COCO-LM : Correcting and Contrasting Text Sequences for Language Model Pretraining
NLP Papers
목록 보기
1/33
ELECTRA
- ICLR 2020 (google research)
- Efficiently Learning an Encoder that Classifies Token Replacements Accurately.
- MLM (Masked Language Model, bidirectional representations)
- 15% 마스킹, 복원하는 task (substantial compute cost)
- 실제 task에서 마스킹을 사용하지 않음
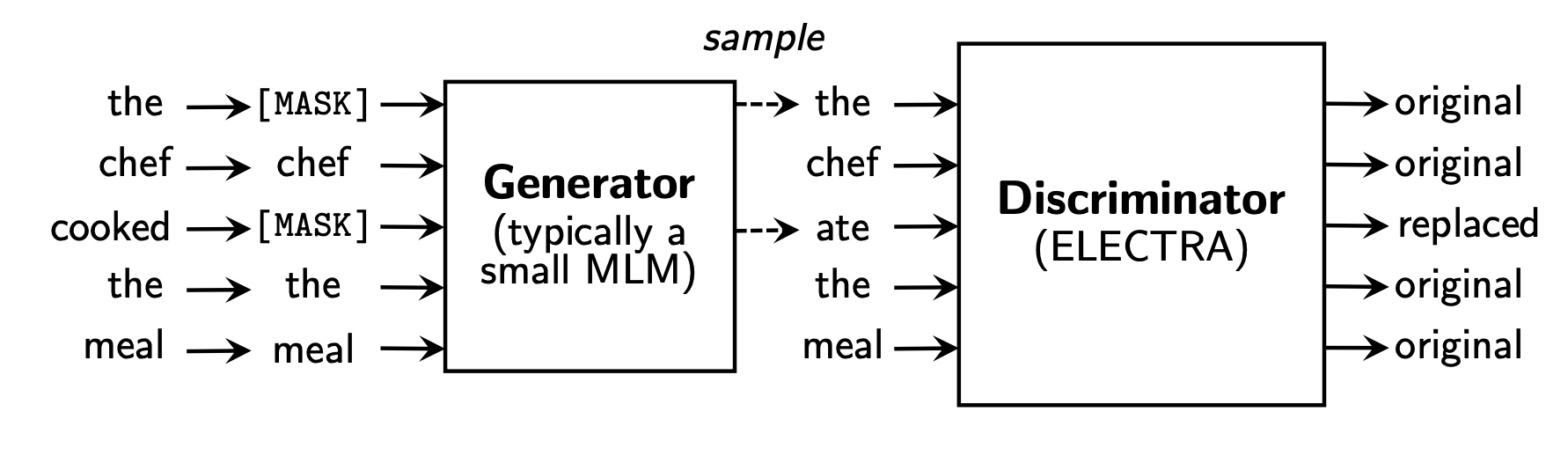
- Small generator (generator 너무 강력하지 않도록 해야 discriminator가 의도대로 학습된다.)
- Replaced Token Detection (RTD)
- Discriminator가 artifical MASK token을 보지 않도록 만들었음.
- Learning from all input positions causes ELECTRA to train much faster than BERT
- MASK만 보면서 정답을 맞추는 것이 아니라 모든 토큰을 보면서 original/replaced를 확인함 (computationally efficient)
- Jointly training, generator는 버리고 discriminator만으로 downstream task를 수행한다.
