최근 대규모 언어 모델(Large Language Models, LLMs)의 성능을 향상시키기 위해 컨텍스트 윈도우를 확장하는 방법이 주목받고 있습니다. 한편, LLM에 검색 기능을 추가하여 성능을 개선하는 솔루션은 이미 오래전부터 존재해 왔습니다. 이에 따라 자연스럽게 두 가지 질문이 떠오릅니다.
- 검색 기능 추가와 긴 컨텍스트 윈도우 중 어떤 것이 다운스트림 작업에 더 효과적일까요?
- 두 가지 방법을 결합하여 최상의 성능을 얻을 수 있을까요?
이 논문에서는 16k 토큰의 컨텍스트 윈도우를 사용하여 약간의 노이즈가 포함된 정보를 처리하는 경우와, 4k 토큰의 컨텍스트 윈도우에 검색 기능을 추가하여 비교적 노이즈가 적은 정보를 처리하는 경우를 비교하고 있습니다. 연구 결과, 후자의 방법이 더 우수한 성능을 보여주는 것을 수치로 보여줍니다.
또한, 이 논문은 16K 또는 32K의 큰 컨텍스트 윈도우를 가진 LLM에도 검색 기능을 추가할 경우, 성능이 더욱 향상된다는 점을 확인했습니다. 결론적으로, 검색 기능 추가와 컨텍스트 윈도우 확장을 동시에 적용하면 더 뛰어난 결과를 얻을 수 있다고 제안하고 있습니다.
이 연구는 LLM의 성능 향상을 위해 검색 기능 추가와 컨텍스트 윈도우 확장이라는 두 가지 접근 방식을 비교 분석하고, 나아가 두 방법을 함께 활용하는 것이 가장 효과적이라고 주장합니다.
Evaluation datasets
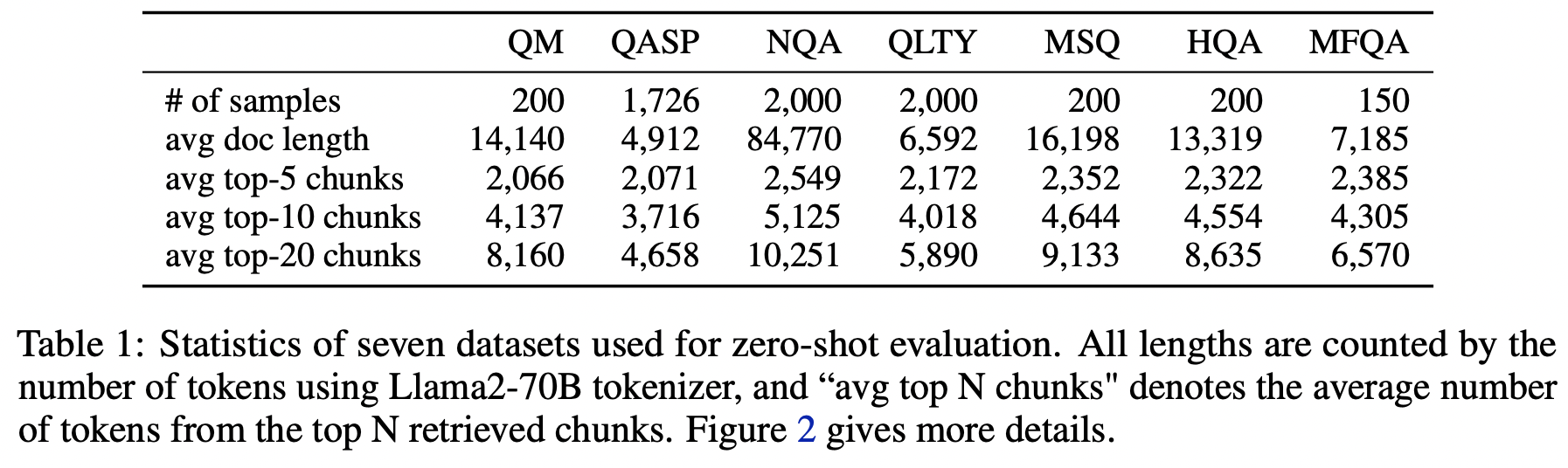 이 논문에서는 대규모 언어 모델의 성능을 평가하기 위해 7개의 다양한 데이터셋을 사용했습니다. 이 데이터셋들은 단일 문서 QA, 다중 문서 QA, 그리고 질의 기반 요약 등 다양한 유형의 테스크를 포함합니다.
