1. 탄생 배경
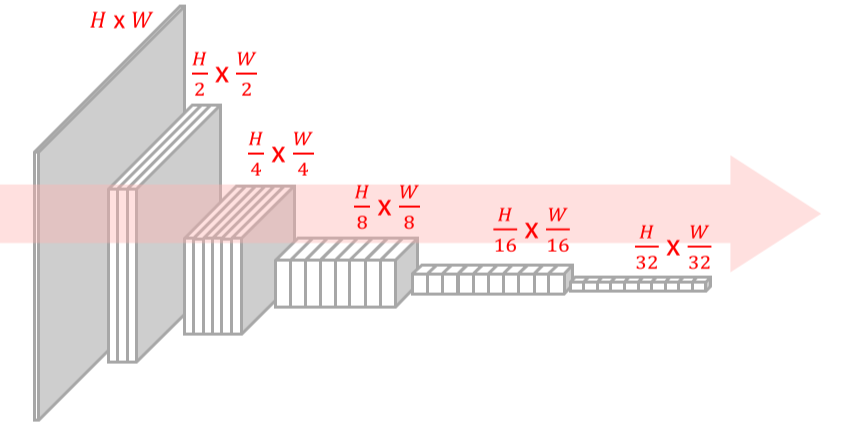
기존 image classification을 위한 CNN은 high resolution input을 low resolution으로 줄여나가는 LeNet 기반 설계를 이용
--> classification에는 모든 feature가 필요하지 않으며, 해상도가 줄면 computational complexity가 줄고, receptive field가 커지기 때문 + 중요 feature만 추출해서 overfitting 방지
하지만 semantic segmentation은 모든 pixel에 대한 분류가 필요하기 때문에 high resolution을 유지하는게 좋음
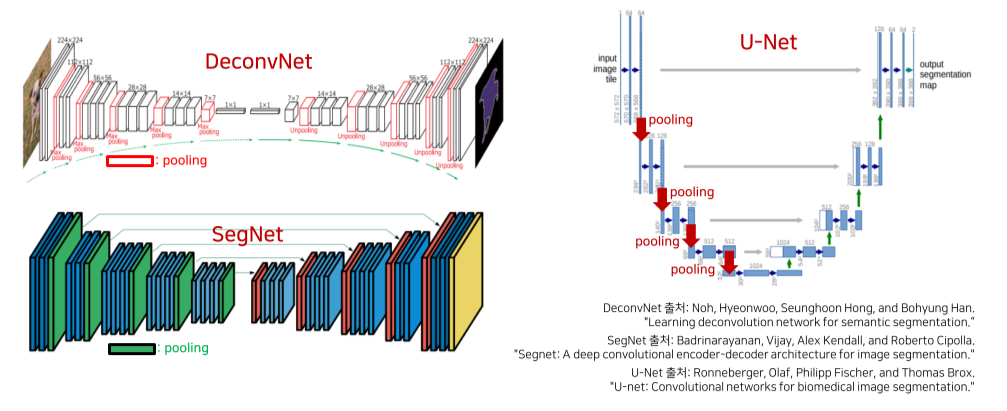
DeconvNet, SegNet: max pooling시 어떤 pixel에서 값을 가져왔는지를 저장해서 unpooling시 공간 정보(positional information)를 살림