- Efficiency (왜 효율적인 것이지? 15% vs 100%)
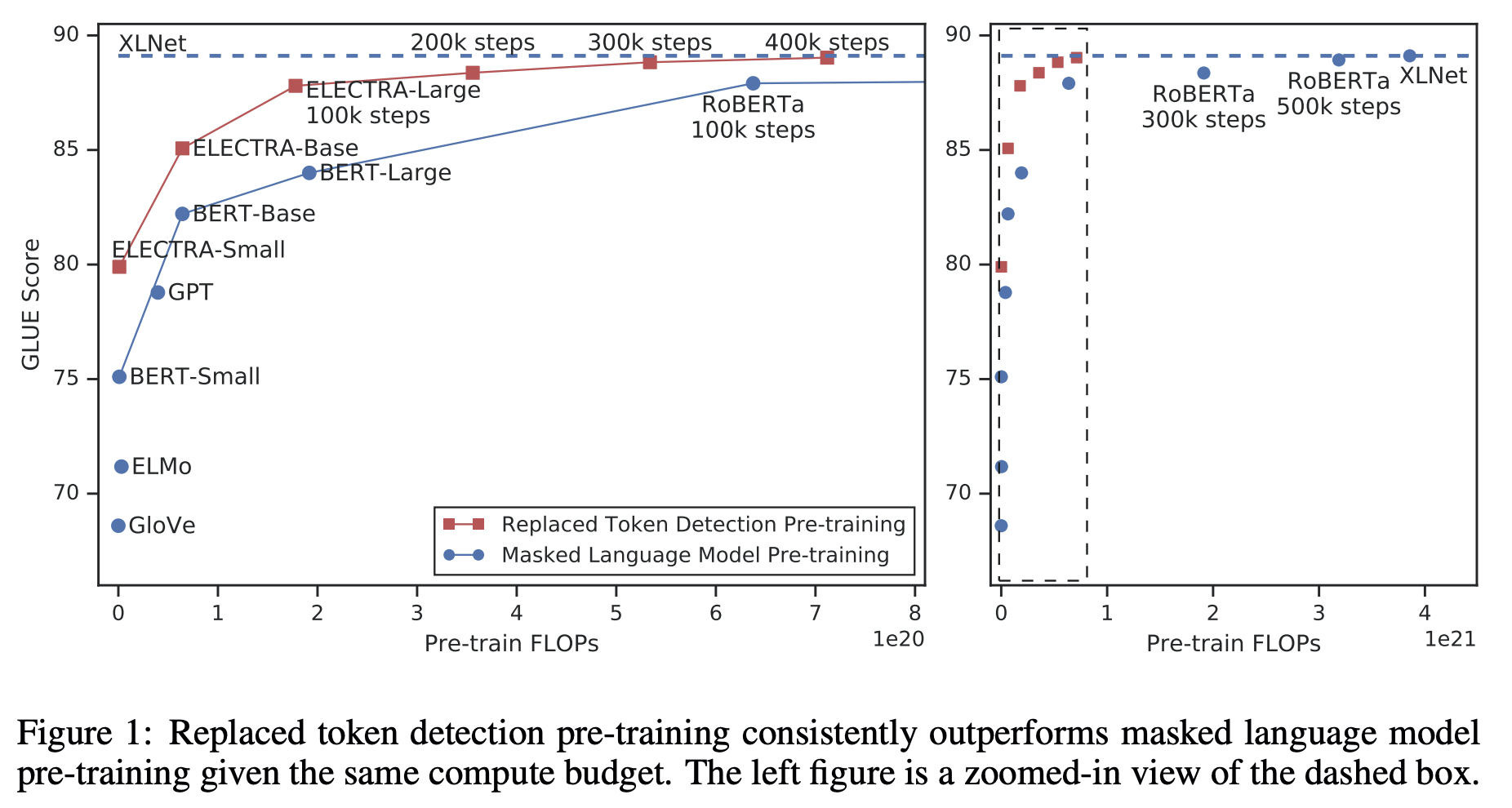

- ELECTRA 15% : discriminator loss를 15%의 token만으로 계산하도록 하였음.
COrrecting and COntrasting corrupted text sequences
ELECTRA
- Missing Language Modeling Benefits.
- language modeling capability
- not be sufficient to capture certain word-level semantics (the binary classification task)
- few-shot 같은 것들을 하기에 적합하지 않다.
