Variational Auto-encoder
Variational inference(VI)
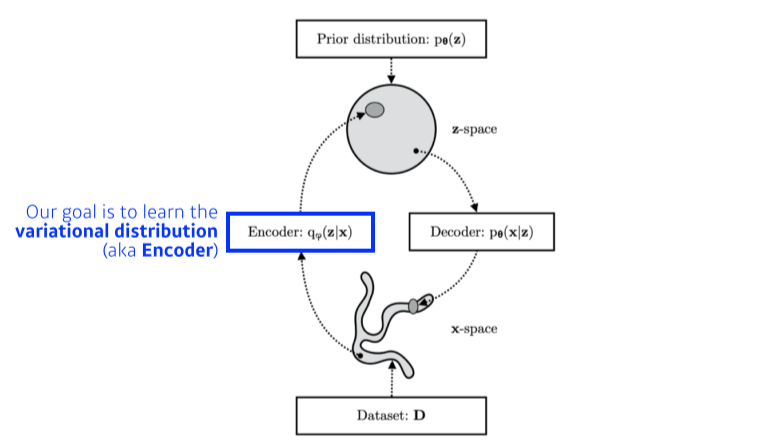
Posterior distribution 를 찾는 것이 목적. 그래서 Variational distribution을 optimize한다
- Posterior distribution : observation이 주어졌을때, 내가 관심있는 random variable의 확률분포
- Variational distribution : Posterior distribution을 구하기 어려워서 대신 근사하는 분포
KL divergence를 이용해 둘 사이의 차이를 줄임 - : latent vector
- : likelihood
ELBO, Evidence Lower BOund
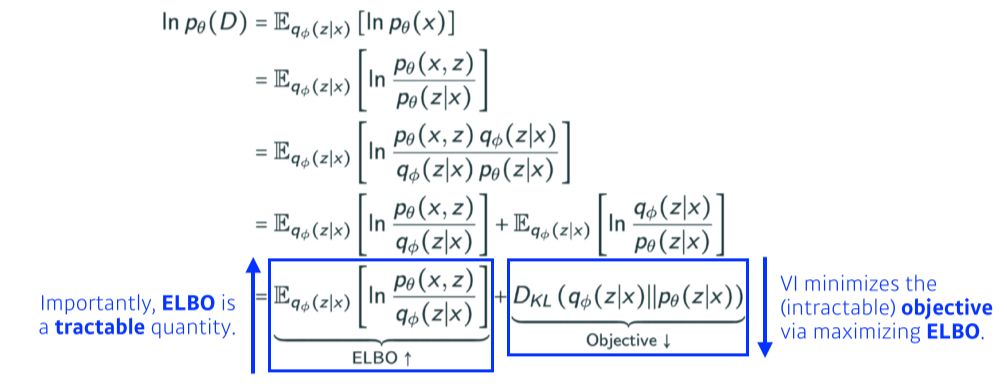

--> 유도해보기!!!
- reconstruction term: encoder를 통해 를 latent space로 보냈다가, 다시 decoder로 돌아오는 reconstruction loss를 줄이는 것
- prior fitting term: 를 latent space에 올렸을 때의 분포가 내가 가정하는 latent space의 prior distribution과 비슷하게 만들어줌
최종 목적
-
라는 input에 대해, 그것을 가장 잘 표현할 수 있는 latent space 를 찾고싶다
-
하지만 에 대한 확률분포 (posterior)를 모르니까 그 posterior를 잘 찾기 위해 variation distribution으로, encoder로 근사해서 찾으려는것
