대규모 언어모델이 수많은 태스크를 해결하고 있지만, 여전히 가볍고도 강력한 임베딩 모델을 만드는 일은 쉽지 않습니다. EmbeddingGemma는 이러한 문제의식에서 출발한 모델입니다. Gemma 3가 지닌 방대한 언어 지식을 계승하면서도, 단방향 구조(decoder-only)의 한계를 극복하기 위해 T5 방식의 encoder-decoder 구조로 재설계하고, 그중 encoder를 임베딩 전용으로 활용하였습니다. 이를 통해 문맥을 양방향으로 이해하면서도 효율적인 경량 모델을 구현하였습니다. 이후 대규모 비지도 데이터로 pre-finetuning, 고품질 태스크별 데이터로 finetuning을 수행하였으며, Bayesian Optimization과 Model Souping을 통해 다양한 태스크의 강점을 결합한 모델입니다.
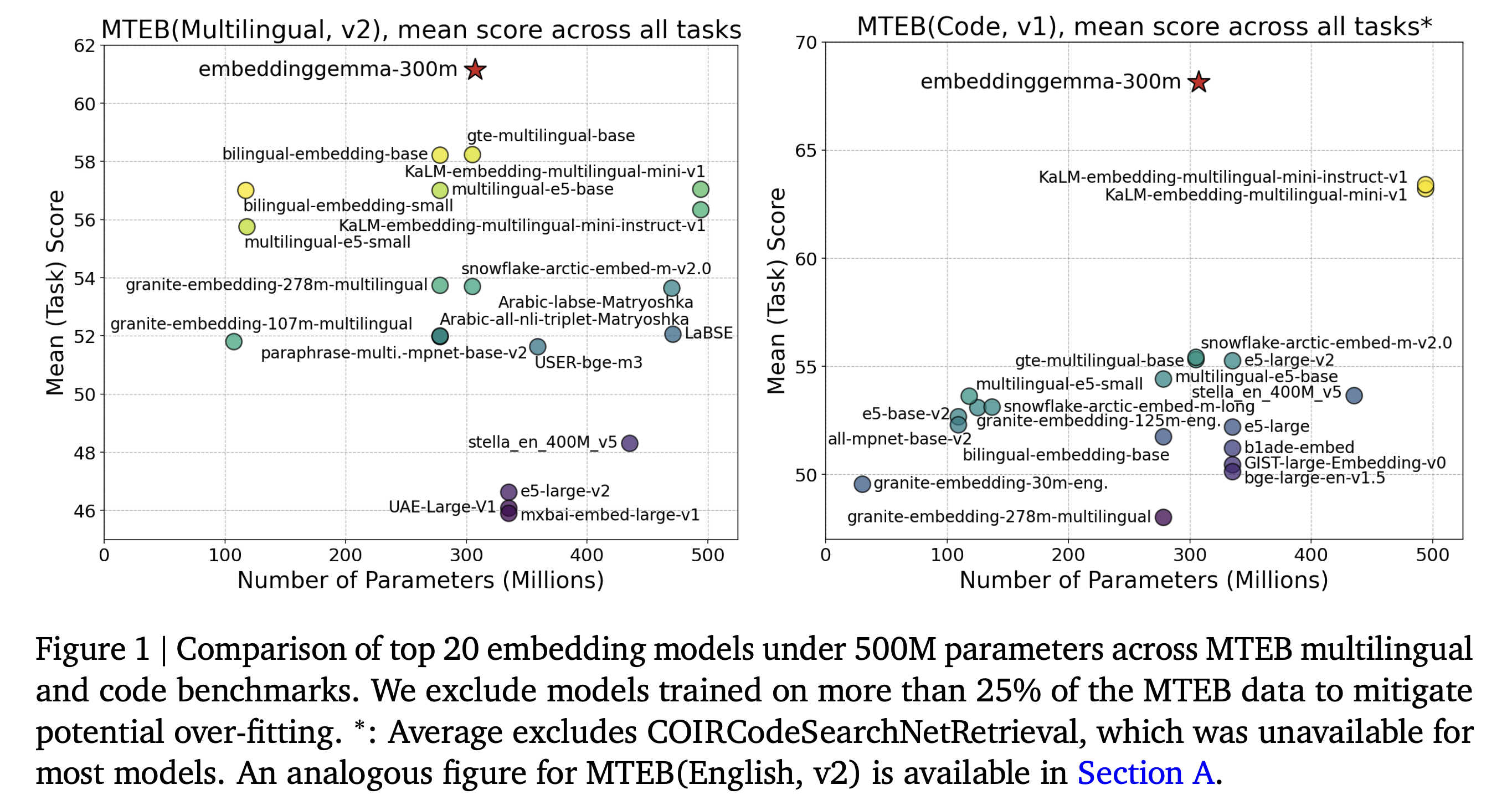
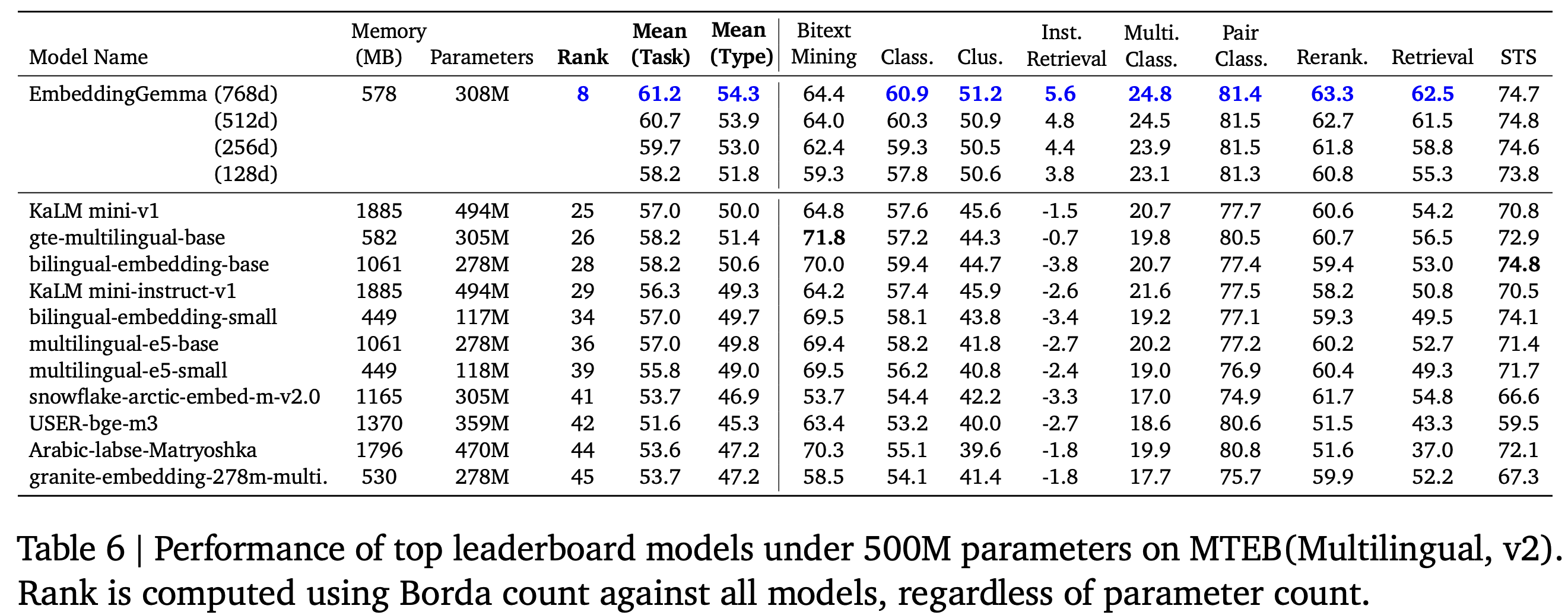
500M가 안되는 모델들을 대상으로 비교했을 때, 별표 모양의 embeddinggemma 모델이 성능적으로 우위임을 확인할 수 있습니다.
Architecture
EmbeddingGemma는 기존 Decoder-only 구조의 Gemma를 Encoder-Decoder 구조로 확장하고(T5Gemma recipe) 그 이후 최종적으로 Encoder-only 모델을 이용해서 성능을 보여줍니다.
원래 Gemma는 단방향(causal) self-attention을 사용하는 디코더 기반 언어모델로, 주어진 입력으로부터 다음 단어를 예측하는 데 최적화되어 있었습니다. 그러나 이러한 구조는 문맥을 한쪽 방향으로만 해석하기 때문에, 문장 전체의 의미를 포괄적으로 표현하는 임베딩 학습에는 한계가 있습니다.
