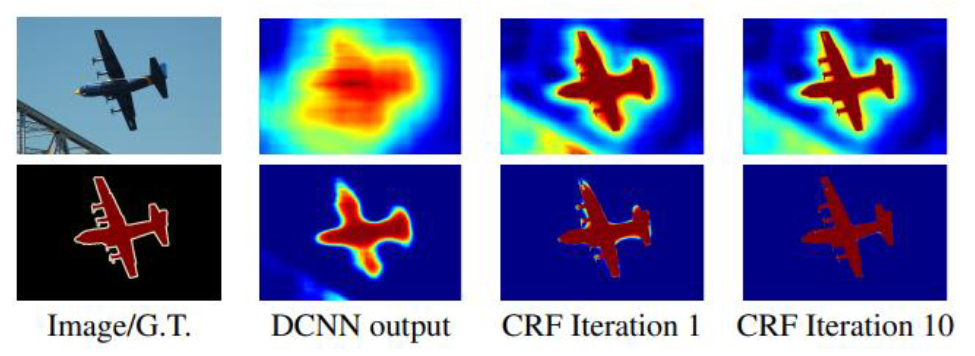
Bilinear interpolation으로 생성한 결과는 픽셀 단위의 정교한 segmentation이 불가능하기 때문에 개선하기 위한 후처리 방법으로 Dense CRF를 사용
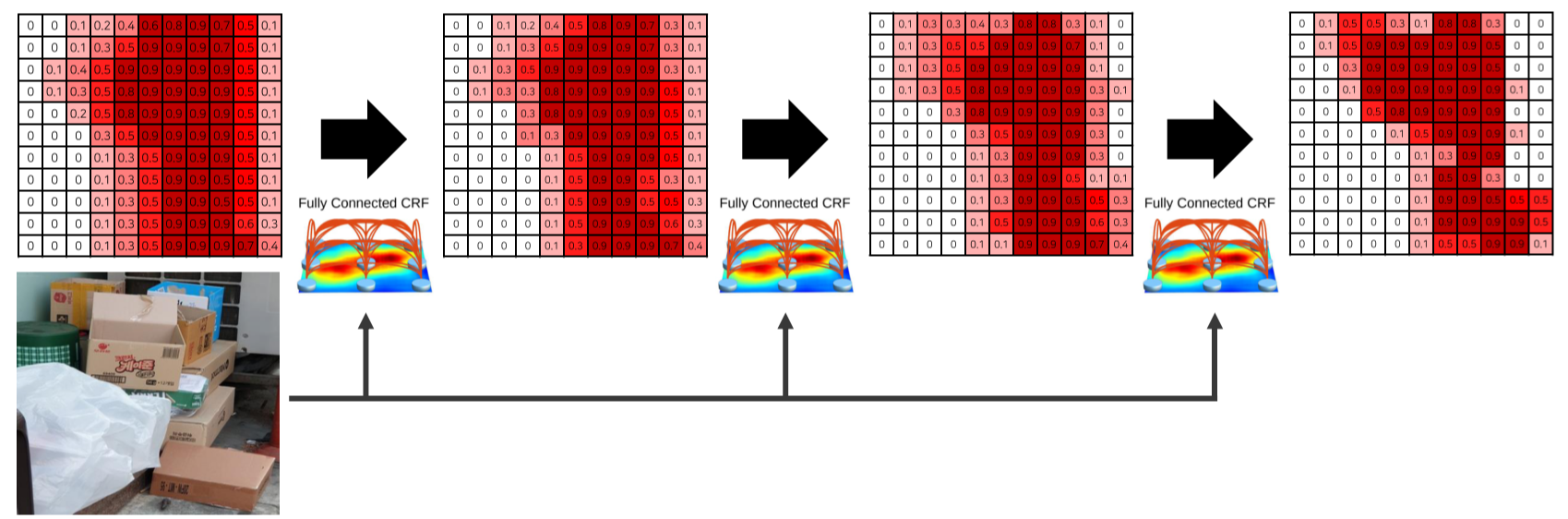

- Dense CRF
- Input: image & obj가 존재할 pixel의 확률
- 색상이 유사한 pixel이 가까이 위차하면 같은 범주
- 색상이 유사해도 pixel의 거리가 멀다면 다른 범주
- 마지막엔 각 픽셀 별 가장 높은 확률을 갖는 카테고리를 선택해 최종 결과를 도출
2) DilatedNet