이 논문에서는 대규모 언어 모델의 성능을 평가하기 위해 7개의 다양한 데이터셋을 사용했습니다. 이 데이터셋들은 단일 문서 QA, 다중 문서 QA, 그리고 질의 기반 요약 등 다양한 유형의 테스크를 포함합니다.
구체적으로, Scroll 벤치마크의 검증 세트에서 4개의 데이터셋(QMSum, Qasper, NarrativeQA, QuALITY)을 사용했고, LongBench에서 3개의 데이터셋(HotpotQA, MuSiQue, MultiFieldQA-en)을 추가로 사용했습니다.
이 데이터셋들은 각각 다른 특징을 가지고 있습니다:
- QMSum은 회의 대화록과 그에 대한 요약을 포함하는 질의 기반 요약 데이터셋입니다.
- Qasper는 NLP 논문에 대한 QA 데이터셋으로, 추상적, 추출적, yes/no 질문 및 대답할 수 없는 질문을 포함합니다.
- NarrativeQA는 책과 영화 대본에 대한 QA 데이터셋으로, 주어진 문서가 매우 길고 노이즈가 있습니다.
- QuALITY는 이야기와 기사에 대한 다중 선택형 QA 데이터셋입니다.
- HotpotQA와 MuSiQue는 Wikipedia 기반의 다중 홉 QA 데이터셋으로, 여러 문서를 읽어야 답을 할 수 있습니다.
- MultiFieldQA-en은 다양한 분야의 긴 문서에 대한 이해 능력을 테스트하기 위해 수동으로 큐레이션된 데이터셋입니다.
이 데이터를 보면 평가셋으로 사용되는 데이터들의 평균 문서 길이가 매우 다양하다는 점을 알 수 있습니다.
Table 1에서 볼 수 있듯이, 이 데이터셋들의 평균 문서 길이는 4.9k(Qasper)부터 84k(NarrativeQA)까지 다양합니다. 따라서 검색 기능이 없는 베이스라인 모델의 경우, 입력 시퀀스 길이에 맞추기 위해 문서를 잘라내야 합니다.
이 연구의 주요 목적 중 하나는 검색 기능 추가와 컨텍스트 윈도우 확장의 효과를 비교하는 것입니다. Chunk를 사용함으로써, 4k 토큰 윈도우에서 검색된 chunk를 사용하는 것과 16k 토큰 윈도우에서 truncation을 사용하는 것의 성능 차이를 분석할 수 있습니다.
이렇게 다양한 데이터셋을 사용함으로써, 저자는 제안된 방법(검색 기능 추가 및 컨텍스트 윈도우 확장)이 다양한 유형의 태스크와 문서 길이에 대해 효과적임을 보여주고자 합니다.
