ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
NLP Papers
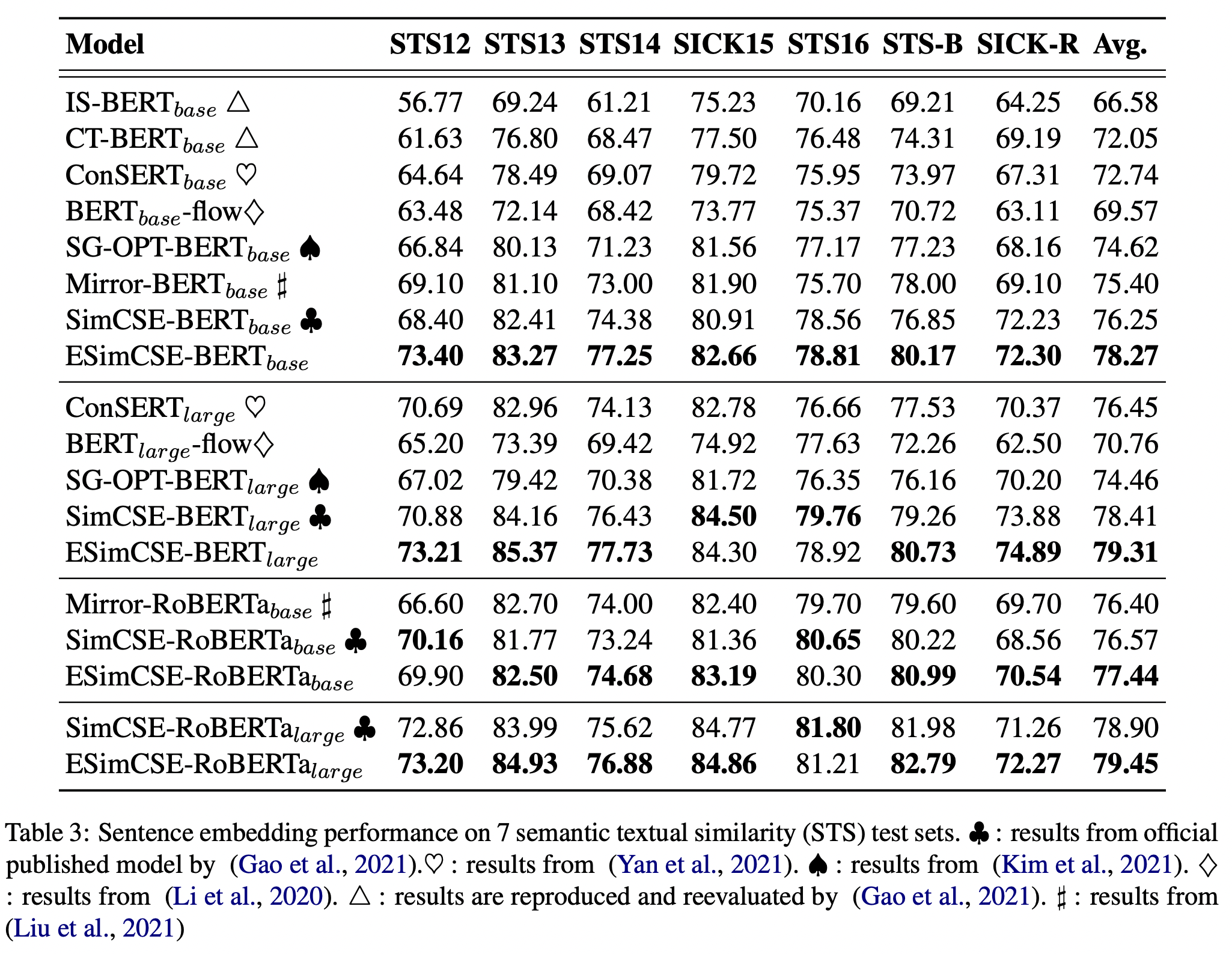
Unsupervised sentence embedding STS task scores
SimCSE 이후로 Sentence embedding 관련 연구들이 있었는데 BERT-base 기준으로 나온 스코어들을 비교해보면, 78점을 넘은 것은 DiffCSE, ESimCSE, PCL 정도가 있다.