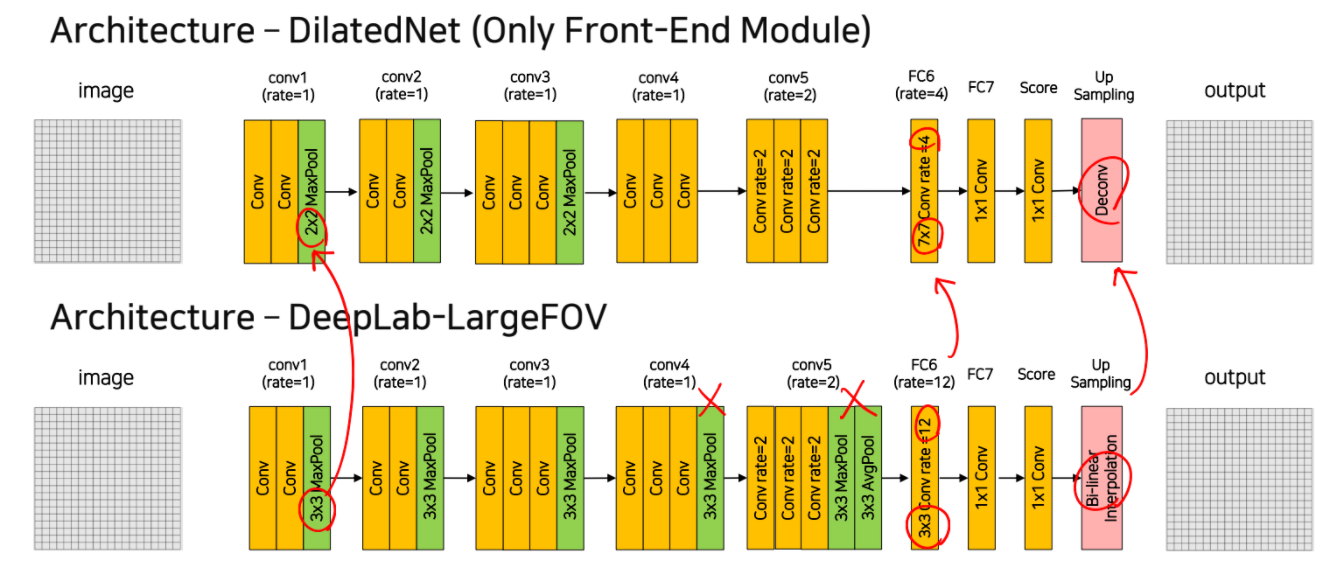
Deeplab에서 pooling layer를 제거하고 FC6의 kernel size를 늘림
Upsampling에서 bilinear interpolation 대신 deconv를 사용
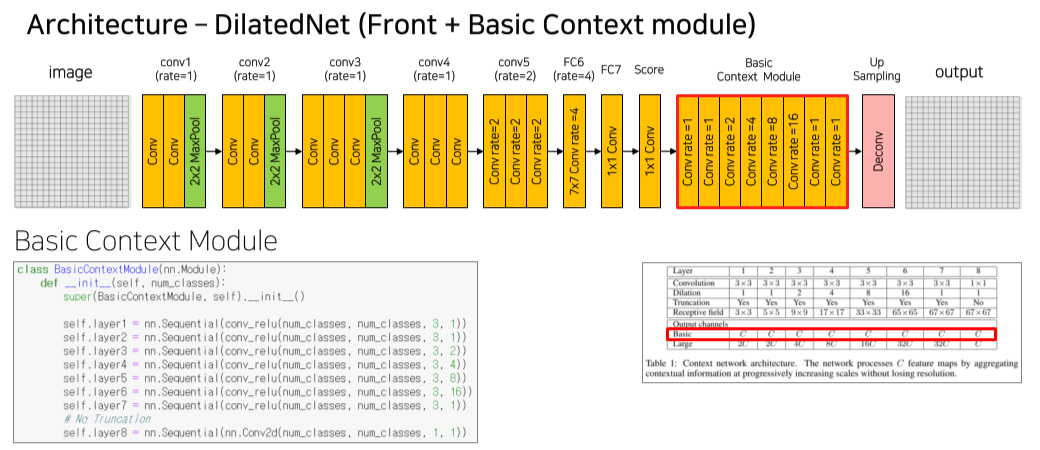
Basic context module을 추가해 dilate rate를 다양하게 줘서 다양한 크기의 object를 잘 감지하게 함
Padding은 동일한 size로 줘서 크기의 변동을 방지
3) Deeplab v2
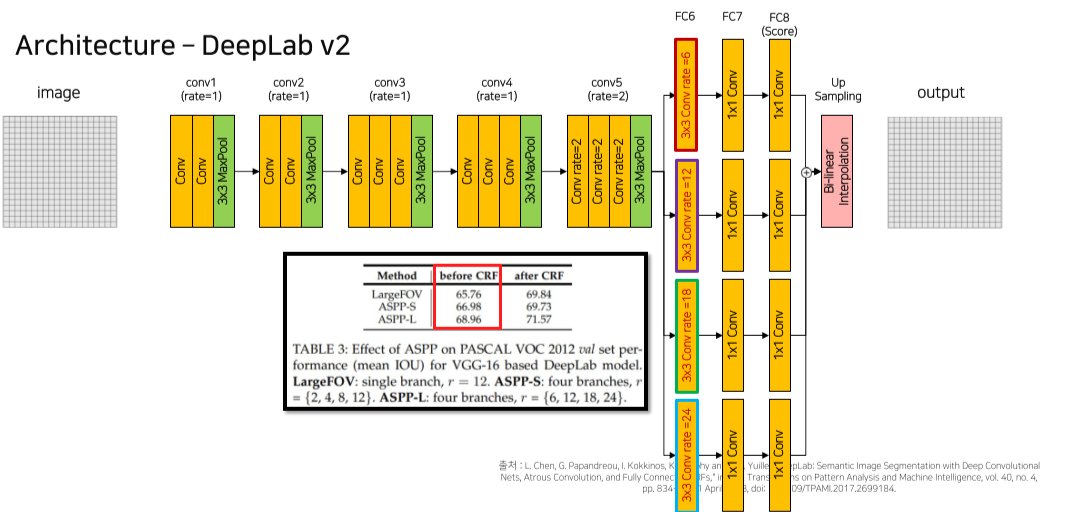
