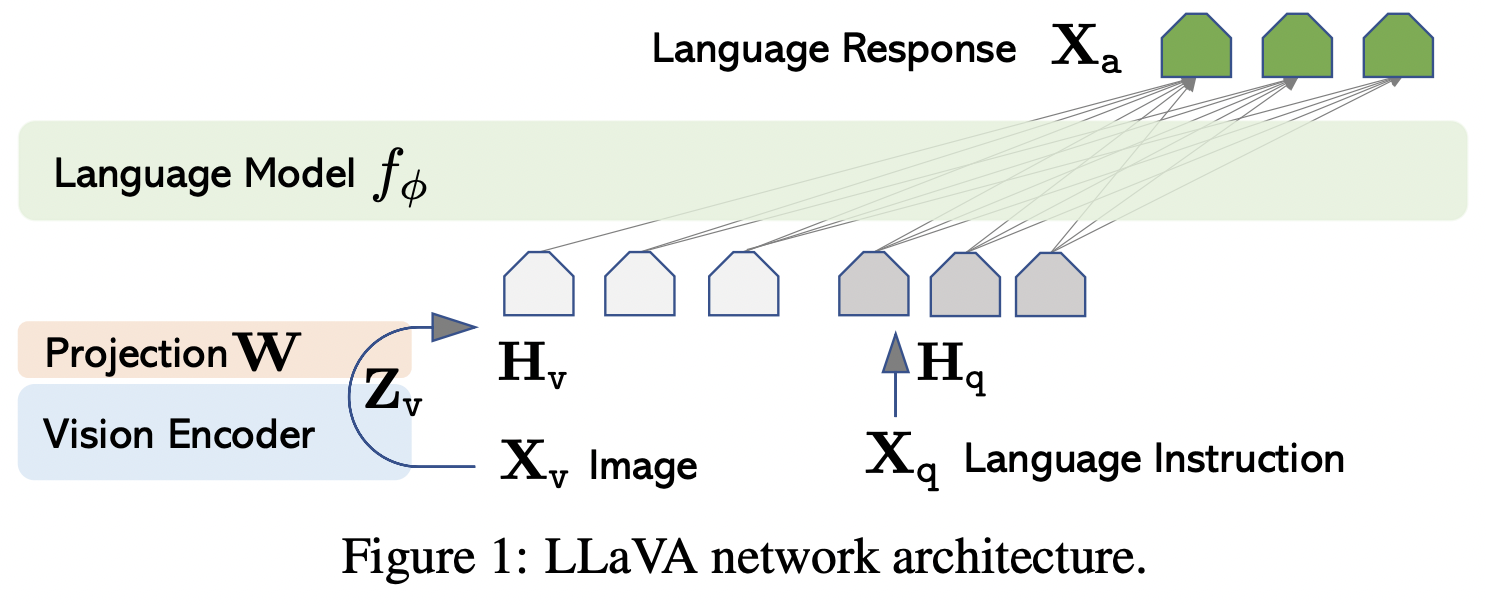
LLaVA: Large Language and Vision Assistant
NIPS 2023 main에 올라간 페이퍼로, LLM을 이용해 language 이해를 넘어 language-vision 동시에 같이 이해하는 GPT-like 멀티모달 LLaVA를 만들었다.
데이터를 만들기 위해서 GPT-4를 사용했으며, 비전 인코더(CLIP ViT-L/14)와 거대언어모델인 Vicuna를 결합한 구조를 가지고 있다. 결과적으로 ScienceQA에서 92.53%로 이 리더보드에서 최고의 성능을 냈다. 오픈소스로 모델과 데이터가 공개되어있다.