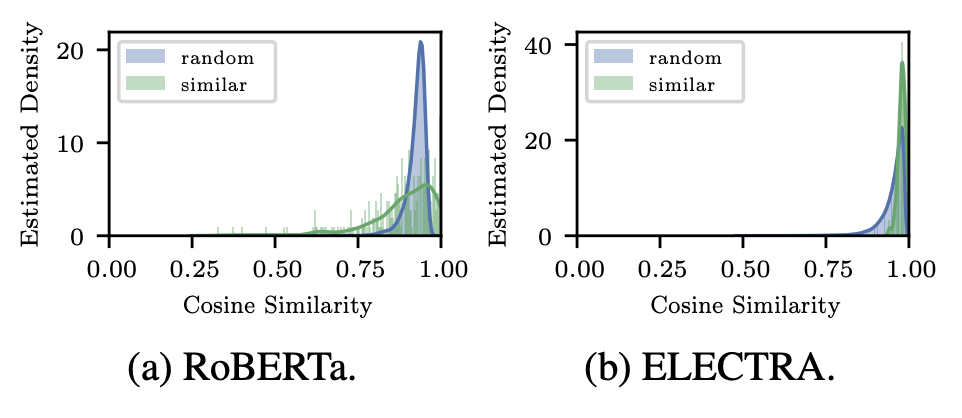
- Squeezing Representation Space.
COCO-LM
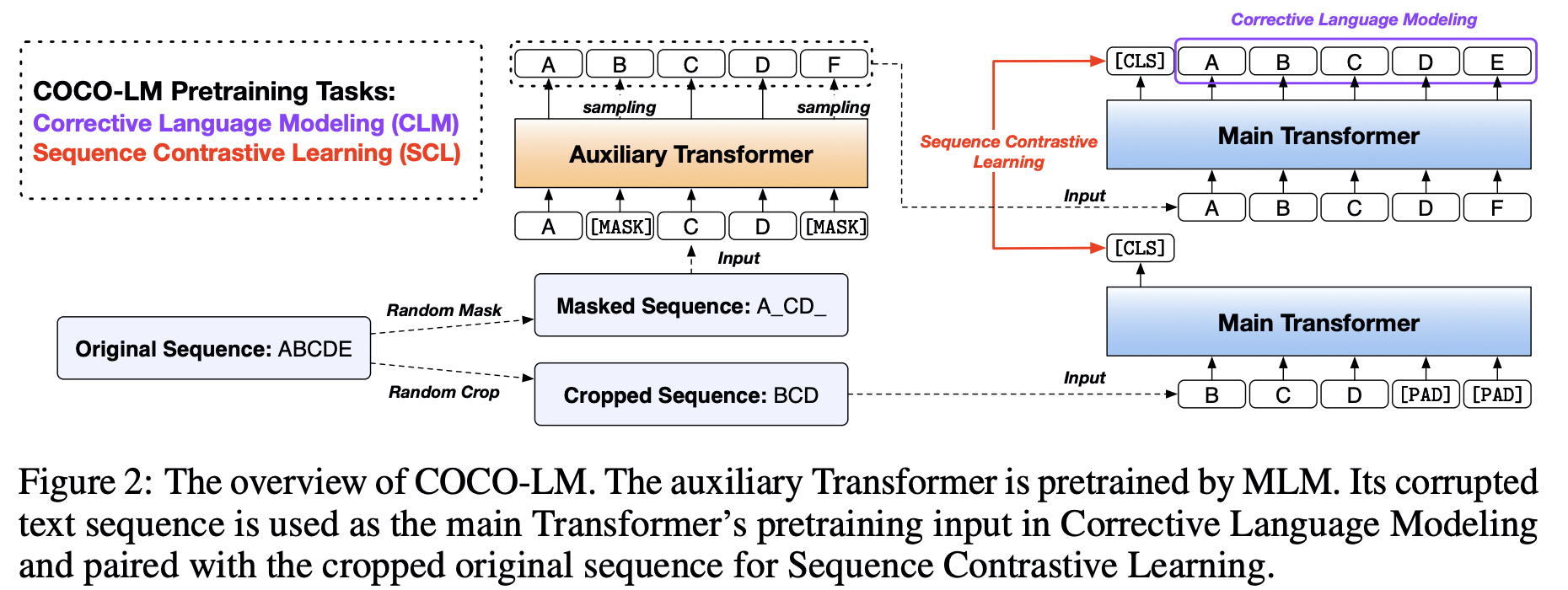
- Corrective Language Modeling (token-level task)
- CLM : a multi-task setup
- a language modeling layer(All-Token MLM) and a binary classification layer(copied or not, similar to RTD)
- The main Transformer first learns the easier classification task and then uses it to help learn the harder LM task.