다양한 크기의 dilate rate를 줘서 low rate에서는 kernel size가 작아 small obj를 위주로, high rate에서는 kernel size가 커서 big obj 위주로 segmentation
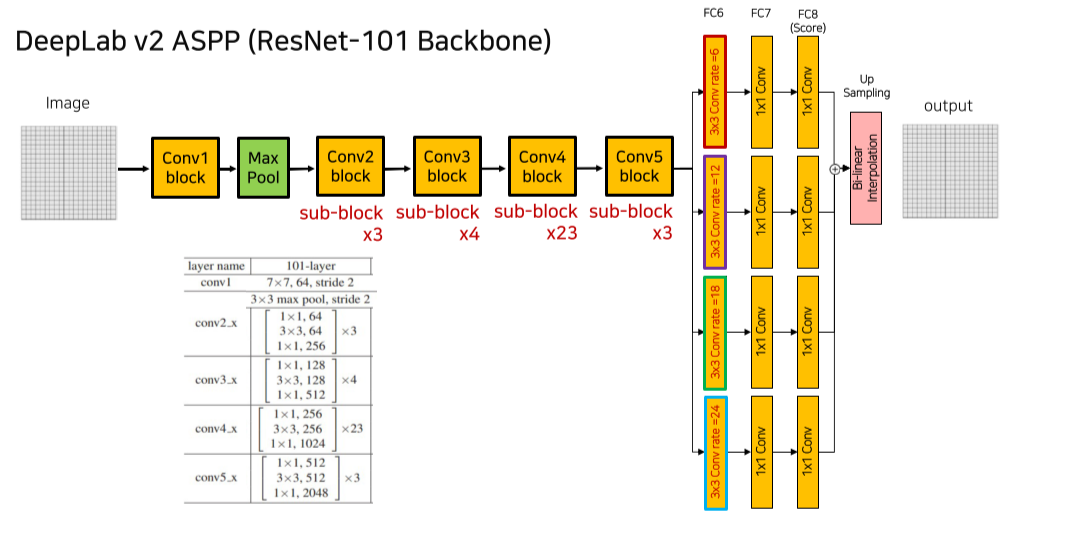
각 conv block은 (strided) conv-BN-ReLU로 구성된 sub block으로 이루어지며 sub block 단위로 skip connection이 추가됨
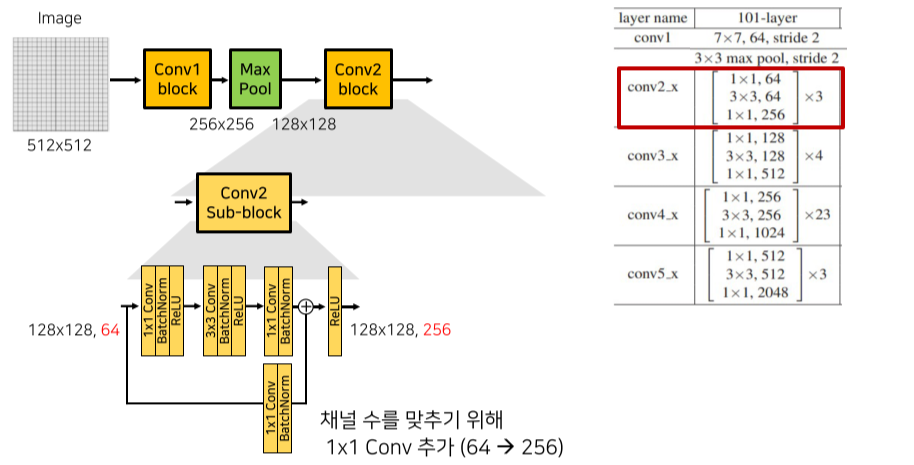
Channel 수가 변경될 때엔 skip connection에도 1x1 conv가 들어가서 channel 수를 맞춰줌