이를 해결하기 위해 T5Gemma recipe를 사용하여 디코더 블록을 복제·수정해 인코더 블록을 추가하고, 인코더에는 BERT처럼 양방향 self-attention을 적용하였습니다. 반면, 디코더는 기존과 동일하게 autoregessive attention을 유지합니다. 이렇게 구성된 Encoder-Decoder 구조는 입력 문장을 전방위로 이해한 후, 그 의미를 바탕으로 출력을 생성할 수 있는 양방향·생성형 하이브리드 구조입니다.
이 과정을 거쳐 EmbeddingGemma는 T5Gemma의 인코더 부분만을 추출하여 임베딩 모델로 사용합니다. 즉, 텍스트를 생성하는 대신 입력의 의미를 압축적으로 표현하는 데 집중하는 구조로 변환하는 것입니다. 이를 비유하자면, “말하기만 잘하던 사람(Decoder-only)”이 “듣고 말도 잘하는 사람(Encoder-Decoder)”을 거쳐, 최종적으로 “듣고 핵심만 머릿속에 저장하는 사람(Encoder-only)”이 된 것과 같습니다. EmbeddingGemma는 이러한 구조적 진화를 통해 문장을 더 깊이 이해하고, 그 의미를 효율적으로 임베딩하는 모델로 발전하였습니다.
Training
문맥 이해력이 뛰어난 encoder를 얻기 위해서 Decoder-only 구조의 Gemma를 Encoder–Decoder 형태로 변환(adapt)하는 Encoder-Decoder Training 단계를 거칩니다. 이후 Encoder 모델을 이용해서 Pre-finetuning, finetuning 단계를 통해 학습합니다.
학습에는 총 2.1T 토큰(encoder-decoder training 1.77T, pre-finetuning 314B, finetuning 20B)의 데이터를 사용했습니다. Encoder-decoder training에서는 Gemma3 pretraining 데이터를 사용했다고 밝혔습니다. (100+ languages 포함된 데이터로 다국어 모델입니다.)