Long context & Retrieval model
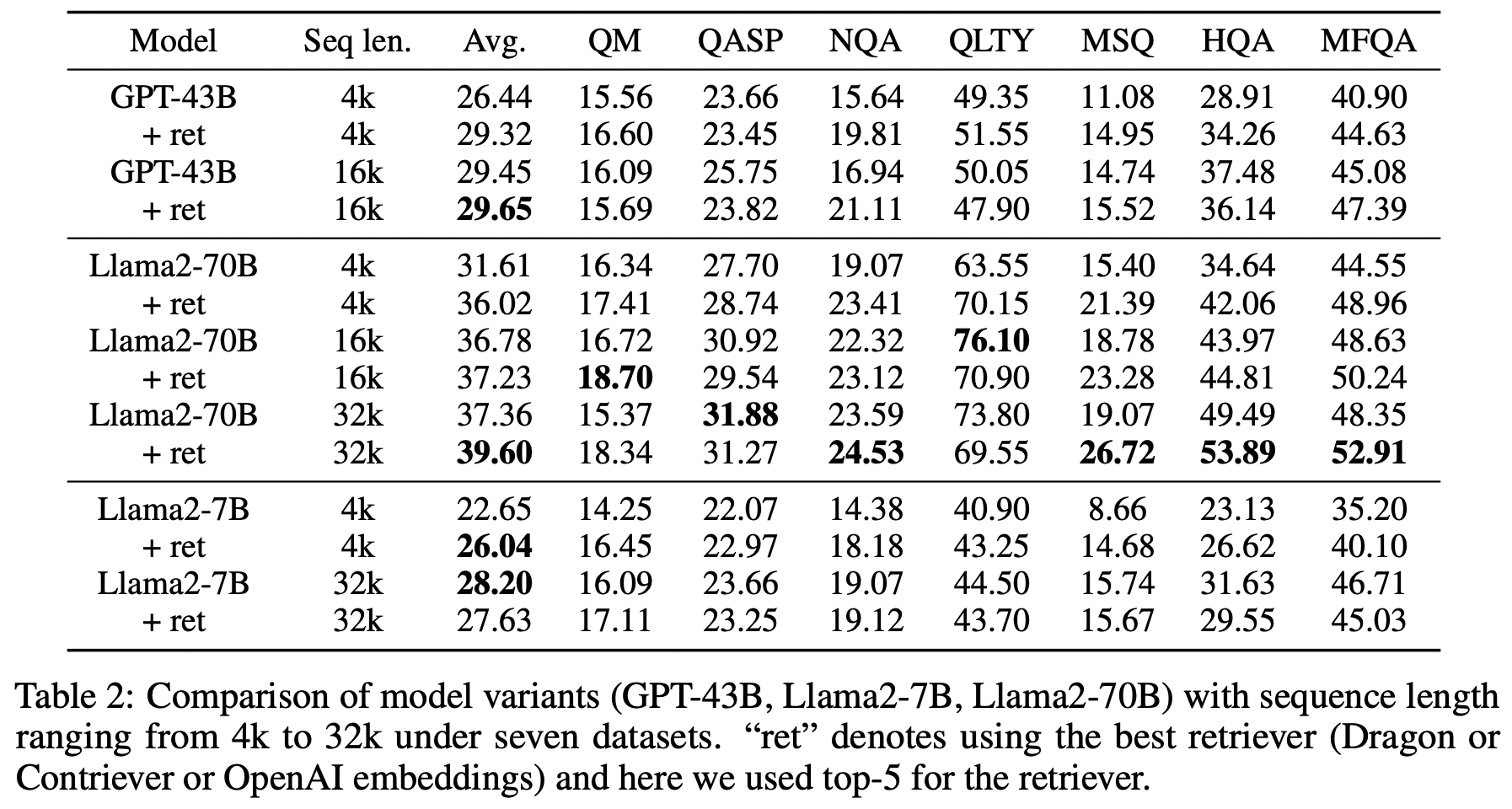
이 논문에서는 컨텍스트 윈도우 확장과 검색 기능 추가에 따른 점수를 보여줍니다.
- GPT-43B의 경우, 4K 컨텍스트 윈도우를 16K로 확장했습니다.
- Llama2-7B는 4K에서 32K로, Llama2-70B는 4K에서 16K와 32K로 확장했습니다.
- 세 가지 검색 모델을 실험했습니다: Dragon, Contriever, OpenAI embedding (Dragon은 Multiple teacher의 개념으로 여러 모델을 통해서 hard negative를 다양하게 뽑은 biencoder model이라고 한다.)
- 각 문서를 300 단어씩 chunk로 나누고, 질문과 chunk를 독립적으로 인코딩했습니다.
retrieval 모델을 안붙여도 좋은 경우가 있기는 하지만 대부분 검색모델을 붙였을 때에 더 좋은 결과가 나오고, 입력 길이가 길어질수록 점수가 좋아진다.