-
근데 posterior distribution을 모르니까 근사할 수 없어서, variational inference을 이용해 ELBO를 maximize하는 것이 Posterior distribution과 Variational distribution의 거리를 줄여주는 것을 알게됨
-
근데 variational inference는 reconstruction term과 prior fitting term으로 나뉜다라는 것이 유도됨
Key Limitation
- Intractable model임
Explicit한 모델이 아니기 때문에 likelihood를 알기 힘들다
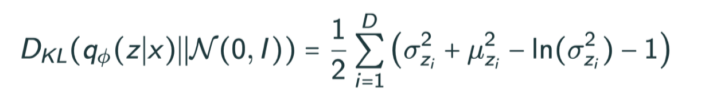
- Prior fitting term(KL divergence)이 differentiable해야함
KL divergence를 SGD, Adam 같은걸로 optimize해야해서 미분가능해야됨
KL divergence는 Gaussian을 제외하곤 closed form으로 나오는게 별로 없다
그래서 대부분은 prior distribution으로 isotropic Gaussian(모든 output dimension이 independent한 Gaussian)을 사용한다
Adversarial Auto-encoder
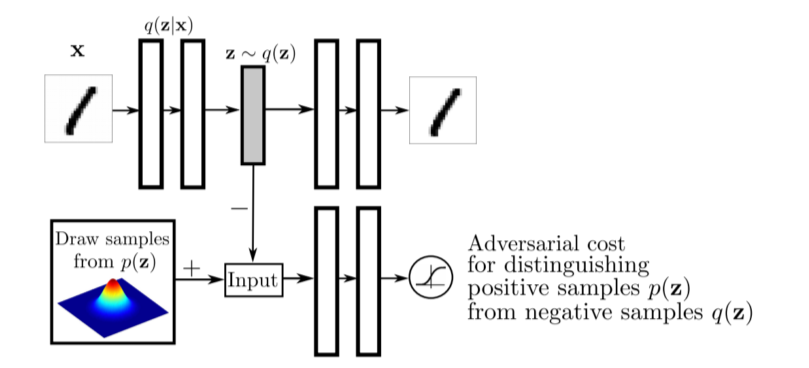
- GAN을 활용해서 latent space간 분포를 맞춰줌(KL div를 대체)