U-Net: transposed conv, skip connection을 이용해 공간정보를 살림
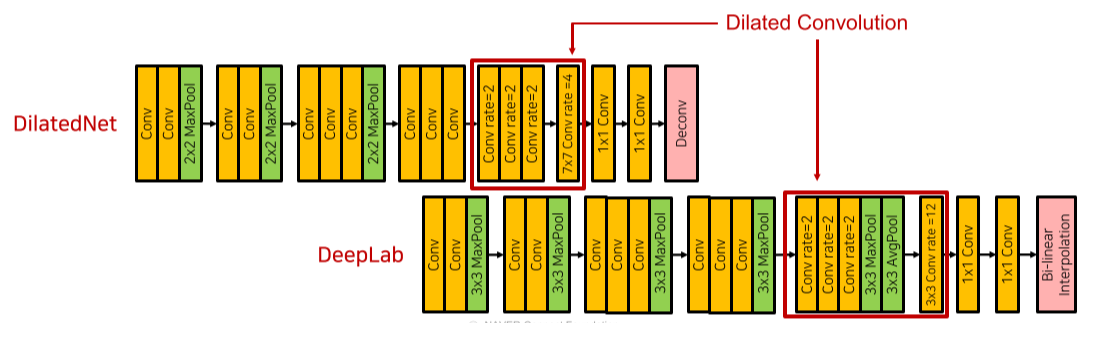
DilatedNet, Deeplab: sampling, unsampling을 dilated convolution으로 대체해 medium resolution까지 줄이면서 receptive field를 늘림
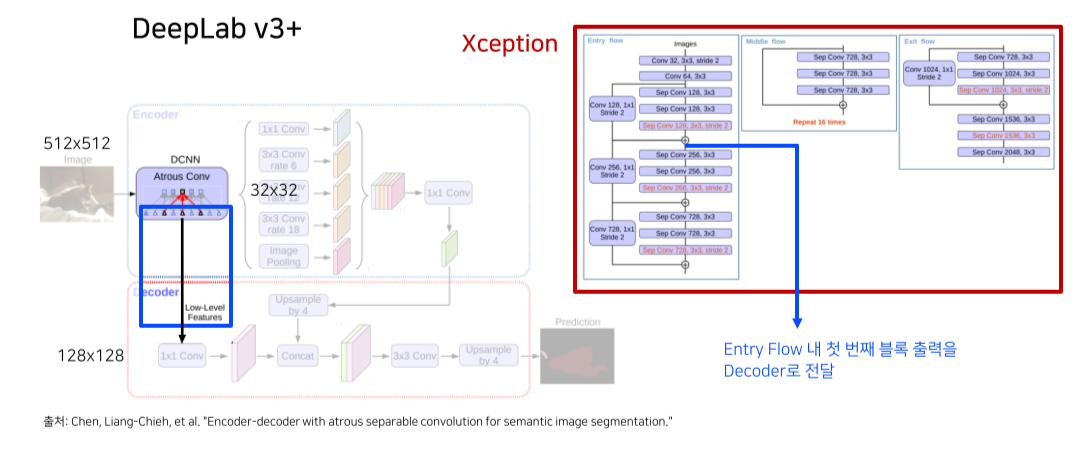
DeeplabV3+: Depthwise separable convolution으로 max pooling을 대체해 detail information을 살리고,
backbone에서 decoder로 skip connection을 추가함

이런 이전의 모든 classification based model은 1) 높은 time complexity, 2) low position-sensitivity라는 단점이 존재했음