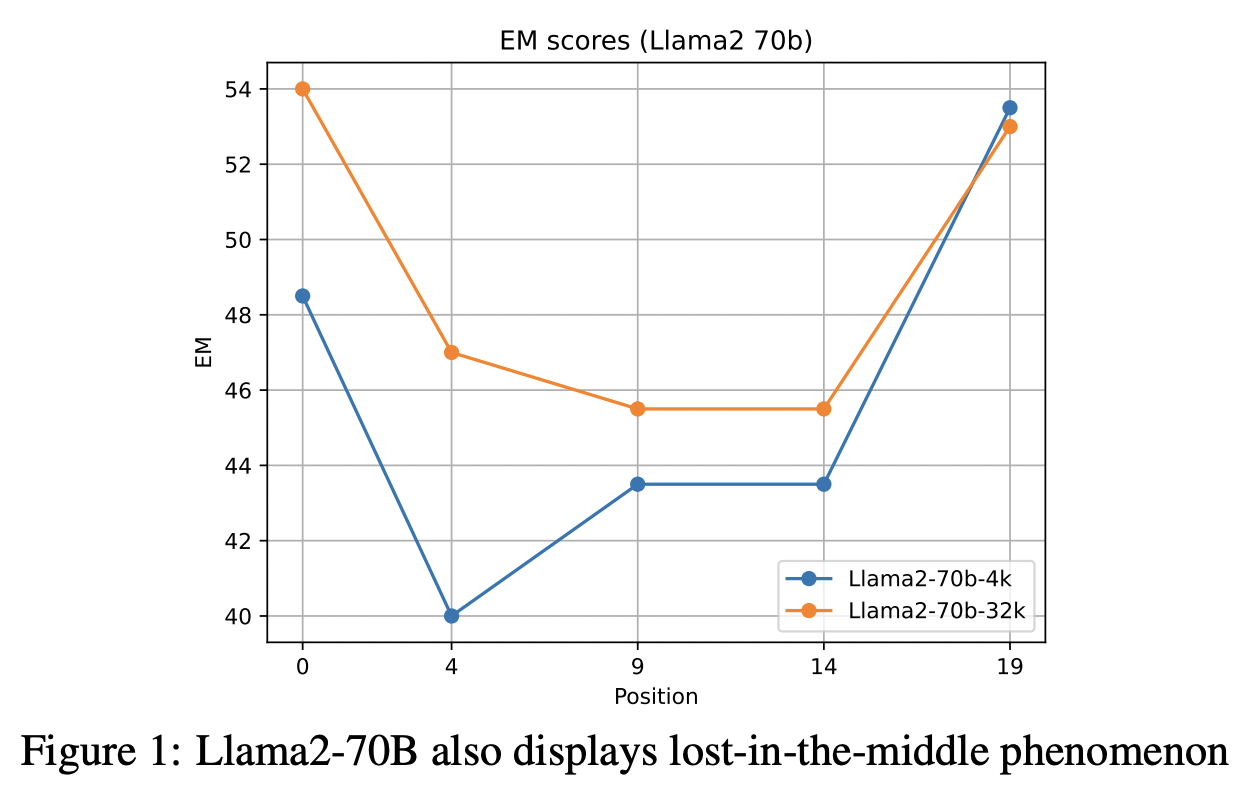
Lost in the middle 현상은 나타나지만 그래도 32k가 4k보다는 덜 손실된다.
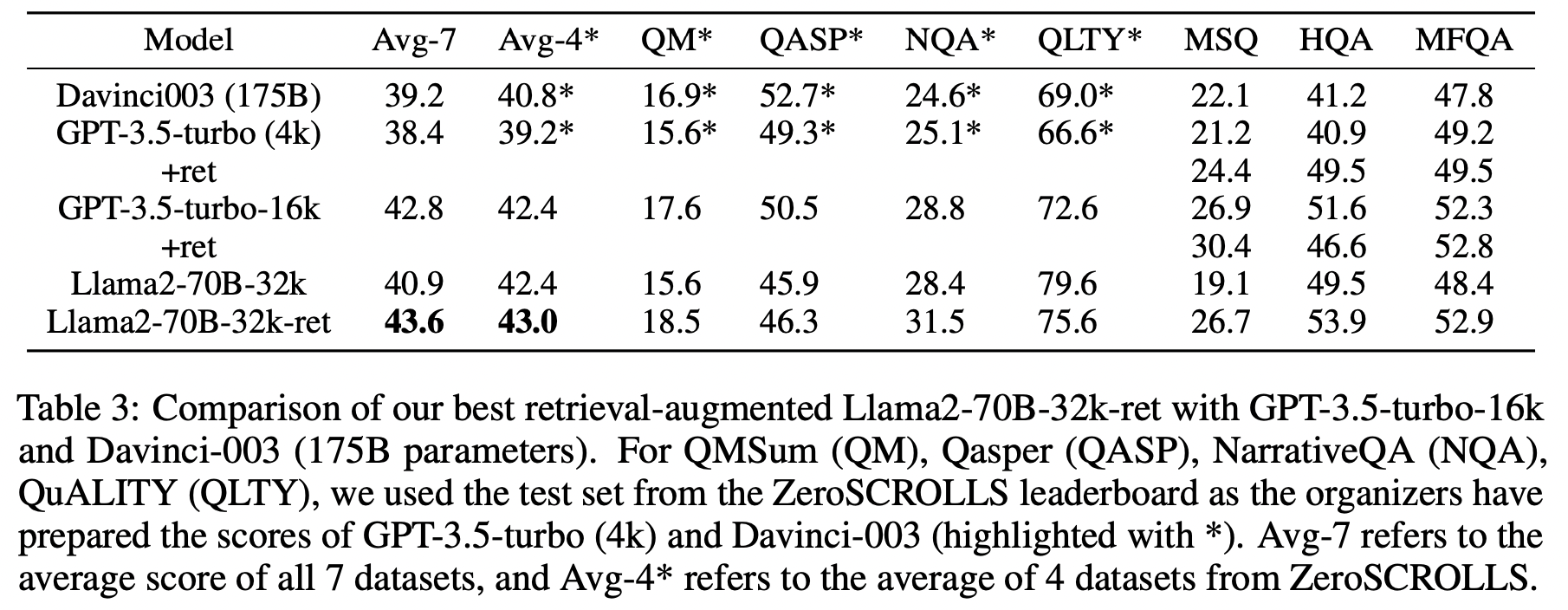
이전 연구인 Bai et al. (2023)에서는 긴 컨텍스트를 처리할 수 있는 모델에 검색 기능을 추가하면 오히려 성능이 저하된다고 주장했습니다. 하지만 이번 논문에서는 모델의 크기나 종류에 관계없이 검색(Retrieval model)을 포함시키는 것이 항상 성능 향상으로 이어질 수 있다는 상반된 주장을 펼치고 있습니다.
이런 차이가 발생한 원인으로, 이전 연구에서 사용된 6-7B 정도의 모델 크기가 상대적으로 작아 긴 컨텍스트를 효과적으로 처리하지 못했을 가능성을 제시하고 있습니다. 특히 4k 정도의 컨텍스트 길이를 다루기에는 7B 모델이 충분히 크지 않았을 수 있다는 의견입니다.