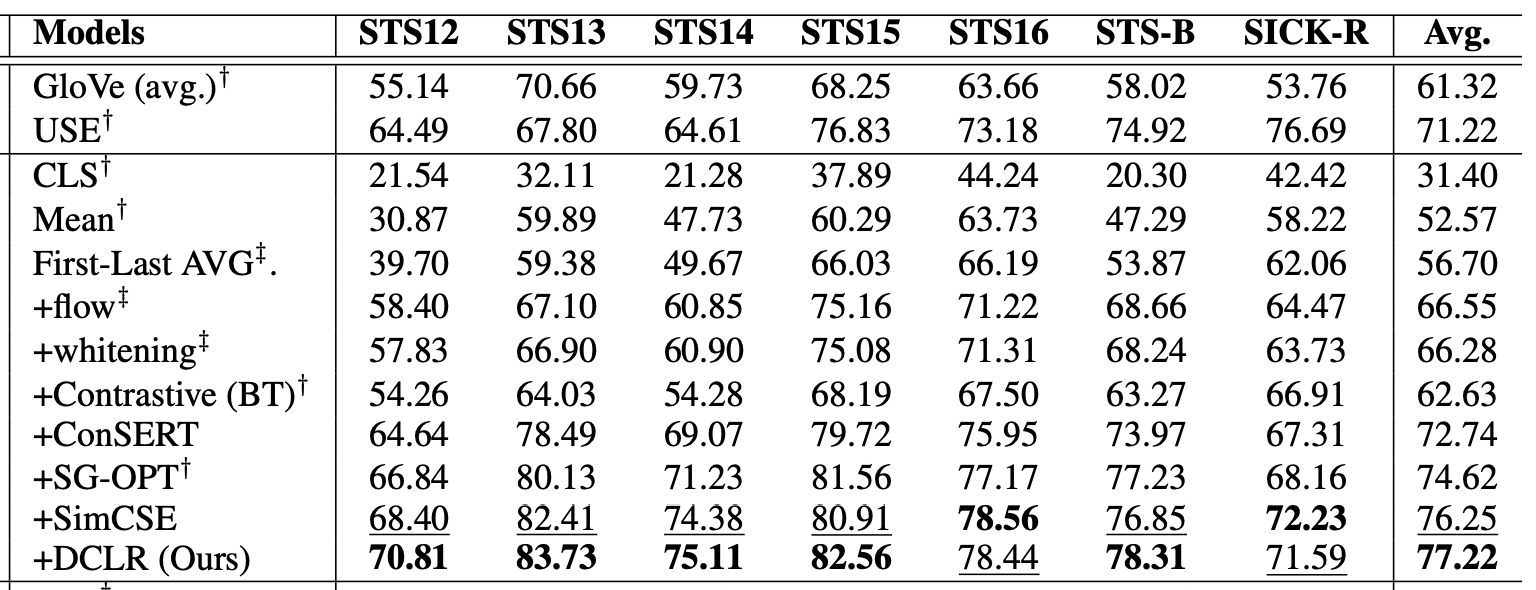



이 중에서 오늘 알아볼 논문은 ESimCSE이다. Sentence embedding 논문으로 COLING 2022 게재되었다.
이 논문은 SimCSE를 baseline으로 삼고 있으며 기존 방법에서 positive pair, negative pair를 더 최적화하는 방식으로 word repetition, momentum contrast를 사용하고 있다.
- SimCSE가 기존 문장과 positive pair(dropout 적용)는 같은 length information을 가지고 있고, negative pair는 그렇지 않아서 이런 length information이 이 둘을 구분하는데에 영향을 미칠 수 있다(biased).
- Contrastive learning에서 negative pair 더 많이 넣을수록 좋아지는데, GPU 메모리 한계가 있을 때에는 이걸 사용하지 못한다.