세 단계 중 두 번째 단계(pre-finetuning)에서부터는 아래와 같은 loss를 사용합니다.
hardness weight
hardness weight을 통해서 학습 중, 어떤 (query, hard negative passage) 쌍이 얼마나 어려운지를 수치화해서 그에 비례해 가중치를 더 주는 방식을 사용합니다. negative 예제에만 이 가중치는 포함되고, 헷갈릴수록(즉, 더 유사도가 높을수록) 지수적으로 큰 weight를 부여하게 됩니다. hyperparameter인 알파값은 5.0으로 설정되어있습니다. 여기에서 stop gradient가 포함되는 이유는 forward 계산에는 쓰이지만 backward 계산에는 쓰이지 않게 하기 위함입니다. (질문)
Global Orthogonal Regularizer
Global Orthogonal Regularizer (GOR)은 embedding 공간 전체를 더 넓고 균일하게 퍼뜨리도록 하는 장치로, 기존 in-batch negative 학습에서 여러 쿼리/문서 쌍이 유사한 구조를 가지면 embedding들이 특정 방향으로 몰려버리는 collapse 현상을 방지하기 위해서 사용되었습니다.
방향성의 측면에서 벡터들이 대부분 같은 방향을 바라보게 된다면, 그 안에서 서로 다른 의미를 표현하는 벡터들 간 구분은 아주 미묘한 각도 차이에 의존하게 됩니다. 이 경우 모델은 embedding 공간의 일부만 사용하게 되어, 의미적 다양성을 충분히 표현하지 못하고 표현 공간이 붕괴(collapse) 되는 현상이 나타납니다.
반면, 벡터들이 서로 다른 방향으로 고르게 퍼져 있을수록, 각 embedding은 고유한 의미 축을 차지하게 되고, 결과적으로 모델은 의미적으로 풍부하고 해석 가능한 표현 공간을 형성하게 됩니다. 이처럼 직교성(orthogonality)은 개별 벡터들이 서로 간섭하지 않도록 하여, embedding 전체가 spread-out된 상태를 이루게 하는 핵심적인 기하적 조건으로 작용합니다.
아래 수식을 보면 배치 안에 있는 임베딩 벡터 쌍들 간의 모든 조합을 공평하게 평균내기 위해서 배치 내 모든 벡터 쌍 조합을 분모(정규화 역할)로 두었습니다. 그리고 쿼리 간, positive 간의 직교성을 loss에 반영하도록 함으로써 q들끼리 서로 너무 비슷하지 않게, p⁺들끼리도 의미적으로 다양한 방향으로 퍼질 수 있도록 유도합니다.
Embedding matching
이미 잘 학습된 teacher embedding model (Gemini Embedding) 을 이용해 작은 모델에서도 그 embedding 구조 자체를 흉내 내도록 학습하도록 하기 위해 아래와 같은 loss를 도입하였습니다.
각 항목은 다음과 같습니다:
- : 쿼리(query) 임베딩
- : positive passage 임베딩
- : hard negative passage 임베딩
각 손실 항목은 teacher의 임베딩 와 student(EmbeddingGemma)의 임베딩 간의 차이를 최소화합니다.
추가로 Matryoshka Representation Learning (MRL) 반영을 위해서 128, 256, 512, 768 차원에서의 학습을 진행합니다.
1. Encoder-Decoder Training 단계
“모델의 인코더 부분을 강하게 만들기 위한” 사전학습(pre-training) 단계로, Gemma 3 의 디코더-전용 구조(decoder-only)였던 모델을 T5Gemma 방식으로 인코더-디코더 구조로 바꿔서(initialization) 학습합니다. 데이터는 매우 방대하고 다양하며, 기존 Gemma 3가 학습한 대규모 언어 데이터셋을 재사용하여 학습을 진행합니다.
2. Pre-finetuning 단계
이 단계부터는 인코더만을 사용해서 임베딩 표현(embedding) 중심으로 학습이 진행됩니다. 모델이 다양한 언어, 다양한 도메인에서 문장 의미 표현의 일반화(generalization)를 갖추도록 하는 것이 핵심 목표가 되며 사용하는 데이터는 다양한 task의 데이터를 사용했으며(question answering, sentence similarity, code retrieval, and web search tasks) 코드 데이터도 학습에 사용되었습니다. 배치사이즈는 키워서 in-batch negative 형태로 학습을 진행했다고 언급되어있습니다.
3. Finetuning 단계
이 단계에서는 batch size를 줄이고 hard negative를 사용했습니다. 작지만 정제된 태스크별 데이터셋을 사용했다고 나와있으며 Bayesian Optimization + Dirichlet Sampling을 통해서 데이터를 혼합했다고 말하고 있습니다.
데이터는 QA, retrieval, STS, summarization 같은 다양한 태스크(Task diversity), 여러 언어(Language diversity), 코드 검색, 코드 임베딩(Code capability) 로 크게 세 가지 데이터를 이 단계에서 학습합니다. 이 때에 Dirichlet Sampling은 “탐색의 출발점(초기 seed)”을 다양하게 만드는 역할, Bayesian Optimization은 그 중 좋은 조합 근처를 지능적으로 탐색하는 역할을 수행합니다.
