검색된 문서 내에 잡음(irrelevant information)이 많아 응답의 품질과 신뢰도가 떨어지는 현상을 문제상황이라고 보고, 이를 해결하기 위해서 MultiAgent FIlteriNg Retrieval-Augmented Generation(MAIN-RAG)를 제안합니다.
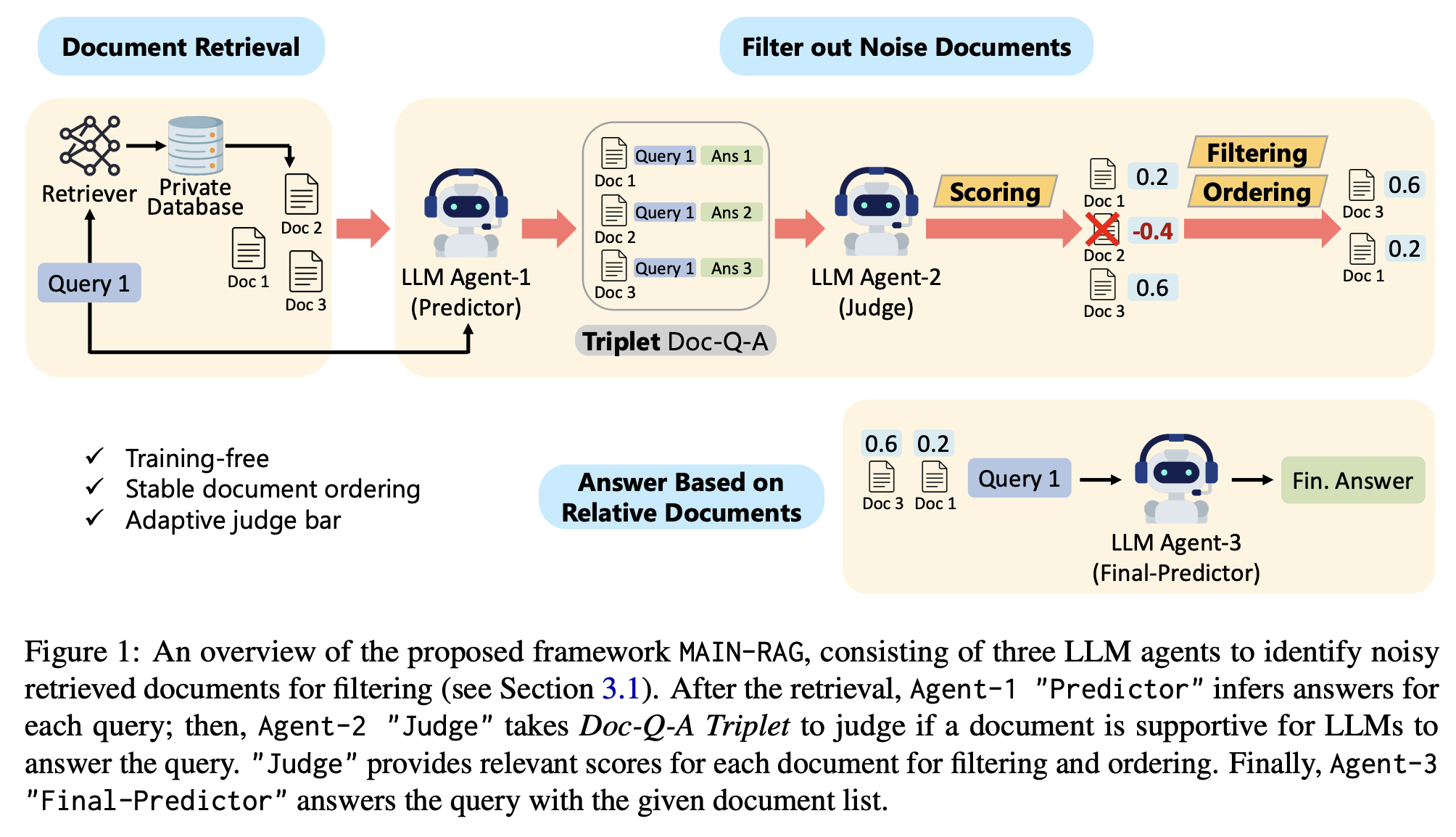
MAIN-RAG
MAIN-RAG에서 제안하는 세 개의 에이전트는 각각 Predictor, Judge, Final-Predictor로, Predictor는 각 문서에 대한 답을 찾고, Judge는 문서와 질문, 정답에 대한 triplet을 평가합니다. Final-predictor는 여기에서 threshold를 넘긴 문서들만을 남겨서 다시 정답을 만들게 됩니다.
