Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
마이크로소프트, ICLR 2022
- ELECTRA 이후에 이런 모델 구조를 이용한 COCO-LM 등 다양한 모델들이 나왔는데, Generator, Discriminator 사이의 사이즈를 굉장히 잘 조절해야 하는 문제가 있다.
- ELECTRA Base 기준 Generator hidden size 1/3 줄이는 반면,
- COCO-LM에서는 hidden size를 동일하게 유지하고 레이어를 1/3 줄였다.
- 이를 해결하기 위해 MLM을 다양하게 활용해서 generator로 생성하는 여러 단계의 문장 난이도로 discriminator를 학습하였다.
- 또 다른 문제로, ELECTRA 스타일에서 Generator는 Discriminator의 영향을 받아 학습되지 않는다.
- ELECTRA는 Generator가 학습될수록 Discriminator는 점점 맞추기 어려운 문제를 주기 때문에 효과적이었다(Curriculum learning).
- 하지만 Disminator의 영향으로 어려운 문제를 만든 것은 아니기 때문에 Generator가 최적으로 Discriminator를 위해서 학습된 것인지는 확실치 않다.
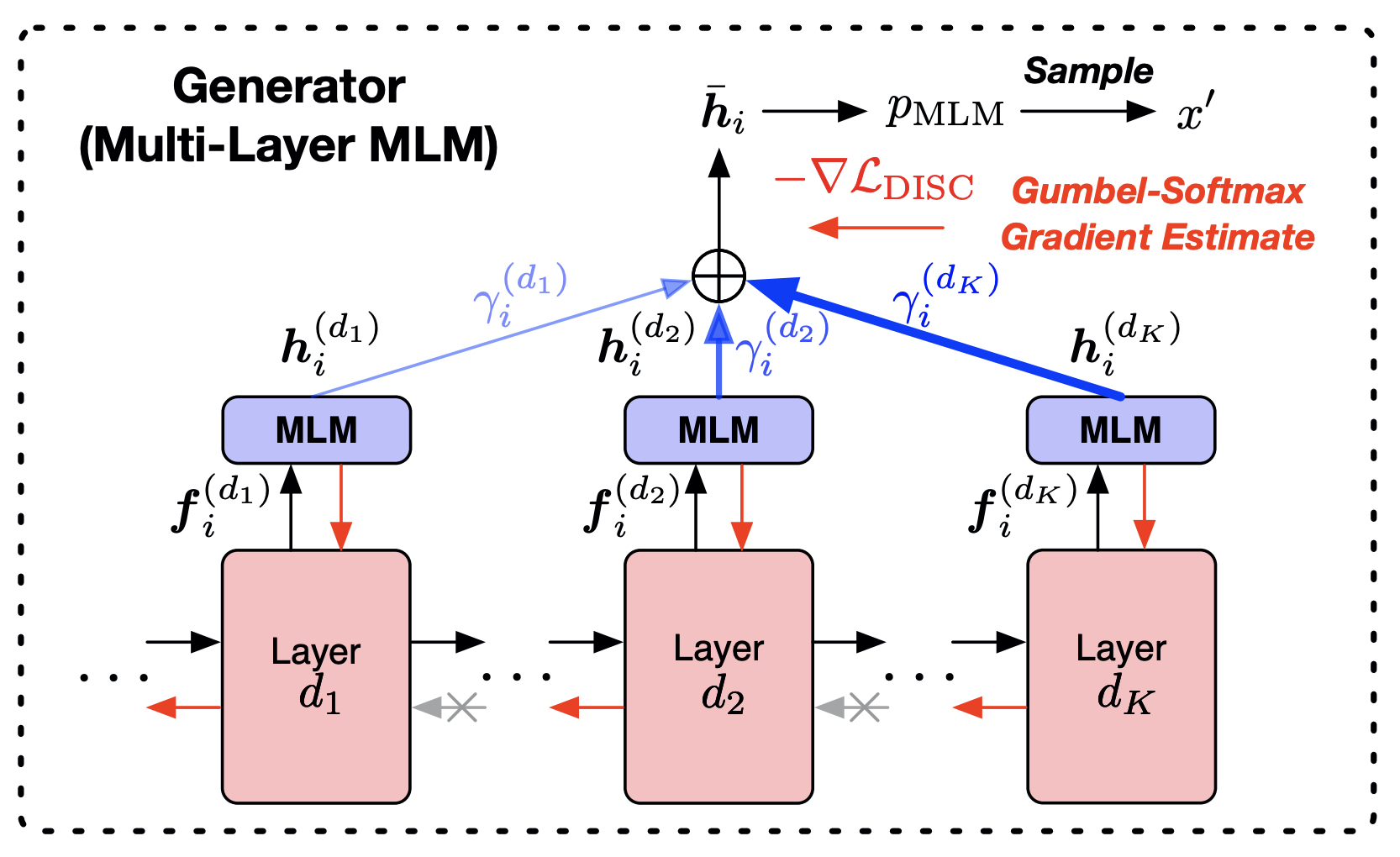
- Mixture weights, Gumbel softmax 추가하여 Discriminator의 영향을 받아 Generator가 학습되었다.