https://llava-vl.github.io/ 에서 실제 데모를 진행해볼 수도 있고
다양한 관련자료들을 볼 수 있는데, 아래 그림은 이 사이트에 있는 예시 중 하나이다. 어떤 작품이고 누가 그렸는지, 어떤 의의를 가지고 있는지까지 구체적인 설명들을 잘해주고 있다. 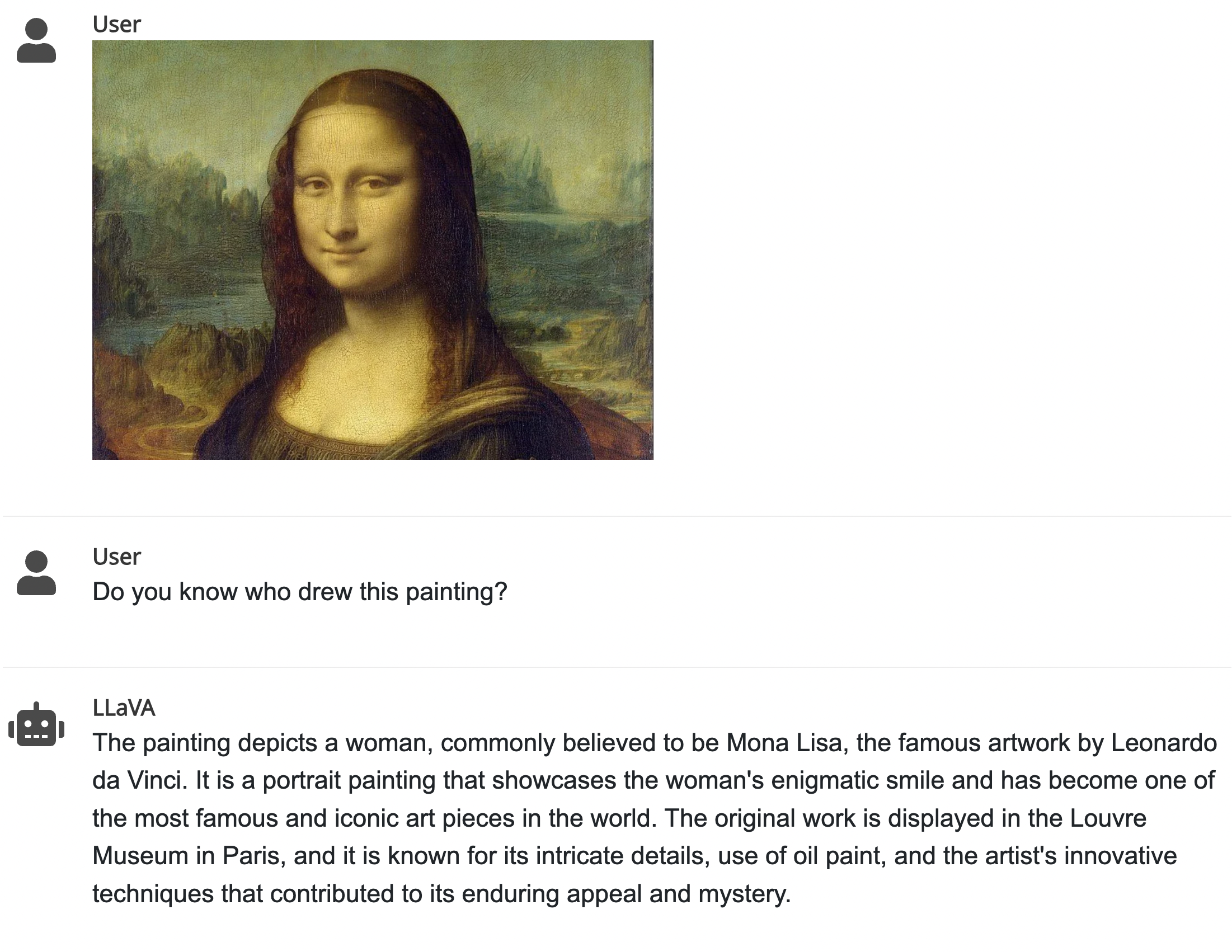
한 단계 더 나아간 버전인 LLaVA-1.5 paper도 공개되었는데 이 부분은 다음에 기회가 더 있다면 다뤄볼 예정이다.
GPT-assisted Visual Instruction Data Generation
그렇다면 GPT-4를 이용해서 우리가 캡션 정보가 있는 이미지를 가지고 있다고 했을 때,
- 어떻게 vision-language pair 데이터를 만들어볼 수 있을까?
- 다양하고 심도있는 추론까지 포함하는 데이터를 생성하려면 어떻게 해야할까?
