NLP Papers
1.COCO-LM : Correcting and Contrasting Text Sequences for Language Model Pretraining
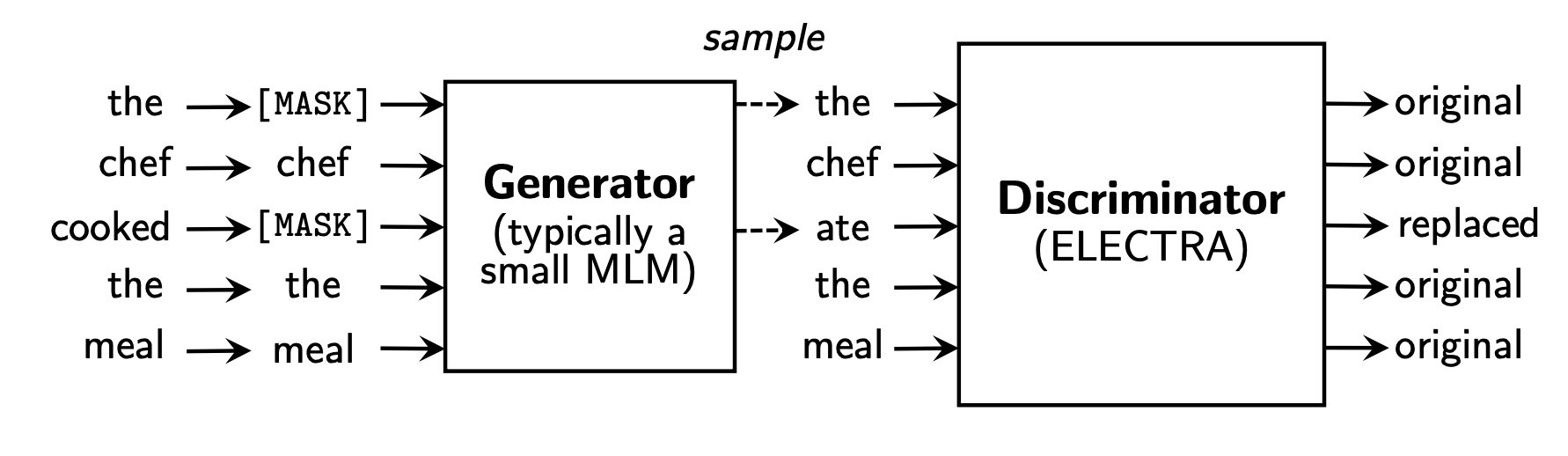
ELECTRA ICLR 2020 (google research) Efficiently Learning an Encoder that Classifies Token Replacements Accurately. MLM (Masked Language Model, bidire
2.HETFORMER: Heterogeneous Transformer with Sparse Attention for Long-Text Extractive Summarization

Abstract 요약 테스크에 대한 논문 의미 그래프를 담기 위해서 GNN을 주로 사용했음 긴 텍스트에서 사용하기 위한 좀 더 효율적인 모델 적은 메모리와 파라미터로 Rouge, F1 좋은 점수를 냈다. HETFORMER on Summarization 토큰, 문장,
3.NORMFORMER

Under review at ICLR 2022, Facebook AI Research
4.MPNet: Masked and Permuted Pre-training for Language Understanding
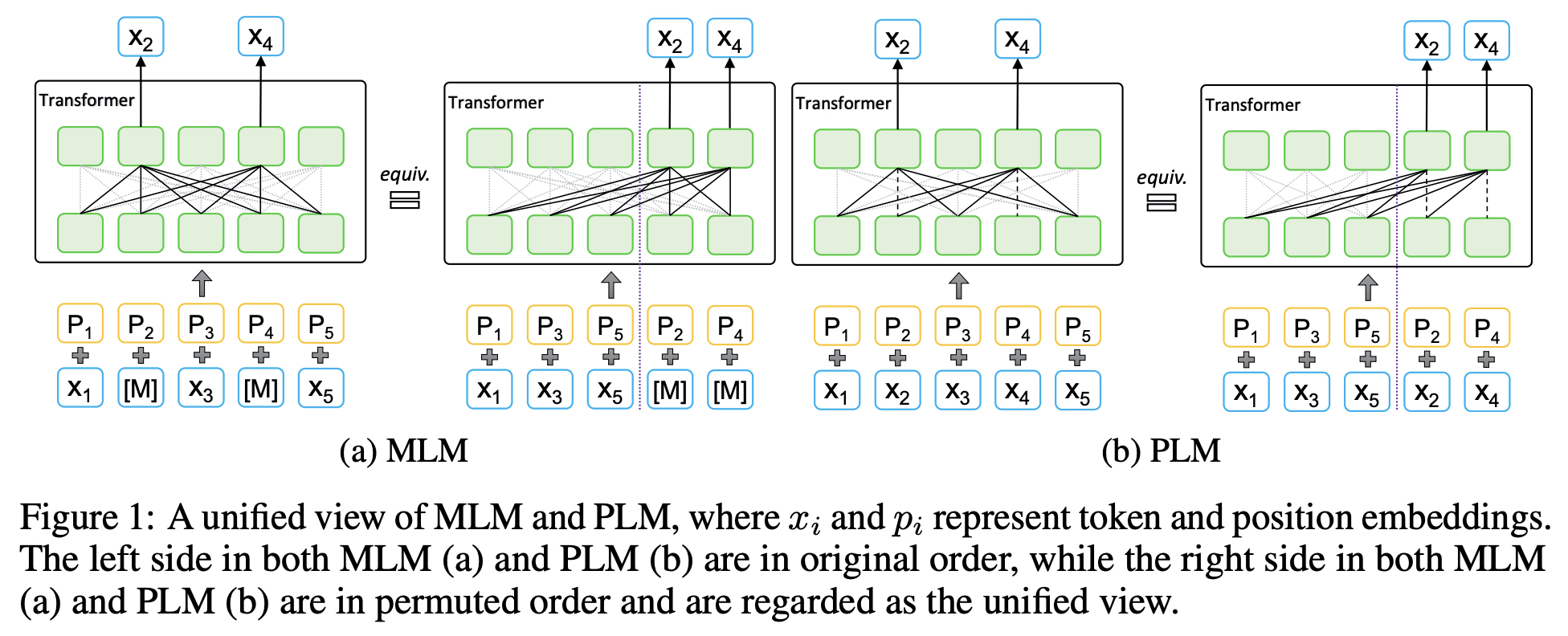
MPNet은 BERT와 XLNet의 장점을 취하고 한계를 보완하는 방식의 pretraining 기법을 제안한다.
5.TABLEFORMER: Robust Transformer Modeling for Table-Text Encoding
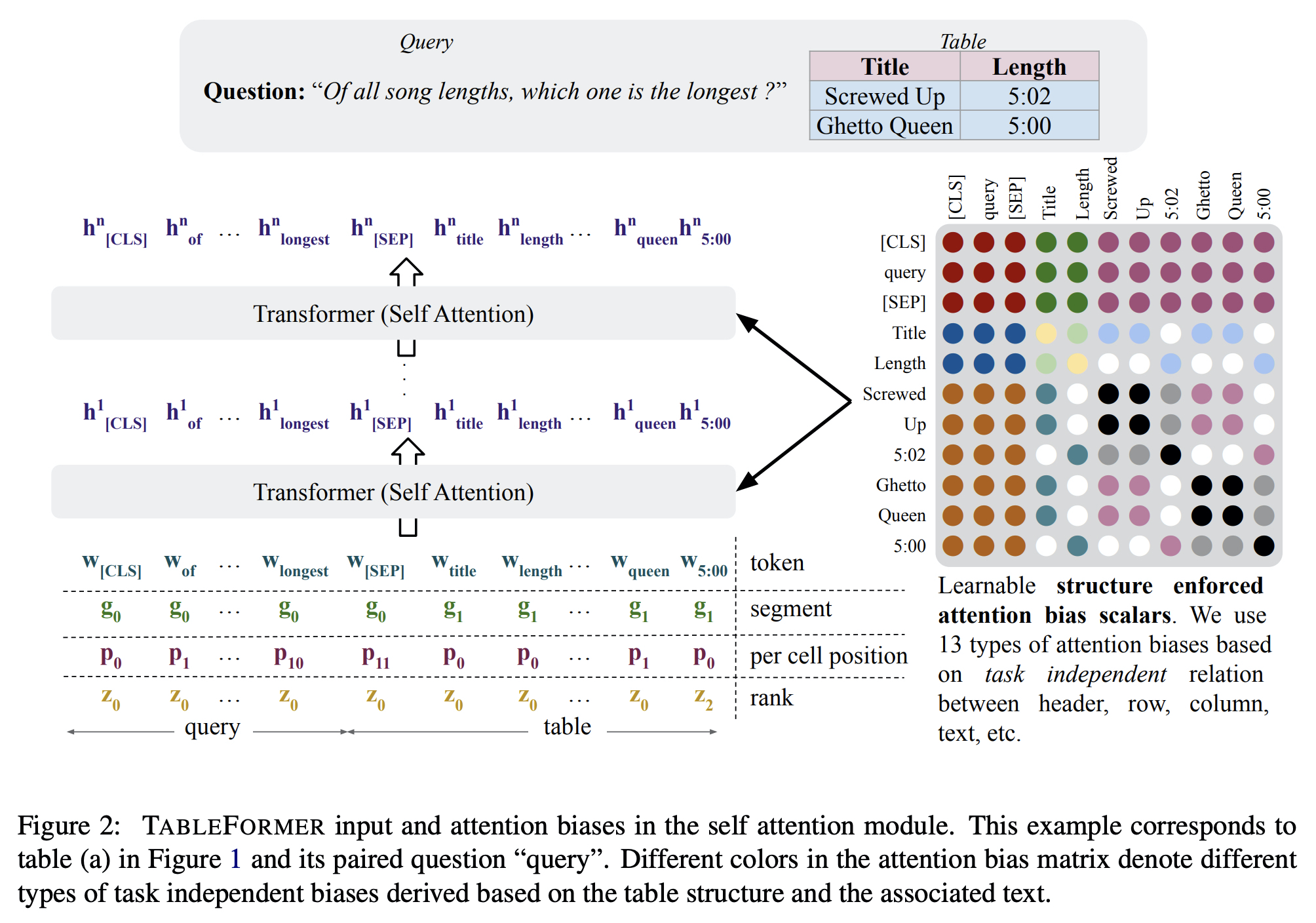
TAPAS 다음으로 나온 논문 (ACL 2022)으로 테이블 구조를 이해하는 언어모델이다.