Dirichlet Sampling은 “합이 1인 다양한 비율 조합”을 손쉽게 랜덤 생성해주기 때문에 이 sampling을 이용해서 초기 태스크별 비율을 샘플링합니다. 해당 태스크 비율에 따라 모델 finetuning을 통해서 성능을 얻게 되면, Bayesian Optimization을 통해서 더 적절할 태스크 비율을 찾도록 합니다. 여기에서는 Gaussian Process(GP) 로 “성능 예측(mean)”과 “불확실성(variance)”을 모두 계산해 최적의 값을 찾아내는 방식입니다.
Gaussian Process (GP) 를 이용하여 각 조합의 성능을 확률적으로 예측하며, 다음 두 가지 정보를 동시에 계산합니다.
- 예측 평균(mean, μ) → 지금까지 관측된 결과로 볼 때 성능이 높을 것으로 예상되는 영역 (활용, exploitation)
- 불확실성(variance, σ²) → 아직 충분히 탐색되지 않은 영역 (탐색, exploration)
BO는 이 두 정보를 Acquisition Function(AF) 으로 결합하여 “다음에 탐색할 태스크 비율”을 결정합니다.
이 식에서
- β가 커질수록 탐색(exploration) 성향이 강해지고,
- β가 작을수록 활용(exploitation)에 집중하게 됩니다.
finetuning 이후 품질을 개선하거나 효율을 높이기 위한 후처리 과정으로 Model Souping과 Quantization-Aware Training(QAT)을 진행합니다.
Model souping에서는 checkpoint들의 파라미터를 단순 평균으로 최종 “EmbeddingGemma (final)” 모델 생성합니다. Bayesian optimization으로 얻은 여러 개의 모델을 이용해서 model soupging을 진행했다고 합니다.
Quantization-Aware Training (QAT)는 quatizaion에서의 성능 저하를 최소화하기 위해 학습 과정에서 미리 그 영향을 반영하는 기법입니다. 학습 중에 “forward pass”에서는 정수 양자화처럼 계산하고, “backward pass”에서는 실수(원래 weight)로 gradient 업데이트를 함으로써 모델이 “이 weight는 나중에 int8로 변환될 거야” 라는 걸 학습 중에 이미 경험하게 되고, 결국 “정수 표현으로도 잘 동작하는 weight 분포”를 만들도록 합니다. 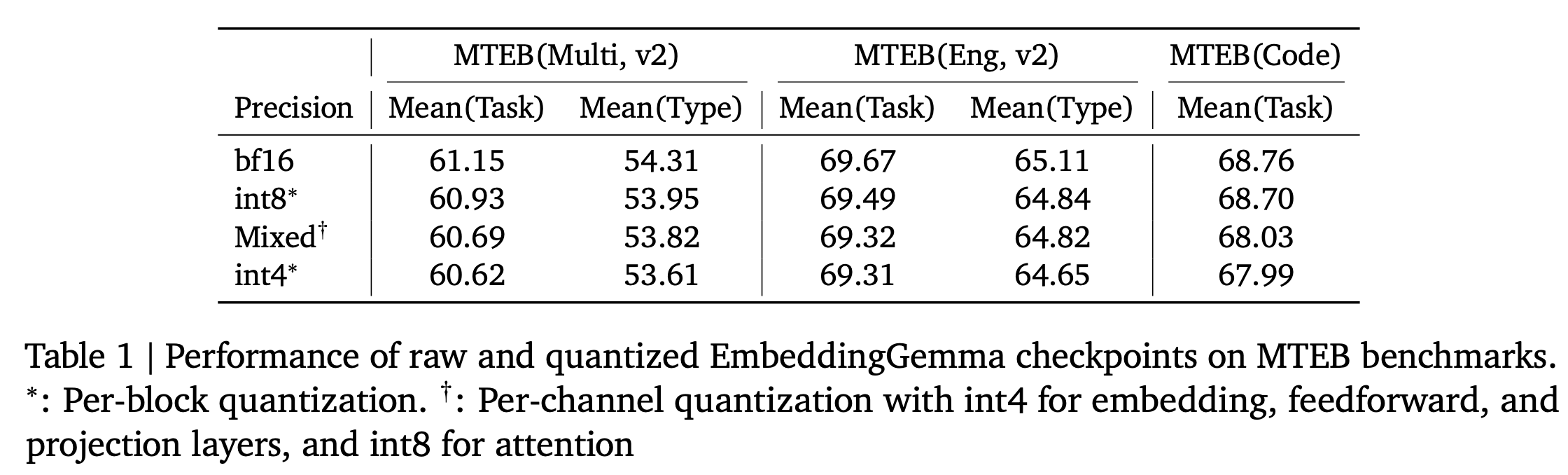
Recipe
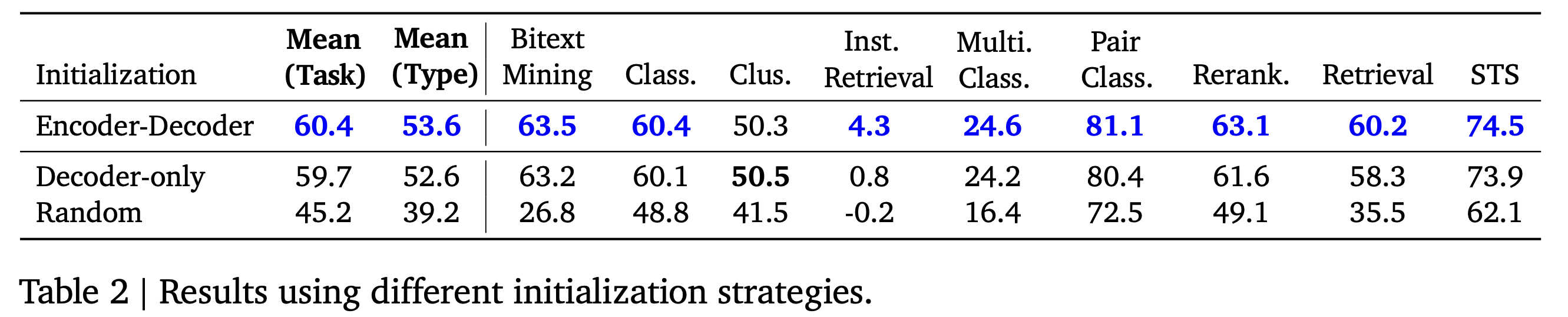
EmbeddingGemma는 학습 초기 단계에서 Gemma 3의 decoder-only 모델을 T5-style encoder-decoder로 변환한 뒤, encoder를 초기화로 사용함으로써 학습을 진행합니다. 이 과정에서 Encoder-decoder 변환하여 initialization을 진행했을 때 실험적으로 문장 유사도, 검색, 분류, 클러스터링 등 대부분의 task에서 일관된 성능 향상을 보여줍니다.
