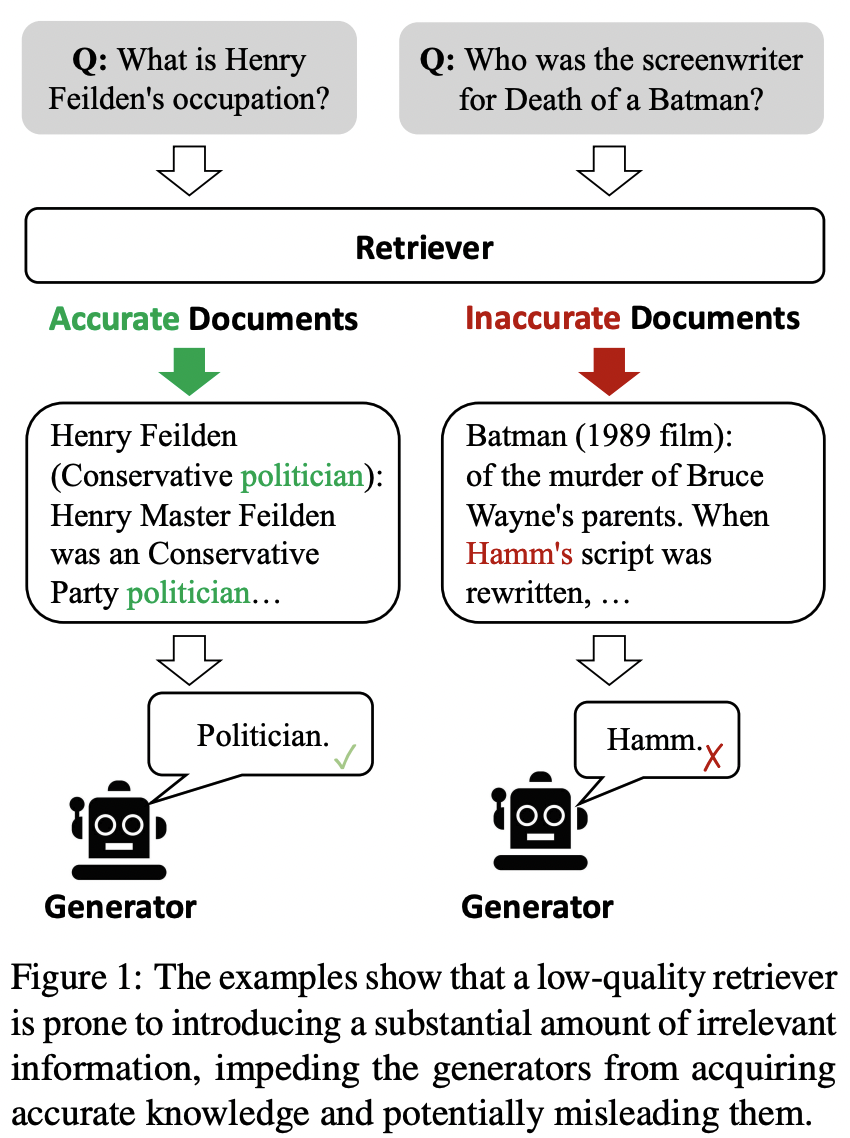
LLM에는 hallucination 문제가 있는데, 이를 보완하기 위해서 관련된 문서를 먼저 뽑아서 LLM에게 같이 전달하는 방식인 RAG(Retrieval-augmented generation)를 채택한다.
하지만 관련성이 없는 문서를 잘못해서 뽑아주게 되는 경우가 생기기도 하는데, 이런 점을 보완하기 위해서 Self-RAG등 렇게 되면 hallucination이 여지없이 발생한다. 이 문제를 해결하기 위해 이 연구에서는 Corrective Retrieval Augemented Generation(CRAG)를 제안한다. (핵심은 Robustness of generation 올리기 위해 관련성이 없는 문서를 관련성이 있는 문서로 바꿔주는 것이다.)