이를 해결하기 위해 high resolution을 계속 유지하는 HRNet(High Resolution Network)이 등장
2. 구조
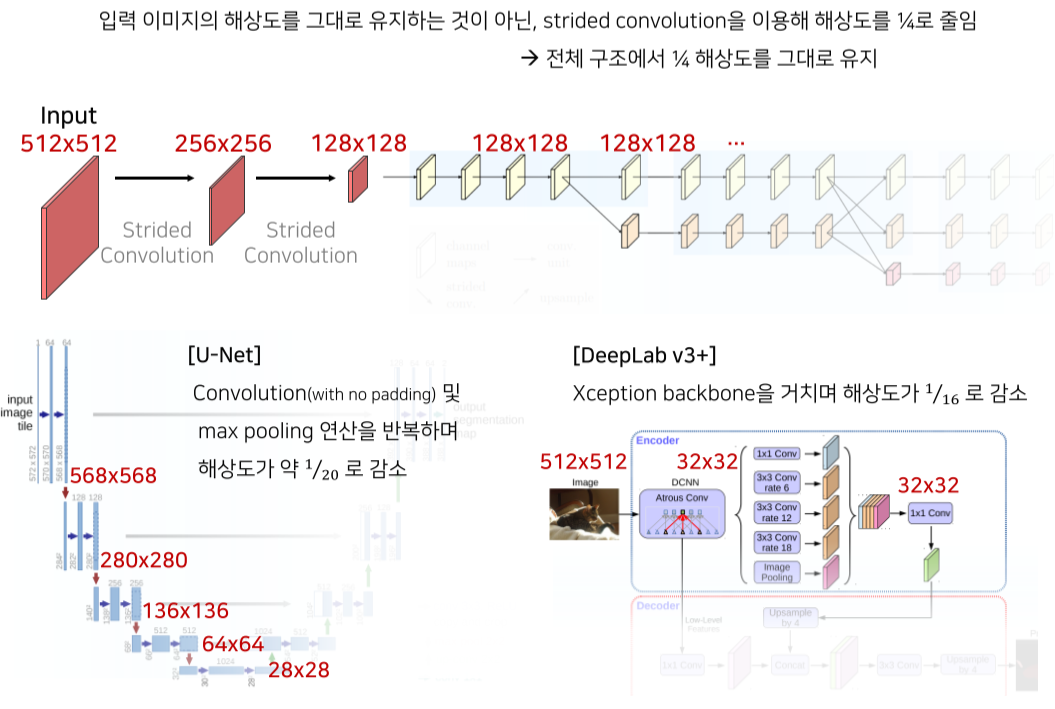
- 해상도를 input image의 1/4로 유지
기존 model들은 1/20, 1/16 정도로 유지했기 때문에 상대적으로 high resolution을 유지함

- 다양한 receptive field를 갖는 feature를 생성
Low resolution의 feature: 넓은 receptive field로 상대적으로 풍분한 semantic information을 가짐
High resolution의 feature: positional information이 많이 살아 detail한 정보를 가짐
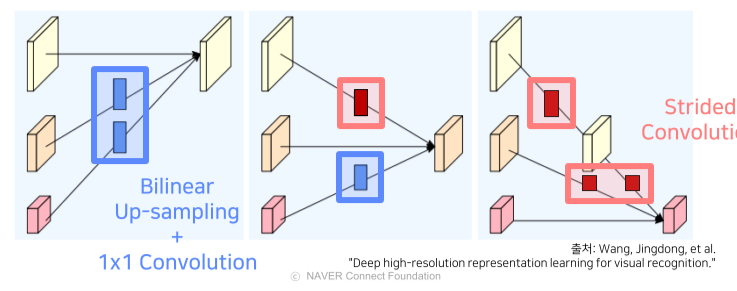
- High/low resolution feature를 각 stage마다 sum해서 다양한 feature를 고려할 수 있게 함