- The binary classification task is trained on all tokens while the language modeling task is trained only on masked positions.
- a language modeling layer(All-Token MLM) and a binary classification layer(copied or not, similar to RTD)
- CLM : a multi-task setup
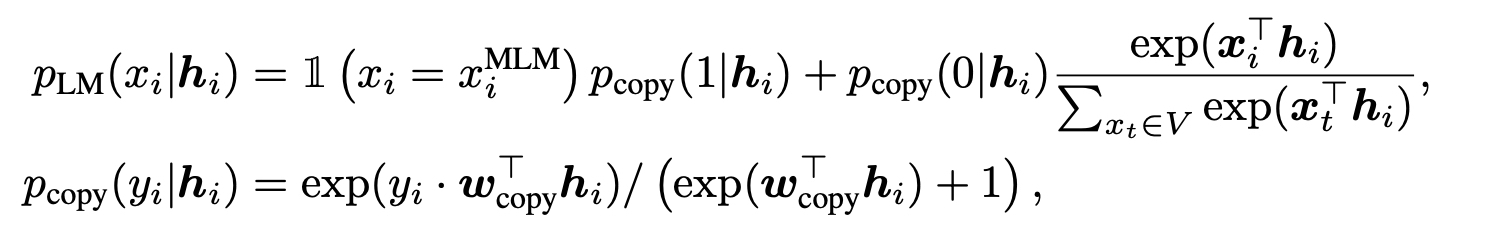
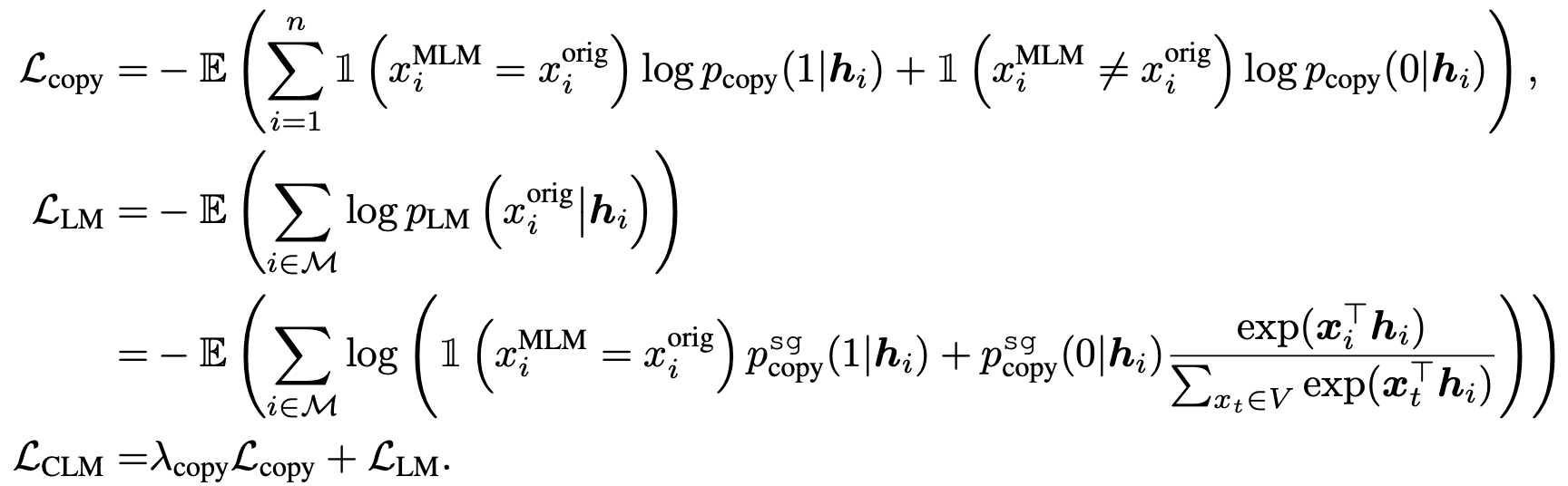
- Sequence Contrastive Learning (sequence-level task)