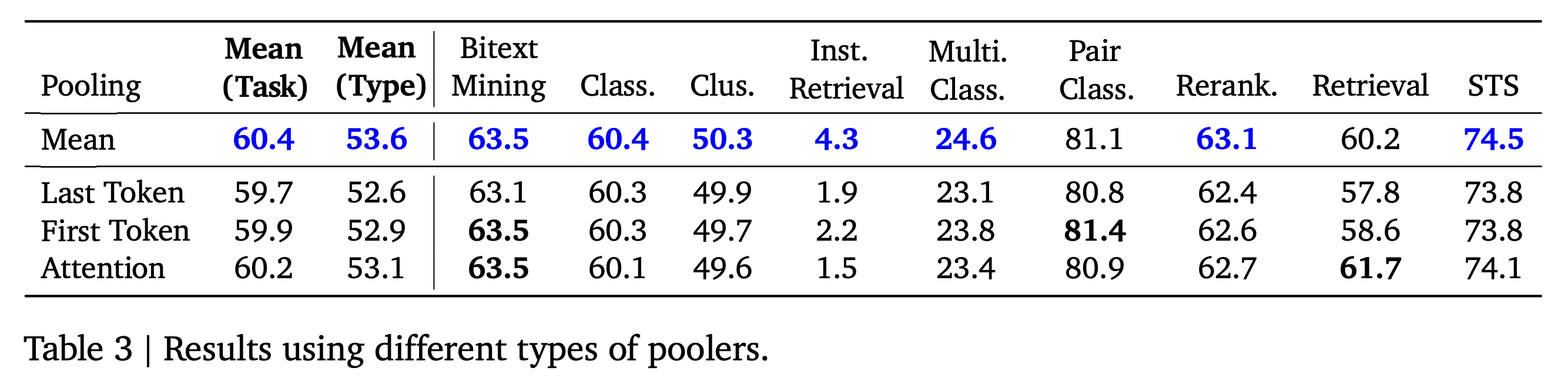
입력 토큰의 hidden state를 하나의 임베딩으로 요약하기 위해 여러 풀링(pooling) 방식을 실험했을 때에 mean pooling이 가장 안정적이고 성능이 높게 나타났습니다.
이 현상은 Suganthan et al. (2025) 의 연구 결과와도 일치합니다. 해당 연구에서는 기존의 decoder-only LLM을 encoder 형태로 변환한 경우, classification이나 regression 같은 문장 단위 태스크에서 attention pooling보다 단순한 pooling(mean 또는 last token pooling) 이 consistently 더 좋은 성능을 보였음을 보고했습니다.
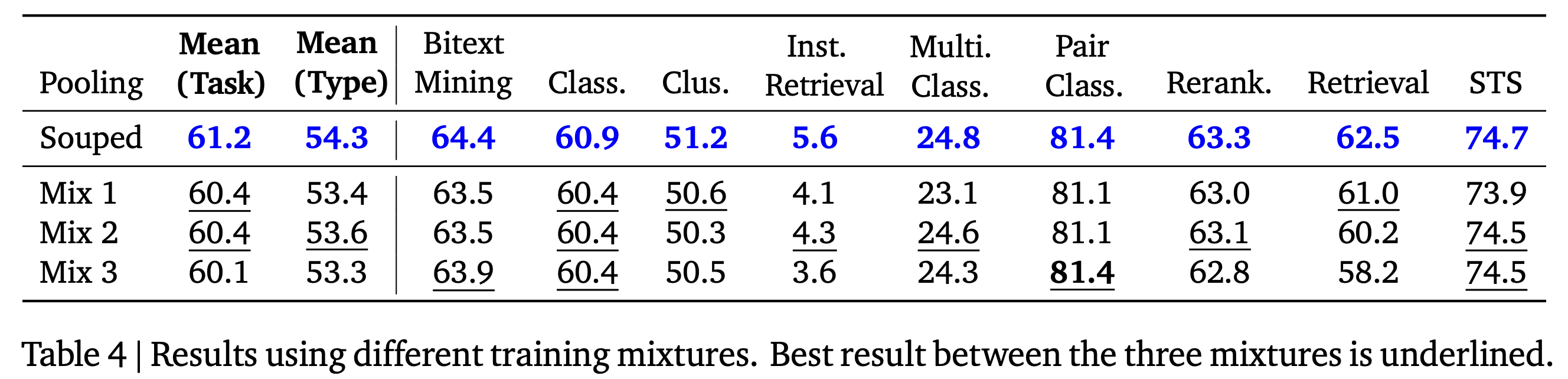
EmbeddingGemma는 Bayesian Optimization으로 탐색한 다양한 finetuning mixture 모델을 평균하는 방식의 model souping 기법을 사용했으며, 그 결과 개별 모델보다 모든 태스크에서 더 높은 성능과 우수한 일반화 성능을 달성했습니다. 각 Mix i는 서로 다른 finetuning mixture (즉, task/언어/도메인 혼합이 다른) 기반으로 학습된 체크포인트인 것으로 보입니다.