Adversarial learning with Mixture of Generators
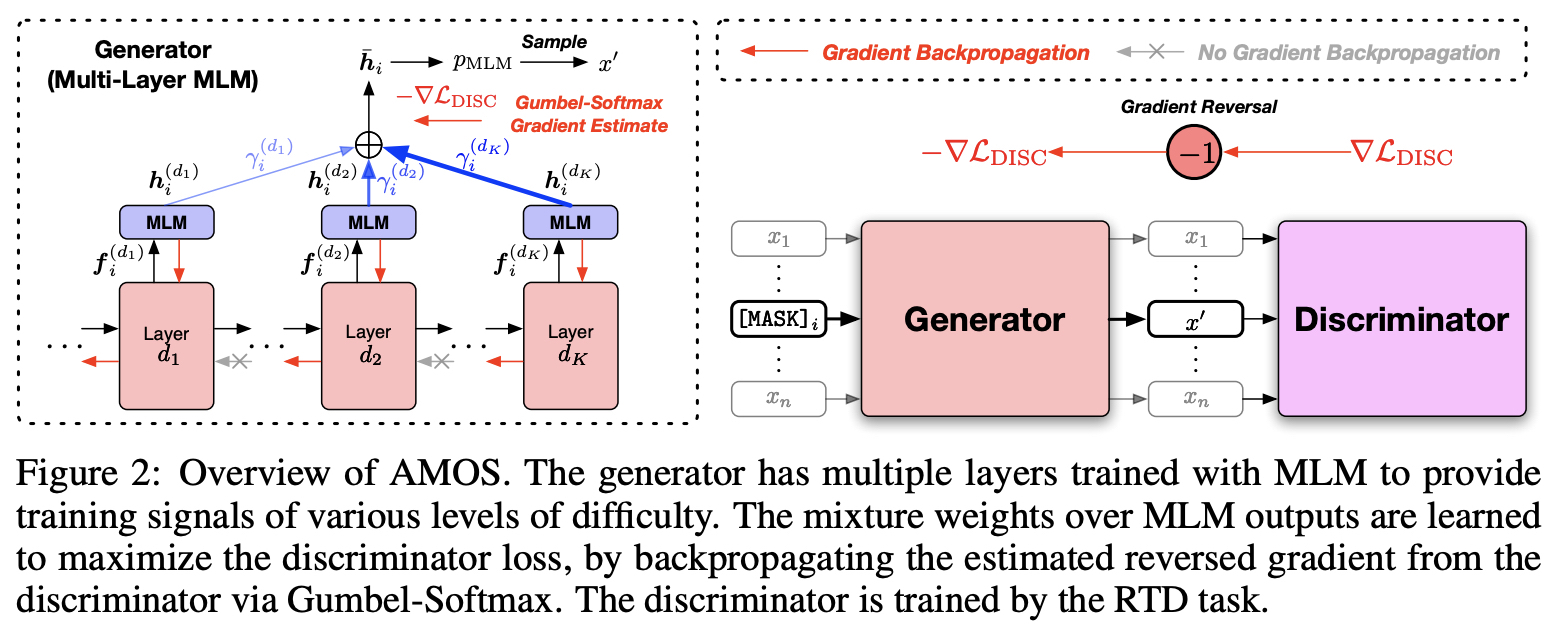
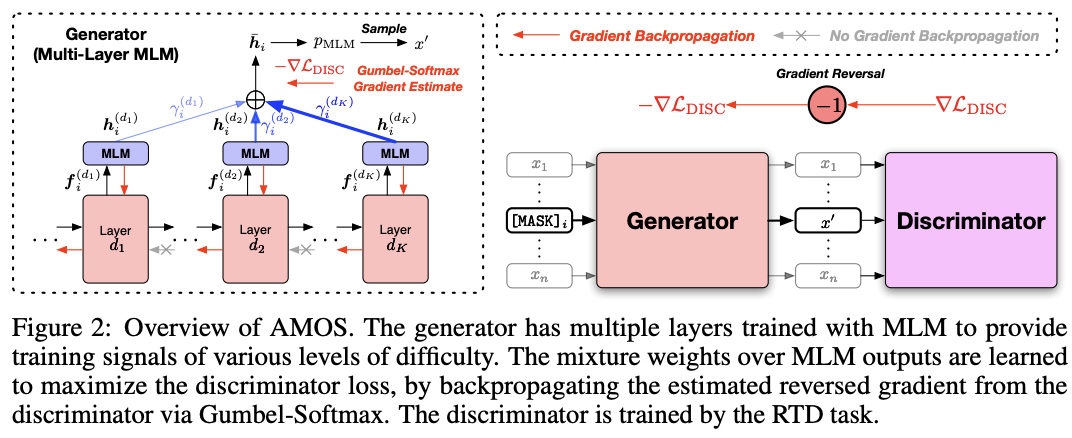
- 문장의 난이도와 각 층마다 생성되는 토큰들을 통해 다른 언어적인 정보를 배울 수 있다.
- shallow MLM model : 간단한 통사적인 정보에 초점이 맞춰져있다.
- deep MLM model : 복잡한 의미적인 정보가 내포되어있다.
Multi-layer MLM generator
- 하나의 인코더 모델의 다양한 레이어 결과들을 활용하도록 Multi-layer MLM 구성하였다.