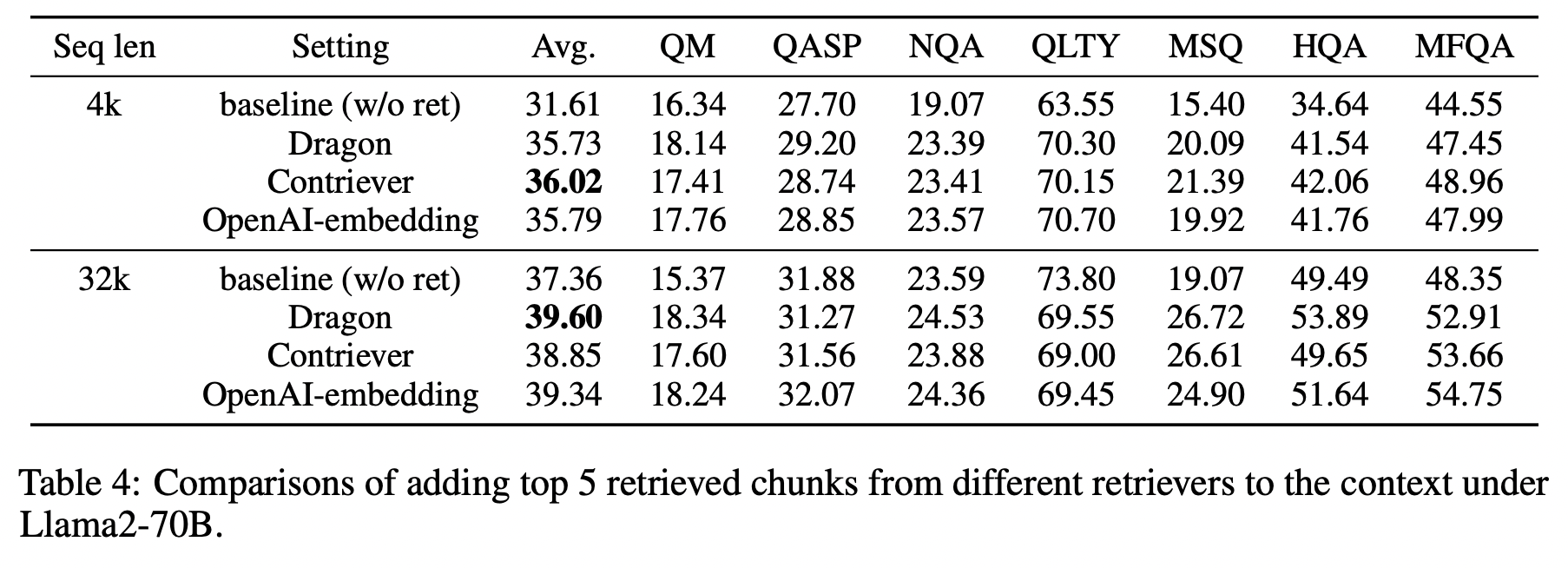
이 연구에서는 검색 모델의 종류에 따라 성능이 오히려 저하될 가능성도 있다는 점을 고려하여, 서로 다른 세 가지 검색 모델을 실험에 사용했습니다. 실험 결과, 사용된 검색 모델의 종류와 관계없이 모든 경우에서 검색 기능을 추가했을 때 평균적으로 더 나은 성능을 보였습니다. 검색 기능 자체의 존재 여부가 더 중요한 요소일 수 있다는 것을 보여주는 결과라고 할 수 있겠습니다.
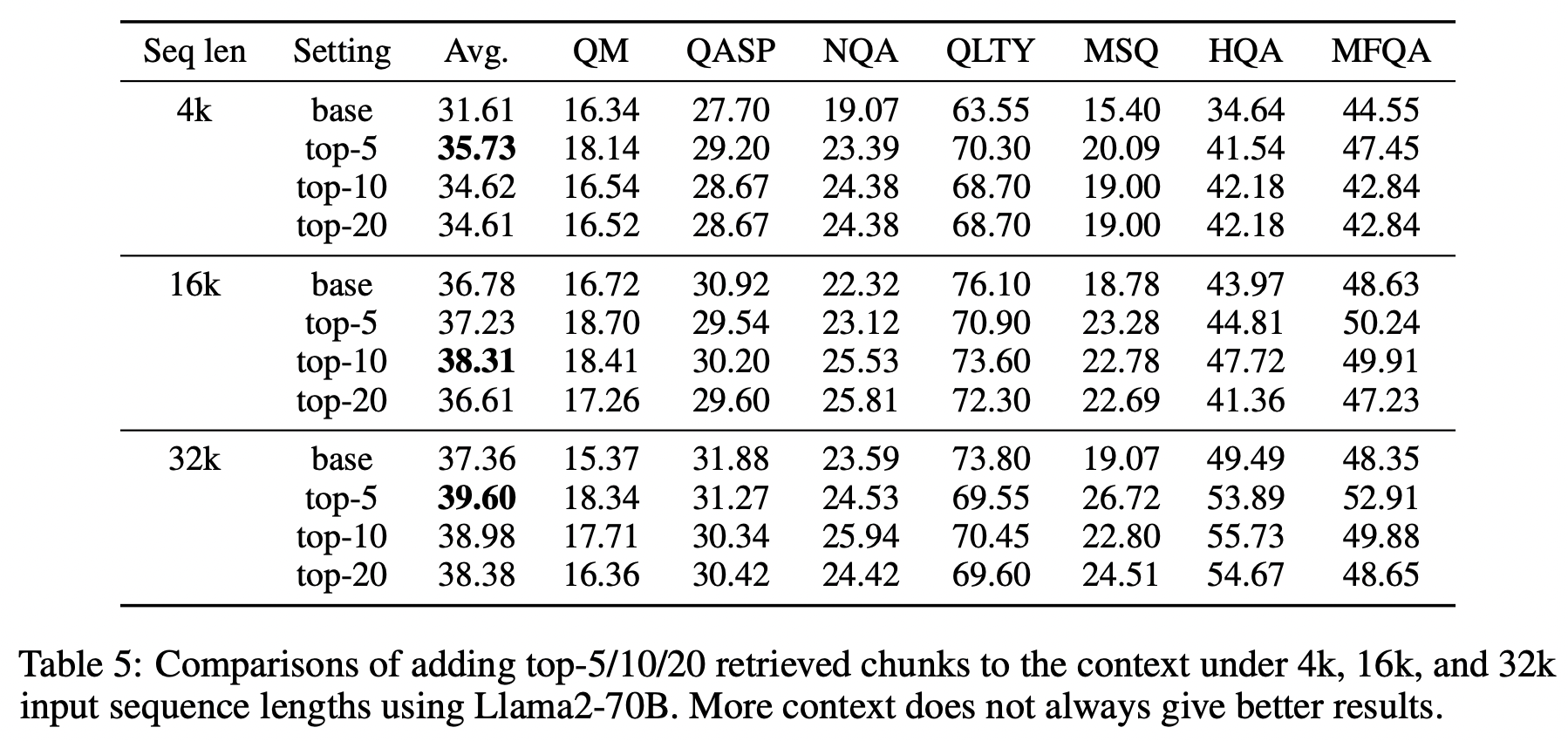
이 연구에서는 검색 청크 수를 늘려가며 모델의 성능을 비교했습니다. 모델마다 최적의 청크 수(Best N)가 다르게 나타났지만, 전반적으로 top-5 청크를 사용했을 때 가장 좋은 결과를 보였습니다. 이는 4k 컨텍스트 윈도우에 top-5 청크가 온전히 들어갈 수 있기 때문으로 분석됩니다.
