DOLA: DECODING BY CONTRASTING LAYERS IMPROVES FACTUALITY IN LARGE LANGUAGE MODELS
NLP Papers
Contrastive decoding
이전 연구(Contrastive Decoding: Open-ended Text Generation as Optimization)에서 디코딩 과정에서 ExpertLM에 더해서 작은 모델인 Amateur LM을 같이 사용함으로써 hallucination을 줄일 수 있는 방법에 대해서 제시한다. 그림에서 볼 수 있듯이 로짓값의 차이를 디코딩에 반영한다. Amateur LM이 못할 것이므로 못하는 로짓을 빼줌으로써 보완을 해준다는 아이디어를 이용했다. 이 경우 두 모델은 같은 vocab을 사용해야한다.
여기에서는 ExpertLM이 잘하고 Amateur LM이 둘 다 잘할 때에는 ExpertLM이 logit이 훨씬 더 크다는 것을 가정한다. ExpertLM이 못하고 Amateur LM이 잘하는 경우는 매우 적을 것이라고도 가정한다. 
이 연구를 기반으로 아마 모델을 굳이 여러개 사용하지 않고 hallucination을 해결할 수 있는 방법을 고민한 것으로 보인다.
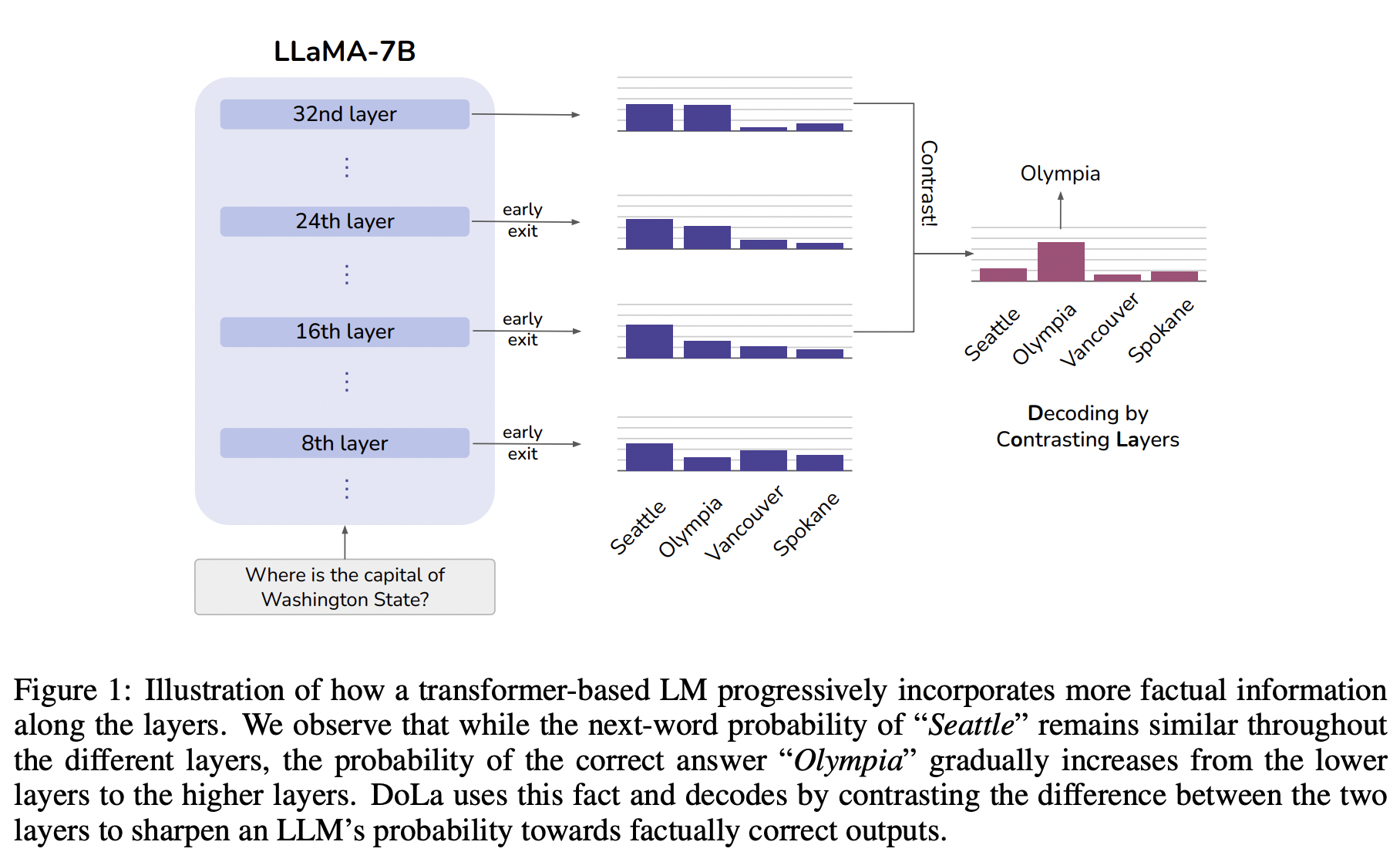
마지막 레이어와 가장 거리가 먼 레이어를 찾아서(Jensen-Shannon Divergences) 디코딩에 반영한다.