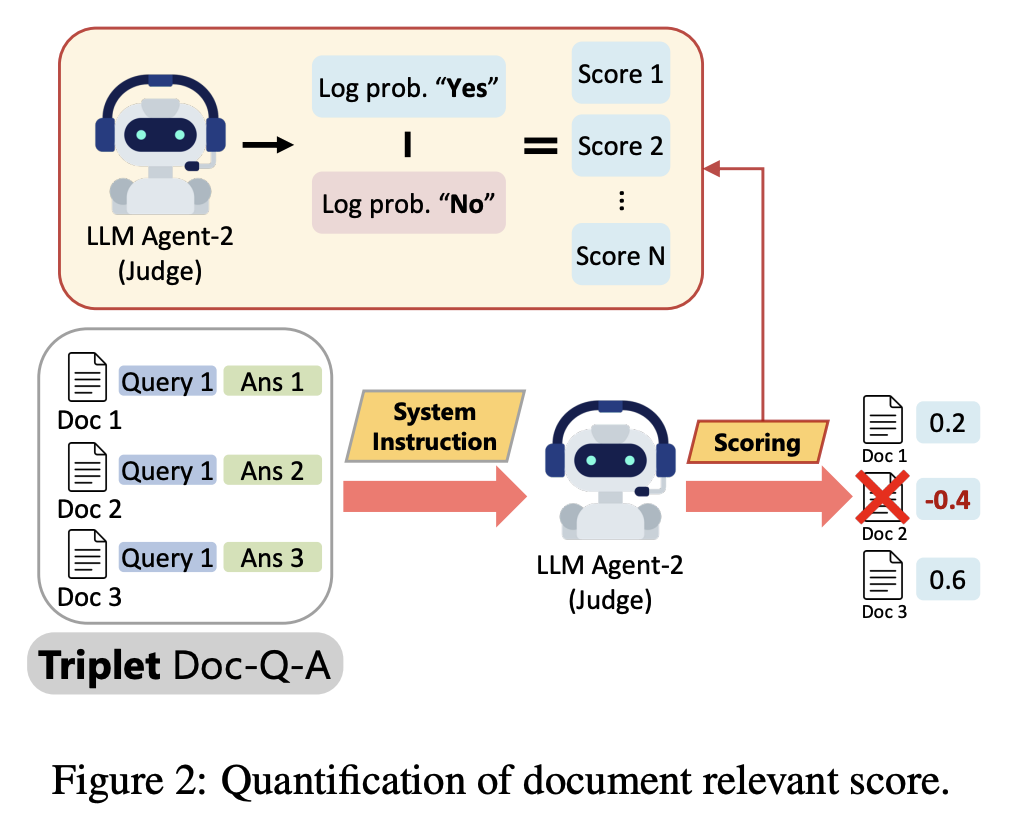
각 문서가 질문에 진짜 도움이 되는지 판단하는 Agent-2(Judge)가 "Yes" 또는 "No"로 답변하고, 이 답에 대한 확률(모델이 "Yes" 혹은 "No"라고 판단할 자신감 정도)을 수치화해서 점수로 매깁니다. 이때 'Yes' 확률에서 'No' 확률을 뺀 값을 점수로 사용합니다. 이런 방식으로 가장 관련성이 높은 문서가 정렬되어서 다시 Agent-3의 입력값으로 들어가도록 만듭니다.

문서마다 Agent-2가 계산한 관련성 점수(Relevance Score)가 있는데, 이를 기반으로 어느 점수 이상을 '관련 문서'로 판단하고 아닌 문서들을 걸러내는 임계값(판단 기준, judge bar)을 정하는 것이 중요합니다. 하지만 질문(query)마다 검색되는 문서들의 특성이 다르기 때문에 이 임계값이 고정되어 있으면 삭제되어야하는 문서가 많이 남아있거나, 유용한 문서가 제거될 수 있습니다. 따라서 각 질의마다 문서들의 평균 점수를 임계값으로 설정하는 adaptive judge bar를 도입합니다. 이 점수는 평균값을 기준으로 τq − n · σ (n은 하이퍼파라미터)을 통해서 도출합니다.