Evaluation
EmbeddingGemma는 MTEB(Massive Text Embedding Benchmark), XOR-Retrieve, XTREME-UP 등 다양한 벤치마크에서 기존의 범용 임베딩 모델들을 크게 능가하는 성능을 보여주었습니다. 특히 500M 이하 경량 모델 중에서는 multilingual, English, code 세 가지 리더보드 모두에서 1위를 달성하며, 모든 태스크 평균(Task Mean), 태스크 유형 평균(Task Type Mean), Borda Rank 등 종합 지표에서도 우위를 보였습니다. 또한 임베딩 차원을 768에서 128로 줄이더라도 여전히 최고 수준의 성능을 유지하여, 차원 축소에도 표현력을 입증했습니다. EmbeddingGemma는 다국어·영어·코드 태스크를 모두 아우르는 범용 임베딩 품질을 보였으며, 파라미터 수가 두 배 이상 많은 대형 모델들과 비교해도 동등하거나 그 이상의 성능을 기록했습니다. 대부분의 상용 API 모델(OpenAI, Cohere, Voyage 등)과 비교할 때, Gemini Embedding을 제외한 모든 공개 모델 대비 최고 수준의 품질을 달성했습니다.
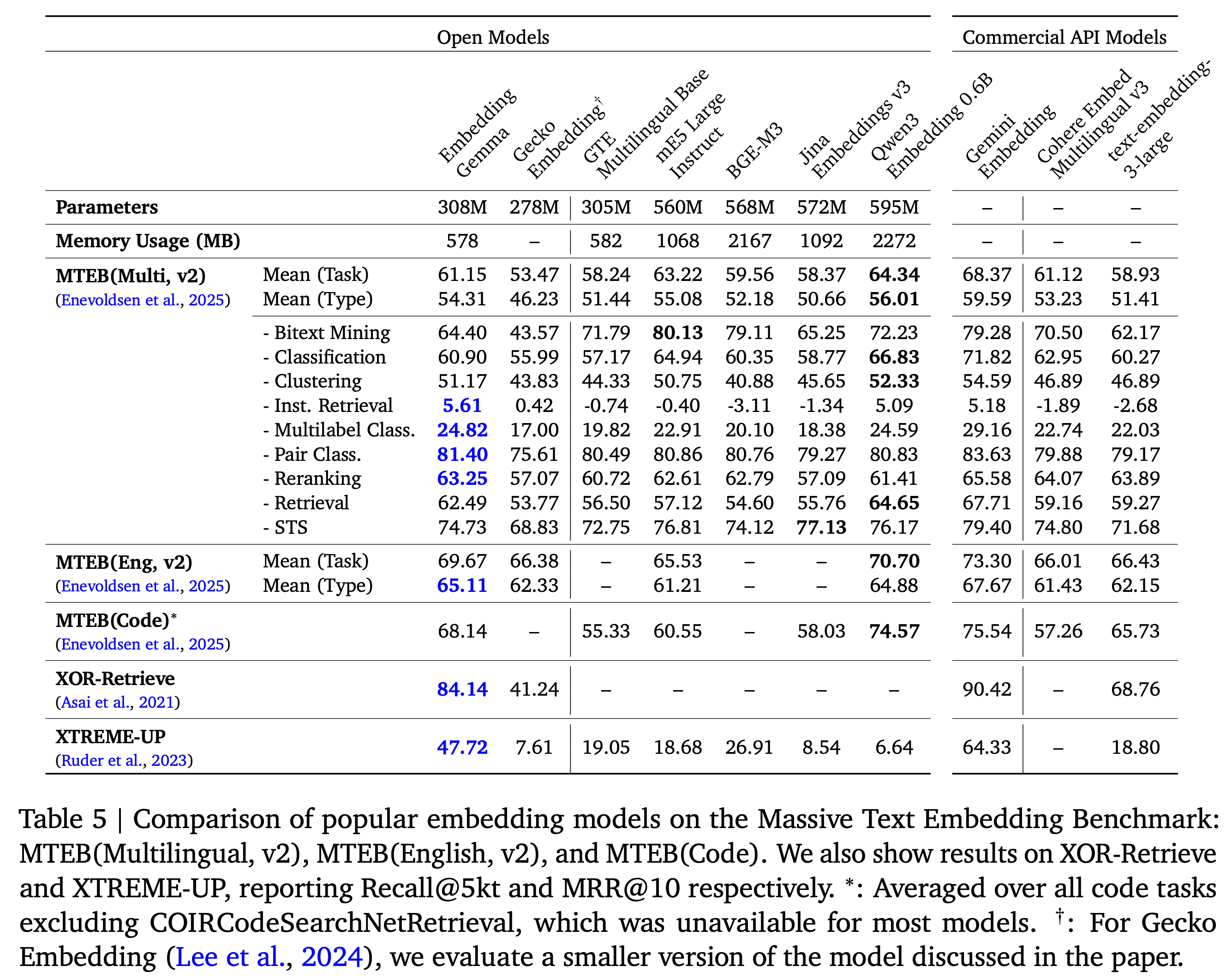
EmbeddingGemma는 MTEB Multilingual v2에서 대부분의 태스크 유형에서 최고 성능을 기록했으며, 특히 instruction retrieval·classification·reranking 등 핵심 태스크에서 Qwen3 Embedding 0.6B를 능가하며, 1B 미만 모델 중 최상위 품질의 multilingual 임베딩 성능을 달성했습니다.