- 완전히 다른 Generator 여러개 사용하면 파라미터를 엄청나게 증가시키므로 이 점을 보완하기 위함
- ELECTRA generator MLM 해당하는 수식(아래)과 비교해보면,
AMOS에서는 각 레이어 d 마다 MLM 결과값()을 활용하고 있음을 볼 수 있다.
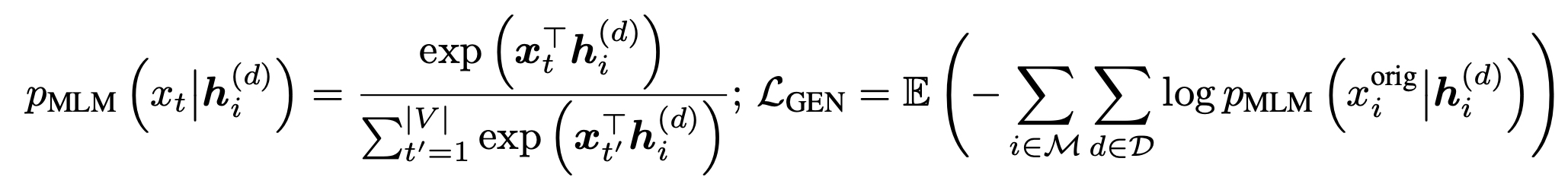
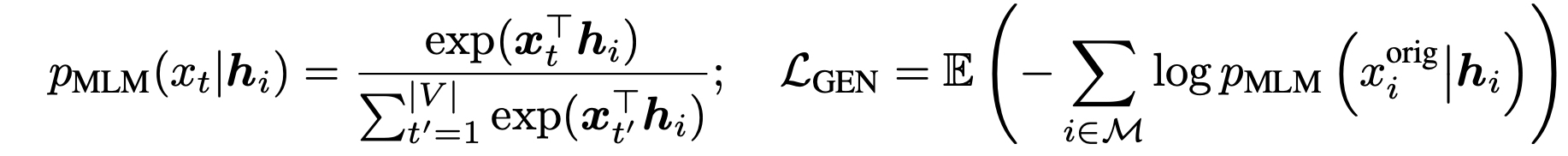
- 레이어들이 사용하는 projection head 파라미터를 공유하여 사용한다. (shared)
- 각각의 MLM objective에 따라 학습이 진행된다.