Adaptive Judge bar

-
τq 값이 높을 때(예: 9.575)는 필터링 기준이 매우 엄격하게 작동한다. 이 경우 관련도가 충분히 높은 문서만 통과하기 때문에 결과적으로 핵심적인 문서만 남게 되며, 모델이 불필요한 정보를 혼동하지 않고 정확한 답변을 생성할 수 있다. 즉, 정밀도(precision)가 높아지는 방향으로 작용한다. 실제 사례에서도 τq가 높을 때 LLM은 정확히 정답(Santurce)을 생성했다.
-
τq 값이 낮을 때(예: -8.425)는 필터링이 매우 느슨해진다. 따라서 관련이 약한 문서까지 함께 남게 되지만, 그 안에 정답에 필요한 중요한 정보(Maniowy)가 포함되어 있을 가능성이 커진다. 이로 인해 재현율(recall)은 높아지며, 때때로 이런 완화된 필터링이 오히려 정확도를 개선하기도 한다.
-
τq가 중간 수준(예: 0.4875)일 때는 필터링 강도가 애매하게 작동하여, 관련 문서뿐 아니라 이름이 비슷하지만 실제로는 관계없는 문서들이 함께 남게 된다. 이런 경우 LLM은 혼동을 일으켜 잘못된 정보를 기반으로 답변을 내놓게 되고, 결과적으로 노이즈가 증가한다.
Experiments
데이터셋
-
TriviaQA
- 약 65만 개의 질문-답변-증거 데이터가 포함된 대규모 QA 데이터셋으로, 위키피디아 및 웹에서 수집한 문서가 배경 지식으로 사용됨.
- 다중 문장 추론과 간접적인 정답 포함 등 복잡한 질문이 많아 일반 SQuAD보다 난이도가 높음.
- 자연어 질문과 문서 표현의 다양성이 크고, 사람이 검증한 하위집합도 있어 정확한 평가 가능.
- MAIN-RAG가 학습 없이 잡음 필터링을 효과적으로 수행하는지 시험하기 적합.
-
PopQA
- 외부 지식에 크게 의존하는 자연어 질문 데이터셋.
- 사전 학습된 모델 단독으로는 정확한 답변 생성이 어려워 검색 증강이 필수적임.
- MAIN-RAG의 필터링 및 문서 정렬 능력을 평가는 데 적합, 실제 환경에서의 잡음 문서 처리 능력 중시.
-
ARC-C (AI2 Reasoning Challenge - Challenge Set)
- 과학 영역의 어려운 문제로 구성되어 있으며, 추론과 복합적인 이해 능력을 요구함.
- 문서 내 명확한 답변뿐만 아니라 추론 능력 평가에 잘 맞는 고난도 데이터셋.
- MAIN-RAG가 복잡한 문서 이해 및 잡음 제거에 어느 정도 강점이 있는지 확인.
-
ASQA (Arabic Spoken Question Answering)
- 아랍어 음성 기반 질문 응답 데이터셋으로, 언어 및 음성 처리 등 다중 도메인 적용 가능성 평가 목적.
- 다양하고 어려운 실제 언어 데이터에 대한 RAG 시스템의 적용 가능성 테스트에 적합.