결과를 살짝 먼저 보면, STS 여러 테스크들 중 STS-B dev set 기준으로 보면 두 방법이 각각 성능 향상을 보여주고 있고 결합되었을 때에 +2.4 정도만큼 점수를 올려주고 있다. 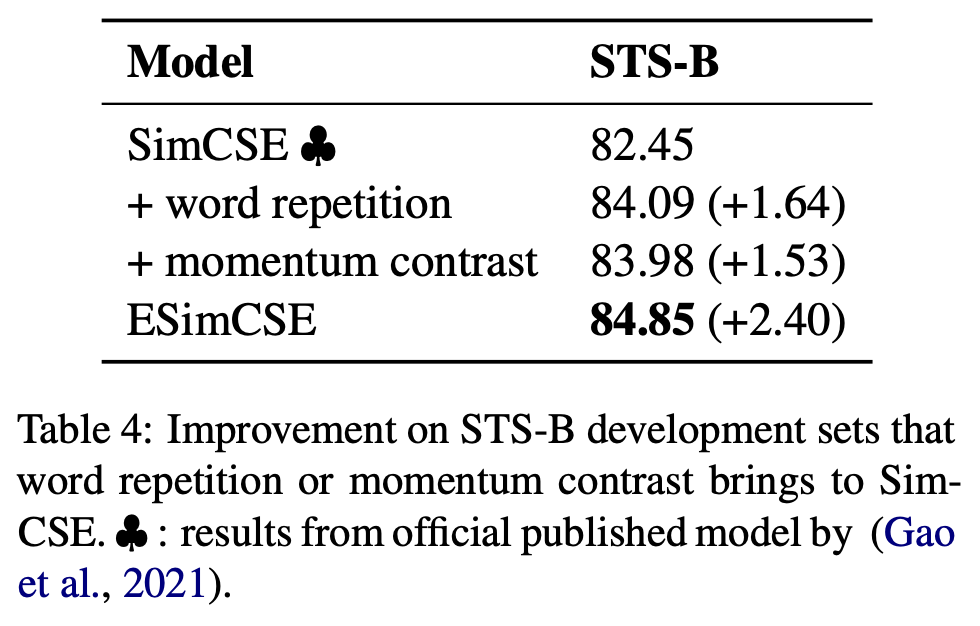
Data augmentaion
기존 SimCSE에서는 dropout을 이용해 성공적으로 positive pair를 생성했는데, SimCSE와는 다르게 positive pair를 만들 때에 물리적인 시퀀스 길이를 다르게 만들어주기 위해서 Word repetion을 사용하였다.

Random insertion, deletion의 경우 위 표에서 유사도가 아예 달라질 수 있는 것처럼 오히려 의미 왜곡을 시킬 수 있는 단점이 있지만 repetition의 경우 의미가 왜곡될 가능성을 비교적 줄이기 때문에 사용되었다.
실제로 간단한 예시를 보면,
- q = “I like this apple because it looks very fresh”
- s1 = “This is a very tall tree and it looks like a giant” (13-17% overlap)
- s2 = “This this is a very very tall tree and it looks looks like a giant.” (word repetition)
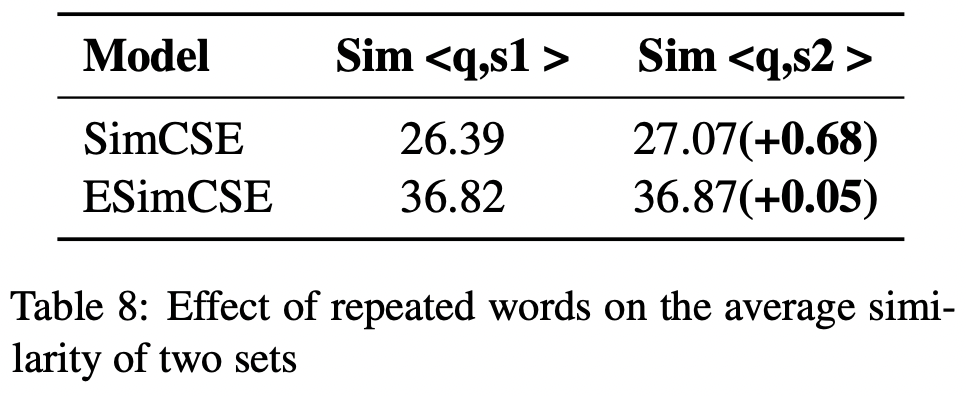
s1과 s2는 이 연구에서는 같은 의미를 가지는 문장이고, q가 이 둘을 바라볼 때에 similarity 수치가 거의 비슷하게 나와야한다는 것이 일반적인 생각이다. 의도대로 ESimCSE가 이 부분은 잘 수행하고 있다. (수치차이가 비교적 더 적음)
실제로 이 논문에서는 sub-word repetition이 사용되었는데, word repetition (토크나이즈 하기 전 기준으로 반복)보다 0.45 높은 성능을 보였기 때문이다.