6.Contextual Representation Learning beyond Masked Language Modeling
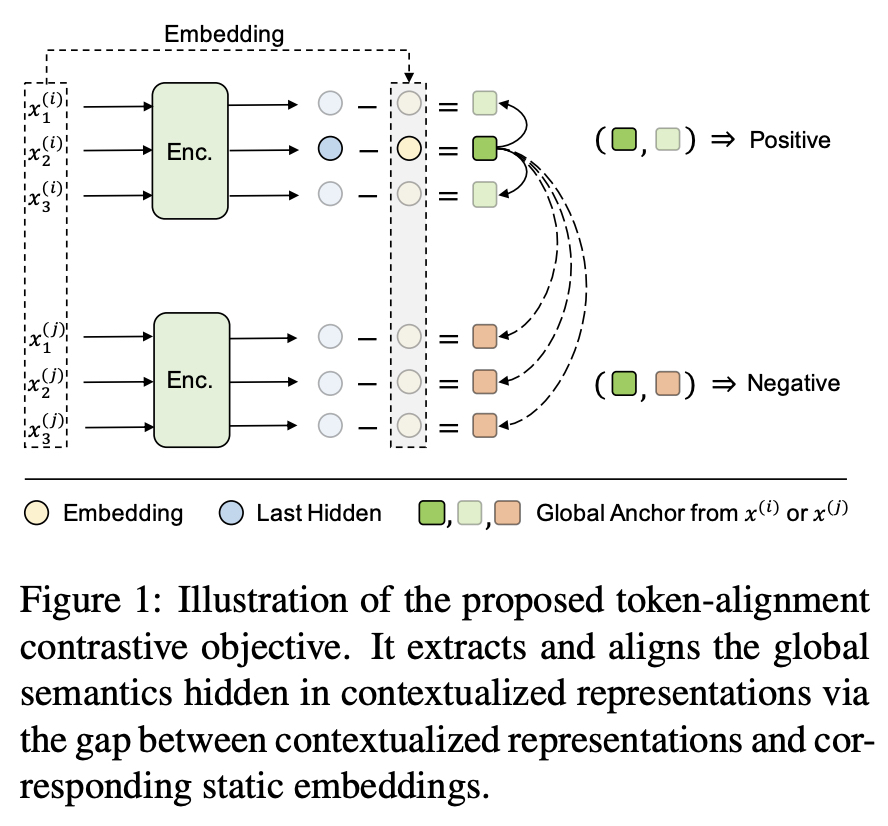
In-batch negative를 MLM에 적용시킨 논문
7.ClusterFormer: Neural Clustering Attention
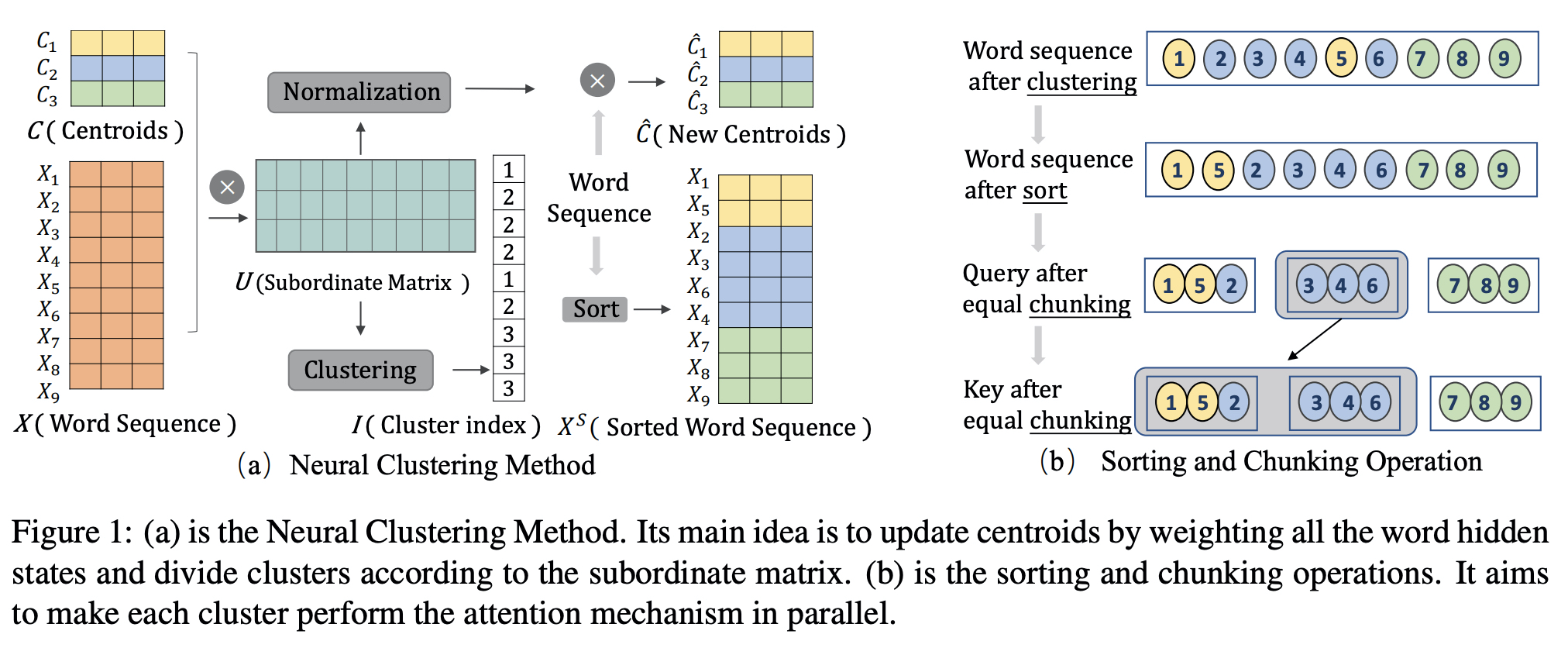
단어 유사도를 이용해서 sparse transformer 만들어낸 논문
8.XLM-E: Cross-lingual Language Model Pre-training via ELECTRA
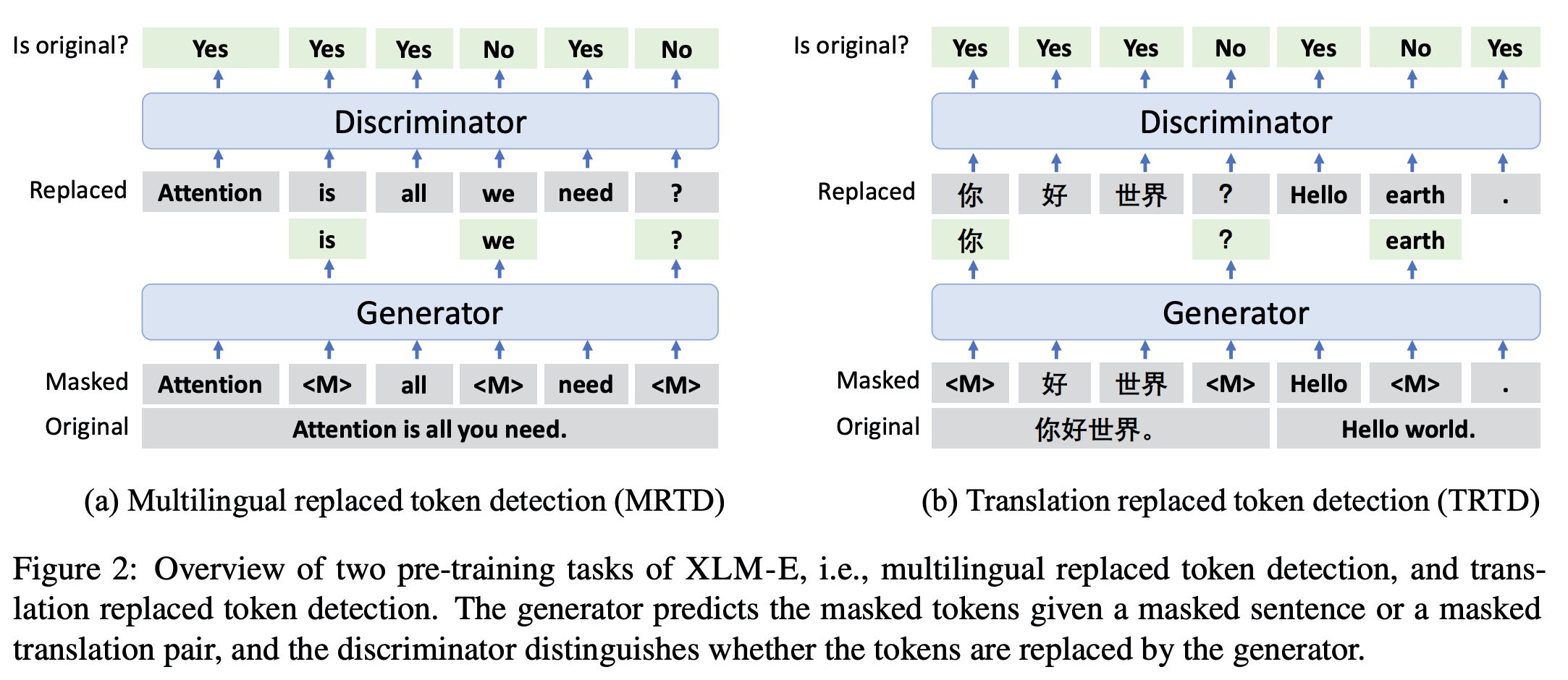
MRTD(multi-lingual replaced token detection), TRTD(translation replaced token detection) 두 가지 loss 사용해서 ELECTRA multilingual 모델을 만들었다
10.Funnel-Transformer : Filtering out Sequential Redundancy for Efficient Language Processing
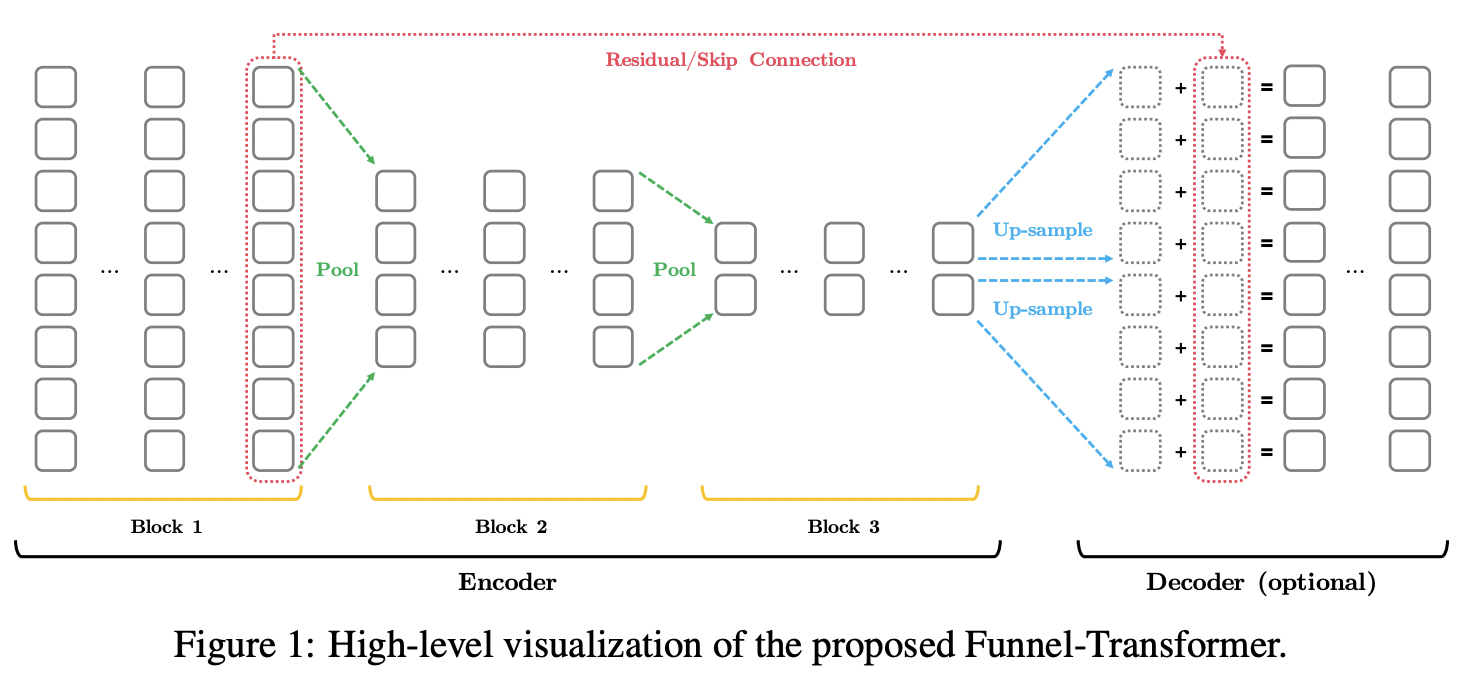