- 위 그림에서 빨간색 화살표로 드러나듯이, 각 블록(레이어) 사이 역전파가 흐르지 않는다.
- 각각 독립적인 여러 Generator를 가지는 효과를 낼 수 있다.
Learning Adversarial Mixture Weights
- Generator, Discriminator 동시에 학습되면서 점점 더 맞추기 어려운 문장이 생성되어 Discriminator의 능력치를 올려주었으면 한다.
- ELECTRA에서도 Generator가 잘 학습되면 Discriminator가 맞추기 어렵게 된다. (Adversarial training)
- 이 논문에서는 Discriminator에 초점을 맞춰 어려운 문장을 생성해내기 위해 Mixture weight를 도입하였다.
- 마스크 처리된 토큰들에 대해서 Mixture weights 씌워 만들도록 하였다.
- 는 위 그림에서 볼 수 있듯이 MLM head 를 거치지 않은 결과값이라고 보면 된다.
- : 학습되는 weight vector이다.
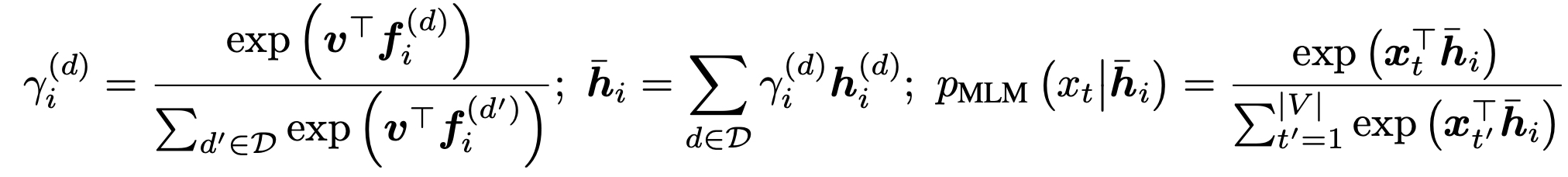
- 샘플링은 Discriminator의 영향을 받아 Mixture weights 학습시킬 수 없기 때문에 Gumbel softmax를 사용한다. (gradient estimation)
- Gumbel softmax (a continuous distribution)
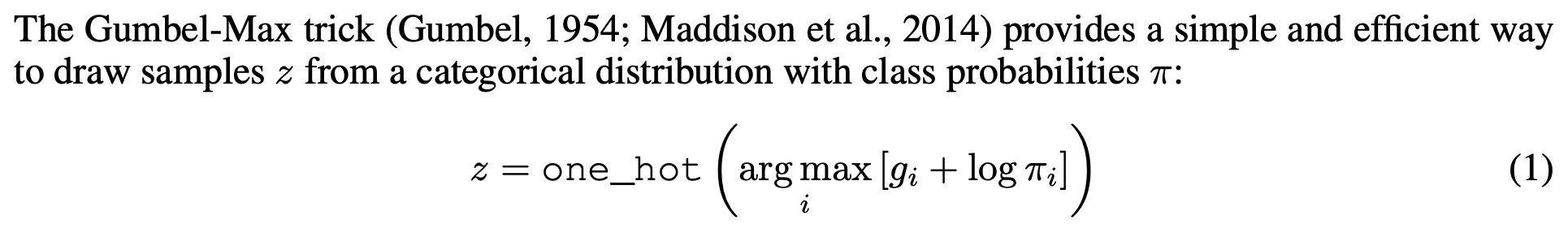
