Funnel-Transformer : Filtering out Sequential Redundancy for Efficient Language Processing
NLP Papers
목록 보기
10/33
- NeurIPS 2020, CMU와 구글 브레인에서 나온 논문
- Hourglass (Hierarchical Transformers Are More Efficient Language Models) 모델을 보다보니, 이 논문을 짚고 넘어가야할 것 같아서 보게 되었음.
- 이 논문에서는 한 문장을 그 문장을 구성하는 전체 토큰 길이의 벡터로 표현한다는 것이 중복 문제를 가진다고 본다. (much-overlooked redundancy)
- Funnel-Transformer 사용해서 해당 시퀀스 표현 벡터를 점진적으로 줄여나가는 것이 계산량을 줄이면서 기존 Transformer 만큼의, 그 이상의 점수를 보여주었다.
- 분류문제처럼 하나의 벡터로 문제를 해결하고자 하는 경우는, 파인튜닝 과정에서 해당 벡터표현의 중복되는 부분을 없애고 하나의 벡터로 의미를 잘 만드는 문제라고도 볼 수 있다.
- 이 논문에서는 아래 질문을 중심으로 모델을 디자인했다.
- 의미 벡터를 잘 압축해서 더 효과적인 모델을 일반적으로 적용가능하게 만들 수 있을까?
- 어떻게 사전훈련된 모델의 의미들을 잘 보존할 수 있을까?
Funnel-Transformer
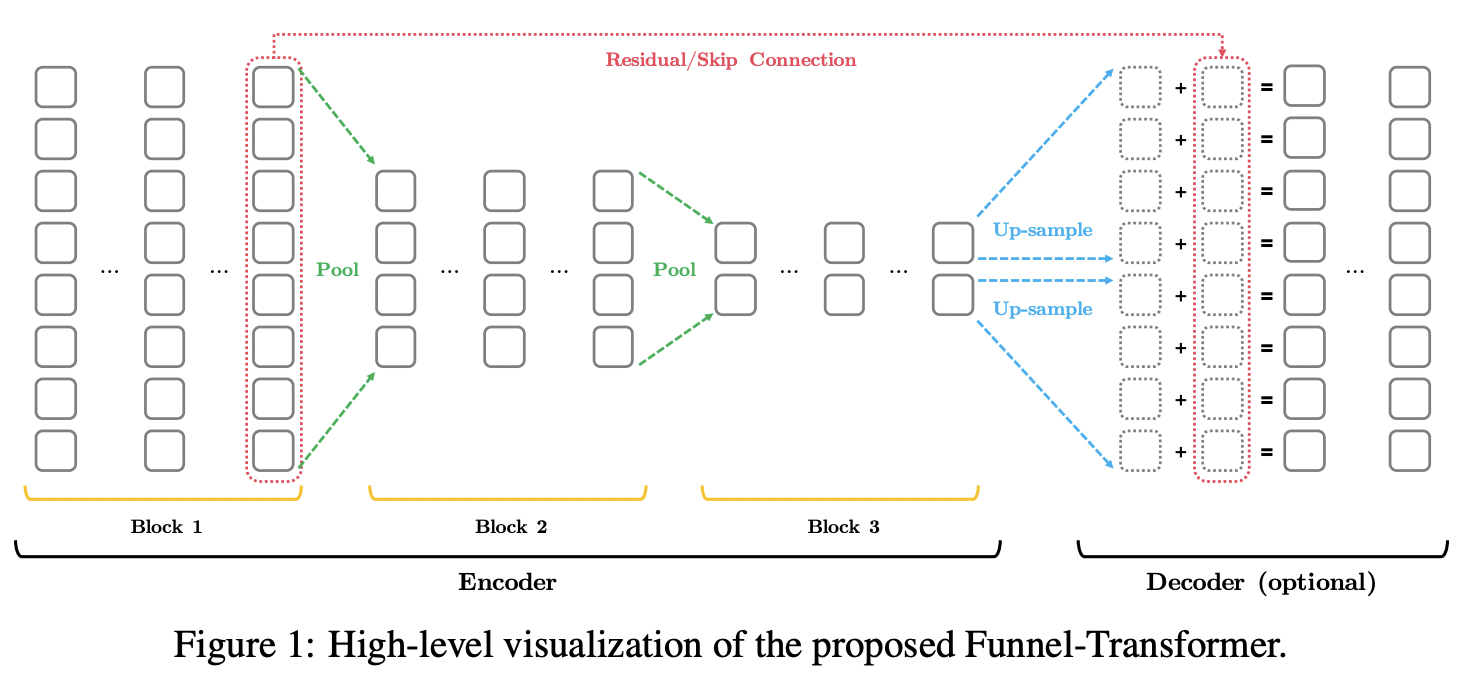
- 의미표현을 잘 압축하기 위해서 점진적으로 hidden vector 크기를 줄이는 방식을 사용했다.