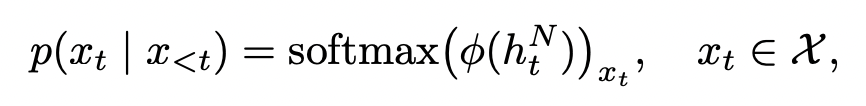
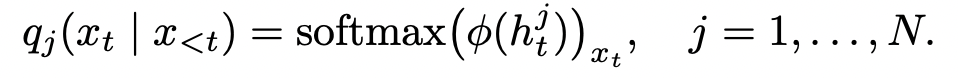
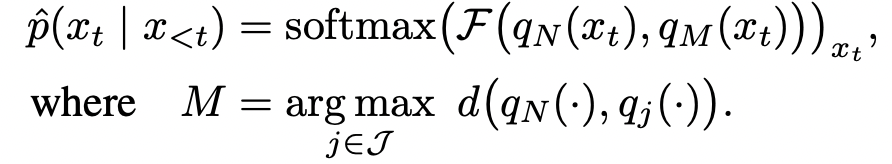
이 수식에서는 가장 마지막 레이어(N)에서의 결과값이랑 이전 레이어에서의 결과값 distribution 차이를 이용해 𝓕로 로짓값의 차이를 반영해서 결과 토큰을 내어주게 된다.
대신에 이렇게 할 경우에는 시간이 너무 많이 들기 때문에, 버킷을 이용한다거나 다양한 방법을 사용하려고 한다.
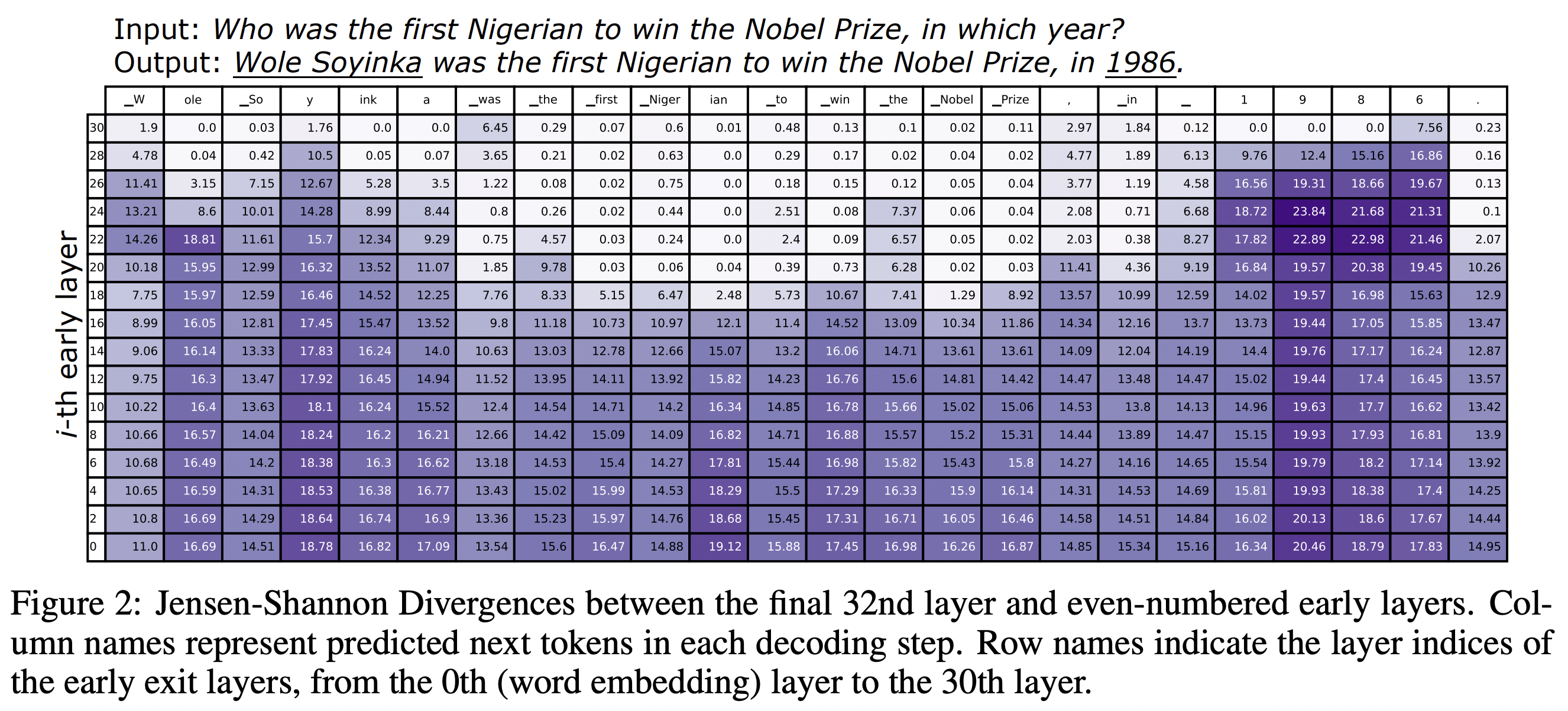
"the first Nigerian"의 경우에는 Input에서도 반복되는 값이기 때문에 비교적 확정적으로 등장하게 된다. (레이어가 높아진다고 해서 값 차이가 크지 않다. 하얀색이 더 많이 보임) 대신에 비교적 지식정보가 사용되는 경우에는 높은 레이어에서도 다양한 토큰들이 올 수 있다.