4) PSPNet
도입 배경
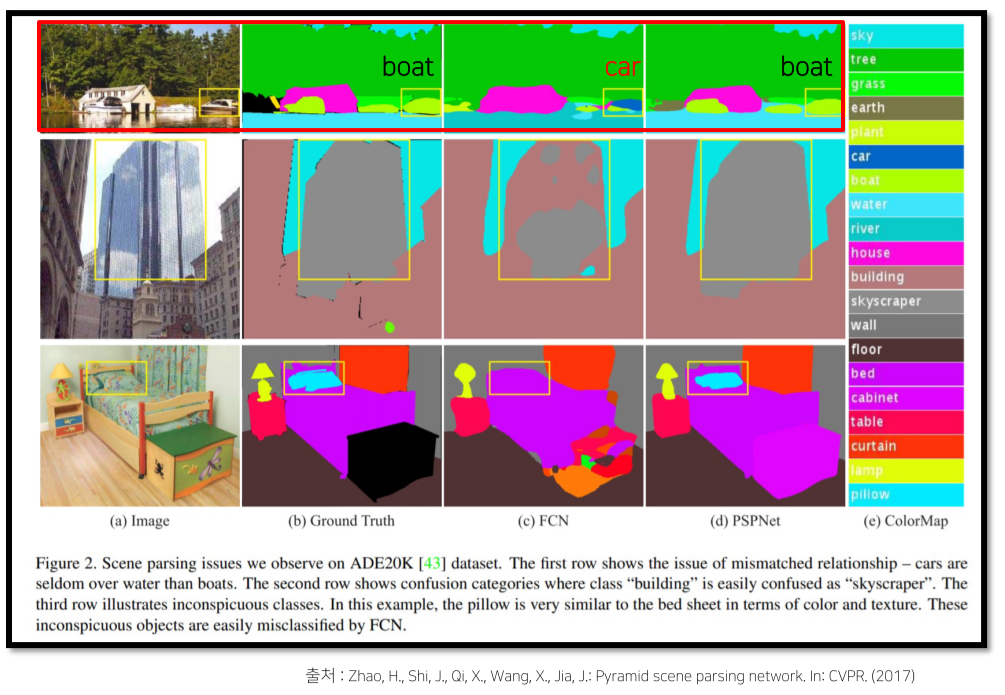
-
Mismatched relationship: boat - car의 외관이 비슷해서 호수 주변에 있는 boat도 car로 예측
-
Confusion Categories: 비슷한 범주인 skyscraper - building
-
Inconspicuous Classes: pillow의 obj size가 작고 bed sheet와 같은 무늬라 예측에 한계
Max pooling을 5번 해서 image size가 1/32로 줄어서 생긴 문제
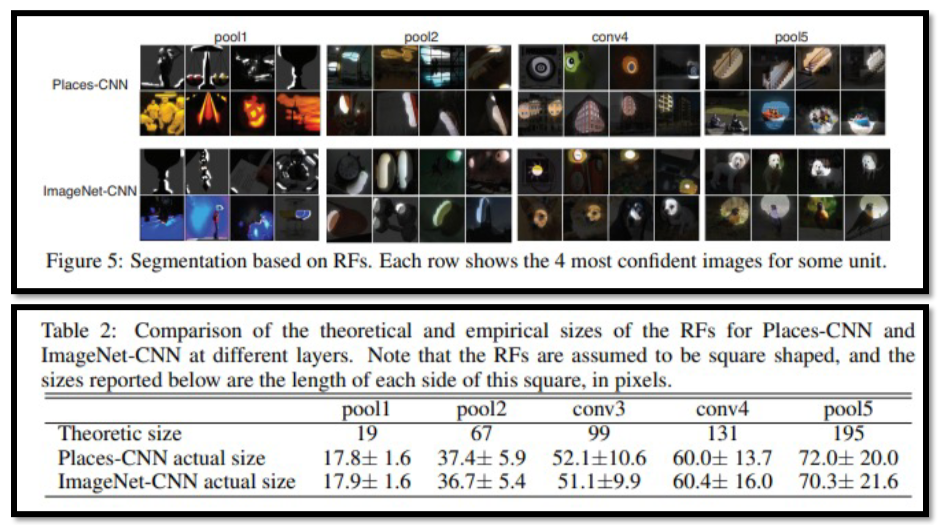