데이터를 생성하기 위해서 사용하려는 LLM은 기본적으로 언어만 다루기 때문에 이미지 정보를 아래와 같이 captions, bounding boxes 두 개의 표현방식을 사용했다. 이미지 데이터는 COCO images 이다.

이 연구에서는 대화식 구성의 경우, 자세한 설명이 있는 경우, 추론이 포함된 경우로 크게 세 가지의 구성의 데이터를 생성하고자 했다.
대화식 구성(multi-turn)은 이미지에 대한 간단한 정보전달이 주를 이루고, 자세한 설명의 경우(single-turn)에는 위치 정보도 포함된 좀 더 구체적인 설명이 들어가 있다. 마지막으로 추론 질문이 있는 경우(single-turn)는 사진에서 사람들이 어떤 어려움을 겪을 수 있냐고 물어보는 식으로 좀 더 깊이있는 설명이 나오도록 한 것을 볼 수 있다.
프롬프트를 통해서 세팅을 설명하고 응답타입에 따라서 질문부터 스스로 만들어보라는 식으로 데이터를 생성했다.
이렇게 생성한 데이터는 LLaVA를 학습할 때에 finetuning 데이터로 사용된다.

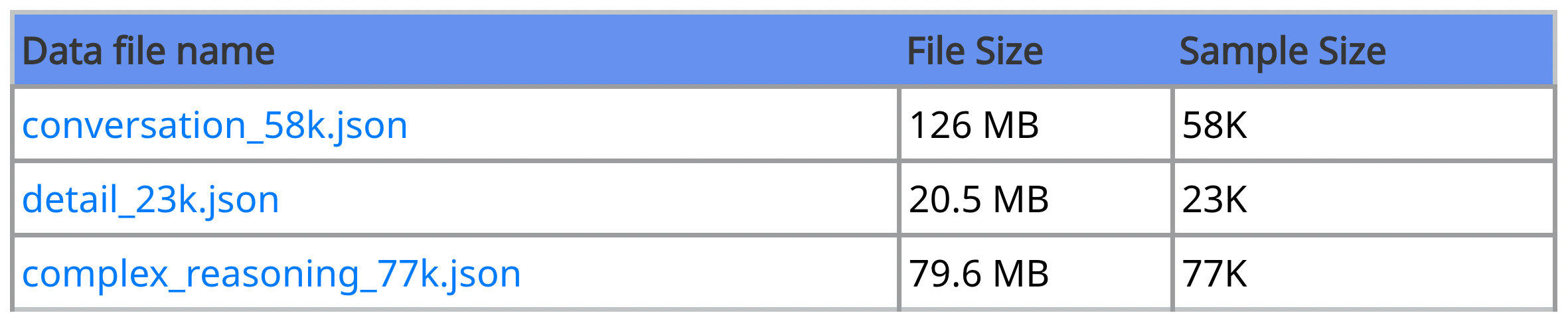
총 158K의 language-image instruction-following 데이터를 생성했는데, 아래와 같이 세 가지 구성에 따라 구분된 데이터가 현재 공개되어있다. (https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K)
Visual Instruction Tuning
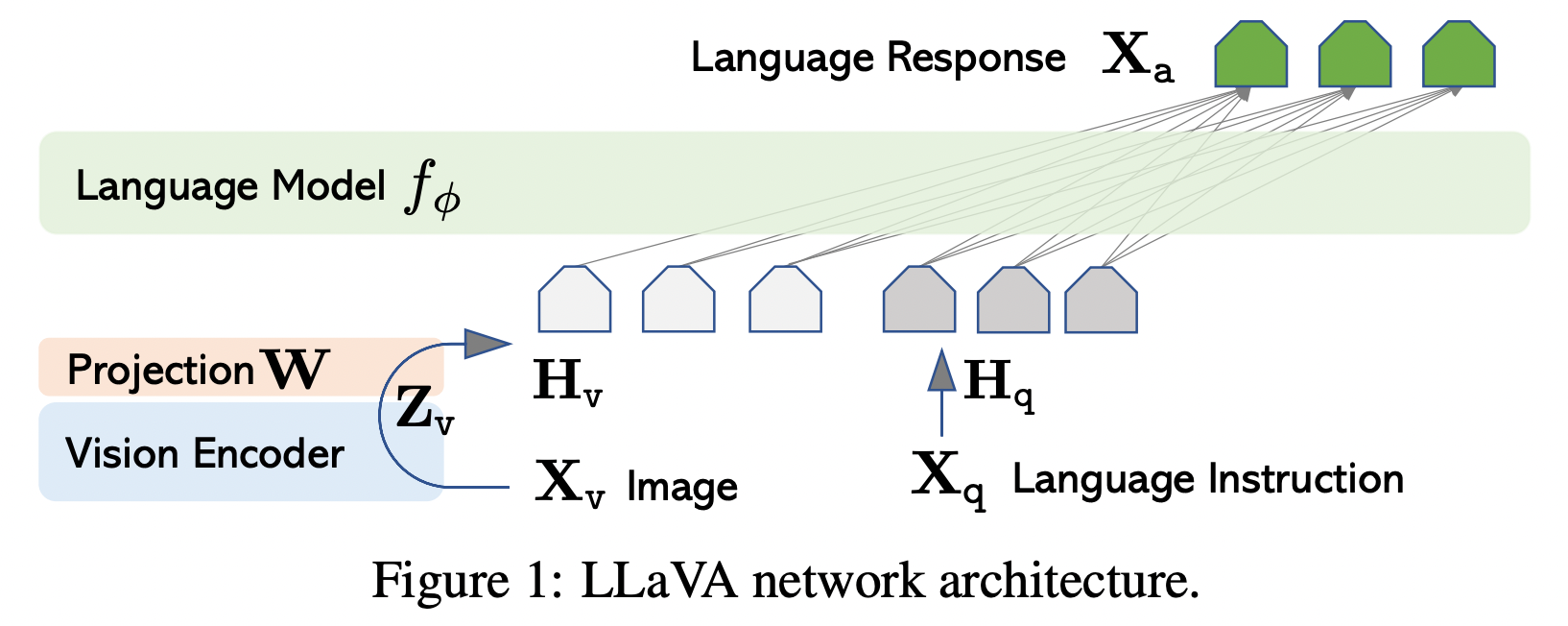