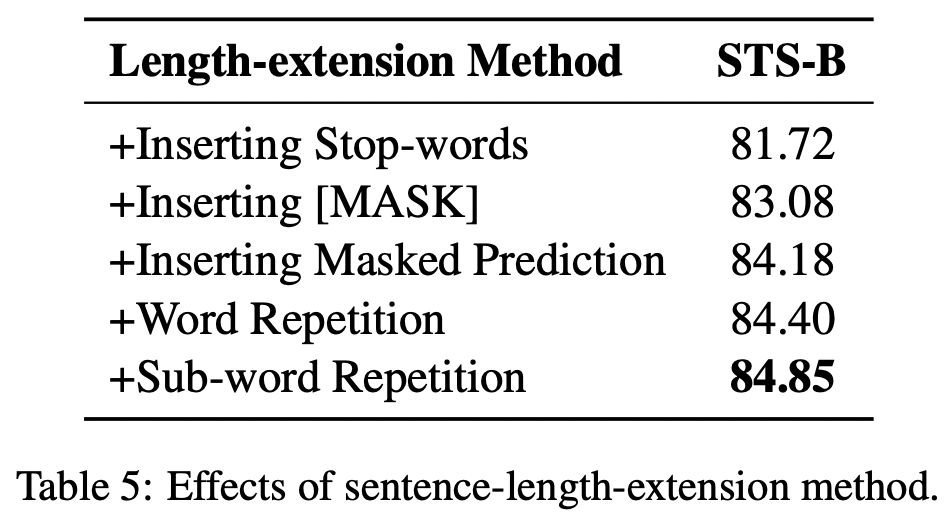 이 테이블을 보면 SimCSE 점수가 82.45인 것을 고려해볼 때 stop-words 넣었을 때에는 오히려 성능 저하가 있었고, 마스크 토큰을 넣거나 오히려 MLM(Masked language model)을 추가했을 때에는 성능이 일정 부분 올랐다는 것을 보여준다.
이 테이블을 보면 SimCSE 점수가 82.45인 것을 고려해볼 때 stop-words 넣었을 때에는 오히려 성능 저하가 있었고, 마스크 토큰을 넣거나 오히려 MLM(Masked language model)을 추가했을 때에는 성능이 일정 부분 올랐다는 것을 보여준다.
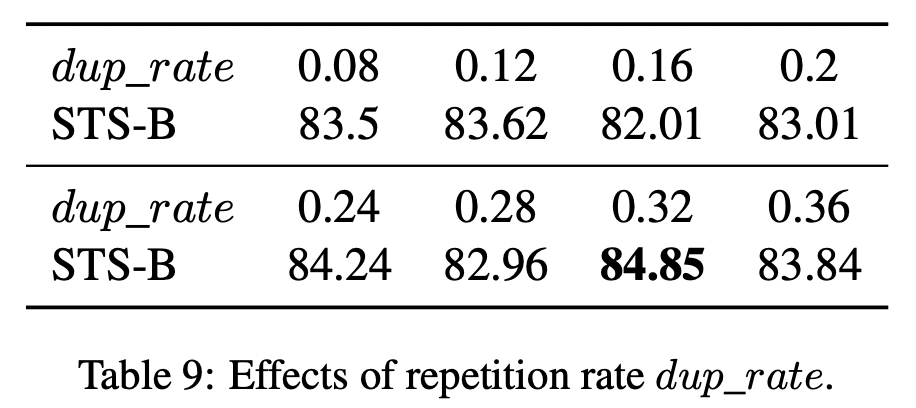
디테일하게는 아래 수식에 따라 dup_len을 구해서 해당 부분만큼 uniform 분포에 따라 랜덤하게 반복할 토큰을 정하였다. dup_rate은 하이퍼파라미터로 아래 테이블 수치에 따라 0.32로 잡았다.