NeurIPS 2020, CMU와 구글 브레인에서 나온 논문 Hourglass (Hierarchical Transformers Are More Efficient Language Models) 모델을 보다보니, 이 논문을 짚고 넘어가야할 것 같아서 보게 되었음. 이 논문에서는 한 문장을 그 문장을 구성하는 전체 토큰 길이의 벡터로 표현한다는 것이 중복 문제...
11.ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
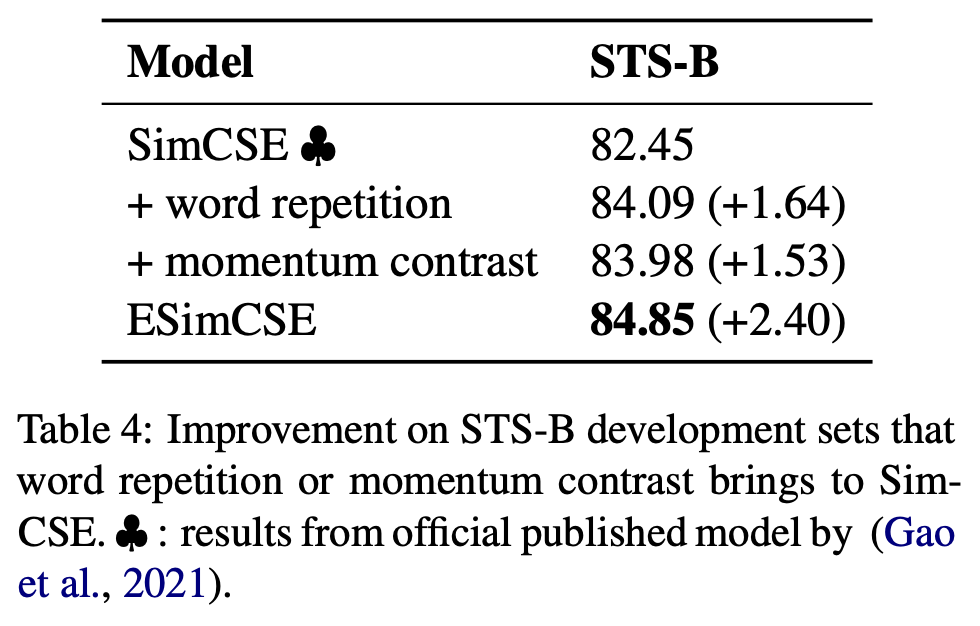
Sentence embedding, STS task에서 현재 기준 SOTA 수준에 있는 연구 중 하나인 ESimCSE 페이퍼에 대한 설명
12.PCL: Peer-Contrastive Learning with Diverse Augmentations for Unsupervised Sentence Embeddings
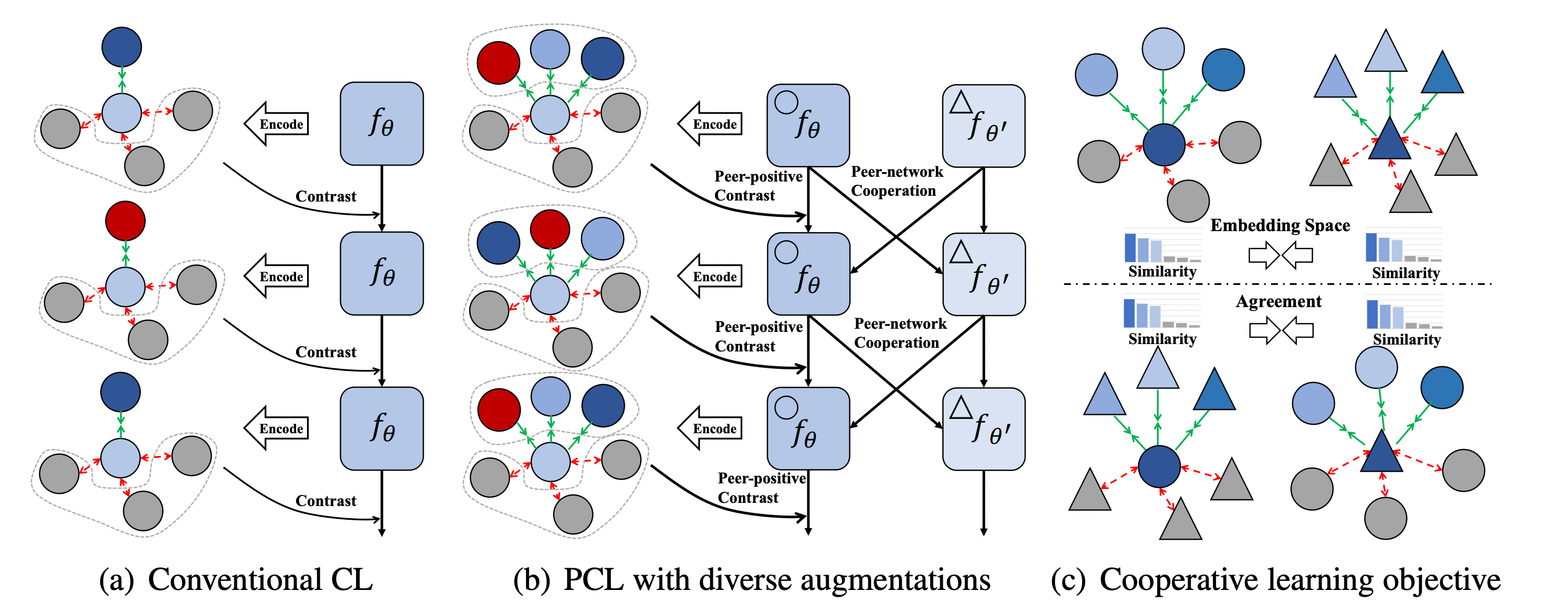
Sentence similarity task에서 가장 높은 점수를 기록한 모델이다. (EMNLP 2022 main)
13.RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
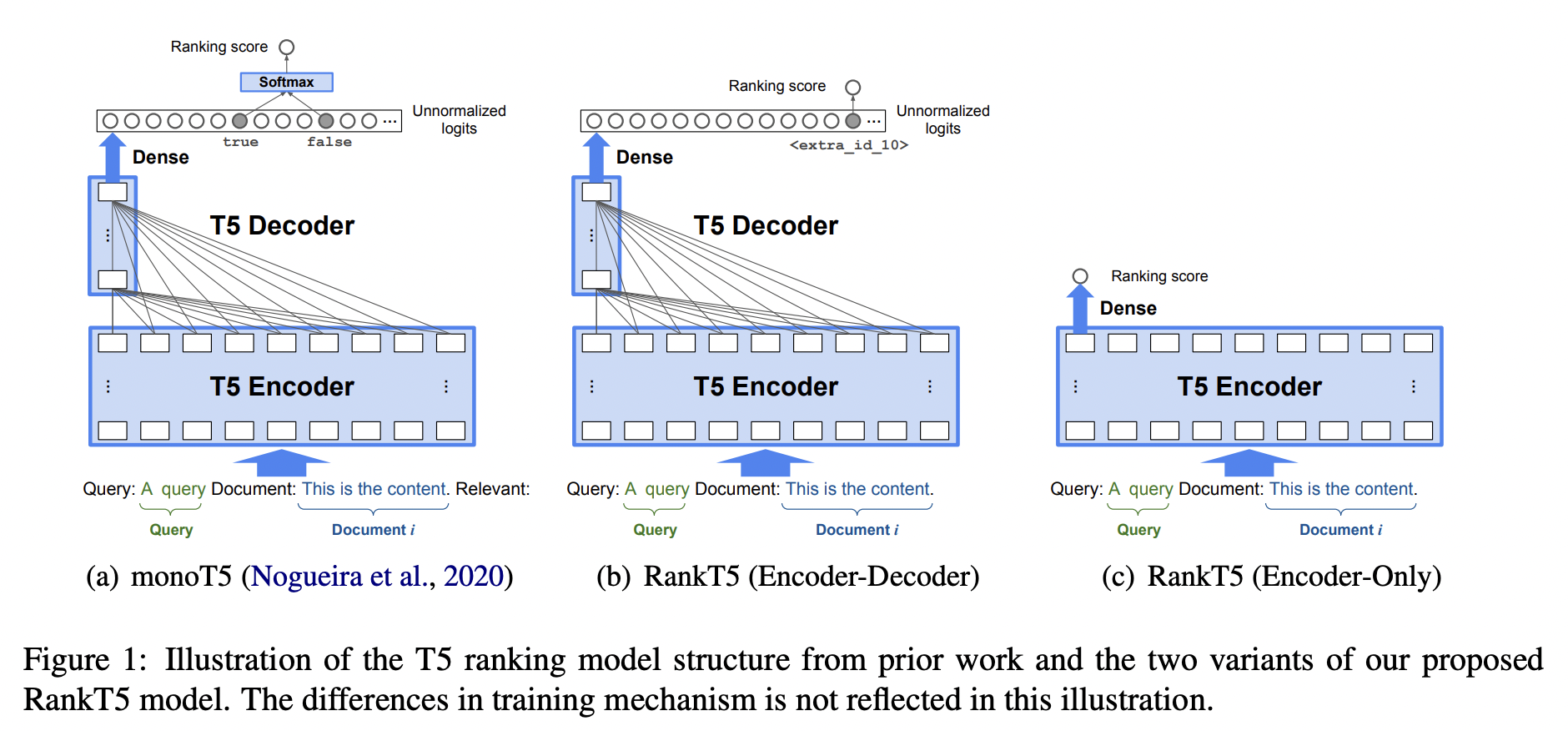
Rerank 관련, google 에서 공개한 논문이다.