그래서 latent distribution을 sampling만 가능한 어떠한 분포가 있어도 맞출 수 있다
Generative Adversarial Network
Generative Adversarial Networks
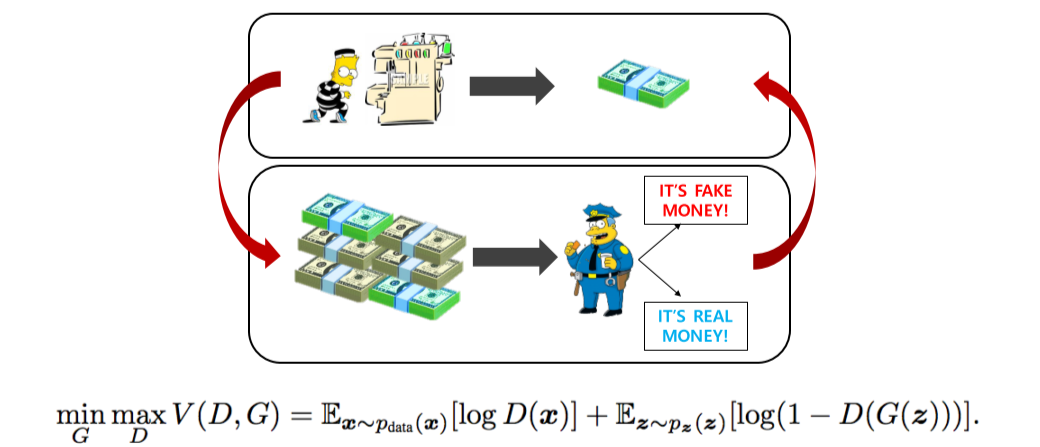
- Generator: 더 잘 속이려고 진짜같은 output을 만듬
- Discriminator: output의 진짜가짜를 구분해냄
- 확률 분포 파라미터를 학습하는 것이 아니라, 단지 원본데이터와 예측데이터의 분포가 비슷하도록 Generation하기 때문에 Implicit model임
- : Discriminator
- : Generator
- : loss function
- : noise
- : 가짜 데이터
- : 진짜 데이터
- : real data distribution에서 뽑은 샘플
- : 가우시안 분포에서 뽑은 샘플, fake data z
GAN vs VAE
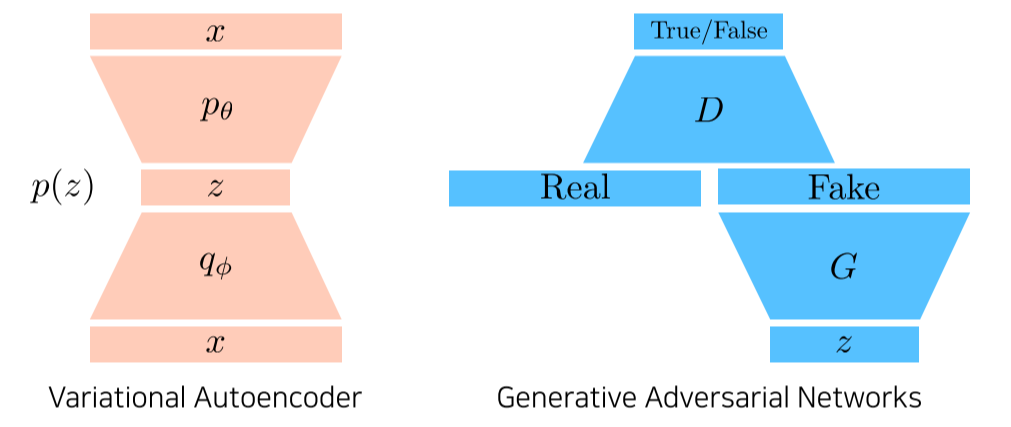
-
VAE: input 가 encoder를 통해 latent space로 갔다가 decoder를 통해 다시 라는 domain으로 나오는걸로 학습
Generation 단계에서는 latent distribution에서 를 sampling해서 decoder를 통해 나오는 결과 가 결과 -
GAN: latent distribution에서 G를 통해 fake가 나오고 discriminator는 fake/real을 구분하는 분류기를 학습
generator는 discriminator의 입장에서 true가 나오도록 다시 update