- 각 토큰이 특정 확률을 가지게 하는 테스크에 대해서는 간단한 디코더를 사용했다.
Encoder
- 각 블록 안에서 시퀀스(hidden vector) 크기는 동일하다.
- 블록 간 이동 시에서는 풀링방법을 사용해서 시쿼스 크기를 줄인다. ( -> )
- Q에 들어가는 와, KV에 들어가는 는 시퀀스 트기가 다르다. (residual은 )
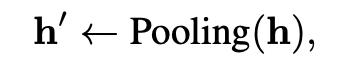
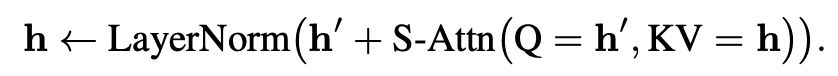
- output sequence size?
- "pool-query-only" variant vs for both the query and key-value vectors
- 일반적인 접근(오른쪽)으로 본다면, 의미표현의 압축은 오직 풀링을 통해서만 이루어지게 된다.
- "pool-query-only" 방법(왼쪽)으로는, 압축은 풀링이 어떻게 진행되는가도 영향을 미치지만, unpooled 시퀀스와 pooled 시퀀스의 셀프어텐션으로도 의미표현의 압축이 진행된다. (more expressive)
- Pooling : the simplest strided mean pooling
- stride 2, window size 2
- 이렇게 풀링진행하면 시퀀스길이를 절반으로 줄인다.
- 근처의 토큰이 점진적으로 합쳐져서 큰 의미적인 요소를 이룬다는 언어적인 가정과도 어울리는 방식이다.
- [CLS]
- [CLS] 토큰을 빼고 진행한 후에, 가장 마지막 레이어 결과에 맨 앞에 붙이는 방식으로 진행했다.
- pooling에는 영향을 미치지 않도록 하기 위함이다.
Abalation
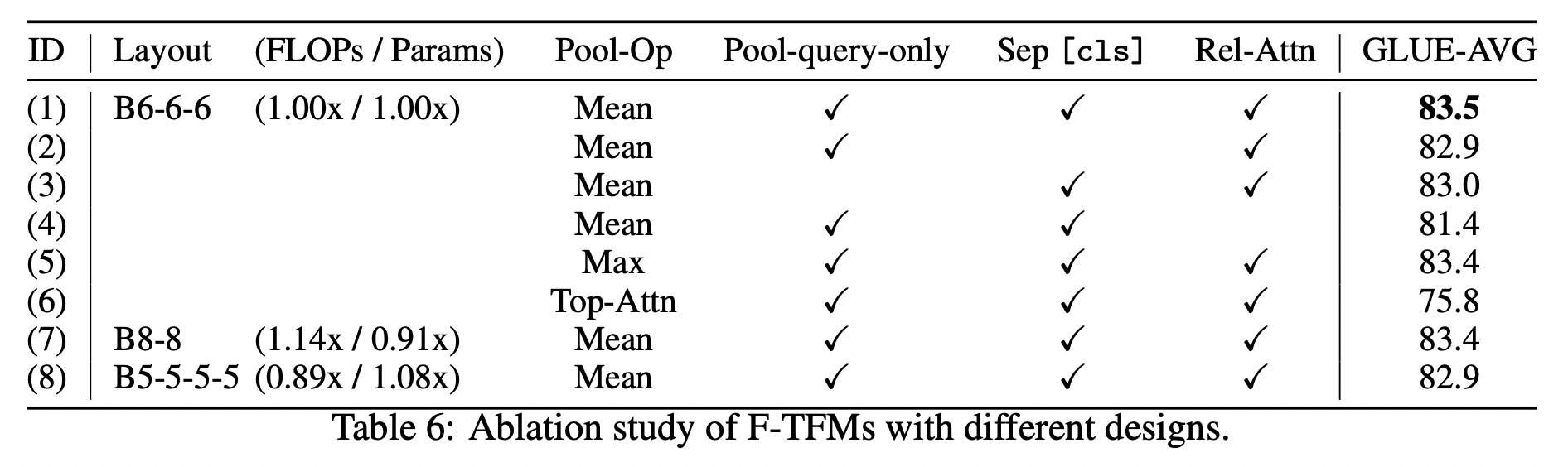
- Pooling operation
- 1(Mean), 5(Max), 6(Top-Attn) 비교 시 Mean 가장 좋음.