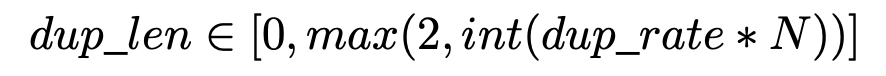
Momentum contrast
CVPR 2020, 비전에서 한정된 GPU 자원에 더 많은 negative 넣는 방법으로 Momentum contrast가 제안되었다. 앞의 배치의 임베딩 아웃풋들을 negative pair 사용해서, 더 많은 negative pair를 보도록 만드는 방법이다. (MoCo라고 불림)
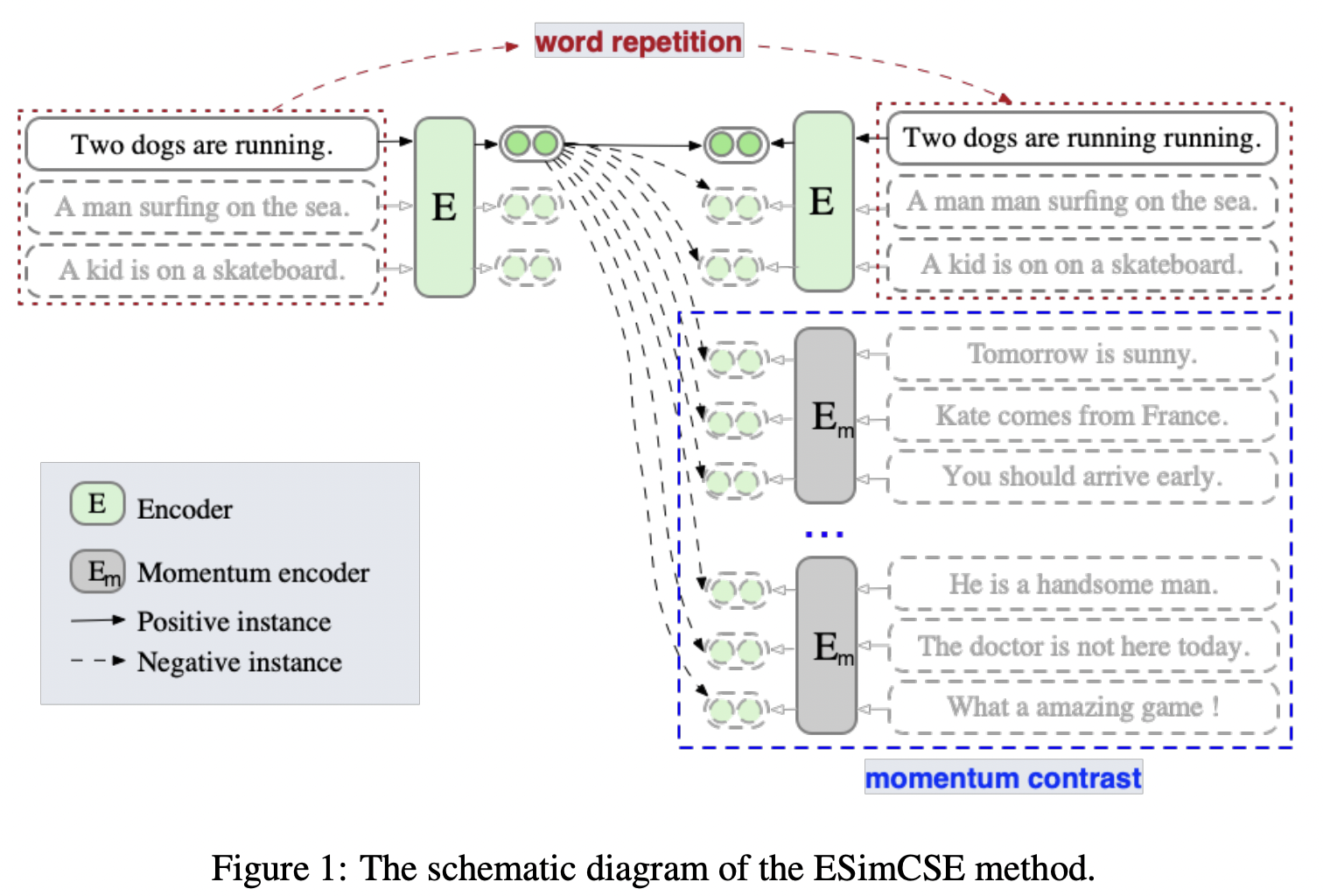
앞의 배치 임베딩 아웃풋을 만드는 인코더는 Momentum encoder로 우리가 트레이닝에서 사용하는 encoder의 영향을 조금씩 받아서 업데이트 시킨다. 이 연구에서 Momentum encoder는 실험에 사용되는 인코더 초깃값인 BERT 웨이트들을 복사해서 초기화한다.