GAN Objective
한쪽은 높이고 싶고, 한쪽은 낮추고 싶어하는 minimax game
Discriminator
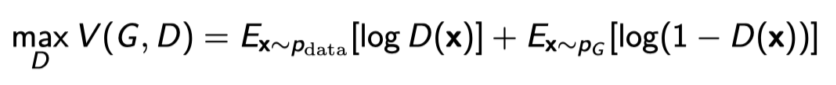
- GAN objective에서 G를 제외하고 D만 본 형태
Optimal Discriminator
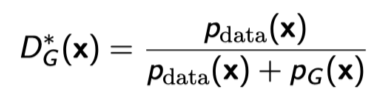
- Generator가 fix돼있을때, generator를 항상 최적으로 분간하는 Optimal Discriminator의 형태
Generator
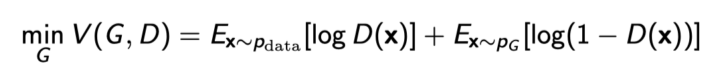
- GAN objective에서 D를 제외하고 G만 본 형태
Optimal Discriminator
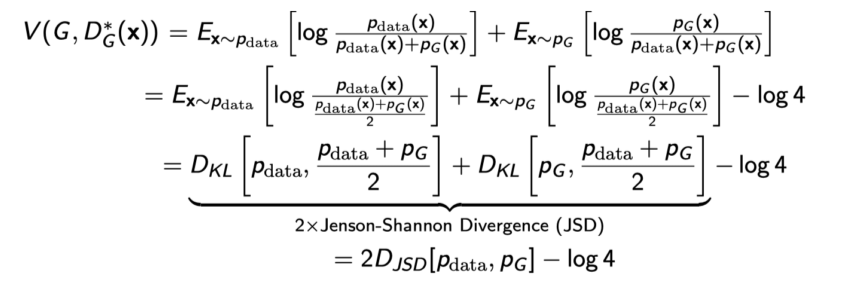
-
GAN의 objective: True data distribution과 내가 학습한 generator 사이의 Jenson-Shannon Divergence를 최소화하는 것
-
하지만 discriminator가 optimal로 수렴한다는 것을 보장하기 어렵기 때문에 현실적으로 Jenson-Shannon Divergence를 저렇게 줄이는 것은 보장하기 어려움
GAN의 종류
DCGAN
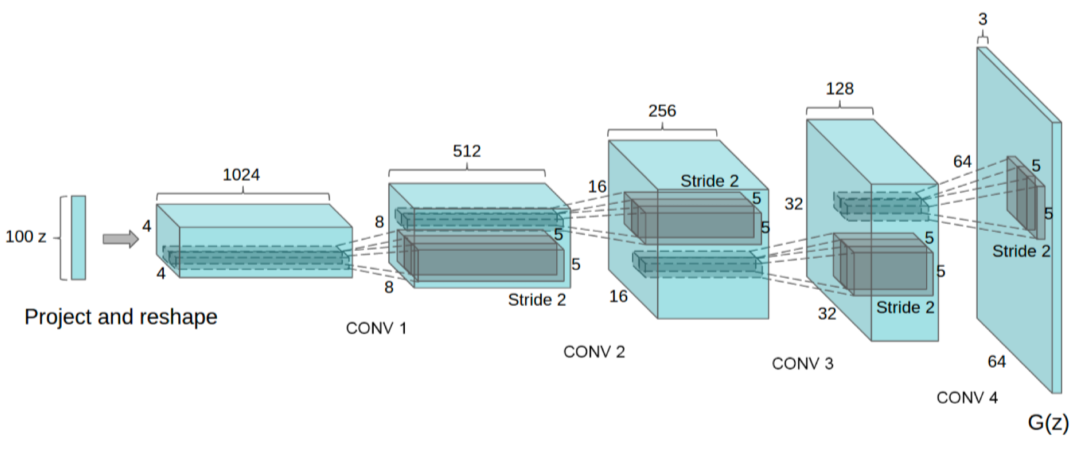
- GAN을 image domain에 적용
- Leaky ReLU를 사용
Info-GAN
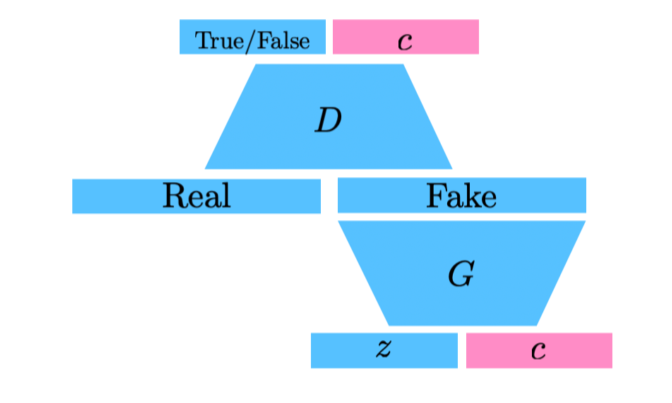