- Separate [CLS] in pooling operation
- 1, 2를 비교했을 때 사용하는 것이 점수가 0.6 높다.
- Pool-query-only
- 1, 3을 비교해보면 1의 경우 0.5 더 높다.
- Transformer-XL의 Relative attention
- 1, 4 비교 시 점수가 큰 폭으로 높다.
- Funnel-transformer에서 가장 중요한 요인으로 여겨질 정도이다.
- 이유는? (같이 토론해보기)
- Block layout design
- 3 block 디자인을 사용했다.
- 2 block 디자인과는 점수차가 거의 나지 않지만, FLOPs 늘어난다.
- 4 block 경우, 점수가 낮아진다.
Decoder
- A single up-sampling (그림 파란 부분)
- 벡터표현을 업샘플링시키면 토큰 단위의 정보를 알맞게 포함하기 어려우므로 이 점을 보완하기 위해서 더해주었다. (residual/skip connection)
- 2 Transformer layers
- token-level prediction 필요한 테스크에 대해서만 디코더를 사용하였다. (그렇지 않은 경우에는 아예 디코더를 사용하지 않음!)
Complexity & Capacity Analysis
- L12H768(BERT base) 대응되는 모델로 B6-6-6H768 제시한다.
- 제시하는 모델은 레이어를 총 열 여덟 개를 가진다.
- 하지만 이 아키텍쳐의 경우 6 + 6/2 + 6/4 = 10.5 만큼의 연산을 하기 때문에 L12H768 보다 적은 연산량을 가지고 있다.
- B6-6-6H768 성능이 L12H768 보다 좋다.
- B6-6-6H768은 트랜스포머 기준 대비 1.5배의 파라미터를 가진다.
- 각 단위 내의 두 번째, 세 번째 블록을 ALBERT와 같이 묶어서도 진행해보았지만