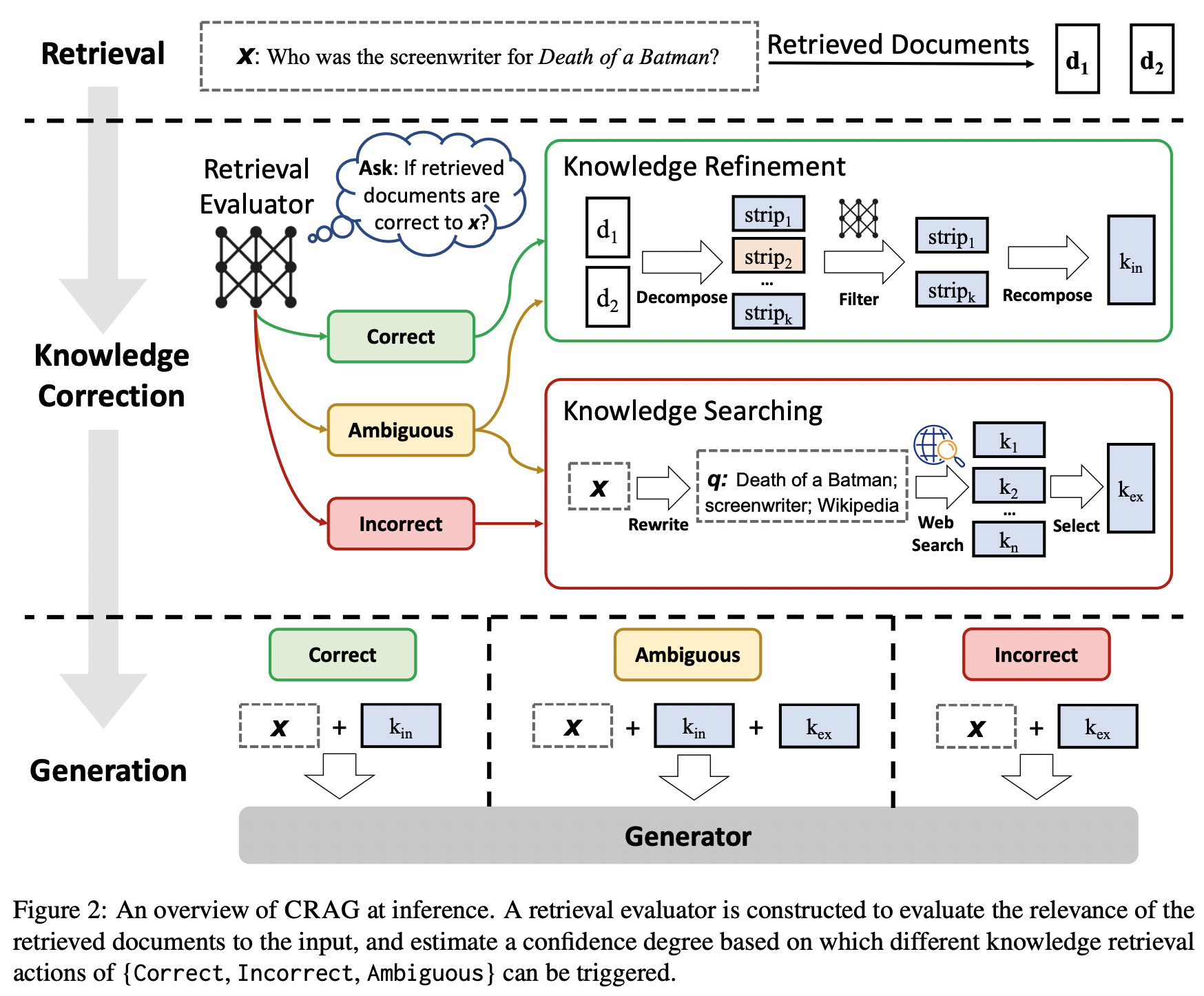
Retrieval evaluator를 T5-large 이용해서 학습하고 relevance score를 생성한다. 생성한 스코어를 기반으로 PopQA의 경우는 (0.59. -0.99), PubQA(0.5, -0.91), Arc-Challenge, Biography는 (0.95, -0.91) 기준으로 Correct, Ambiguout, Incorrect를 구분한다.