- 학습할 때 라는 auxilary class를 추가해서 generation할때 GAN이 특정 mode(condition vector, one-hot vector)에 집중할 수 있게 만들어줌
Text2Image

- DALL-E가 이 연구를 기반으로 시작
- 문장을 기반으로 image 생성
Puzzle-GAN
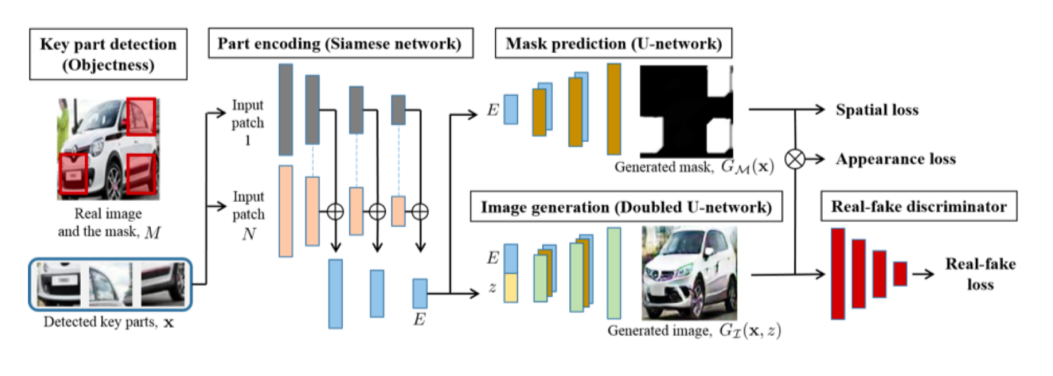
- image의 sub patch로 다시 원래 image를 복원
CycleGAN

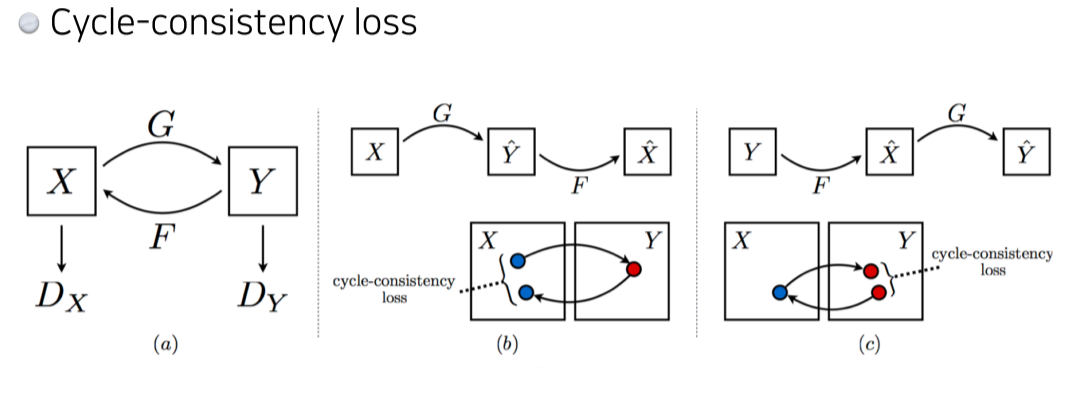
- image의 domain을 바꿔줌
Star-GAN

- 단순히 image의 domain을 바꾸는 것이 아니라 control 할 수 있게 해줌
Progressive-GAN
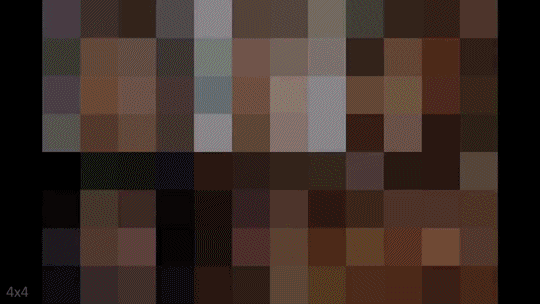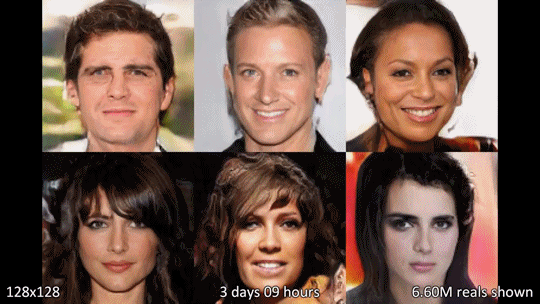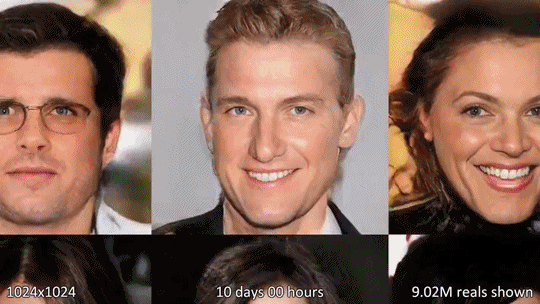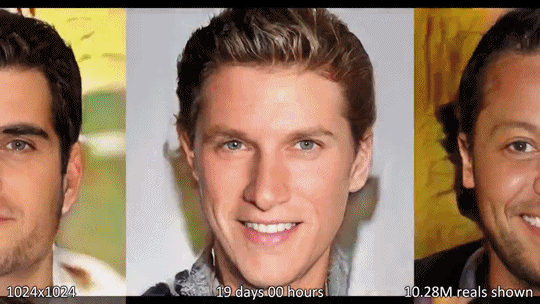
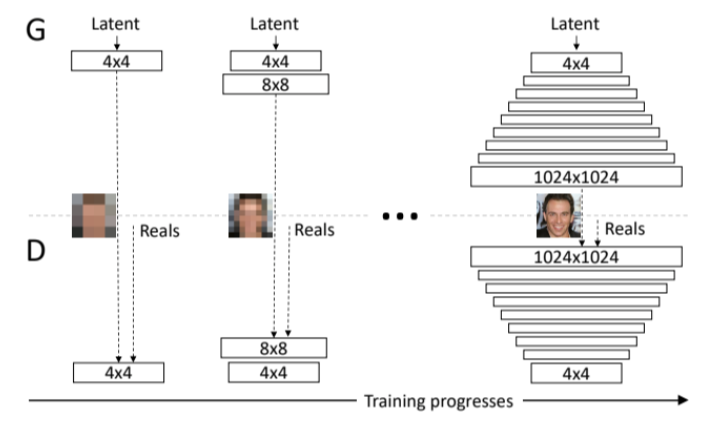
- coarse한 image부터 1024x1024까지 pixel을 키우는 것이 특징(progressive training)
참고하면 좋은 논문
Latent Variable Models
VARIATIONAL INFERENCE & DEEP LEARNING : A NEW SYNTHESIS (2017) Open access.
추가강의