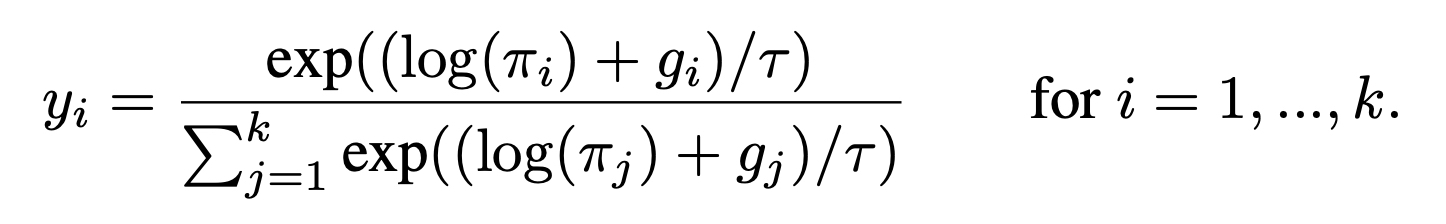
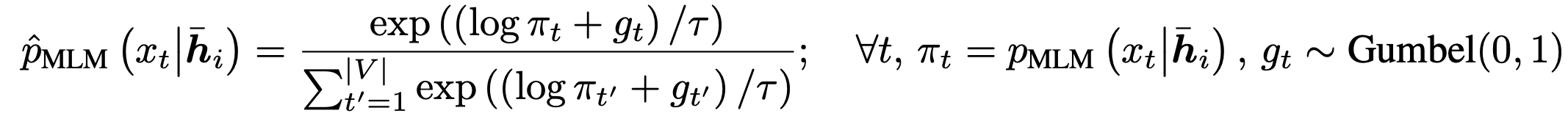
- temperature
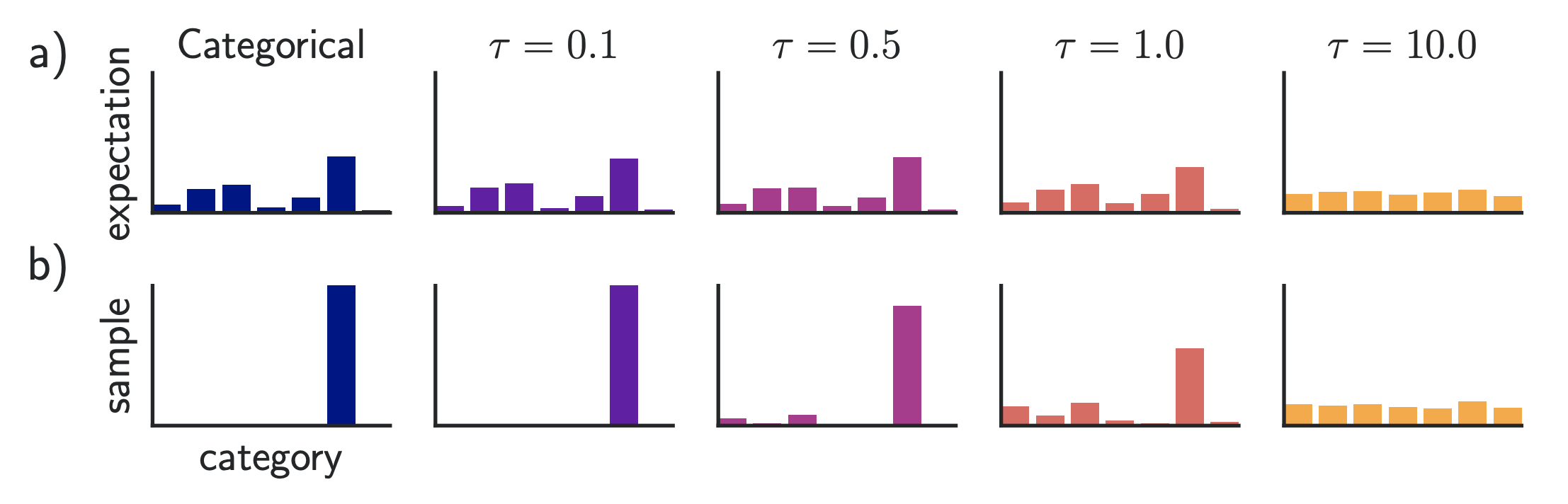
- Gumbel softmax (a continuous distribution)
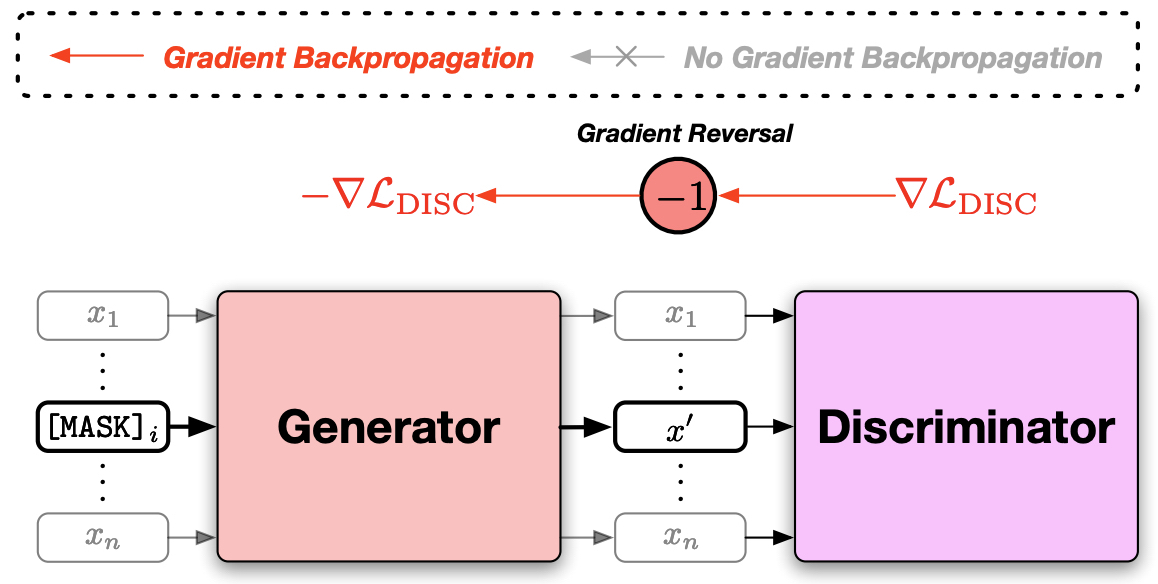
- Gradient reversal layer
- Adversarial learning에서 한 쪽의 성능은 높이면서 다른 한 쪽의 성능을 낮춰야할 때에 음수 부호를 붙인 상수를 곱해 로스항에 결합하는 방식(Domain-Adversarial Training of Neural Networks)