High -> low: Convolution의 stride = 2로 size / 2, channel x 2, pooling 대신 stride를 사용해 정보 손실을 최소화함
Low -> high: 1x1 conv, bilinear upsampling으로 channel / 2, size x 2
Computational complexity를 위해 1x1 conv 이후 upsampling 진행
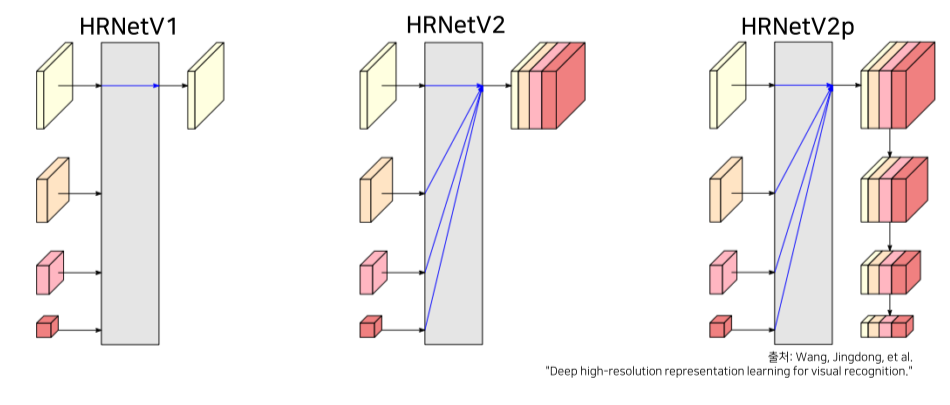
- Task에 맞는 output을 생성
V1: high resolution feature만 사용해서 pose estimation, keypoint detection에 활용
V2: low resolution feature를 bilinear upsampling 후 모든 feature를 합해서 semantic segmentation에 활용