14.Query2doc: Query Expansion with Large Language Models

Query expansion을 비교적 간단한 방식으로 진행하여 MS-MARCO, TREC DL에서의 점수를 올렸다. 이 페이퍼에서 제시한 방법의 결과인 데이터는 아래에 공개되었다. https://huggingface.co/datasets/intfloat/que
15.Precise Zero-Shot Dense Retrieval without Relevance Labels
데이터가 없을 때 어떻게 dense retrieval을 하기 위한 방법을 고민한 논문이다. 데이터가 없는 상황에서는 필요한 데이터를 먼저 마련해야한다.
16.Large Dual Encoders Are Generalizable Retrievers
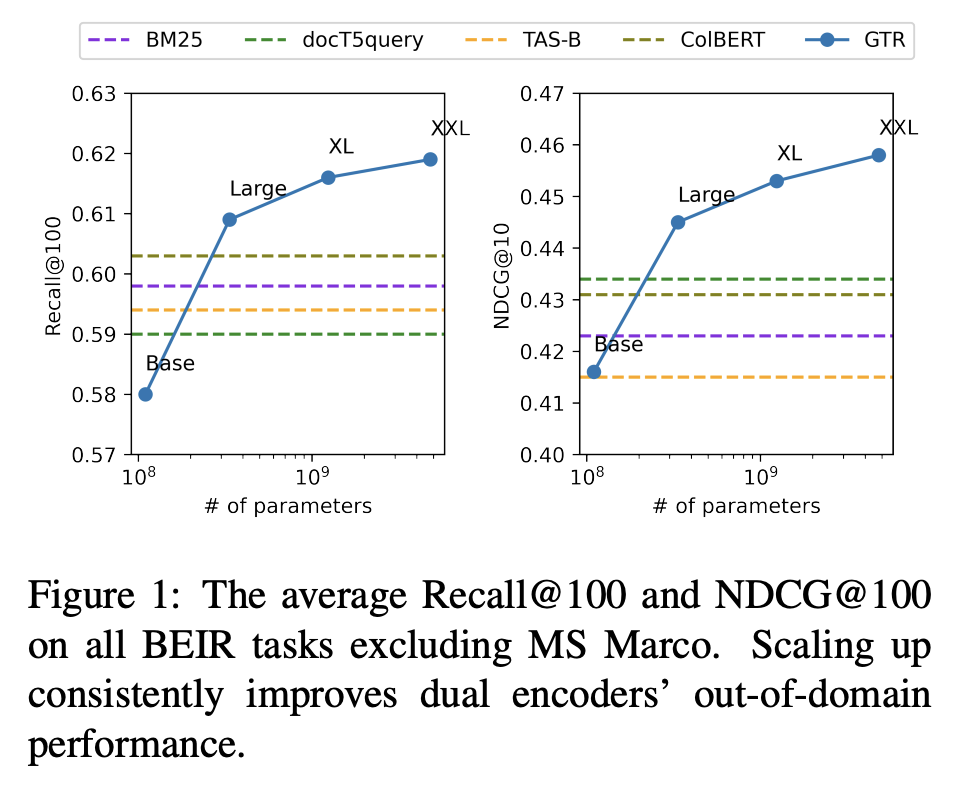
google research 모델. t5x_retrieval 깃헙에 소스와 함께 공개되었다.
17.Self-attention Does Not Need O(n^2) Memory
Google research. (들어가는 질문) Self-attention의 시간과 공간복잡도는? Self-attention의 시간과 공간복잡도가 그렇게 되는 이유는? 점수 차가 거의 없는 것을 확인할 수 있다. (질문) 아래 두 수식이 사실상 같은가? We initialize the vector $v∗$ ∈ $R^d$ and sca
18.Zero-Shot & Few-Shot Open-Domain QA
LLM에서 검색 모듈 없이 Open domain QA 진행하는 두 가지 연구를 소개한다.
19.Visual Instruction Tuning
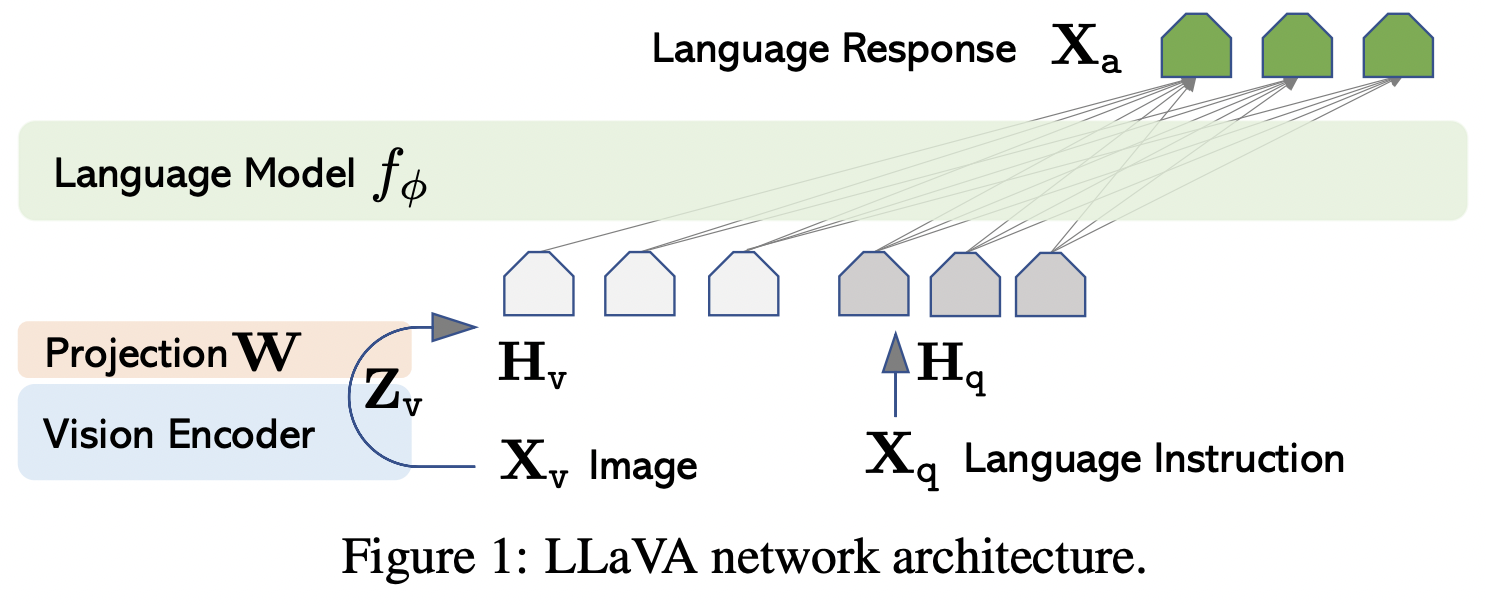
NIPS 2023 main에 올라간 페이퍼로, LLM을 이용해 language 이해를 넘어 language-vision 동시에 같이 이해하는 GPT-like 멀티모달 LLaVA를 만들었다.