이 연구에서 가장 하고싶은 것은 기존에 잘 만들어진 LLM과 이미지 모델을 이용해서 instruction을 반영할 수 있는 모델을 만드는 것이다. LLaVA 가장 초기버전인 이 연구에서는 비전 인코더모델은 CLIP ViT-L/14(OpenAI, contrastive learning을 결합한 captioning model), LLM으로는 LLaMA를 사용하였다. (LLaVA-1.5에서는 LLM을 Vicuna로 사용했다.)
( 아니 근데 알고보니 라마, 알파카, 비쿠냐는 낙타류의 비슷하게 생긴 목이 긴 동물들이라고 한다. 라마는 그 중 가장 거칠고 크고 혹시라도 꼬리를 만지면 바로 공격하는 동물이라고 한다. 비쿠냐는 조금 더 고급스럽게 생겼는데, 가둬놓고 키우지 못해서 실제로 털 가격이 굉장히 비싸다고 한다. )
라마는 메타에서 만들어 오픈소스로 공개한 모델로 7B, 13B, 33B, 65B모델까지 있다. 이 중 비교적 작은 7B모델로 스탠포드 연구자들이 공개한 모델이 알파카이다. 알파카는 경량화 관련한 이슈로 이후에 많이 등장하는 것 같다. 비쿠나는 7B, 13B 모델을 이용해서 만들어졌는데, 13B 모델이 ChatGPT와 거의 비슷한 좋은 성능을 보이는 모델이라고 한다. 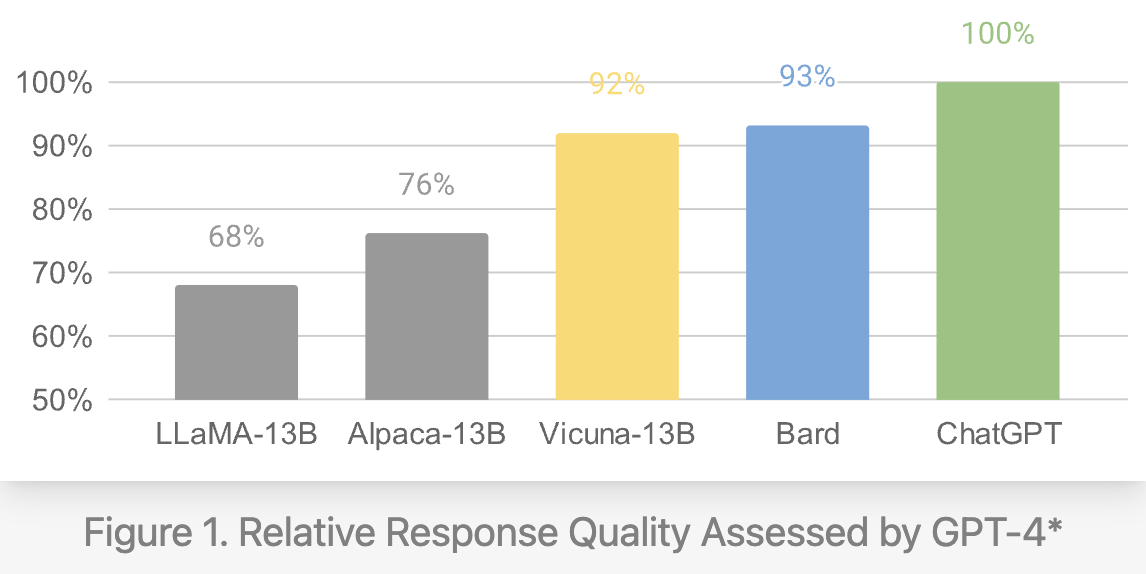
Two stages for LLaVA training
LLaVA는 두 단계 구성을 가지는데,
첫 번째 단계는 CC3M 데이터를 이용해서 projection layer만을 학습시키는 단계이다. 이 과정은 vision-language aligning을 목표로 한다. (CC3M 데이터는 이미지와 캡션으로 구성된 3백만개의 데이터이다.)