(B6-3x2-3x2H768) 성능이 좋아지지는 않았다.
- 각 단위 내의 두 번째, 세 번째 블록을 ALBERT와 같이 묶어서도 진행해보았지만
Experiment
- Base scale
- 256 batch size, 백 만 스텝 학습한 사전학습 언어모델
- Wikipedia, Book Corpus (as original BERT)
- Large scale
- 8000 batch size, 50만 스텝,
- Wikipedia, Book Corpus, ClueWeb, Gigaword, Common Crawl (XLNet, ELECTRA)
- Finetuning
- 시퀀스 단위 테스크에 초첨을 맞췄다. (a single vectorial representation)
- the GLUE benchmark
- classification tasks (IMDB, AD, DBpedia, Yelp-2, Yelp-5, Amazon-2, Amazon-5)
- the RACE reading comprehension dataset
- 추가로 the SQuAD question answering task 로도 확인함
- 시퀀스 단위 테스크에 초첨을 맞췄다. (a single vectorial representation)
- Relative positional attention parameterization (Transformer-XL)
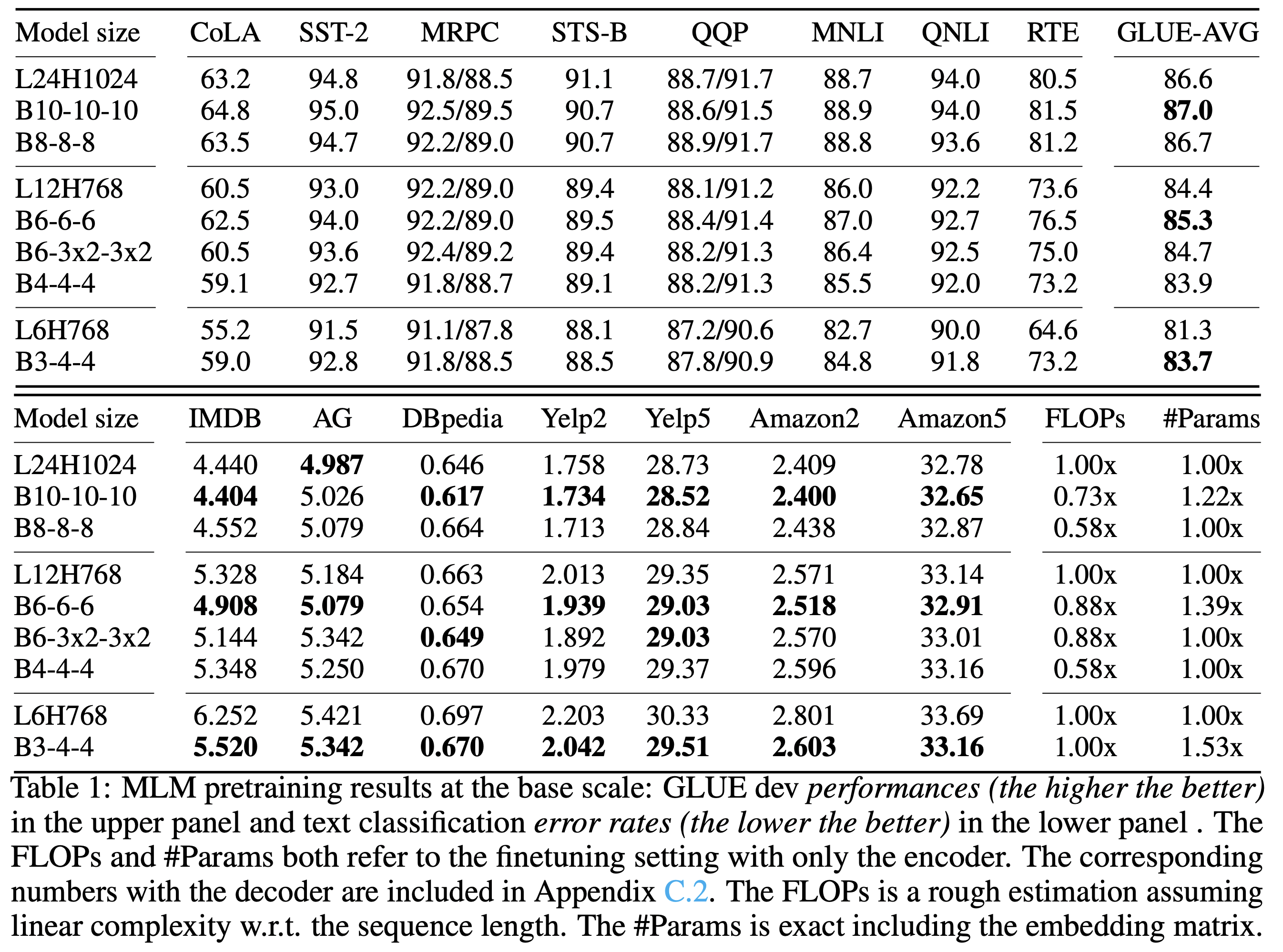
Base-scale Results
-
BERT settings
- L24H1024 (large), L12H768 (base), L6H768 (small)
- 기본적으로 세 블록을 가지는 구성을 취함. (FLOPs, #Params)
- STS-B는 그렇게 점수가 높아지지 않음.
- parameter sharing 별로 도움이 되지 않는다.