V2p: HRNetV2에서 down sampling한 결과를 출력해 Faster-RCNN 등의 backbone으로 사용돼 object detection에 활용
3. 세부구조
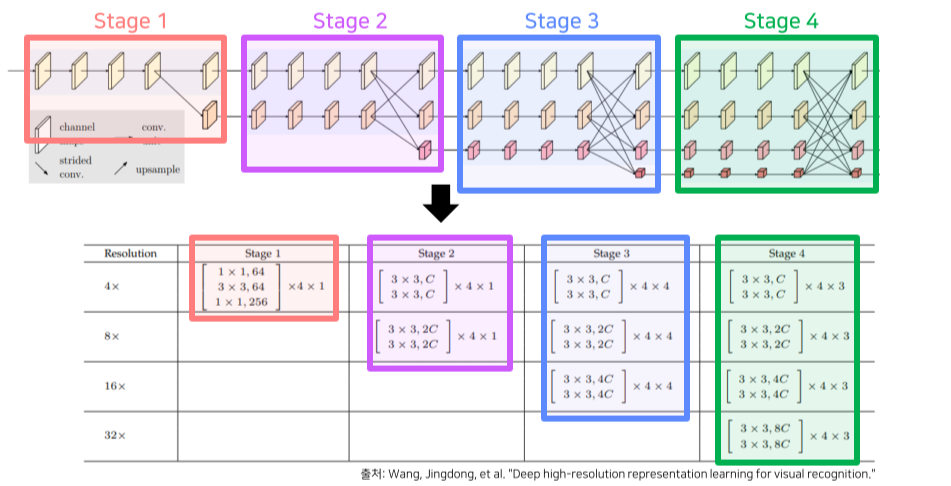
총 stem + 4 stages로 구성
Stem

HRNet의 channel 수는 최상위 resolution의 channel을 기준으로 하며, model에 써있는 숫자를 따른다
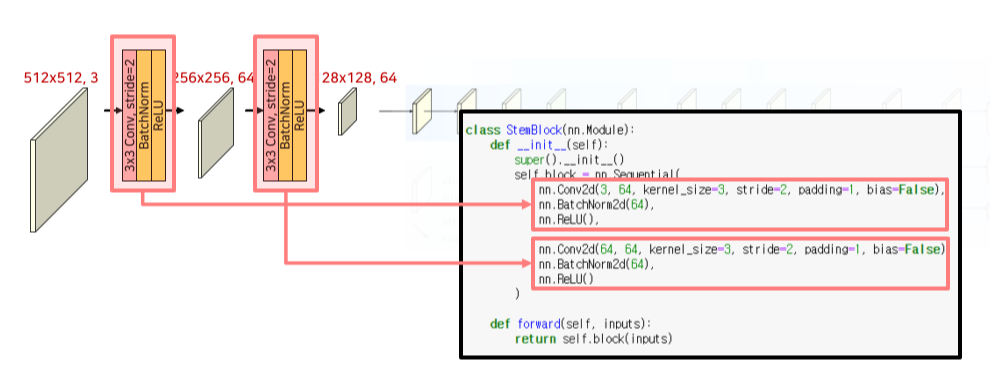
Stem에서는 input resolution의 1/4만큼 size를 줄임
Stage 1
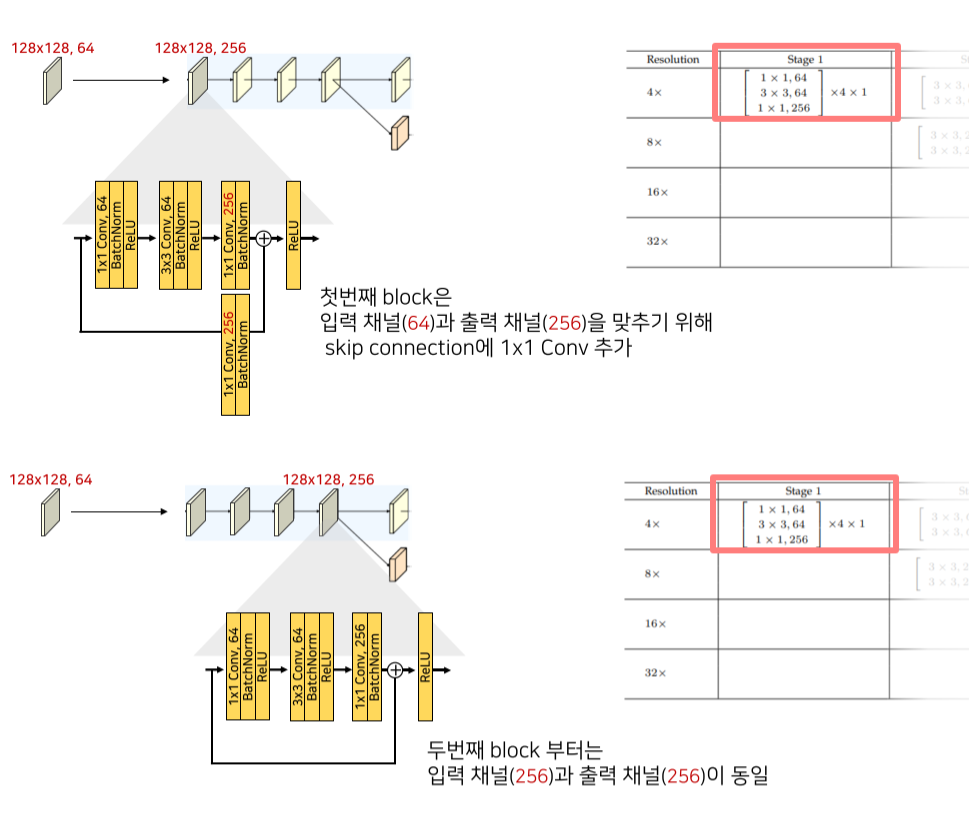
각 stage마다 동일한 block이 4번 반복됨
첫 block은 input-output channel이 다르기 때문에 skip connection에도 1x1 conv가 추가됨
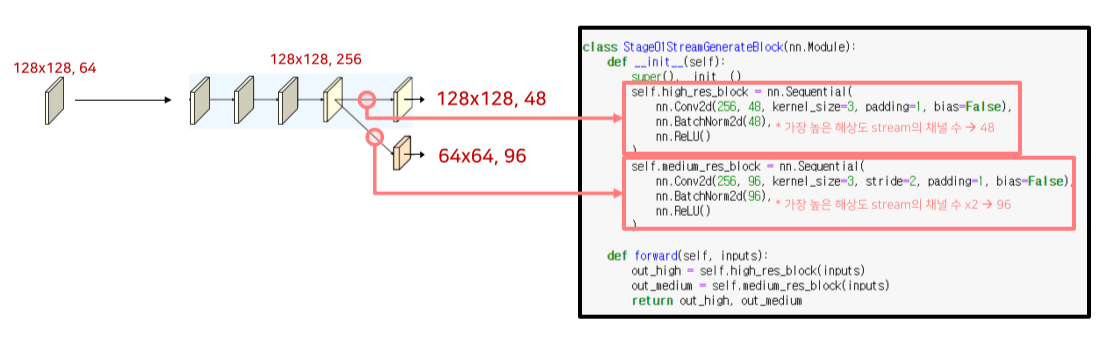