또한 receptive field의 이론-실제 size의 차이가 많이 남
Architecture
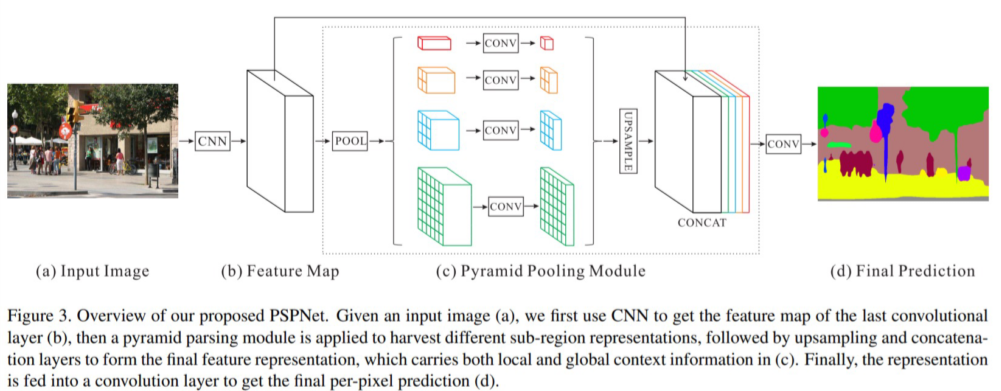
Feature map에 1x1, 2x2, 3x3, 6x6 출력의 average pooling을 적용해 sub-region 생성
Feature map과 pyramid pooling module을 upsampling한 output을 서로 concat
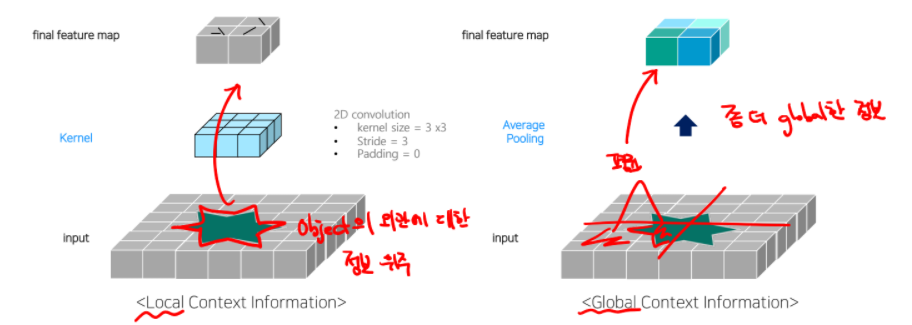
Average pooling은 convolution에 비해 global info를 잘 잡아낸다는 장점이 있음
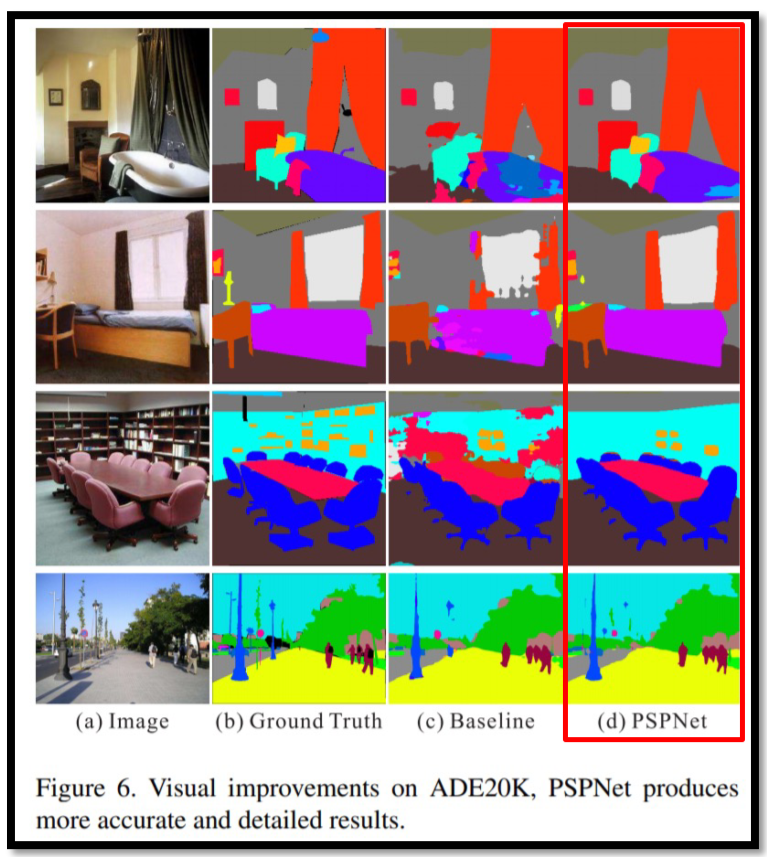
