필수과제1) ViT: Vision Transformer
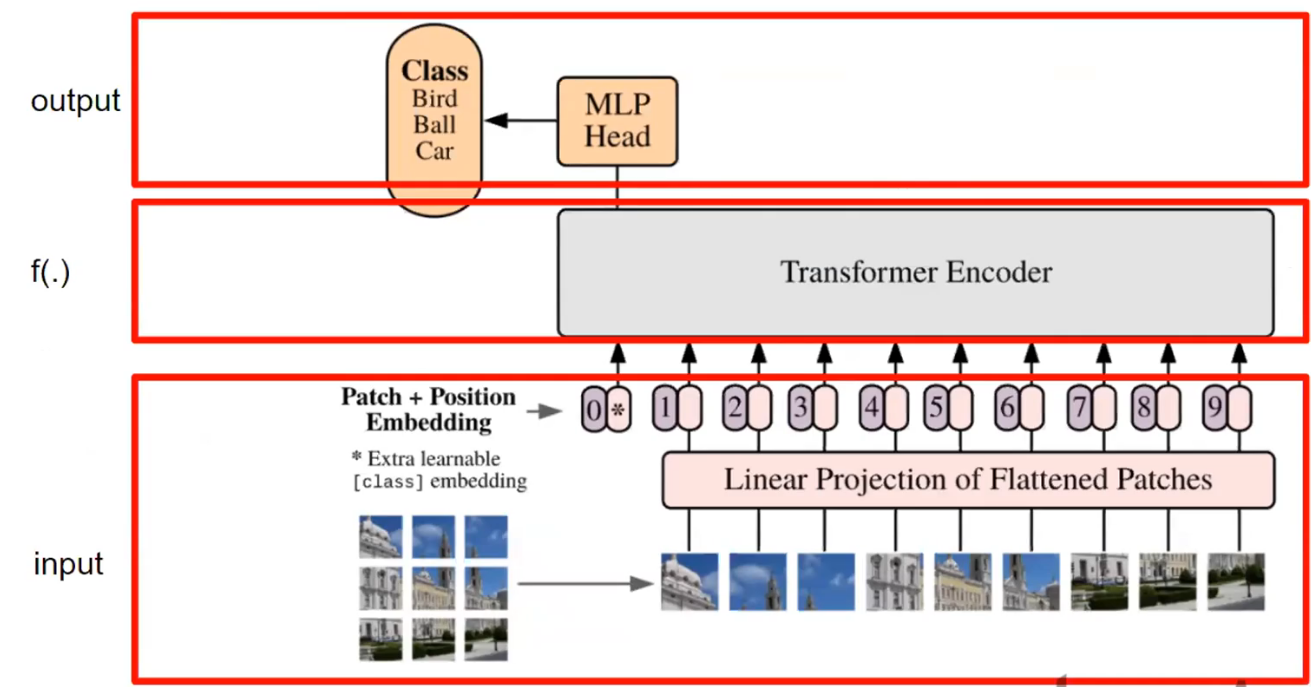
- 논문: https://arxiv.org/abs/2010.11929
리뷰: https://jeonsworld.github.io/vision/vit/ - 구현 참고: https://yhkim4504.tistory.com/5
- NLP에서 쓰이는 transformer를 CV에 적용
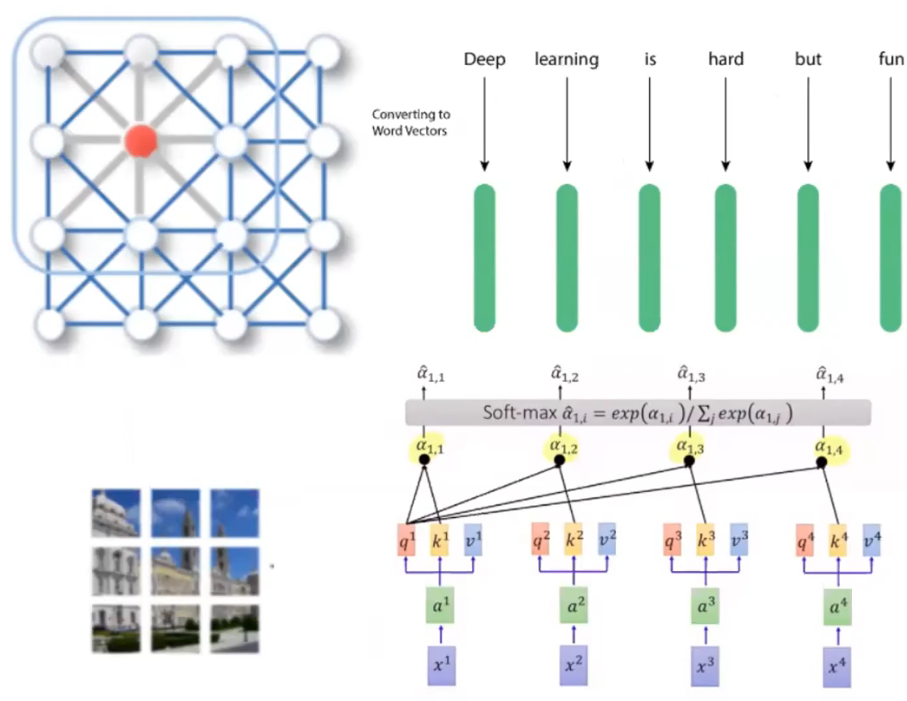
- NLP에서는 connection이 먼(문장 상에서 거리가 먼) node들의 정보도 가져오고 싶어서 attention을 이용했다
- image는 각 픽셀을 node로 볼 수 있다
하지만 모든 픽셀과의 관계(attention)을 보는 것은 비효율적 - 그래서 sub-patch를 적용
- patch는 einops 라이브러리를 활용
(torch.view보다 훨씬 간편해서 적극 추천)
Patch Embedding
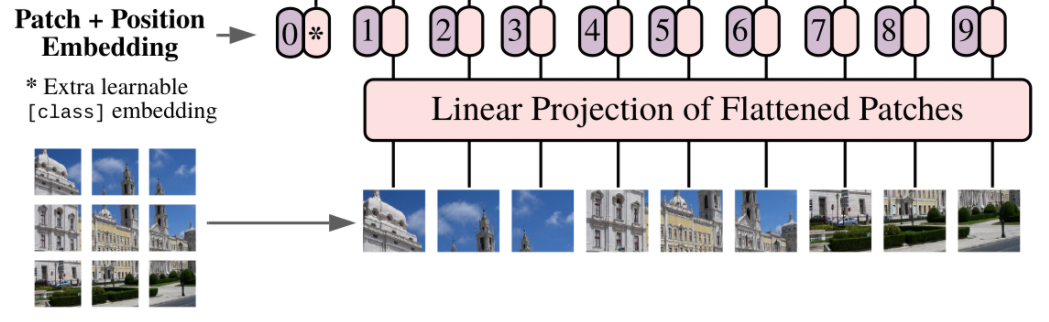
- According to the paper, "To handle 2D images, reshape the image into a sequence of flattened 2D patches where is the resolution of the original image, is the number of channels, is the resolution of each image