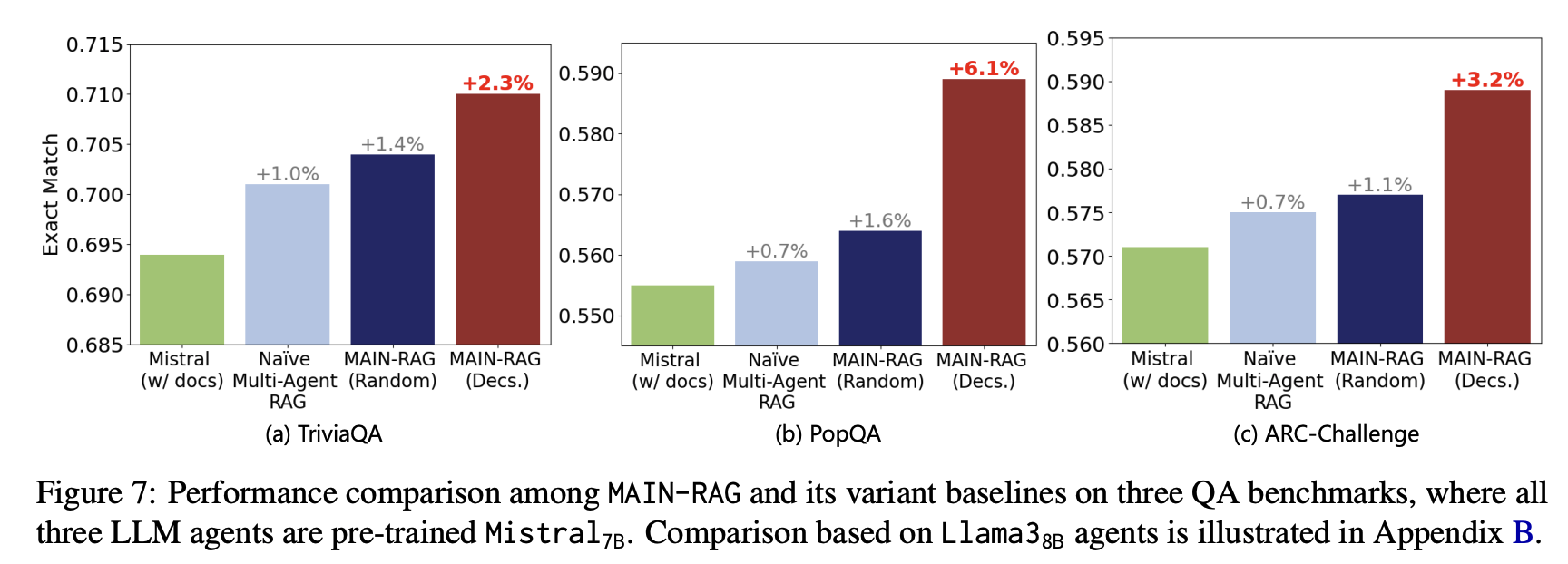
- Naïve Multi-agent RAG:
Agent-2(판단 에이전트)의 역할을 단순화해, 관련 문서 여부를 "Yes" 또는 "No"라는 자연어 판단으로만 결정합니다. 즉, 점수화(log odds)를 쓰지 않고 단순 분류만 한다는 의미입니다. - MAIN-RAG (Random):
MAIN-RAG 방식대로 문서 점수를 산출하고 필터링 후, 필터링된 문서들의 순서를 무작위로 섞어서(ramdomize) 모델에 입력합니다. 이렇게 하면 문서 순서가 문제에 미치는 영향을 평가할 수 있습니다. - MAIN-RAG (Decs.):
문서 점수화와 필터링 후에 문서를 관련도 순서대로 점수가 높은 문서부터 낮은 문서 순서로 정렬해서 처리하는 방법입니다.