- Correct일 경우에는 관련성이 있다고 판단되는 문서들 내부에서 noisy한 부분을 더욱 제거하기 위해 한두문장 정도의 더 작은 단위로 자르고 다시 evaluator를 통해서 -0.5보다 낮은 스코어를 가지는 부분을 제거하고(filter) 스코어 기반의 정렬을 통해서 Knowledge refinement를 진행한다. (모델 length 짧기 때문에 작은 단위로도 이 부분을 수행하는 것으로 보인다.)
- Incorrect인 경우, 관련성이 있는 문서가 존재하지 않기 때문에 Web 검색을 통해서 (이 연구에서는 Google API) 문서를 가져온다. 웹 검색을 하기 전 키워드 기반의 검색을 위한 rewriting을 거치게 된다. 그렇게 해서 가져온 문서(top
-5)들을 기반으로 refinement를 진행한다.
- Ambiguous일 때에는 위의 두 개를 혼합해서 진행하도록 한다.
이전 Self-RAG에서는 critic model로 LLaMA-2(7B)를 사용한 반면 여기에서는 0.77B의 작은 모델을 사용했다는 점이 가장 큰 차이점이다.

이 연구에서는 PopQA(short-form generation), Biography(long-form generation), PubHealth(true-or-false question), Arc-Challenge(multiple-choice question) 네 가지 task를 수행했고 결과는 아래와 같다.