- a contrastive learning objective (robust representations)
- different view (data augmentations)
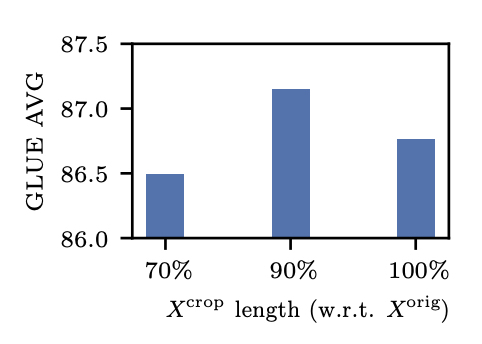
- 90% of original input length : the major sequence meaning is preserved
Auxiliary Transformer
- Small aux transformer : layer는 줄이지만, hidden dimension은 줄이지 않았음
- Main transformer input값을 만들 때에는 dropout을 사용하지 않음.
Experiments
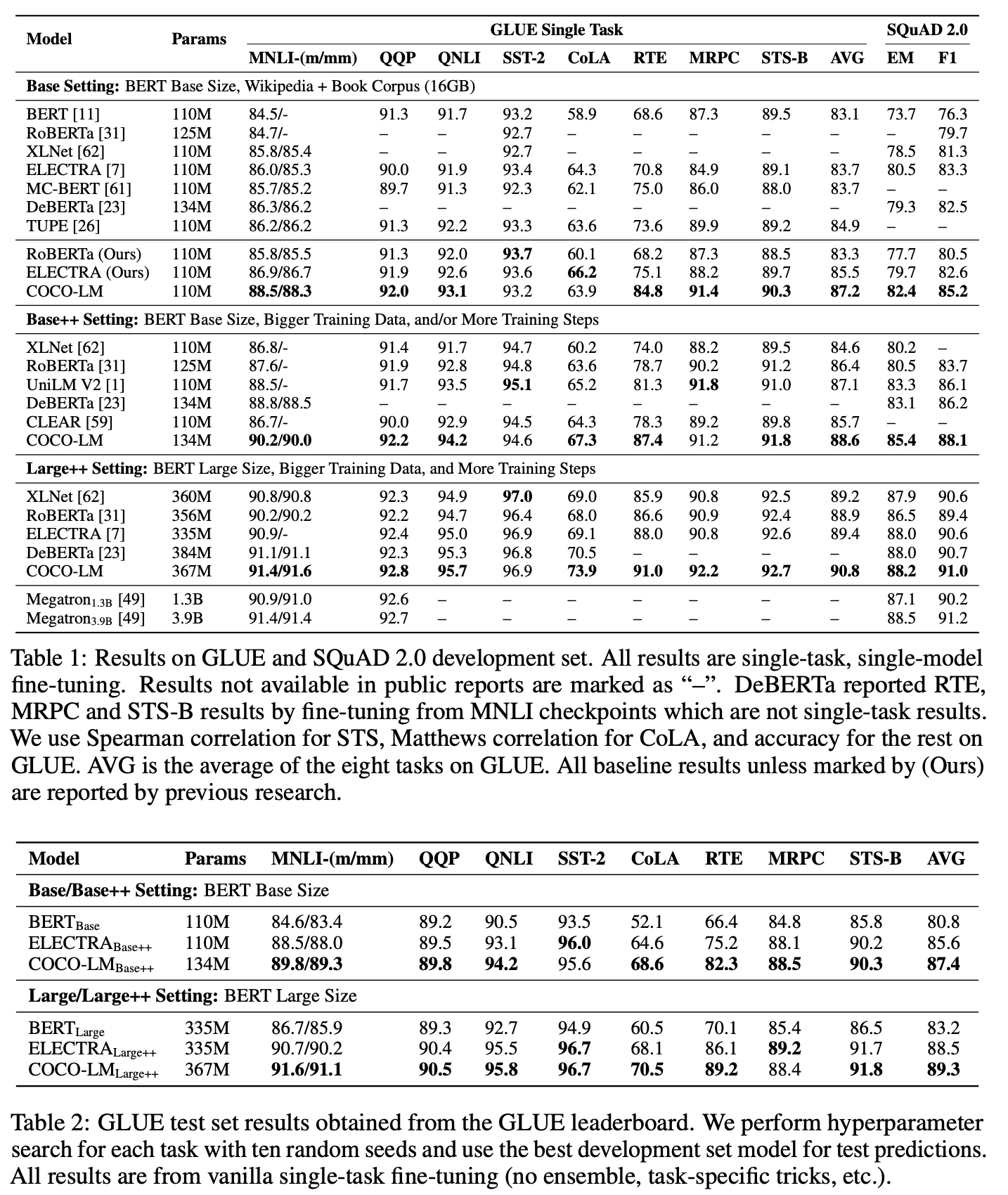
base
- Wikipedia and BookCorpus (16GB)
- 32, 768 uncased BPE vocabulary (TUPE)
base++
- OpenWebText, CC-News, and STORIES (160GB)
- 64, 000 cased BPE vocabulary
aux transformer
- 4-layer transformer in base/base++
- 6-layer in large++
Analysis
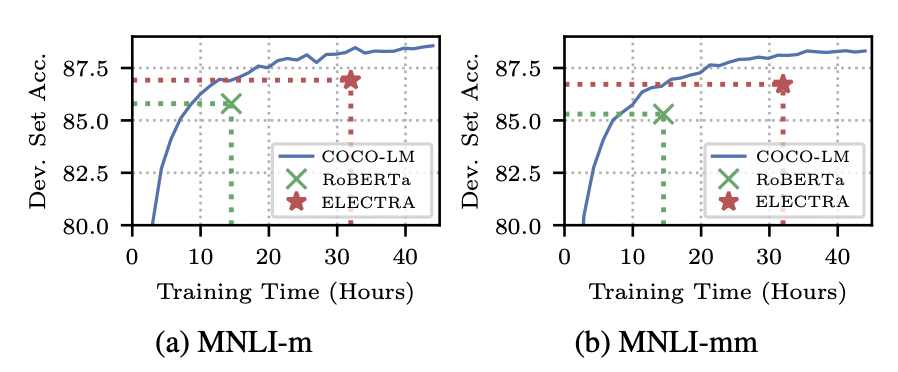
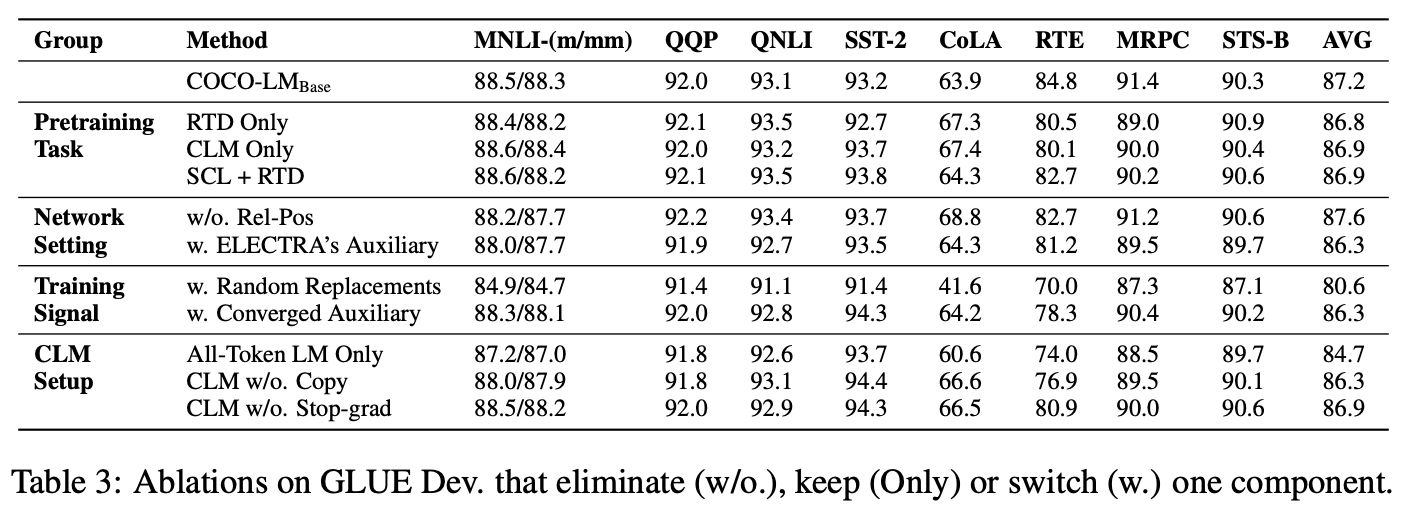
- Pretraining task
- SCL only?