20.DOLA: DECODING BY CONTRASTING LAYERS IMPROVES FACTUALITY IN LARGE LANGUAGE MODELS
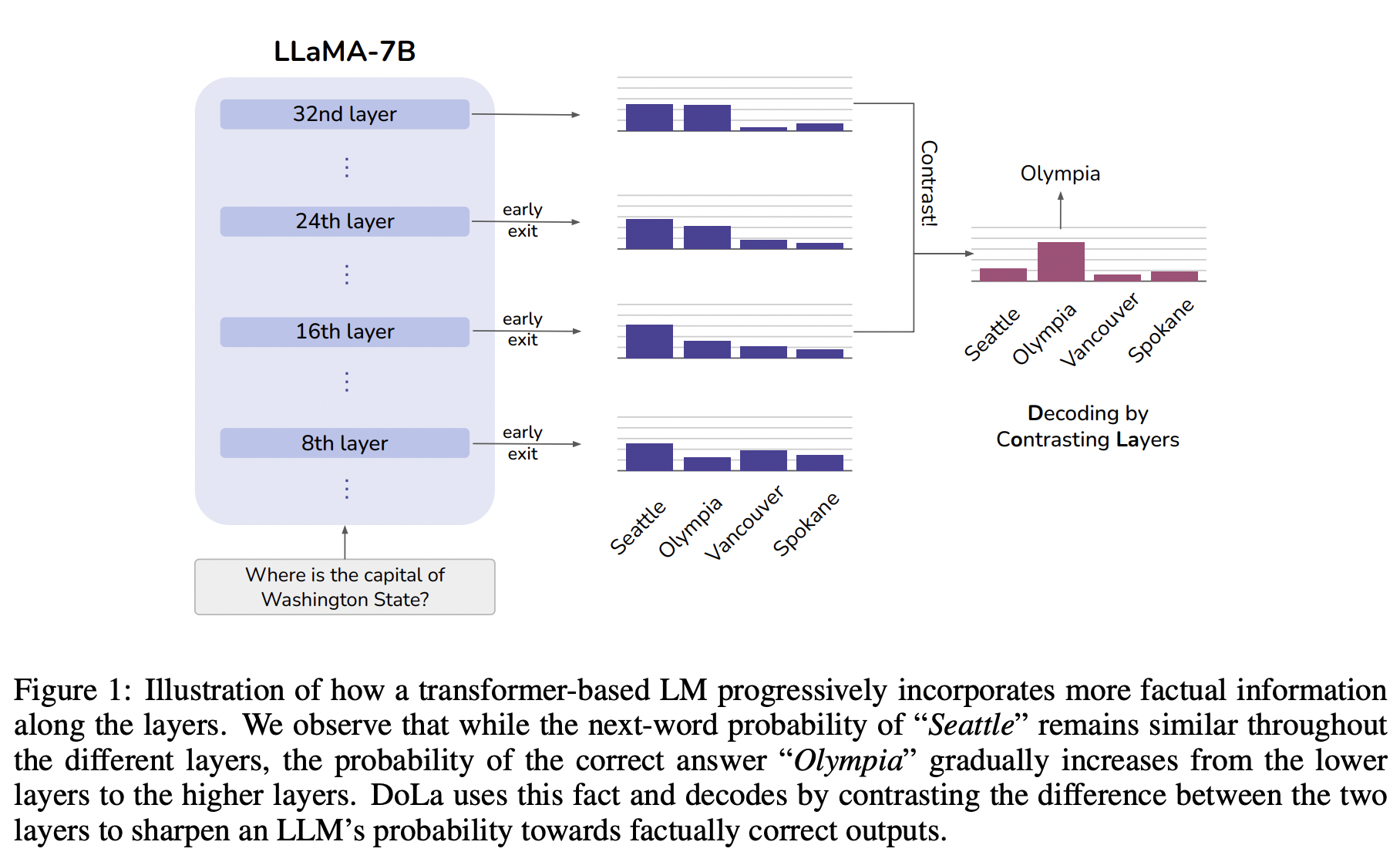
Contrastive decoding 이전 연구(Contrastive Decoding: Open-ended Text Generation as Optimization)에서 디코딩 과정에서 ExpertLM에 더해서 작은 모델인 Amateur LM을 같이 사용함으로써 hallucination을 줄일 수 있는 방법에 대해서 제시한다. 그림에서 볼 수 있듯이 로...
21.FunSearch: Making new discoveries in mathematical sciences using Large Language Models
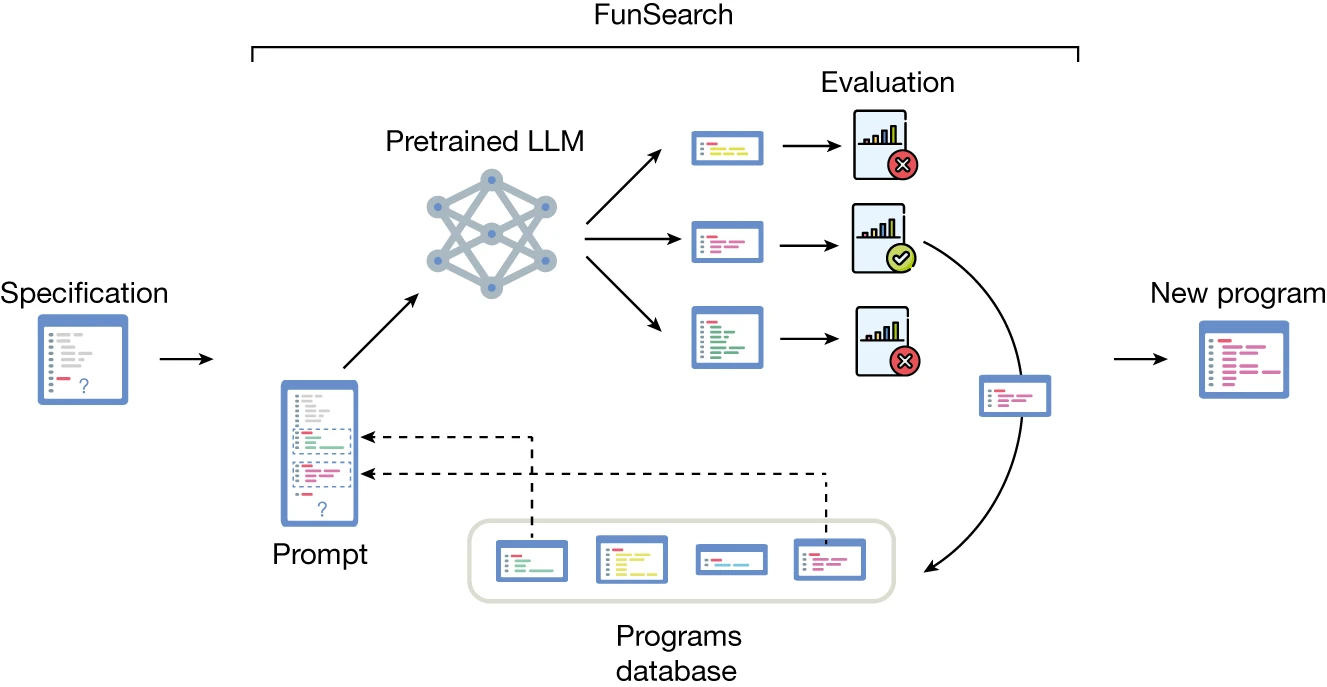
FunSearch는 2023년 12월 말에 나온 Deepmind 논문으로 Nature에 실렸다고 한다. Open problem에 대해서 기존에 인간이 풀었던 방식 이외로의 해결방식을 제시했다.
22.Corrective Retrieval Augmented Generation
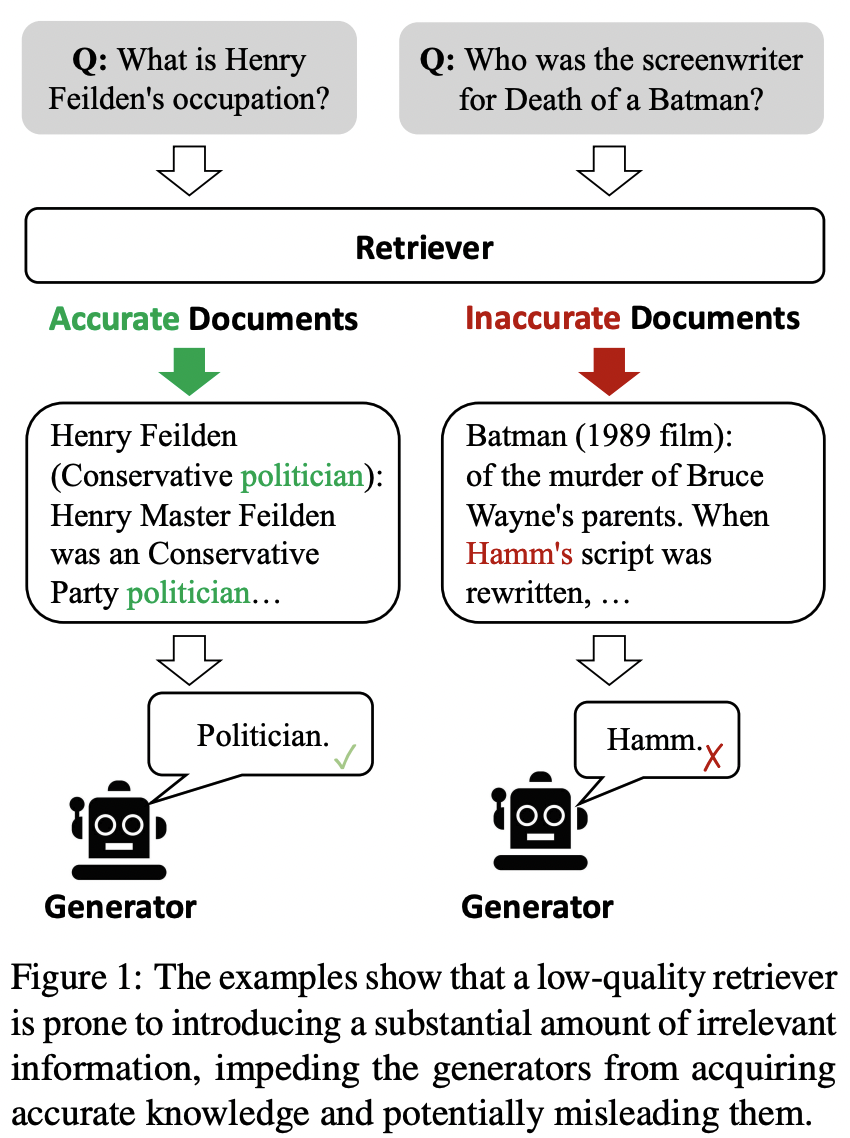
LLM을 보완하기 위해 RAG 방식을 사용하는데, RAG에서 관련성이 없는 문서를 가져오는 경우를 최소화하기 위한 방식으로 CRAG를 제안한다.