4번째 block 이후엔 하위 stream 생성
Strided conv(convolution의 stride = 2)로 channel x 2, size / 2
Stage 2
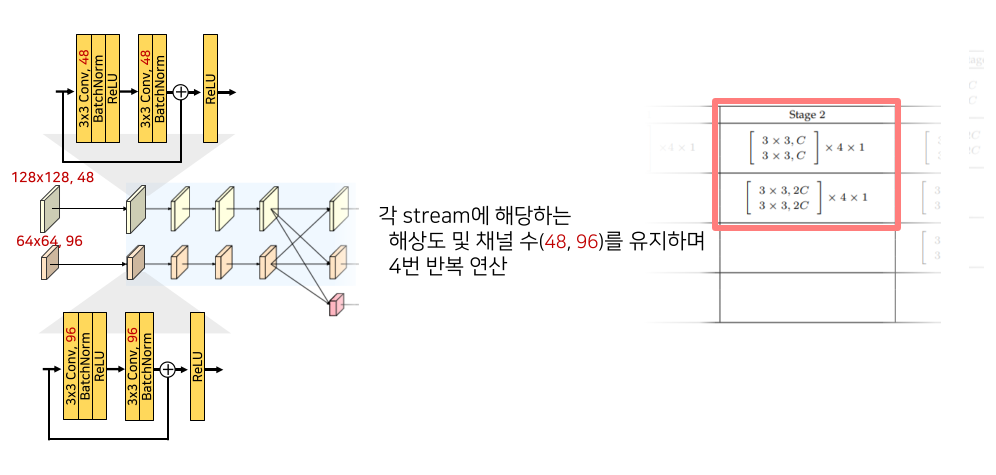
각 block은 2번의 3x3 conv로 구성, 총 4 block을 반복
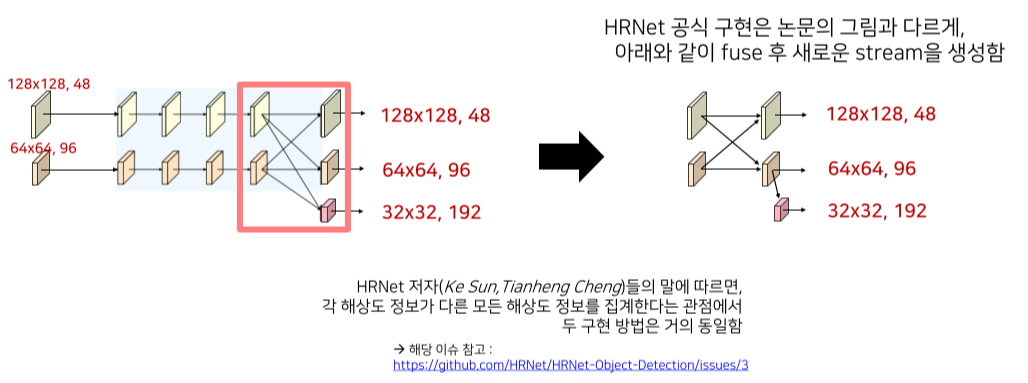
새로운 하위 stream은 high-mid resolution을 sum 후 생성

Feature의 크기를 키울 때는 computational complexity를 고려해 1x1 conv 후, bilinear upsampling
줄일때는 strided convolution을 이용
Stage 3, 4
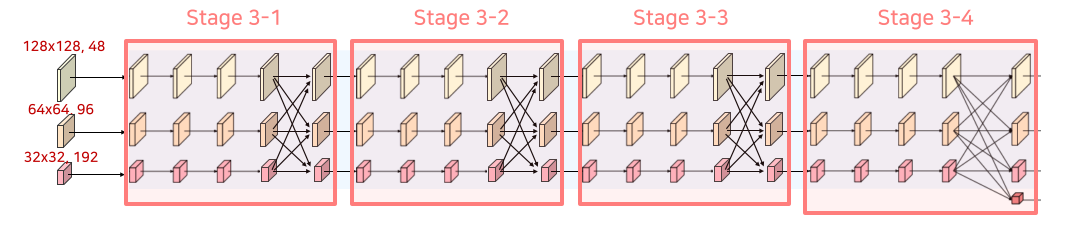
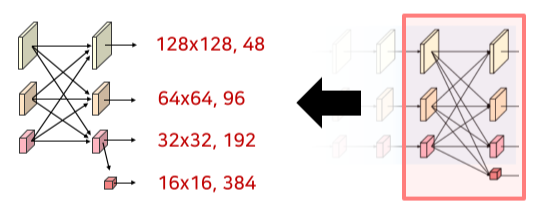