두 번째 단계에서는 비전 인코더만 웨이트를 고정해놓고 위에서 학습한 projection layer와 LLM을 학습한다. 여기에서는 일반적인 language-vision chatbot, ScienceQA를 잘하기 위한 모델을 만든다. Multimodal chatbot을 만들기 위해서 위에서 만든 158K language-image instruction-following data를 학습하며 ScienceQA 벤치마크를 위해서는 데이터를 single-turn 데이터로 보고 학습을 진행한다.
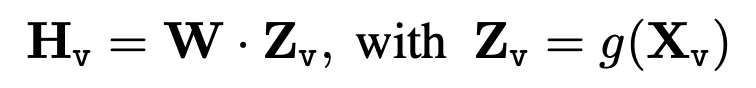
(추가) 첫 번째 단계에서 CC3M 데이터를 학습하기 전에 한번 필터링을 진행하는데, SpaCy로 명사구를 뽑아 해당 명사구의 빈도에 따라 필터링을 진행했다고 한다. 필터링 과정을 통해서 3백만개의 데이터 중 595K만을 남겨서 사용했다.
결과 예제를 보았을 때 BLIP-2, OpenFlamingo의 경우에는 단순히 이미지를 설명하는데에 그친다면 LLaVA(multimodal chatbot)의 경우 instruction은 좀 더 반영한 답변을 해준다고 볼 수 있다. (GPT-4와도 좀 더 비슷하게 답변을 해준다.)

Experiments
Multimodal chatbot의 결과를 GPT-4를 통해서 만들었다.
Evaluation set(30개, 3가지 이므로 총 90개의 예제)의 캡션과 바운딩 박스를 이용해 LLaVA의 결과, GPT-4의 결과(an upper bound)를 만든다. GPT-4를 이용해서 응답의 유용성, 관련성, 정확성, 그리고 세부 사항의 수준을 평가하고, 1에서 10점의 척도로 전반적인 점수를 매긴다. 추가적으로 해당 평가에 대한 설명을 주도록 하였다.