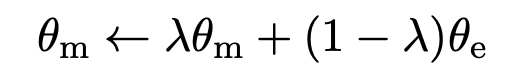
이 때에 Momentum encoder는 gradient 학습은 따로 진행하지 않으며, 이전 배치의 임베딩 아웃풋을 만들 때에는 dropout을 사용하지 않는다. 위와 같은 수식으로 업데이트하는데 람다는 0.995로 사용한다. (크게 변하지는 않고, 지금 변하는 인코더에 맞춰서 조금씩의 변화만 허용한다.)
Momentum contrast 적용되면, 결과적으로 오른쪽 아래 항이 추가된다. 이 아래 모델 그림에서 파란 박스로 칠해진 부분이다.
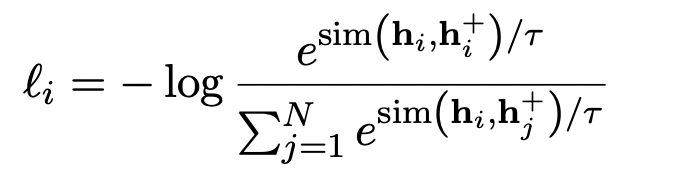
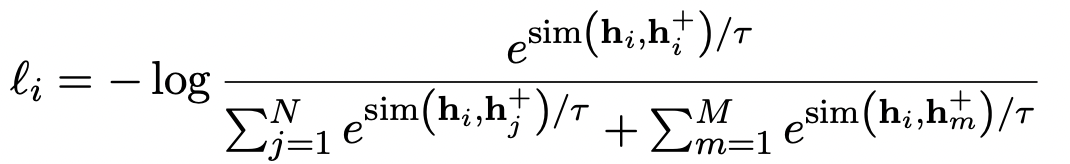
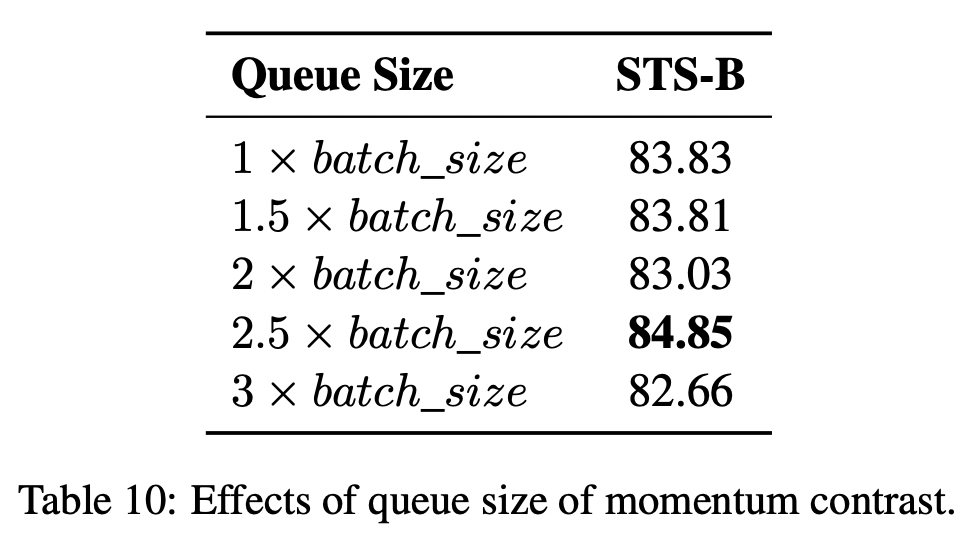
그렇다면 이전 momentum encoder로 부터 계산된 negative pair들을 얼마나 가지고 있어야 좋을까? 이 연구에서는 batch size에 2.5배라고 한다. 사실 계속해서 점수가 오르는 것이 더 좋은 그림인 것 같지만, 이 연구에서 해석하기로는 2.5배 아래로는 negative pair 수가 부족해서이고 그 위로는 너무 이전에 학습된 negative pair라서 점수가 더 오르지 않는 양상을 보인다고 한다. (?)
Experiments
결과표는 다음과 같다.