-
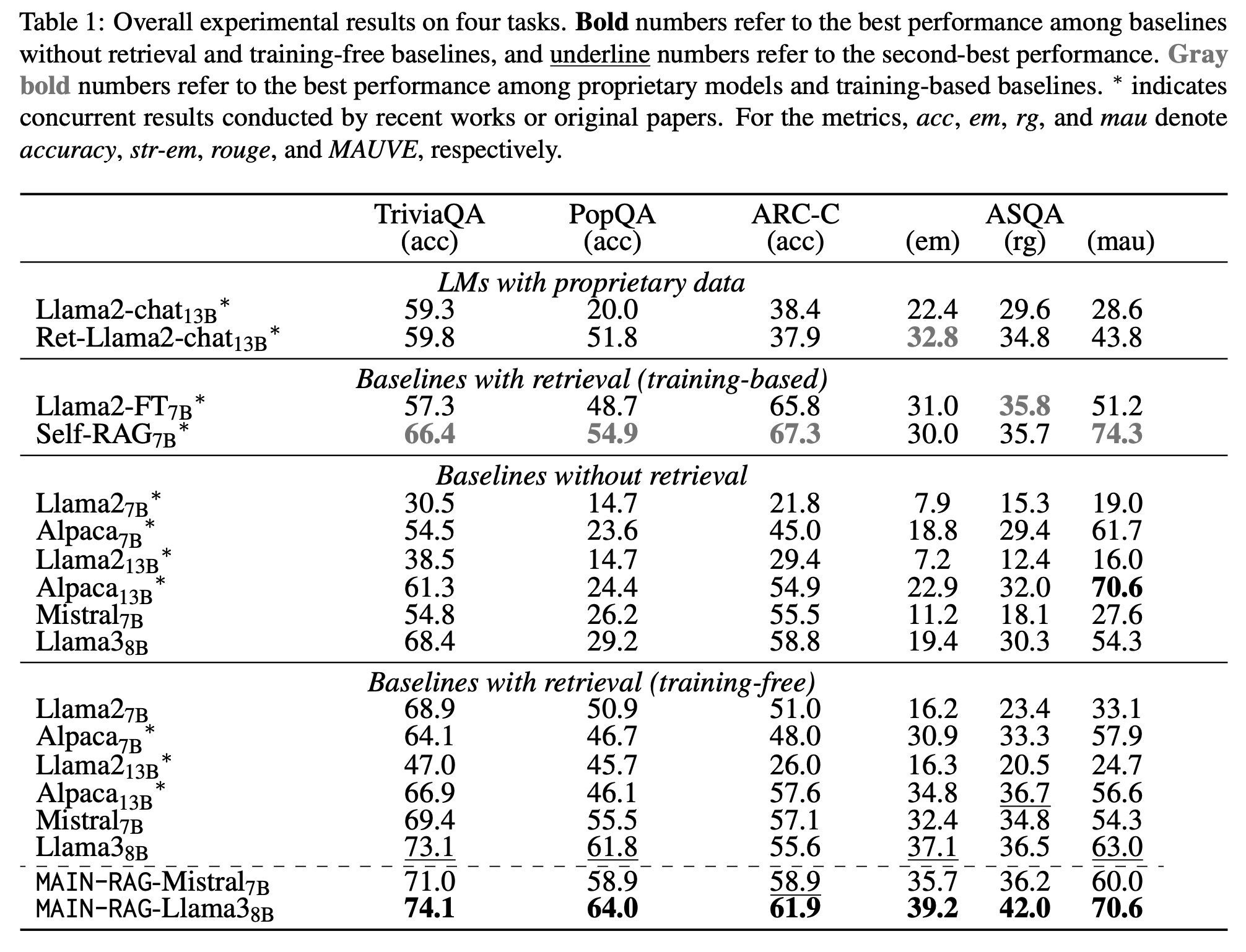
MAIN-RAG는 “training‑free + no‑retrieval” 모든 베이스라인 대비,
- Mistral‑7B 세팅에서 최대 +6.1%p,
- Llama‑3‑8B 세팅에서 최대 +12.0%p 정확도 상승을 보였다는 것을 강조할 수 있습니다.
- 벤치마크 전부에서 training‑free 계열 중 최고 성능이라는 점(“in all four benchmarks”)이 핵심 메시지입니다.
-
PopQA는 롱테일 팩트에 대한 open‑domain QA라, 외부 지식·retriever 품질 의존도가 큽니다.
- retriever가 target dataset에 파인튜닝돼 있지 않아 noisy contexts가 많이 섞이는데, MAIN-RAG의 multi‑agent filtering 덕분에 단순 RAG보다 큰 이득을 본다는 점을 “노이즈 많은 환경에서 특히 효과적인 방법”으로 볼 수 있습니다.
-
Training‑based RAG와의 관계
Self-RAG, Llama2‑FT처럼 retriever/LLM을 학습한 시스템과 비교했을 때, TriviaQA와 PopQA에서는 성능 갭을 상당 부분 “bridge” 한다고 주장합니다.- 특히 long-form ASQA에서 rouge(rg) 기준으로는 MAIN-RAG‑Mistral7B가 일부 지점에서 Self-RAG(7B), Llama2‑FT(7B)를 이기는 케이스가 있어,
- “추가 파인튜닝 없이도 멀티에이전트 필터만으로 training‑based RAG 일부를 대체/보완 가능하다”고도 생각할 수 있습니다.