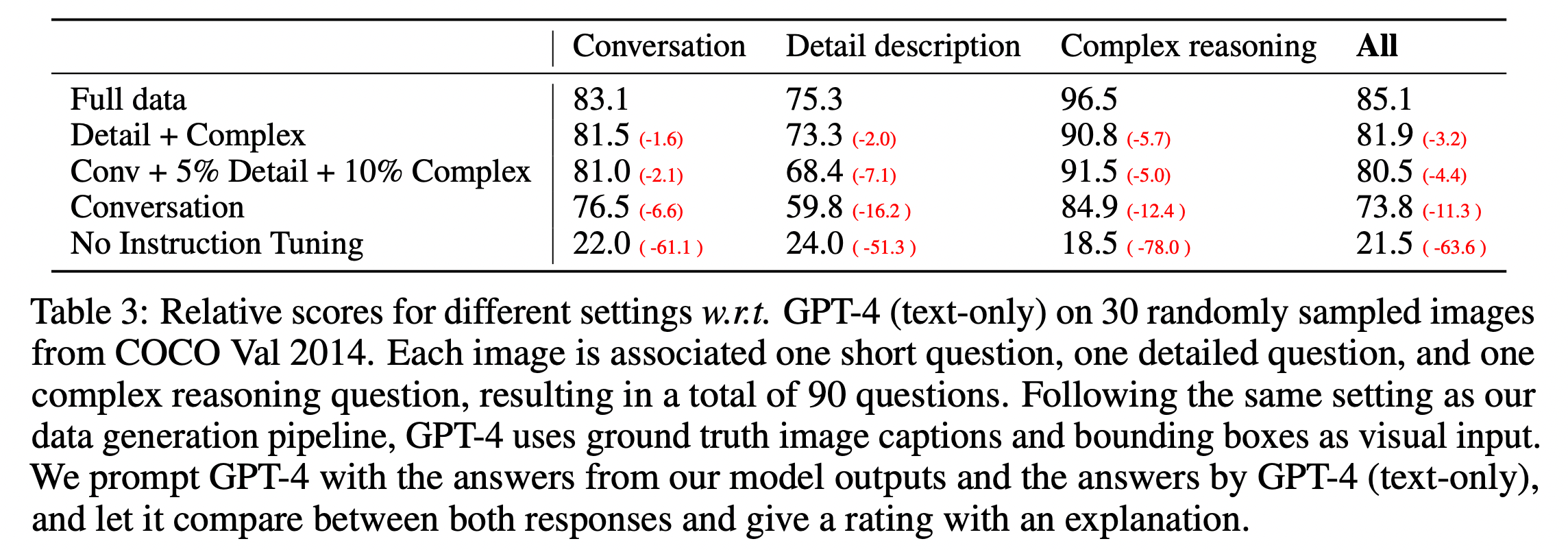
No instruction tuning과 비교했을 때, 전체 데이터를 학습했을 경우가 확연하게 점수 차이가 나는 것을 확인할 수 있다(50점 이상). 데이터 generation을 세 가지로 진행하였는데, 확실히 conversation보다 detail+complex가 더 좋고 보다 더 좋은 것은 모든 데이터를 추가했을 때이다. 눈여겨볼 부분은 conversation에서 조금의 detail, complex 데이터를 추가하는 것 만으로도 점수가 크게 향상(7점)된다는 점이다.