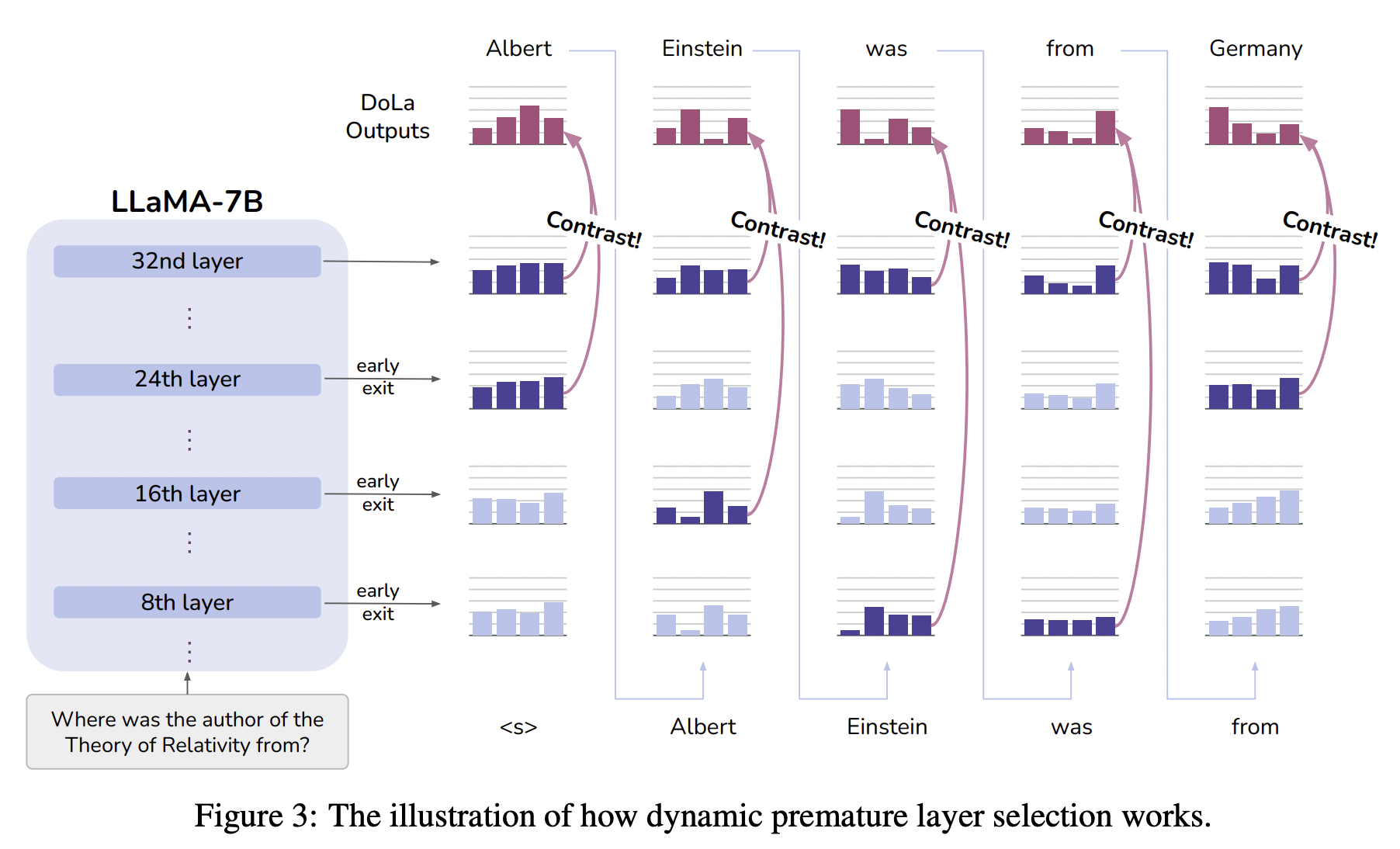
Dynamic Premature Layer Selection
Inference 단계에서 시간을 줄이기 위해서 레이어를 위, 아래 둘로 나누어서 validation set에서 선택한 버킷 안에서만 inference를 진행하도록 한다. 보통 뒤에 위치한 버킷(레이어들로 구성된)이 선택될 것 같지만, 테스크에 따라서 앞에 버킷이 선택되기도 한다. 오히려 짧고 사실에 근거한 답변이 필요한 TruthfulQA의 경우에는 뒤쪽 버킷을 선택했고 답변이 비교적 긴 경우 (FACTOR & GSM8K)에는 앞쪽 버킷을 선택한다. 