성능 올라간걸 확인 가능
5) Deeplab v3
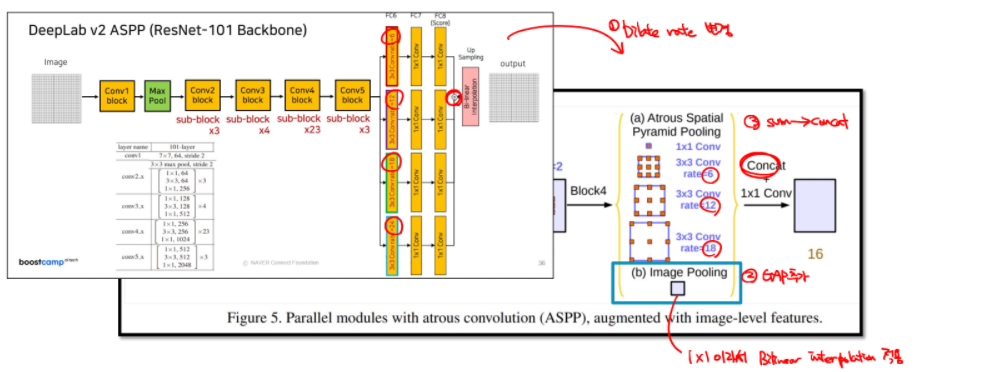
Deeplab v2에서 dilate rate를 변경하고, GAP 추가, sum을 concat으로 변경한게 차이점
GAP의 output은 1x1이라 bilinear interpolation을 적용
1x1 pixel의 bilinear interpolation은 padding처럼 확장하는 식으로 전개
6) Deeplab v3+
Architecture
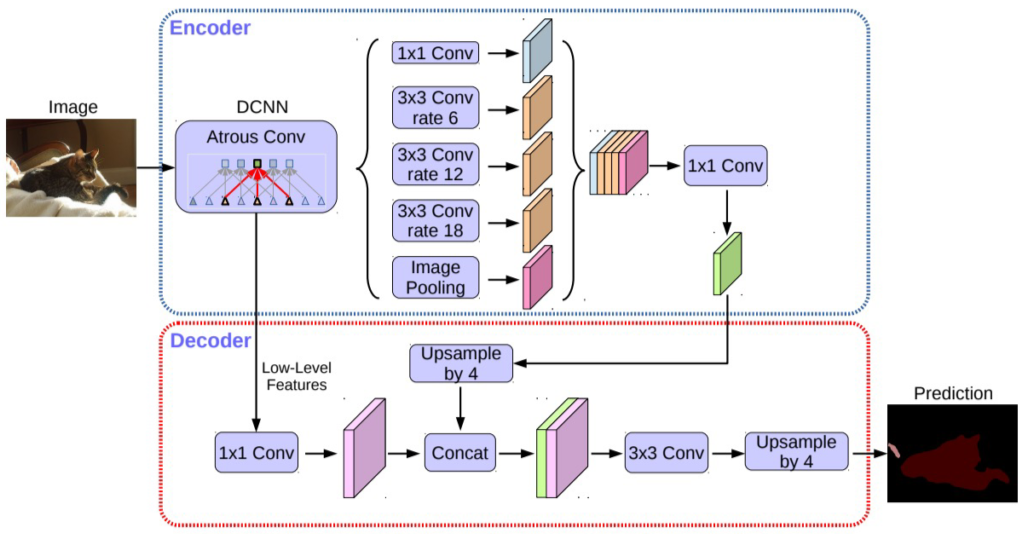
Encoder-Decoder 구조