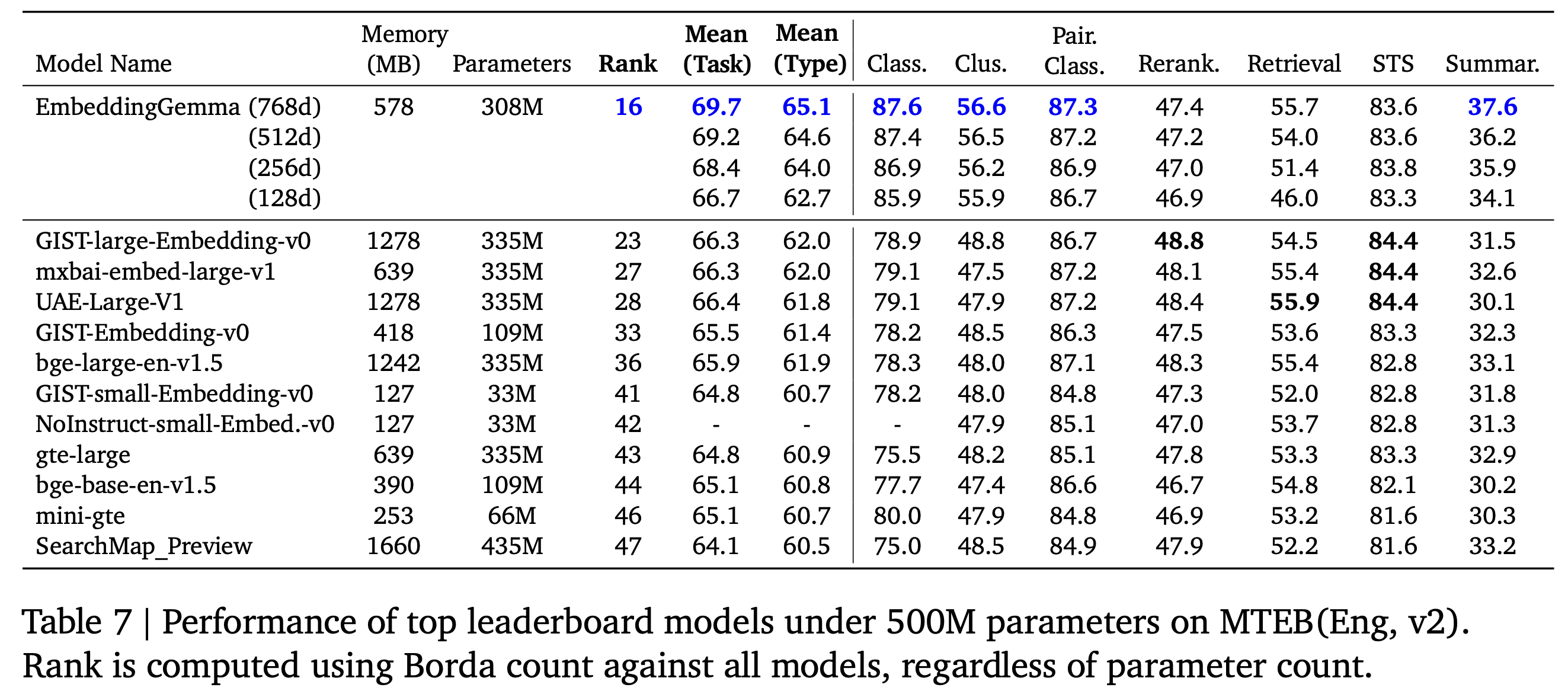
EmbeddingGemma는 MTEB English v2에서 전체 종합 점수 1위를 기록했으며,
특히 classification·clustering·summarization 태스크에서 각각 +8.5, +7.8, +4.4 포인트의 향상을 달성했습니다.