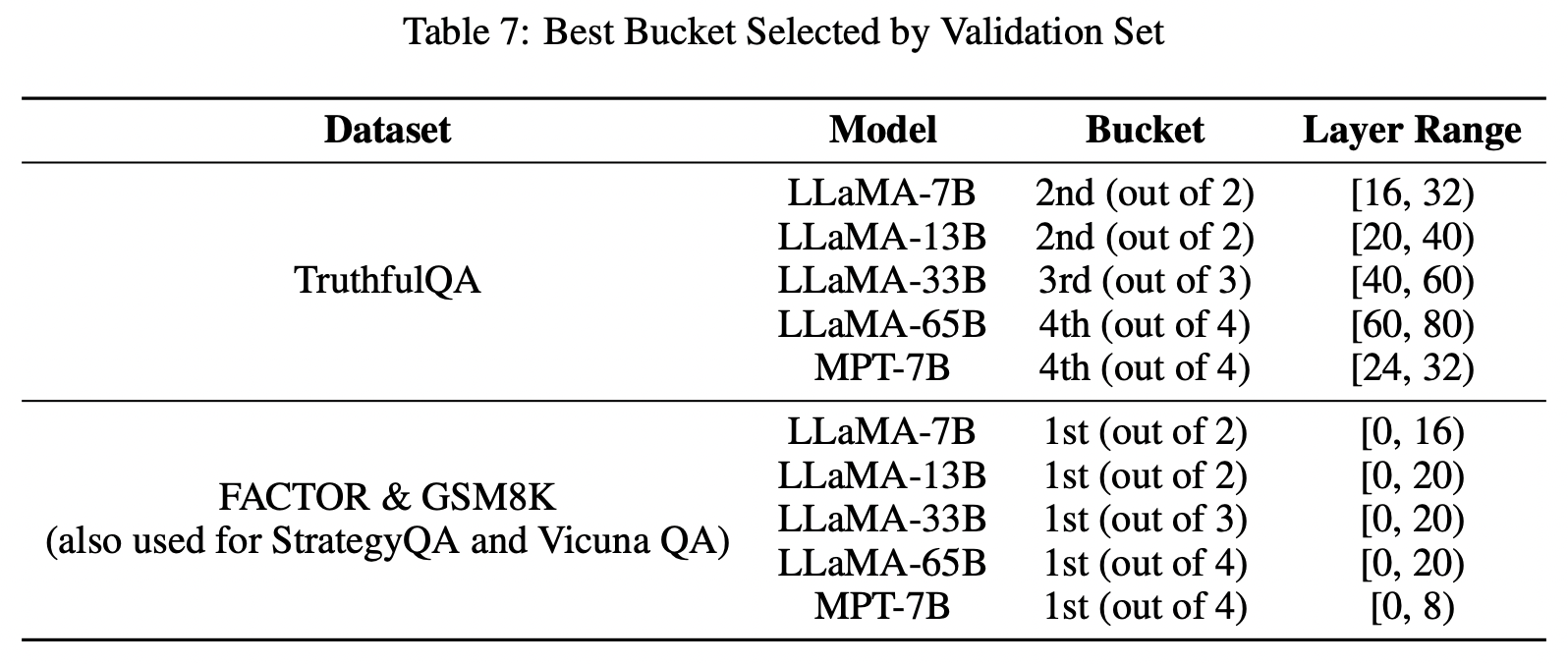
False Positive
Mature Layer에서 로짓이 굉장히 낮은데 Premature Layer에서 로짓이 비교적 높은 경우(그럼에도 Mature보단 낮지만)에는 결과적으로 좋지 않기 때문에 Mature Layer에서 가장 높은 로짓에 알파(여기에서는 0.1)를 곱해서 그보다 낮은 vocab들을 고려대상에서 제외한다.
Latency
근데 이 테이블을 보면 ≈1.683 토큰 갯수가 10개 정도 된다면 1.7배가 되었다.