patch, and is the resulting number of patches, which also serves as the effective input sequence length for the Transformer. The Transformer uses constant latent vector size through all of its layers, so we
flatten the patches and map to dimensions with a trainable linear projection."
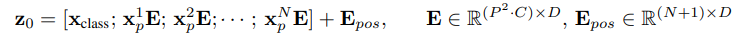
- : input image의 resolution(height, width)
- : input image의 channel
- : pathch의 갯수
- : patch의 한 변의 길이
- : embedding vector의 dimension
Encoder
MHA, Multi-head Attention
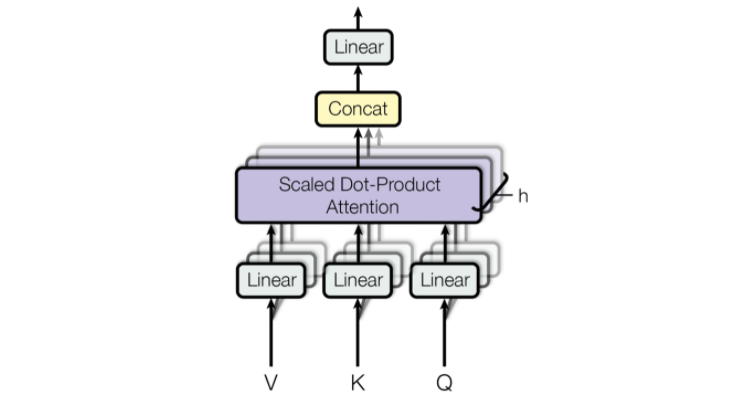
Linear Projection
- Patch+Position embedding 된 벡터를 linear projection해서 embedding size로 맞춰줌
Multi head
- embedding vector와 크기가 같은 QKV를 head_num으로 나눠줌
SDPA, Scalde Dot-Product Attention

- 위 계산을 통해 MHA의 output이 나옴

즐겁게 개발하기