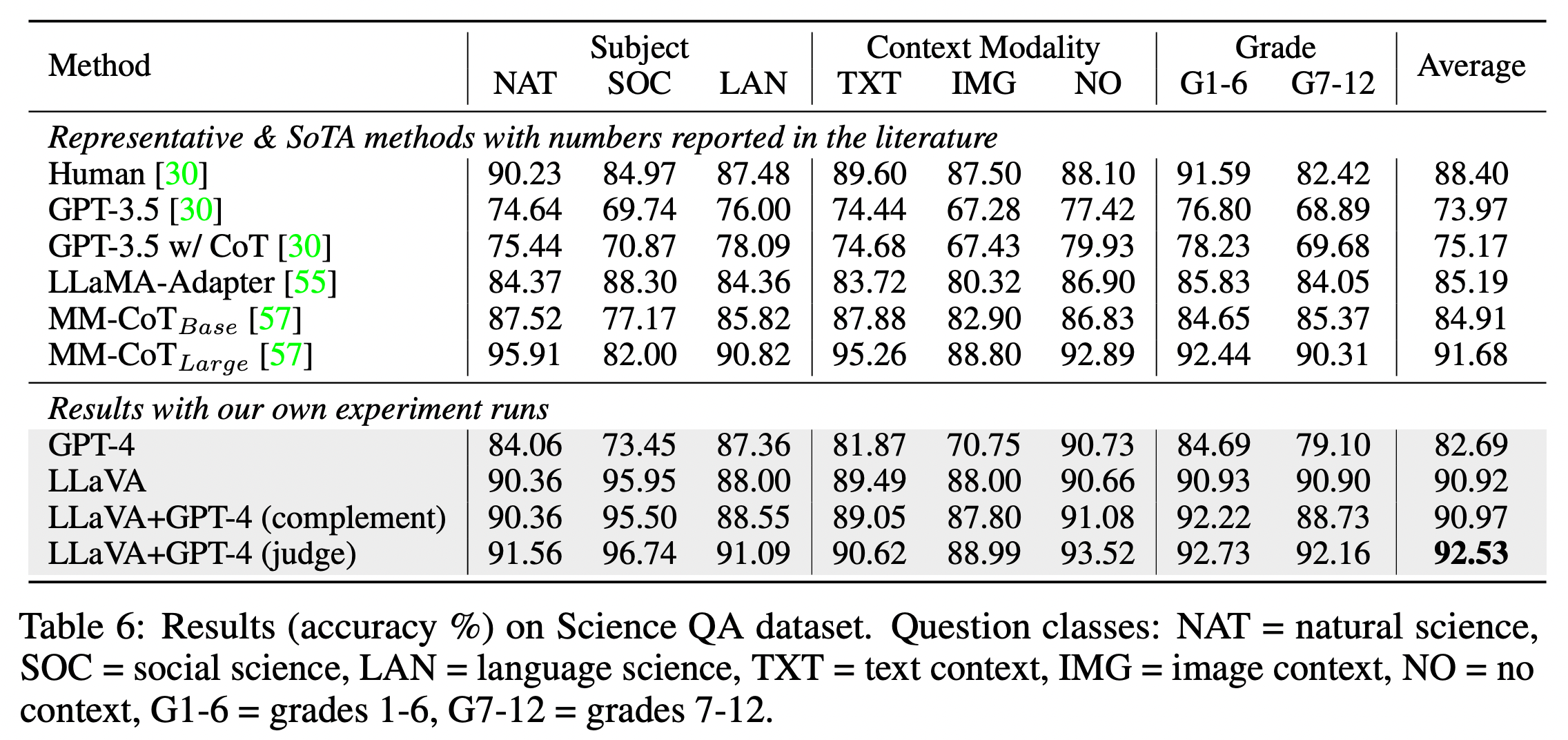
ScienceQA 벤치마크는 natural science, language science, and social science를 기준으로 각각 하위주제를 가지고
있는 multimodal multiple-choice 데이터셋이다. 이 벤치마크 데이터셋은 각각 12,726(train), 4,241(dev) 및 4,241(test)개의 예제로 그림과 텍스트가 같이 포함된 질문-답변 셋이다. (예제는 https://scienceqa.github.io/explore.html 에서 확인할 수 있다.)
아래 결과표에서 LLaVA의 점수는 90.92라고 보면된다. GPT-4와 같이 결과를 내면서 최종적으로 성능을 92.53까지 올리기는 했는데, complement는 GPT-4에서 결과를 주지 못할 때의 LLaVA의 결과를 사용한 것을 말하고, judge의 경우는 두 모델의 결과가 다를 때 GPT-4가 판단해서 최종적인 결과를 생성하도록 하는 방식이다.
Instruction tuning을 multimodal space까지 확장시켰다는 점에서 의미가 있는 논문이다.
