1. Spark vs Hive
Hive
- spark SQL 이전에 hadoop기반 sql 접근계층
Spark SQL
- Hive와 호환성
- ANSI-sql, HiveQL을 모두 지원하는 자체 SQL Parser포함
- DataFrame과 호환성이 좋다
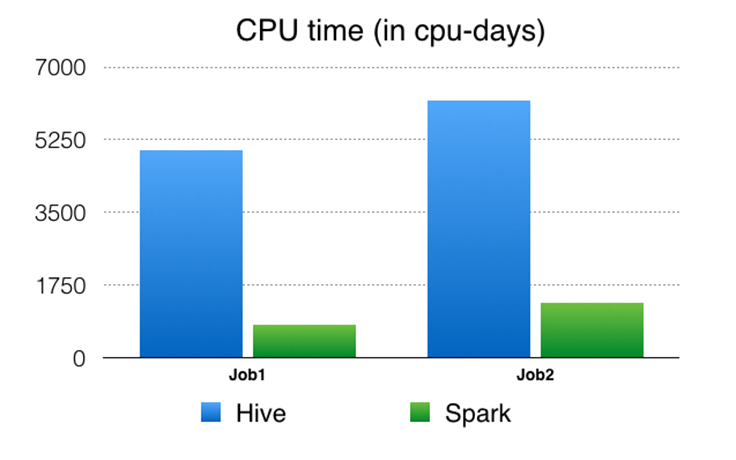
- 성능 개선
- Spark SQL은 온라인 트랜잭션 처리(Online transaction processing, OLTP)oltp를 위한 데이터베이스가 아니라 온라인 분석 처리(Online Analytical Processing, OLAP)olap를 위한 데이터베이스로 작동한다.
- 적은 데이터에서는 오히러 적합하지 않다.
- Hive Metastore를 사용
Spark SQL Thrift JDBC/ODBC 서버
-
Spark는 자바 데이터베이스 연결jdbc 인터페이스를 제공한다.
-
Thrift JDBC/ODBCodbc 서버는 HiveServer2 기반으로 만들어졌다.
-
사용자는 Thrift JDBC/ODBC 서버를 경유해 SQL문을 실행할 수 있다.
- hiveserver2 실행
hive --service hiveserver2- Thrift 서버 실행
$SPARK_HOME/sbin/start-thriftserver.sh- Beeline으로 접속
beeline beeline> !connect jdbc:hive2://localhost:10000
zeppelin과 사용
- 먼저 Thrift JDBC/ODBC 서버에서 connect jdbc:hive2://localhost:10000로 접속 후 zeppelin에서 hive interpreter로 실행해줘야 한다.
- hive interpreter가 없는경우
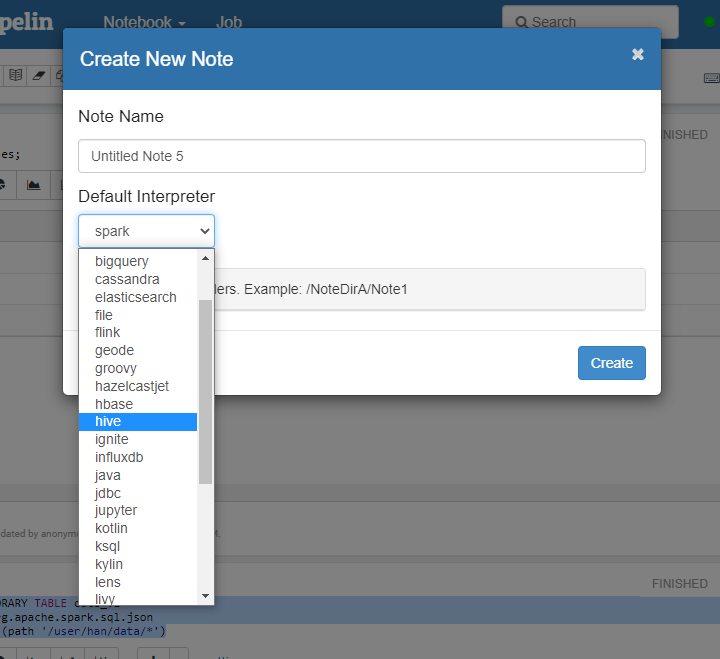
- create 클릭
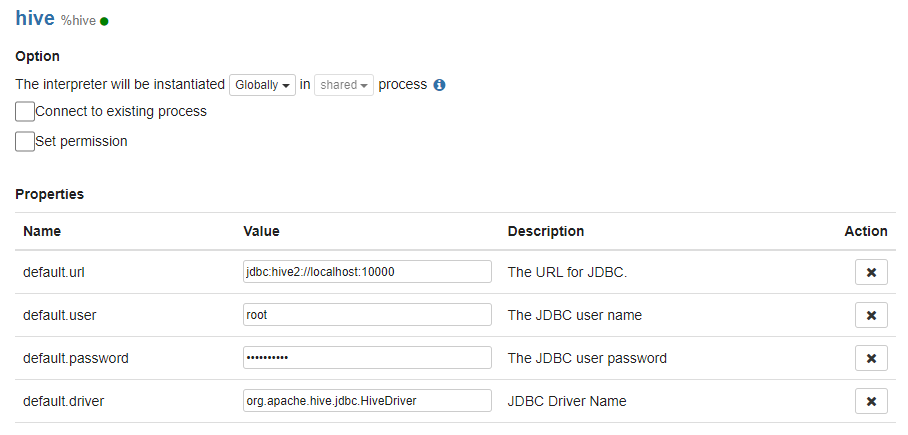
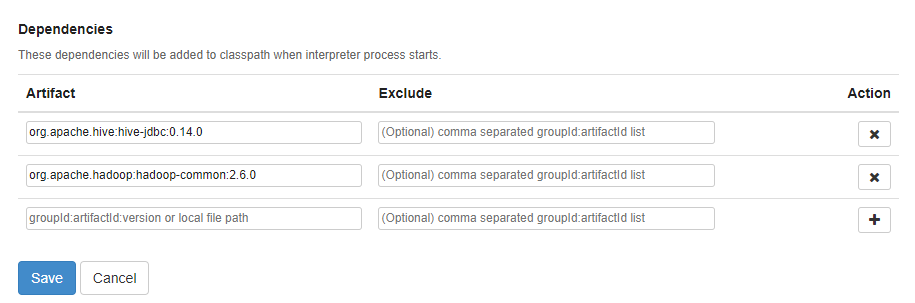
- /opt/zeppelin/interpreter/jdbc 폴더에 hive-jdbc-3.1.2.jar파일 저장
- hive default.driver를 위해
json to table
- 임시테이블
CREATE TEMPORARY TABLE people
USING org.apache.spark.sql.json
OPTIONS (path '[the path to the JSON dataset]')- 테이블
CREATE TABLE cate
USING org.apache.spark.sql.json
OPTIONS (path '/user/han/data/*')Reference
https://databricks.com/blog/2015/02/02/an-introduction-to-json-support-in-spark-sql.html

Data Analytics Engineer