23.Retrieval meets Long Context Large Language Models
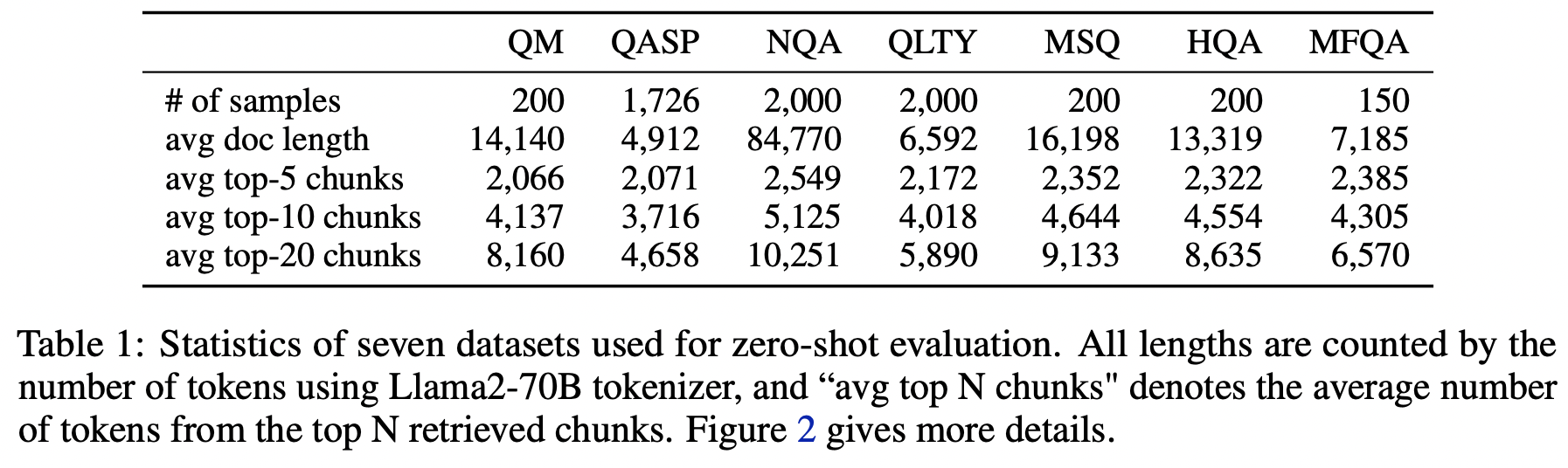
이 논문은 대규모 언어 모델(LLM)의 성능 향상을 위해 검색 기능 추가와 컨텍스트 윈도우 확장이라는 두 가지 접근 방식을 비교 분석한 연구입니다. 결과로 검색 기능은 모델의 컨텍스트 윈도우 크기와 관계없이 성능을 크게 향상시키는 것으로 나타났음을 보여줍니다.
24.LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
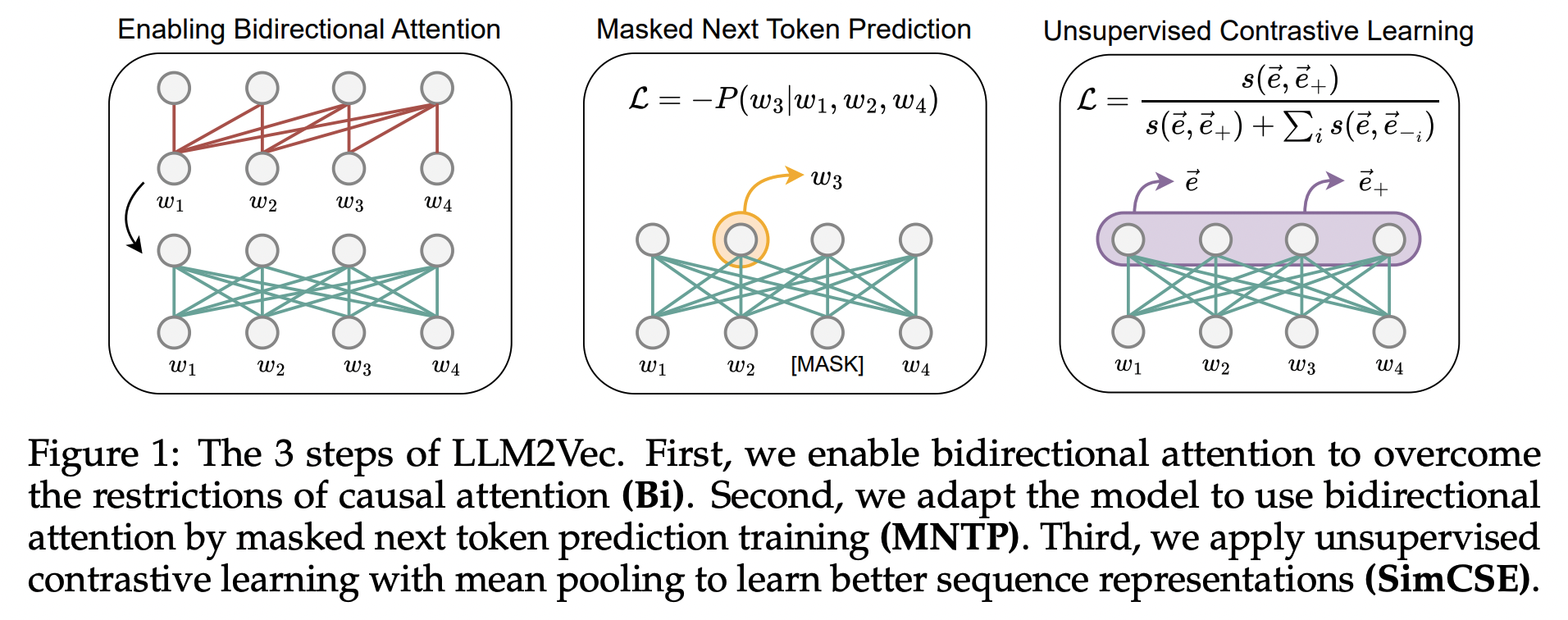
이 논문은 디코더 전용 대규모 언어 모델(LLM)을 텍스트 임베딩 모델로 변환하는 새로운 간단한 비지도 학습 방법인 LLM2Vec를 제안합니다. LLM2Vec을 통해 디코더 전용 LLM을 강력한 텍스트 인코더로 변환할 수 있습니다.
25.Linq-Embed-Mistral Report
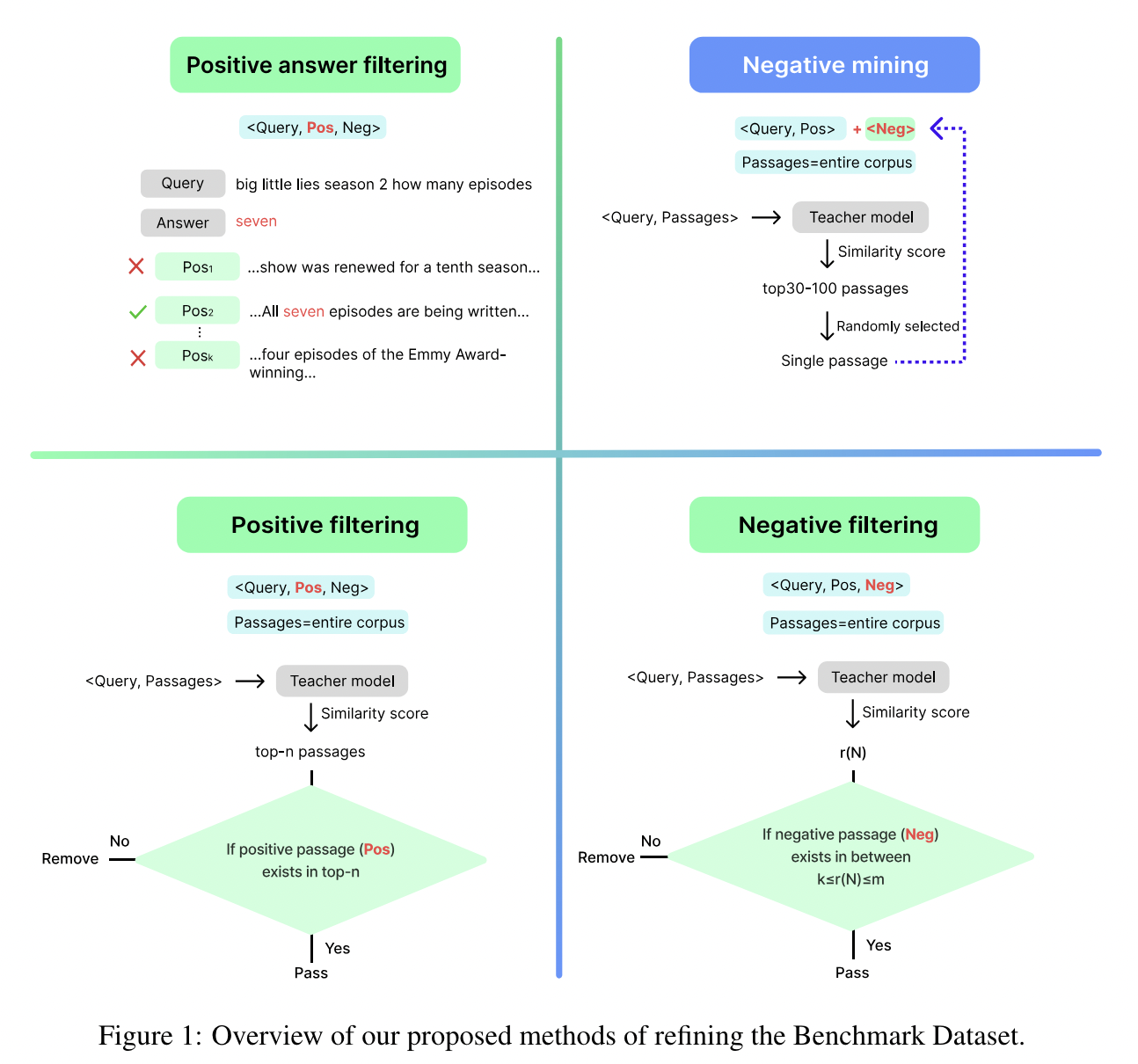
E5-Mistral 모델의 성능은 56.9였습니다. 정제된 데이터셋을 추가함으로써 SFR 모델의 성능이 59.0으로 증가하였으며, 더 정교한 합성 데이터셋을 이용함으로써 이 리포트에서 공개한 모델은 60.2까지 향상되었습니다.