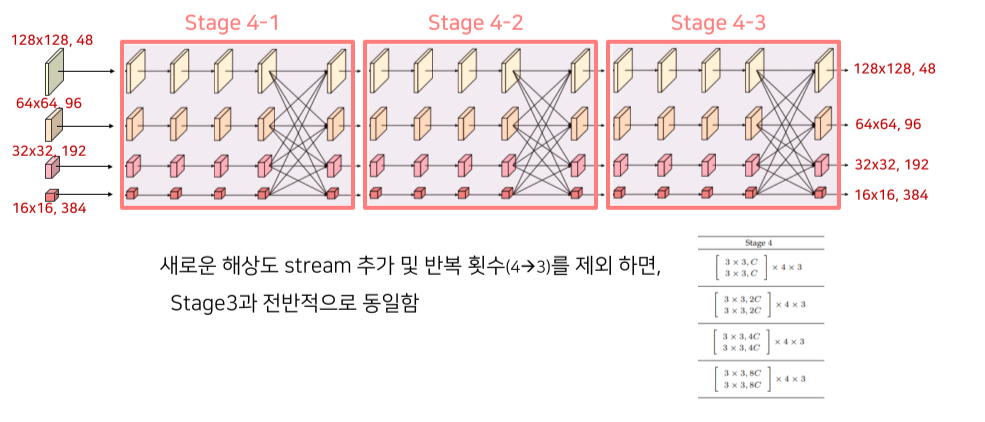
Stage 2에서 사용한 block을 channel 수만 변경해서 동일하게 사용
Representation head
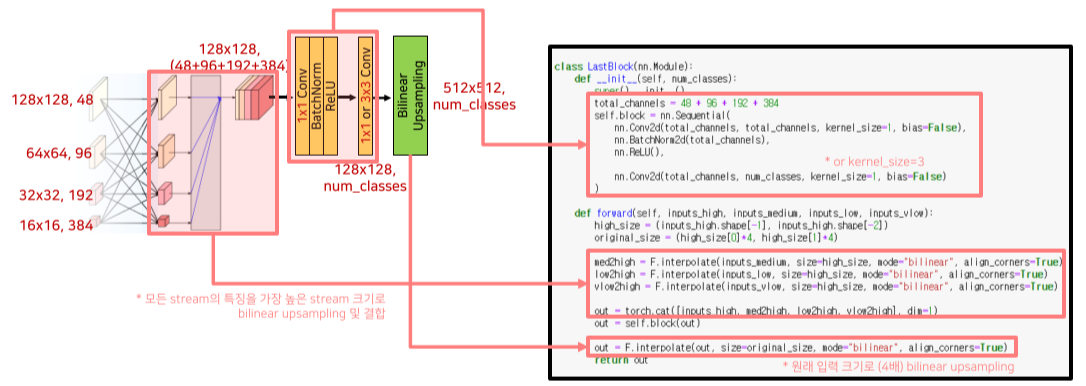
- 저해상도 특징들을 bilinear upsampling 후 모든 특징들을 결합
- 두 번의 1x1 conv 연산으로 최종 예측할 카테고리 수만큼의 채널 생성
- 원래 입력 이미지 크기(x4)로 bilinear upsampling하여 최종 출력 형성
4. 실험 결과
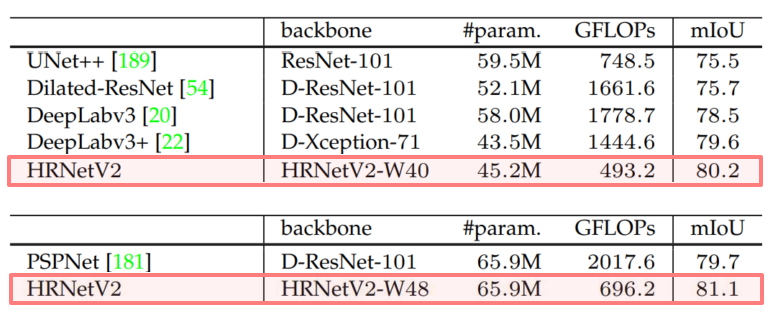
모델 크기(#param.) 및 계산복잡도(GFLOPs)에 따른 성능(mIoU) 비교
일반적인 classification network을 backbone으로 사용한 UNet++, DeepLabv3(+), PSPNet 과 비교하여 HRNet을 사용해 더 작은 모델로 더높은 성능을 기록