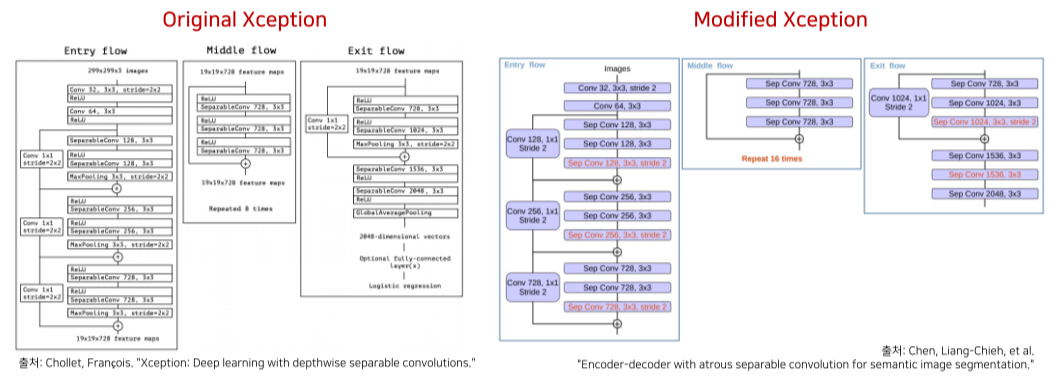
modified Xception을 backbone으로 사용
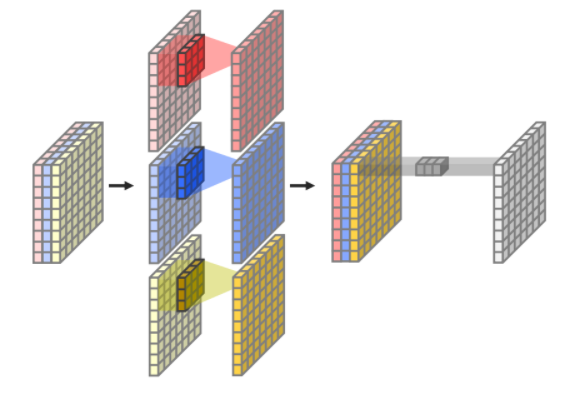
Xception에서는 depthwise, pointwise conv를 합친 depthwise separable convolution을 사용
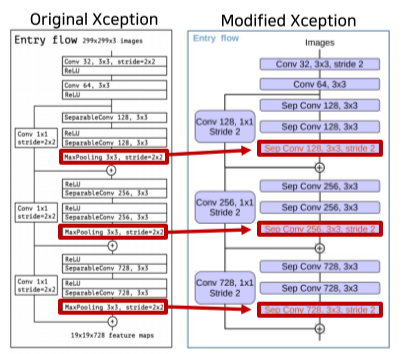
Max pooling을 depthwise separable convolution으로 바꿔서 더 detail한 정보를 고려할 수 있음
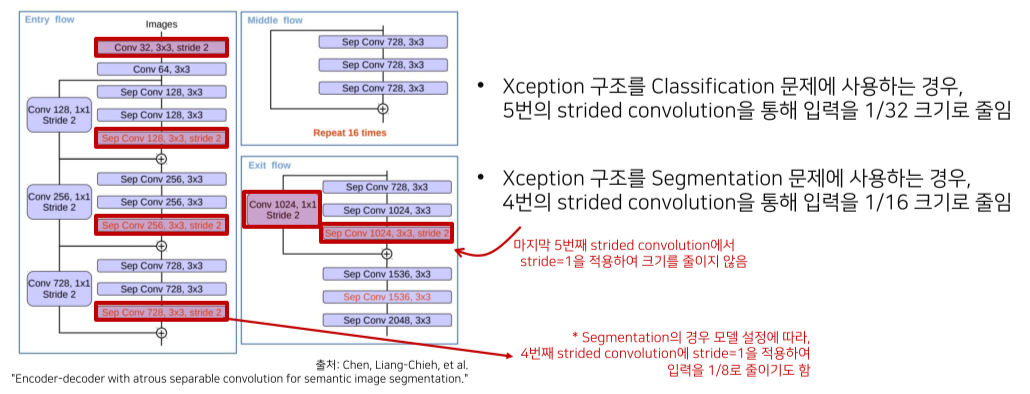
Task에 따라 input size를 줄이는 정도가 다름