26.Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting
Speculative RAG는 두 개의 모델을 활용해 성능을 개선합니다. 작은 전문 모델이 여러 초안을 만들고, 큰 일반 모델이 이를 검토하여 최상의 답변을 선택합니다. 이 방식은 정확도를 높이고 응답 시간을 단축합니다.
27.Retrieving, Rethinking and Revising: The Chain-of-Verification Can Improve Retrieval Augmented Generation
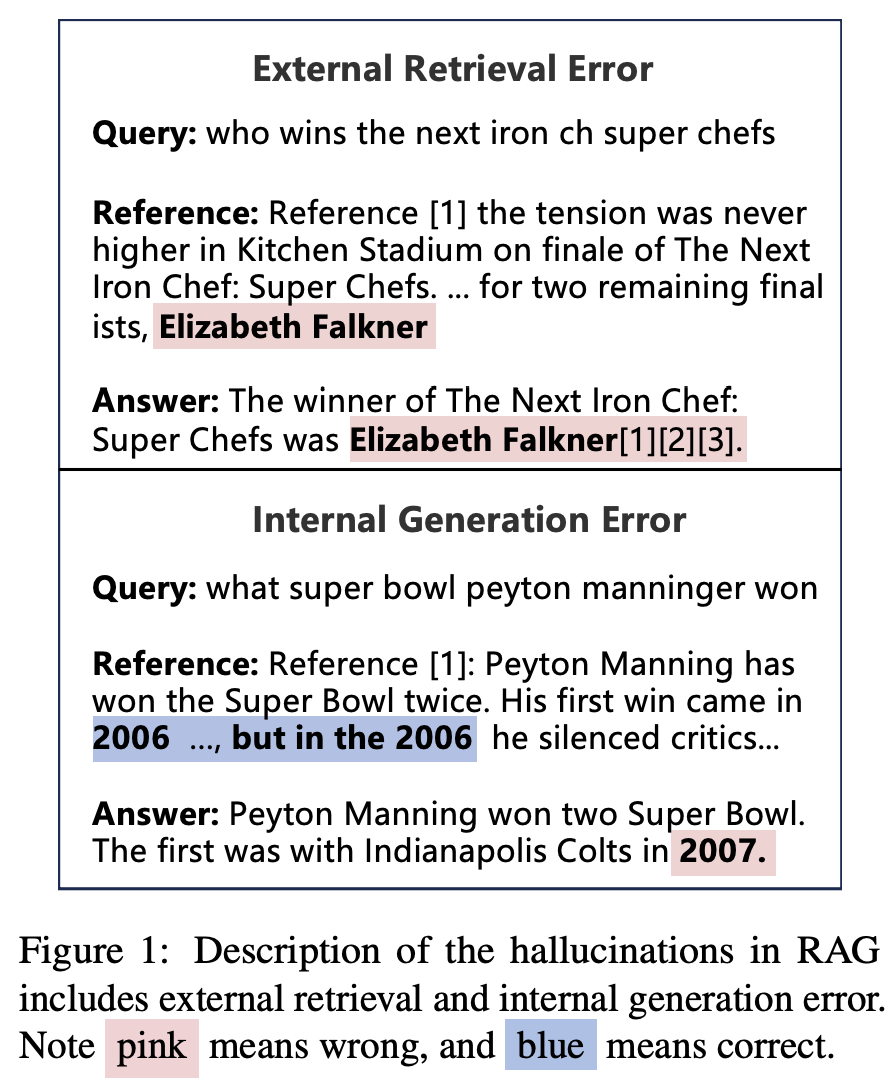
이 논문은 바이두에서 나온 2024년 10월 8일 논문입니다. LLM(대형 언어 모델)은 강력한 텍스트 생성 능력을 갖추고 있지만, 종종 hallucination 문제로 인해 사실과 다른 정보를 제공하는 경우가 발생합니다. 이를 방지하기 위해 RAG(검색 보강 생성) 방법이 도입되었습니다. 하지만 RAG(검색 보강 생성) 방법을 사용하더라도, 여전히 ha...
28.LIGHTRAG: SIMPLE AND FAST RETRIEVAL-AUGMENTED GENERATION
LightRAG 논문에서는 기존 RAG(Retrieval-Augmented Generation) 시스템의 주요 한계점으로 평면적 데이터 표현에 의존하는 점, 부적절한 맥락 인식, 단편적인 답변 생성, 확장성 및 효율성 문제, 그리고 동적 환경에서의 적응 문제를 지적하고 있습니다. 기존 시스템은 데이터를 평면적으로 표현하여 복잡한 관계와 상호의존성을 포착하지...
29.LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs
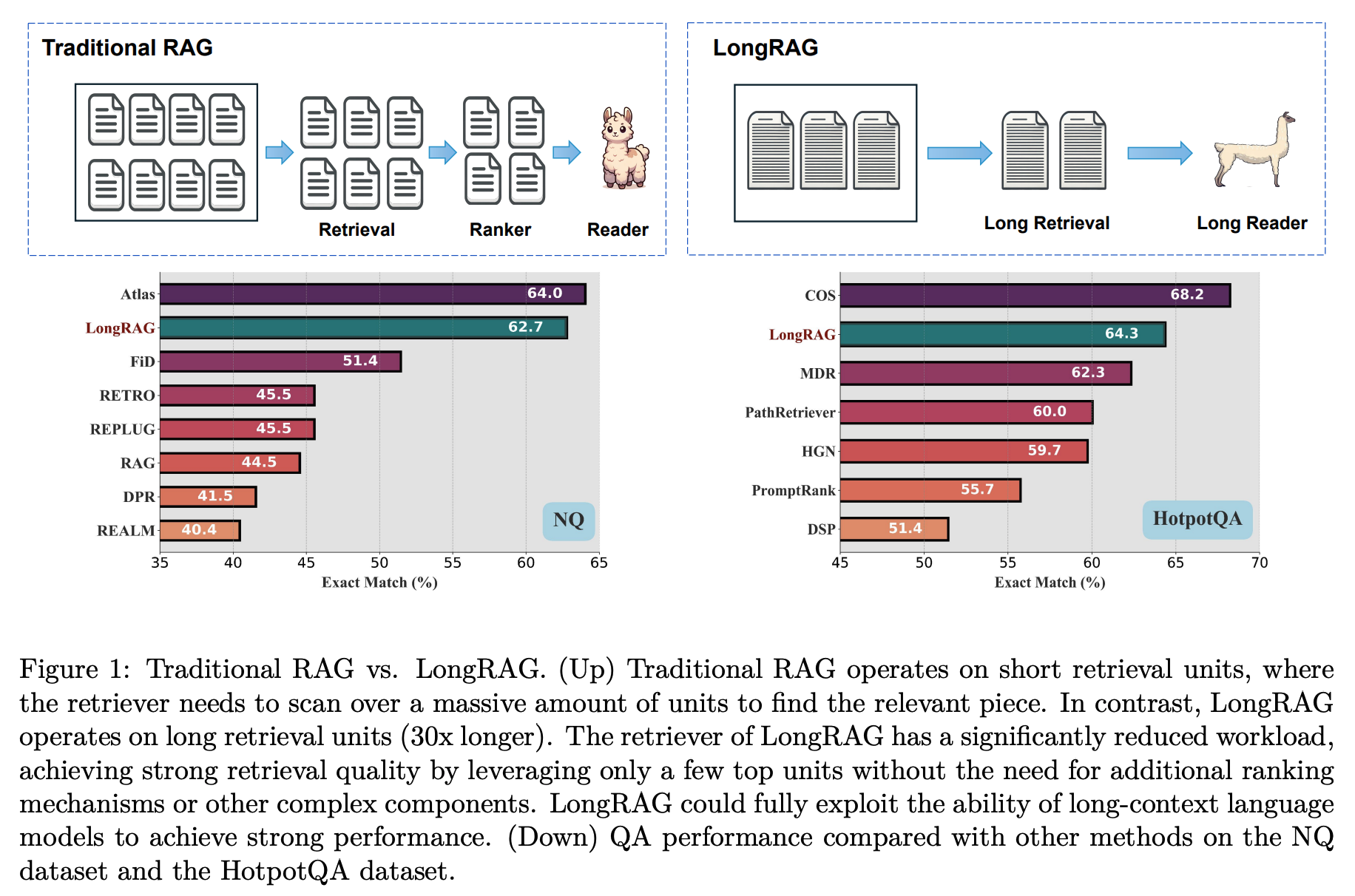
LongRAG는 검색 단위를 4,000 토큰으로 30배 확장하여 전체 검색 단위를 2,200만 개에서 60만 개로 줄임으로써 답변 정확도를 높인 연구입니다.