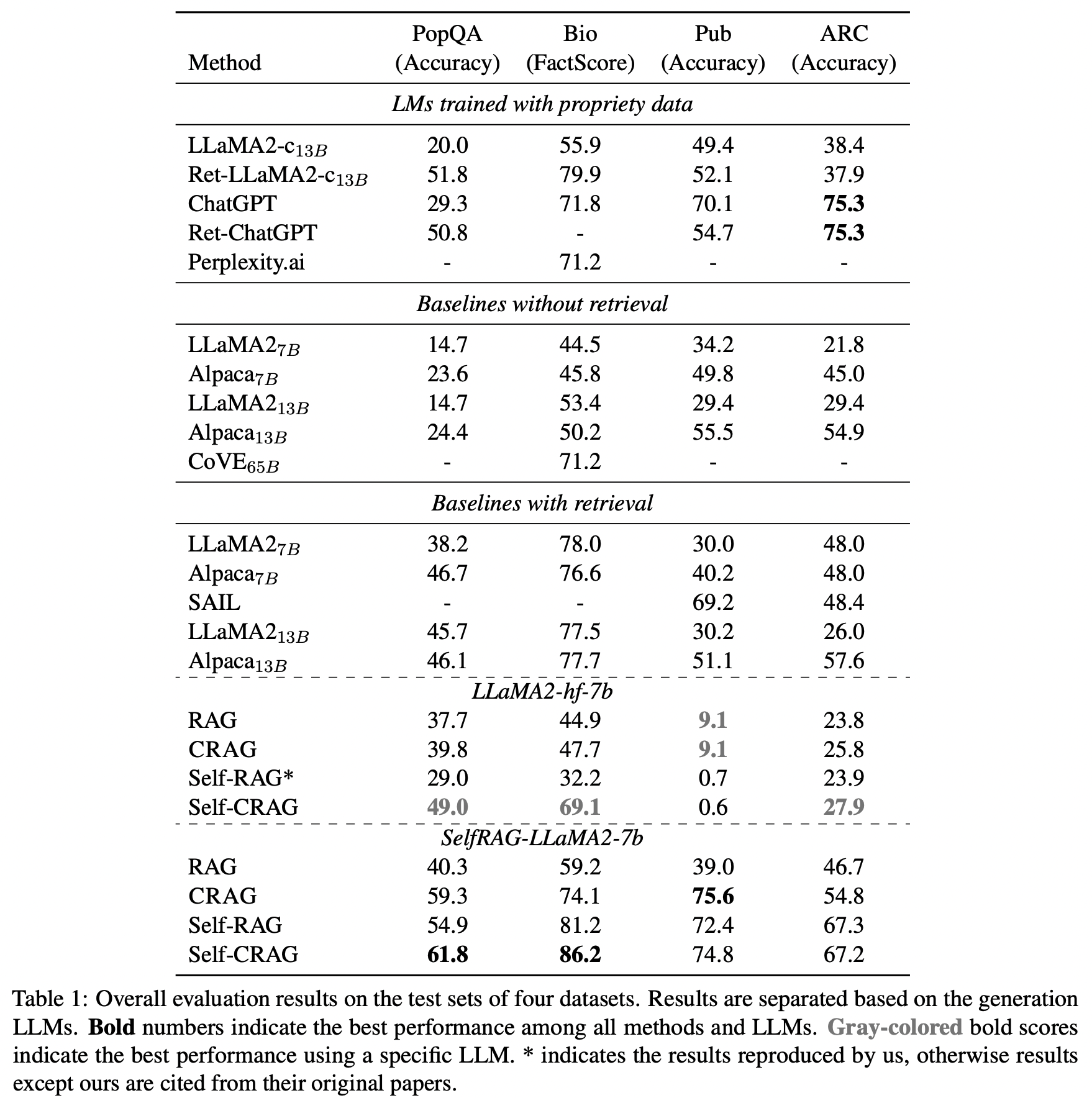
- 결과를 통해서 알 수 있는 것은 RAG < CRAG
- Self-RAG < Self-CRAG (
- Metric은 Biography의 경우 FactScore를 사용했다. (LLM 생성 결과를 신뢰할수 있는지를 확인하는 모델 통한 점수)
- Chain-of-Verification (CoVE)
- CoVe first generates a plan of a set of verification questions to ask, and then executes that plan by answering them and hence checking for agreement.
- Llama 65B로 만든 것으로 보인다.
Abalation & Analysis
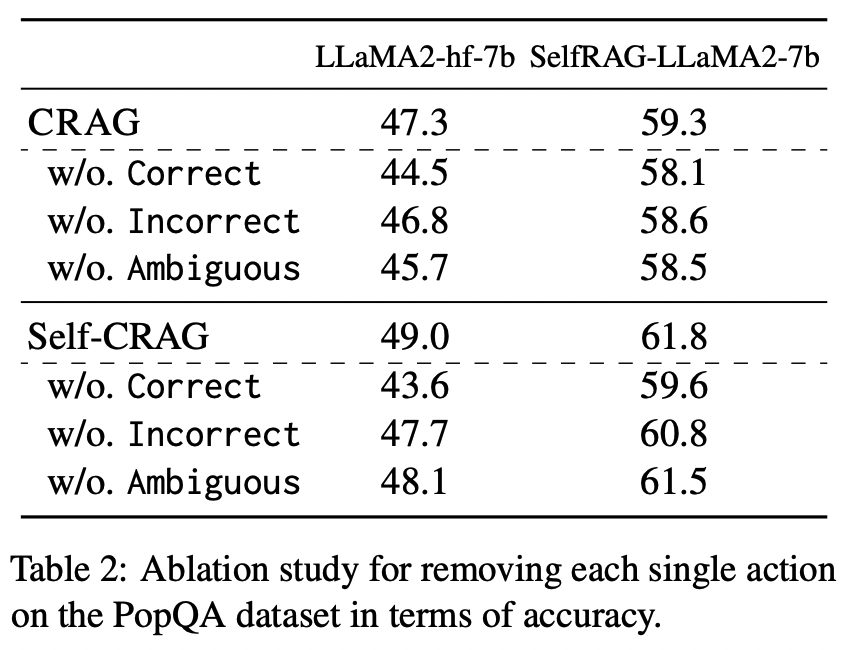
- action은 세 가지로 incorrect, ambiguous를 사용하는 경우, correct, ambiguous를 사용하는 경우, correct, incorrect만을 사용하는 경우로만 한정해서 결과를 확인했을 때에 점수가 떨어지는 것을 확인할 수 있다.