-
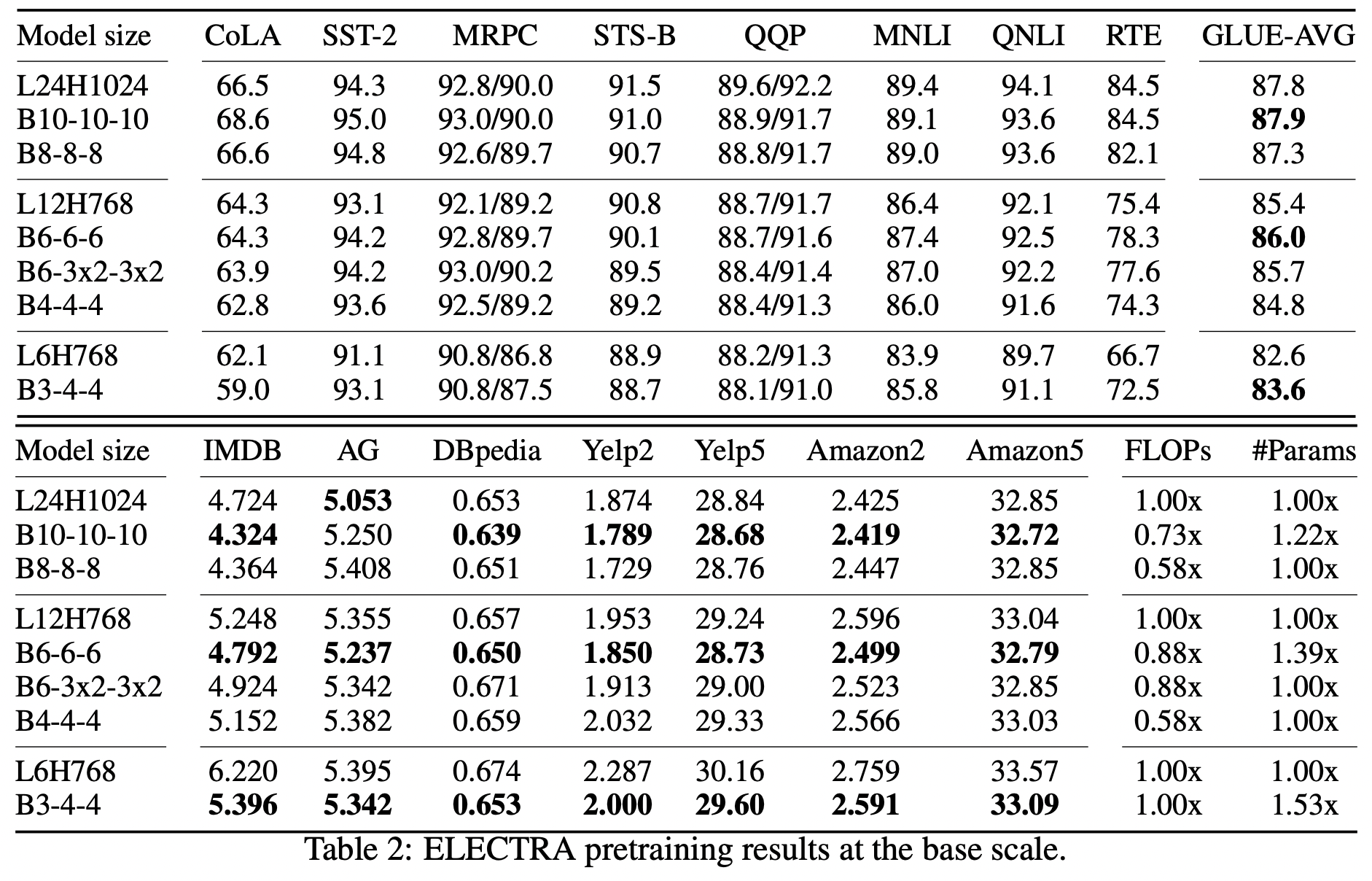
일반성을 확인하기 위해서 ELECTRA 기준으로도 테스트 진행
-
조금씩 점수가 오르기는 했지만 위보다 더 적은 점수차를 보임.
-
ELECTRA 사용한 수치를 그대로 사용함.
- Discriminator loss coefficient 50, 1/4 Generator size
- Funnel-Transformer를 discriminator, generator에 둘 다 적용했다.
-
해당 논문에는 ELECTRA base 훈련 시에는 span word masking 실험결과가 좋지 않아 베이스 모델의 경우 single-token sampling 적용했다고 한다.