30.Chain of Agents: Large Language Models Collaborating on Long-Context Tasks
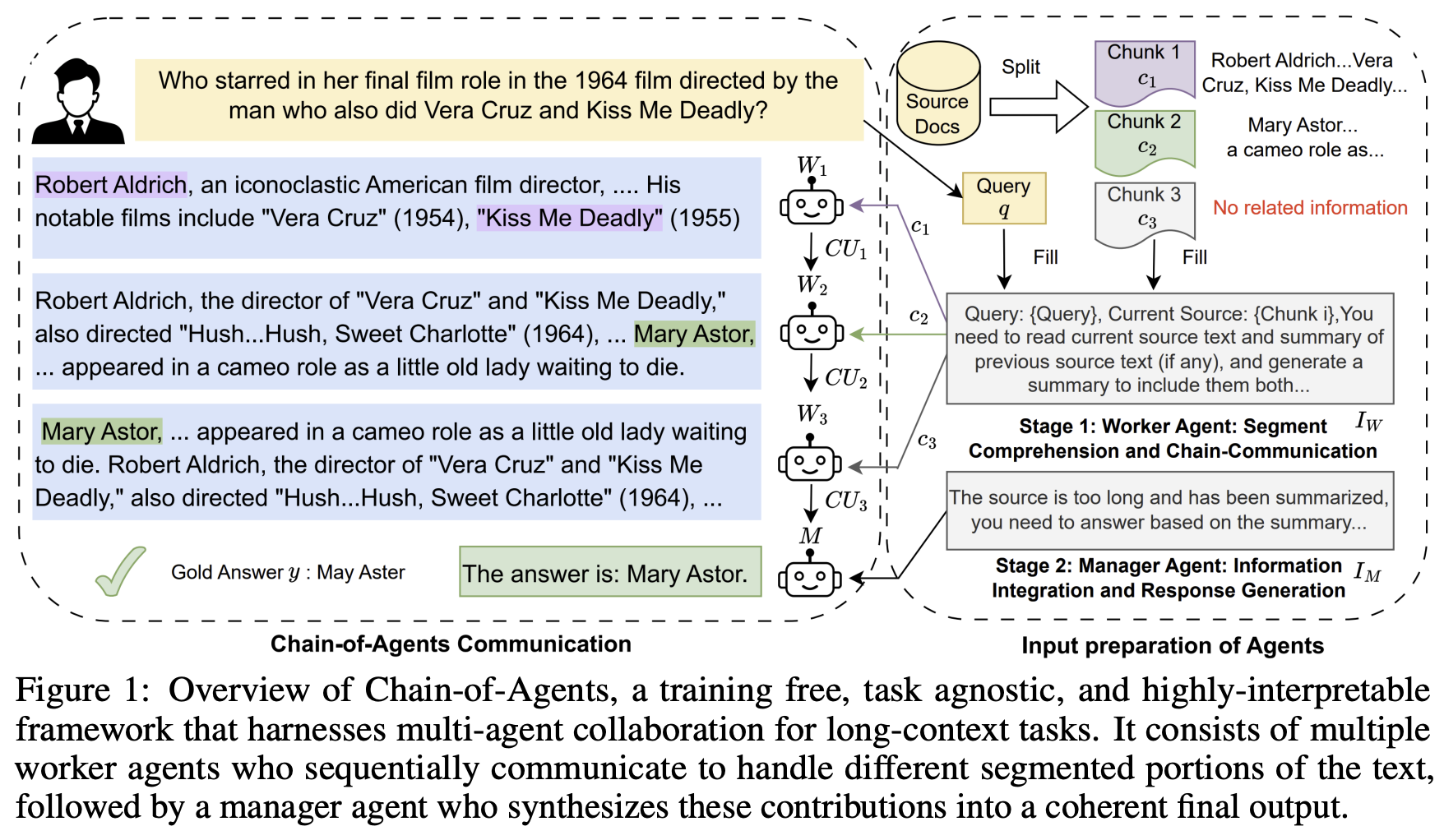
긴 문맥을 처리하는 데 있어 현재의 대형 언어 모델(LLM)이 겪는 한계와, 이를 극복하기 위한 새로운 접근법인 Chain-of-Agents(CoA) 프레임워크를 소개합니다.
31.Shifting from Ranking to Set Selection for Retrieval Augmented Generation
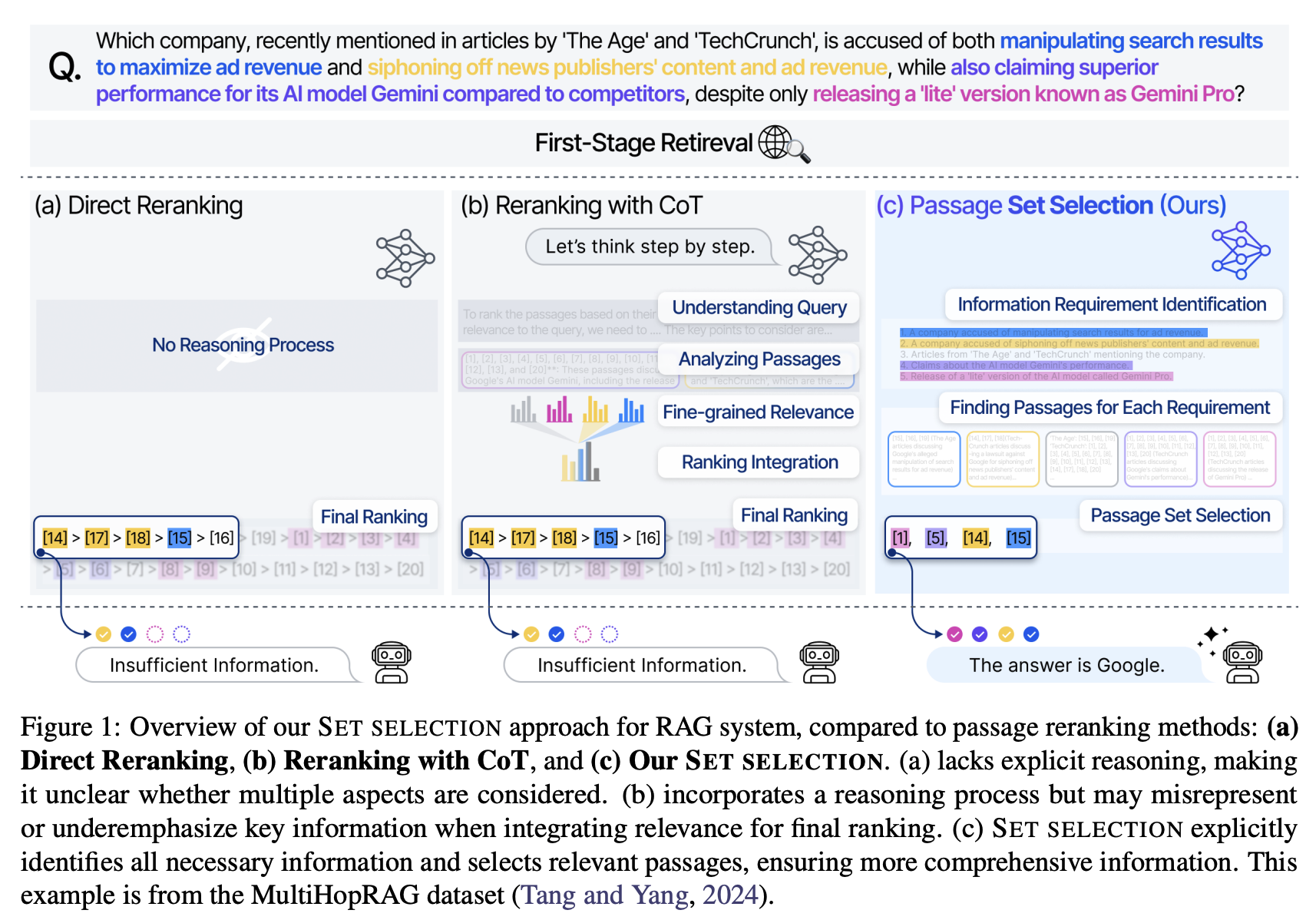
(a) Direct Reranking 그냥 점수 기반으로 passage를 개별 정렬 reasoning 없음 → 질의가 요구하는 여러 측면을 반영했는지 불분명 (b) Reranking with CoT reasoning은 있지만, 최종 단계에서 모든 관련성 점수를 단일 ranking으로 통합 이 과정에서 중요 정보가 희석·누락될 수 있음 (c) Set S...
32.EmbeddingGemma: Powerful and Lightweight Text Representations
대규모 언어모델이 수많은 태스크를 해결하고 있지만, 여전히 가볍고도 강력한 임베딩 모델을 만드는 일은 쉽지 않습니다. EmbeddingGemma는 이러한 문제의식에서 출발한 모델입니다. Gemma 3가 지닌 방대한 언어 지식을 계승하면서도, 단방향 구조(decoder-only)의 한계를 극복하기 위해 T5 방식의 encoder-decoder 구조로 재설계하...
33.MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation
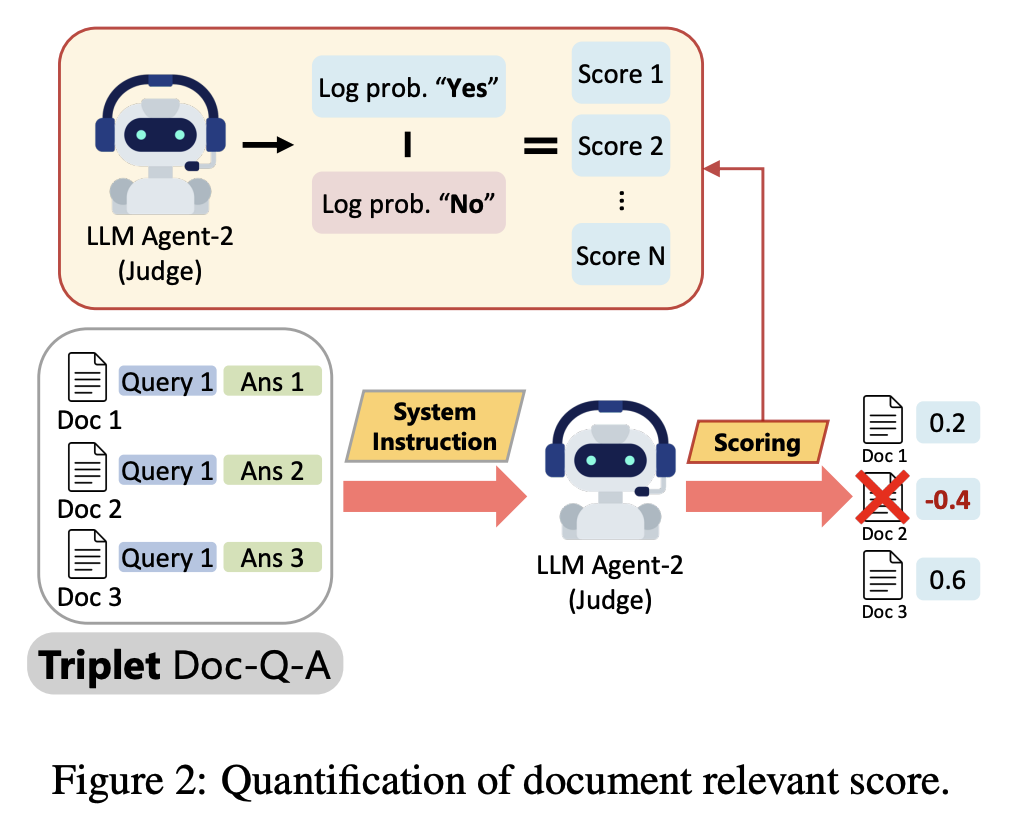
검색된 문서 내에 잡음(irrelevant information)이 많아 응답의 품질과 신뢰도가 떨어지는 현상을 문제라고 보고, 해결을 위해 MultiAgent FIlteriNg Retrieval-Augmented Generation(MAIN-RAG)를 제안합니다.