문제제기
Train 하기 전에 weight initialize하는데 안 하는 것과 무슨 차이가 있을까요? 다른 코드들 보면 안하는 경우가 더 많은 거 같아서요.
라는 질문이 부스트코스 오픈카톡방에 올라와서 논의를 하게 됐고, 그에 대한 기록과 나음대로의 정리를 해보려고 한다.
첫 생각
나는 처음에는 train하면서 weight(parameter)는 update되가니까 초기값이 어떤 값이라도 상관 없어서 그런거 아닐까?라고 생각했었다.
하지만 다른분들의 의견도 들어보고 조사를 해본 결과 몇 가지 이유가 있다는 것을 알 수 있었다.
다른 캠퍼분들의 의견
-
초기값이 모두 0이면 문제가 생기기 때문에
-
torch는 tensor를 만들면 자동으로 난수를 넣어주기 때문에 init을 생략하기도 한다
보통은 seed를 통일하거나, 기타 오류를 제거하기 위해 init을 명시하는 편
혹은 특정 initializer를 사용하기 위해
-
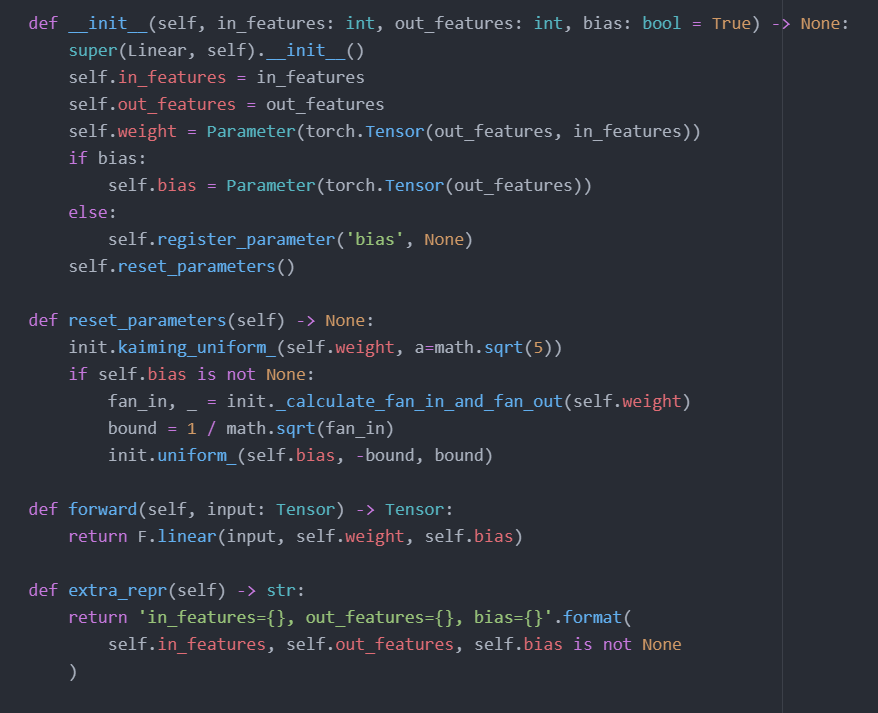
보통 keras나 torch에서 nn.Parameter로 register*하는 경우가 아니면 미리 적절하게 weight initialization 되어있어서 그렇다
그 예로 nn.Linear(affine transformation)를 보면 weight, bias를 full-rank가 아닌 empty로 생성하고 nn.Parameter로 등록 후 reset_parameters()로 초기화한다
default로 설정된 kaiming uniform 말고도 다른 method로 init할 수 있다(https://pytorch.org/docs/stable/nn.init.html)
NLP를 하는 사람이라면 익숙한 huggingface 라이브러리에서도,
각 모델 별 init weight 조절을 달리 해주는 편
*register: nn.Module이 인식할 수 있게 모델 parameter를 등록해주는 행위 -
가끔가다보면 논문 구현 코드에 따로 init을 해주는 경우가 있는데,
1) 직접 다른 분포로 초기화를 하고 싶거나
2) 아님 nn.Parameter로 torch에 없는 모델을 구현하고 싶거나(주로 GAN류)
3) 명시적으로 어떤 분포로 학습했다는 것을 알리고 싶거나 (그럴일이 거의 없긴 하지만)
멘토님 답변
- 가중치 초기화(weight initialization)는 딥러닝 학습의 어려움을 극복하기 위한 방법 중 하나
- 초기값을 올바르게 설정하는 것이 이유
optimization에서 어떤 초기값에서 출발하느냐에 따라 local minimum, global minimum에 빠지느냐가 결정되기 때문에 아무리 좋은 optimizer를 사용하여도 초기값을 잘못 설정하면 global minimum으로 수렴하기가 상당히 어렵다 - 하지만 딥러닝 모델은 거대한 feature space를 가지고 있기 때문에 올바른 초기값을 설정하는 것은 어렵다
forward에서는 전달되는 값이 너무 커지거나 작아지지 않게,
backward에서는 gradient vanishing/exploding이 일어나지 않게 weight를 적절히 초기화하는 것이 중요
하지만 이는 정해진 규칙이 없으며 휴리스틱하게 설정해야함
자료조사
-
Breaking Symmetry in Deep Learning
N-layered DeepLearning model에서 weight를 0으로 initialize했을 경우 cost는 줄어들지만 weight는 update되지 않는 현상(symmetry)을 목격할 수 있음
--> bias만 update되기 때문 -
Why doesn't backpropagation work when you initialize the weights the same value?
Weight가 모두 똑같으면 output unit들은 모두 똑같은 error(cost?)를 갖게되고, optimization에서 다시 weight가 모두 똑같이 update되기 때문에 output들이 항상 같게 나올 수 밖에 없다
--> model이 unequal weight에 절대 도달할 수 없음 -
Neural Network: The Dead Neuron
What is the “dying ReLU” problem in neural networks?
NN을 모두 0으로 initialize하고 ReLU를 적용하면 dead neuron*이 돼버려 모든 input에 대해 output으로 0만 출력하게됨
* dead neuron은 learning a large negative bias term for its weights할 경우에도 발생함(weight exploding) -
Xavier and He Normal (He-et-al) Initialization
activation function에 따라 적절한 initialize 방법이 달라짐
sigmoid류일 경우엔 Xavier init이, ReLU류일 때엔 He(Kaiming) init이 적절하다
정리
다른 분들의 답변과 자료조사를 통해 알아낸 바를 정리해보자면,
- Weight Initialize:
- local minimum에 빠져 model 성능이 떨어지는 것을 방지
- model에 따라 적절한 init 방식을 선택
- gradient가 vanish/explode하는 것을 방지
- model을 재현할 때 동일한 성능을 내기 위해서 seed를 통일하기 위해서
- PyTorch 등에서 weight initialize를 따로 하지 않는 이유:
- 함수 내부에서 알아서 reset_parameter()를 통해 init하기 때문에
정도가 될 것 같다.
추가자료
def seed_everything(seed=2021):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.use_deterministic_algorithms(True)- seed를 고정할 때 쓰는 코드