Encoder
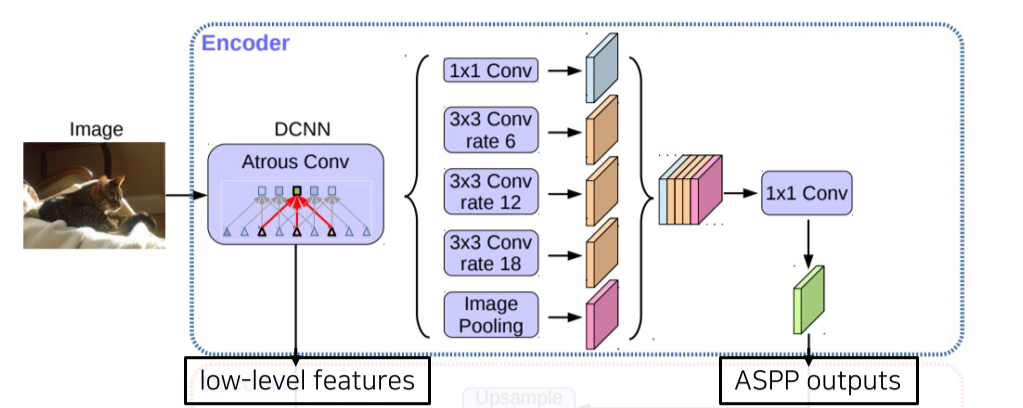
Atrous separable convoltion을 적용한 ASPP 모듈 사용
Backbone 내 low-level feature와 ASPP 모듈 출력 모두 decoder에 전달
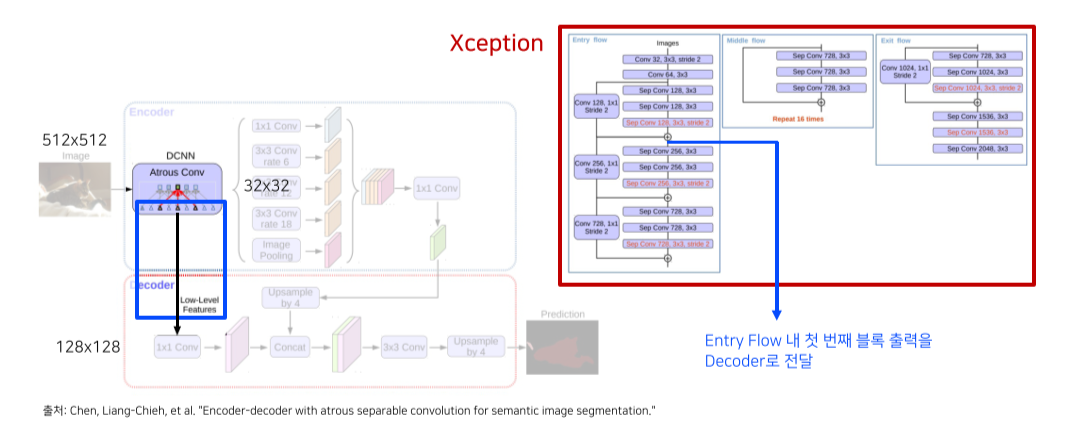
Skip connection은 entry flow의 첫 블록 출력을 이용함
Decoder
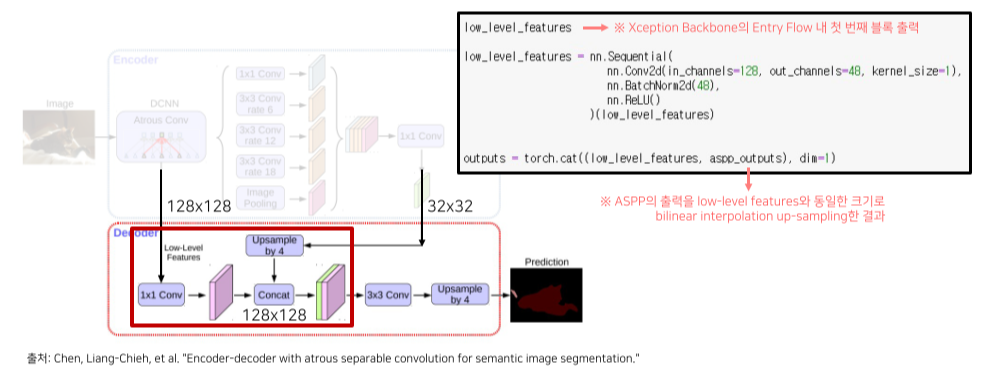
ASPP module의 출력을 bilinear upsampling해서 low-level feauture와 결합