-
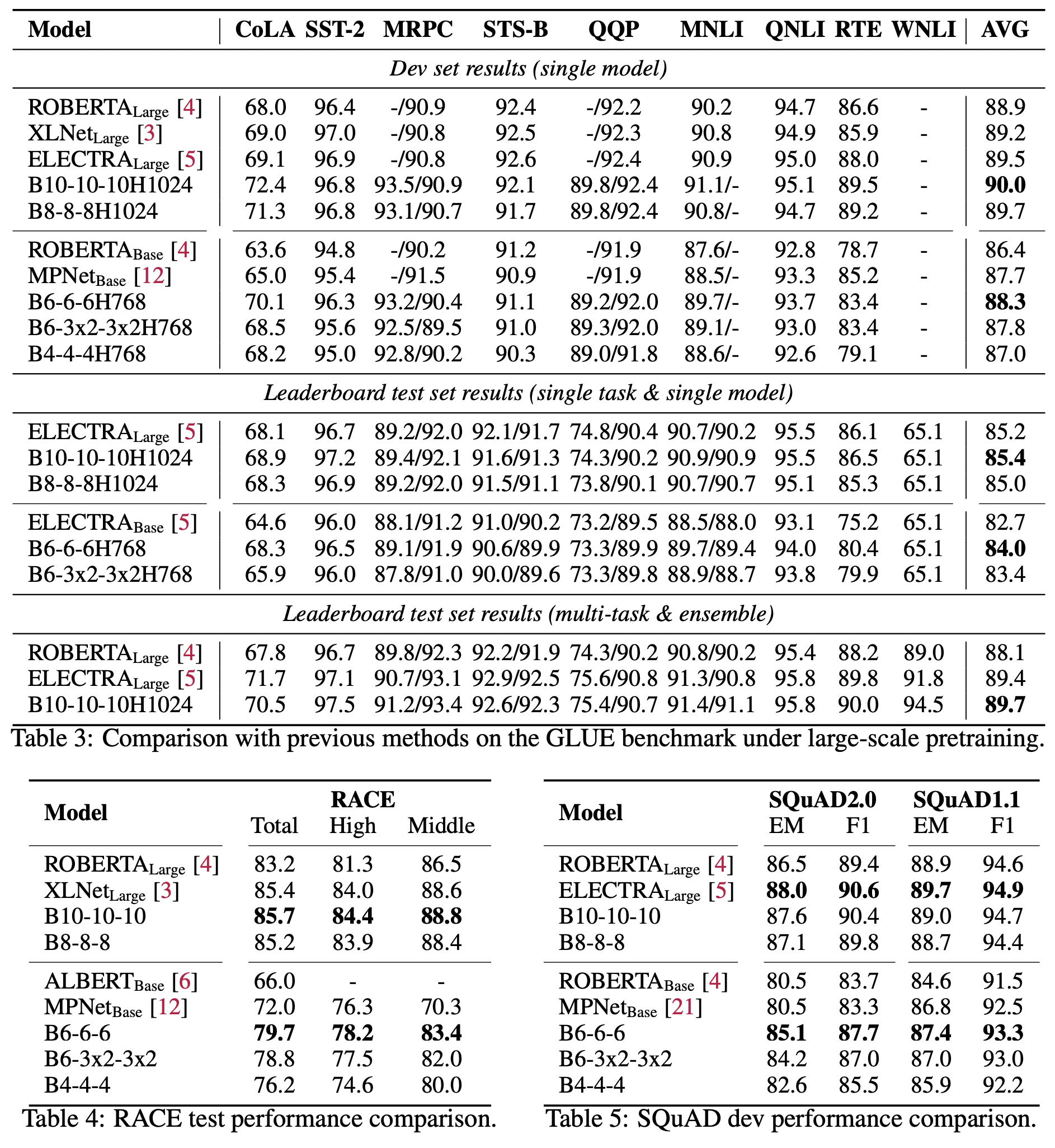
Large-scale Results
- 앞에서 제시한 수치와 비슷한 양상의 결과를 보여준다.

산미 있는 커피를 좋아하는 자연어처리 엔지니어. 일상 속에서 요가와 따릉이
를 좋아합니다. 인간의 언어를 이해하고 생성하는 AI 기술 발전을 위해 노력하고 있습니다. 🧘♀️🚲☕️💻