- RTD only, CLM only 비교했을 때에는 거의 미세한 차이만 있었으나, SCL+RTD < COCO-LM (SCL+CLM)
- Network setting
- Rel-Pos 가 MNLI를 제외한 다른 task에서 높은 성능을 보이기도함.
- ELECTRA's aux : 12 layer, 256 hidden
- Training signal
- aux transformer 사용하지 않고, random replacements 사용하여 main transformer를 학습하고자 함.
- converged aux < pretrain two transformers together
- the auxiliary model gradually increases the difficulty of the corrupted sequences
- CLM setup
- CLM을 아예 사용하지 않고, LM으로만 진행하였을 때 성능이 상당히 낮아졌다. (SCL + LM)
- Correct corrputed text, binary classification을 제거한 경우
- Correct corrputed text, binary classification(같이 쓰이는 stop gradient를 사용하지 않았을 경우)
SCL
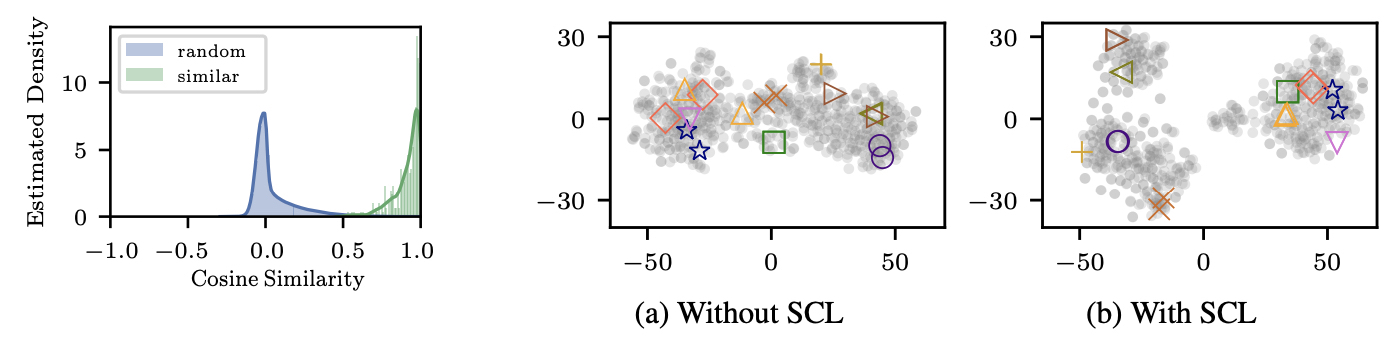
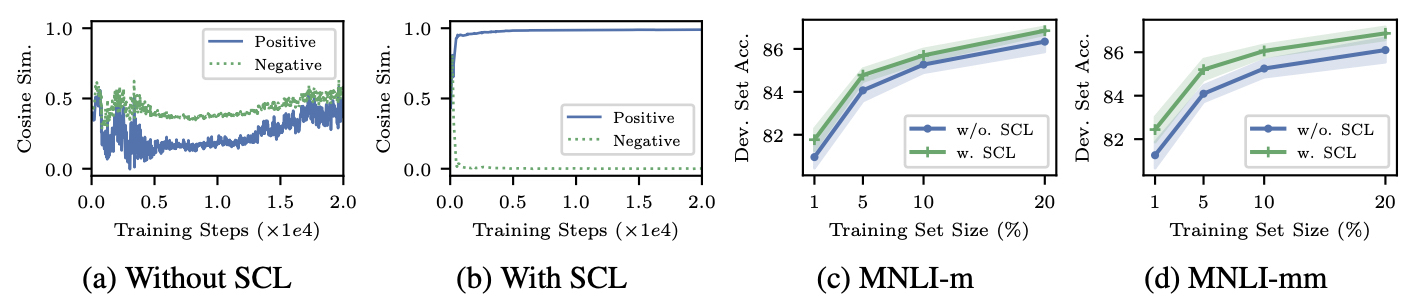
CLM
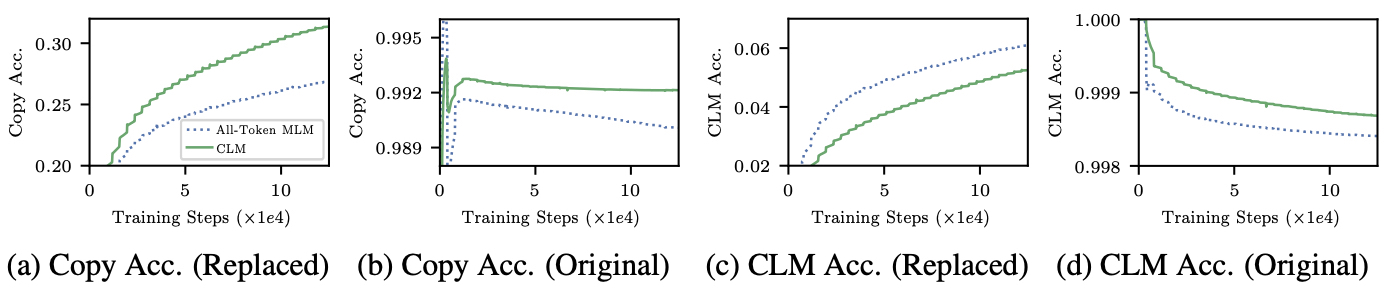
-
Original : 안바뀐 친구를 안바뀌었다고 찾아주는 것.
-
Replaced (7-8%) : 이상한 것을 발견하고(Copy acc), 제대로 바뀌게해줘야한다 (CLM acc)
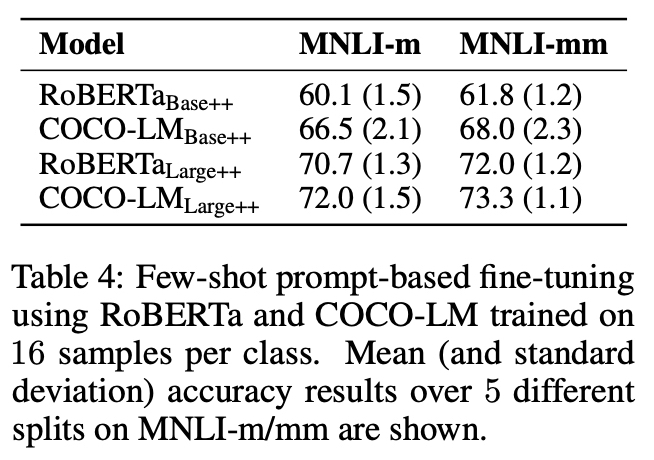
-
ELECTRA는 language modeling task로 학습된 것이 아니기 때문에 prompt label word 생성이 어렵다.
(작성중...)

산미 있는 커피를 좋아하는 자연어처리 엔지니어. 일상 속에서 요가와 따릉이
를 좋아합니다. 인간의 언어를 이해하고 생성하는 AI 기술 발전을 위해 노력하고 있습니다. 🧘♀️🚲☕️💻