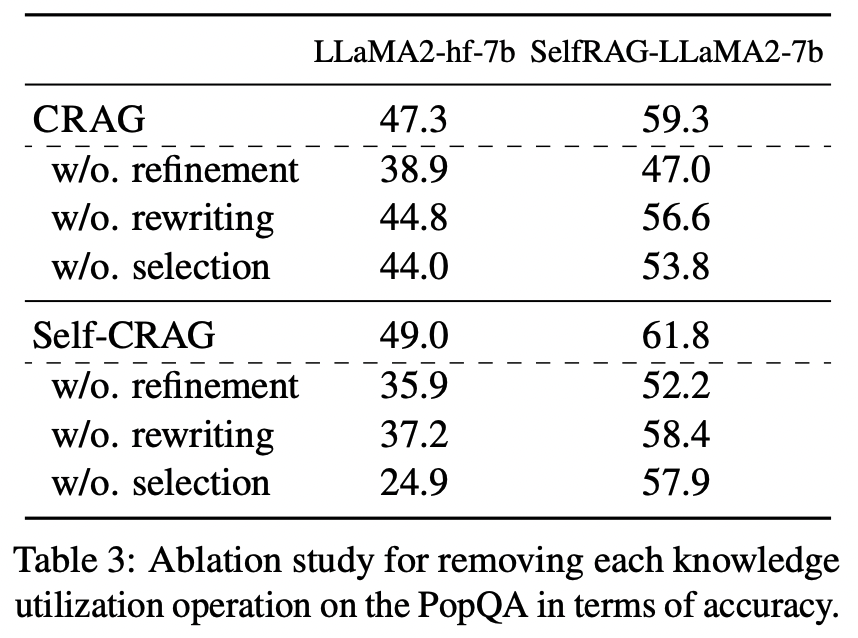
- Refinement, Query rewriting, External knowledge selection을 하지 않을 때에도 각각의 경우 점수가 떨어지는 것을 보면 이것들이 전부 다 최종결과를 생성하는 데에 중요한 역할을 하고 있음을 알 수 있다.
- Evaluator로 T5-large를 사용하고 있는데, 이건 ChatGPT 이용한 evaluator보다 성능이 좋다.

- ChatGPT를 이용한 Evaluator는 아래와 같이 만들었다. (다만 T5 evaluator의 경우 relevance score가 나오는데 아래 프롬프트를 보면 binary 결과가 나오도록 만들어졌다.)

- ChatGPT를 이용한 Evaluator는 아래와 같이 만들었다. (다만 T5 evaluator의 경우 relevance score가 나오는데 아래 프롬프트를 보면 binary 결과가 나오도록 만들어졌다.)
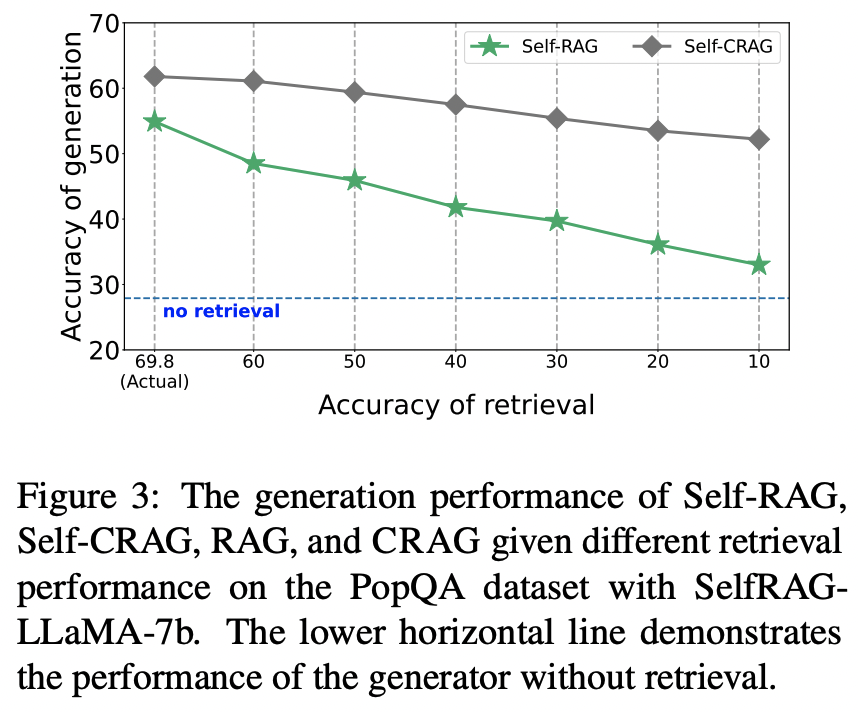
- Retrieval 성능에 따른 generation 결과도 살펴보면 Self-RAG보다 Self-CRAG가 더 좋고 덜 가파르게 점수가 떨어진다.