한편, 16k 컨텍스트 윈도우에서는 top-10 청크까지 모두 들어갈 수 있어 가장 우수한 성능을 보였습니다. 반면, 32k 컨텍스트 윈도우의 경우 top-5 이후의 gold label을 잘 찾아내는 것이 중요했지만, "lost in the middle" 현상으로 인해 top-5 청크를 사용했을 때 평균적으로 가장 좋은 성능을 보였다고 합니다.
이러한 결과는 단순히 검색 청크 수를 늘리는 것만으로는 성능 향상에 한계가 있으며, 컨텍스트 윈도우 크기와 모델 아키텍처의 특성을 고려하여 최적의 청크 수를 선택하는 것이 중요함을 시사합니다. 특히 "lost in the middle" 현상은 긴 컨텍스트 윈도우를 가진 모델에서 중요한 정보가 중간에 위치할 때 활용도가 낮아질 수 있음을 보여주는 사례입니다.
Wrap up
이 연구는 대규모 언어 모델(LLM)의 성능 향상을 위해 검색 기능 추가와 컨텍스트 윈도우 확장이라는 두 가지 접근 방식을 체계적으로 분석했습니다.
- 검색 기능은 짧은 컨텍스트(4K)와 긴 컨텍스트(16K/32K) LLM 모두의 성능을 크게 향상시킵니다.
- 간단한 검색 기능이 추가된 4K 컨텍스트 LLM은 16K 긴 컨텍스트 LLM과 유사한 성능을 보이면서도 추론 시 더 효율적입니다.
- 컨텍스트 윈도우 확장과 검색 기능 추가를 통해 최적화된 Llama2-70B-32k-ret 모델은 GPT-3.5-turbo-16k와 Davinci003을 능가하는 성능을 보였습니다.
최적의 성능을 얻기 위해서는 모델 아키텍처, 컨텍스트 윈도우 크기, 검색 청크 수 등 다양한 요소를 종합적으로 고려해야 합니다. 검색 청크 수를 늘리는 것이 항상 성능 향상으로 이어지는 것은 아니며, "lost in the middle" 현상으로 인해 오히려 성능이 저하될 수 있다는 점에 주목할 필요가 있습니다.
그럼에도 불구하고 이 연구 결과는 검색 기술과 긴 컨텍스트 처리 기술을 효과적으로 조합하는 것이 LLM의 성능을 한층 더 끌어올릴 수 있는 방법임을 시사하고 있습니다.