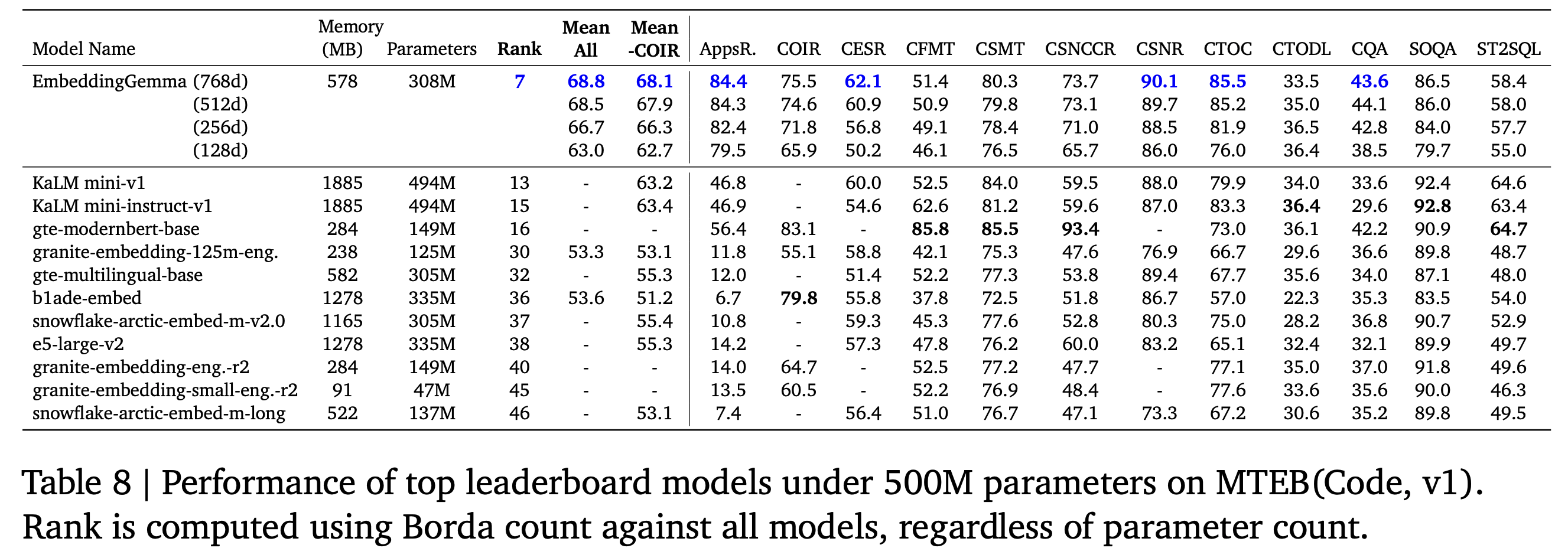
EmbeddingGemma는 MTEB(Code) 벤치마크의 모든 종합 지표에서 최고 성능을 기록했으며, 특히 AppsRetrieval(+37.6)과 CosQA(+10.0) 태스크에서 압도적인 향상을 보였습니다. 이는 EmbeddingGemma가 자연어–코드 간 의미적 표현을 효과적으로 학습한 모델임을 입증합니다.
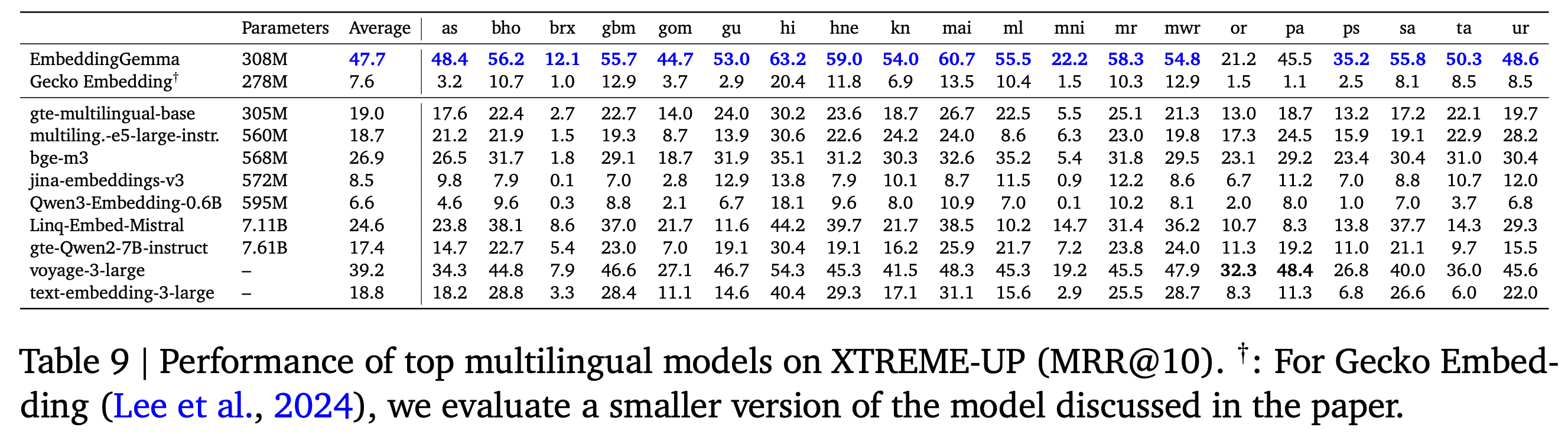
EmbeddingGemma는 XTREME-UP 벤치마크의 cross-lingual retrieval 태스크에서, 대규모 다국어 모델과 상용 API 모델을 모두 능가하는 탁월한 성능을 보였습니다. 이 태스크는 데이터가 제한된 언어권(20개 언어) 의 질의를 영어 문서와 매핑하는 고난도 과제에 해당합니다.