- Discriminator 쪽에서 넘어오는 gradient -1 곱해줌으로써 Mixture weights 학습하도록 한다.
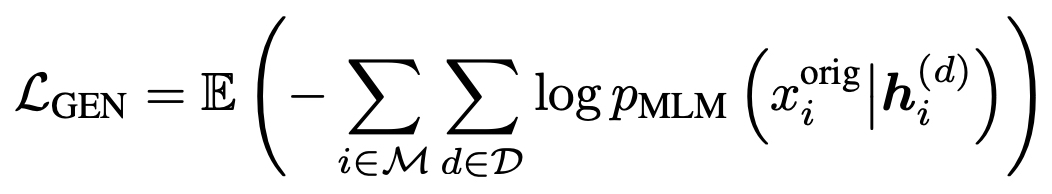
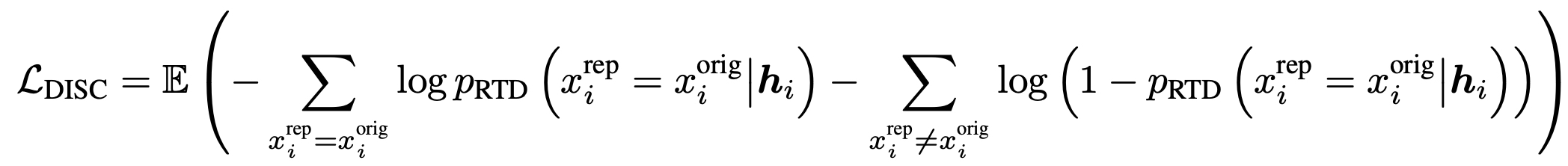
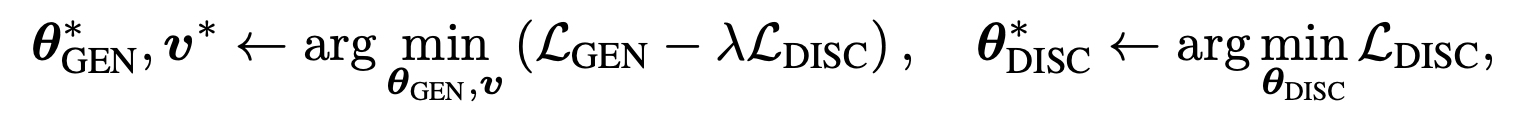
- ELECTRA objective
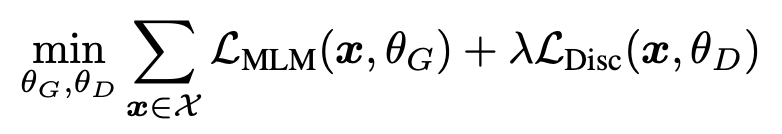
Experiments
- hyperparameter
- = 0.3
- = 50
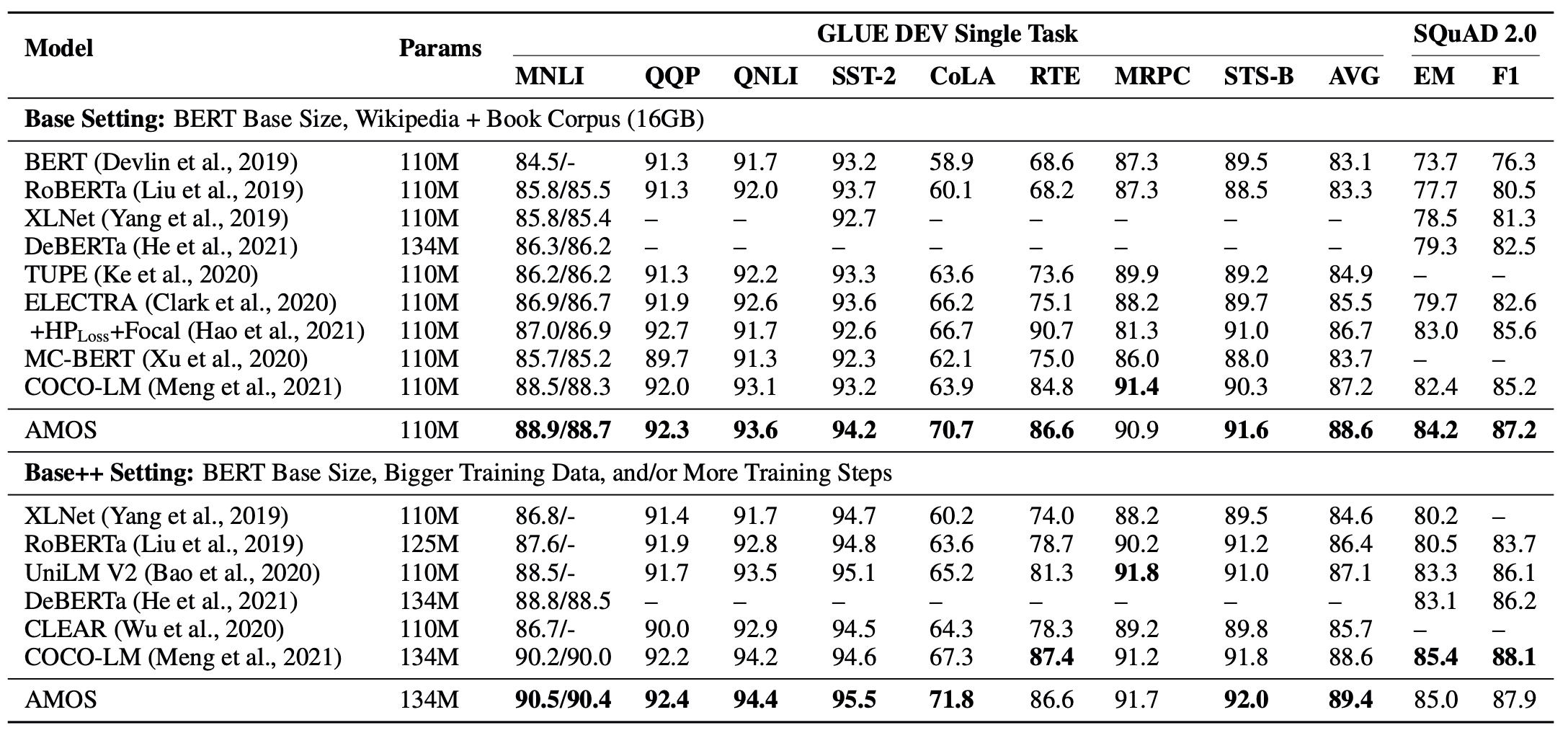
Abalation study
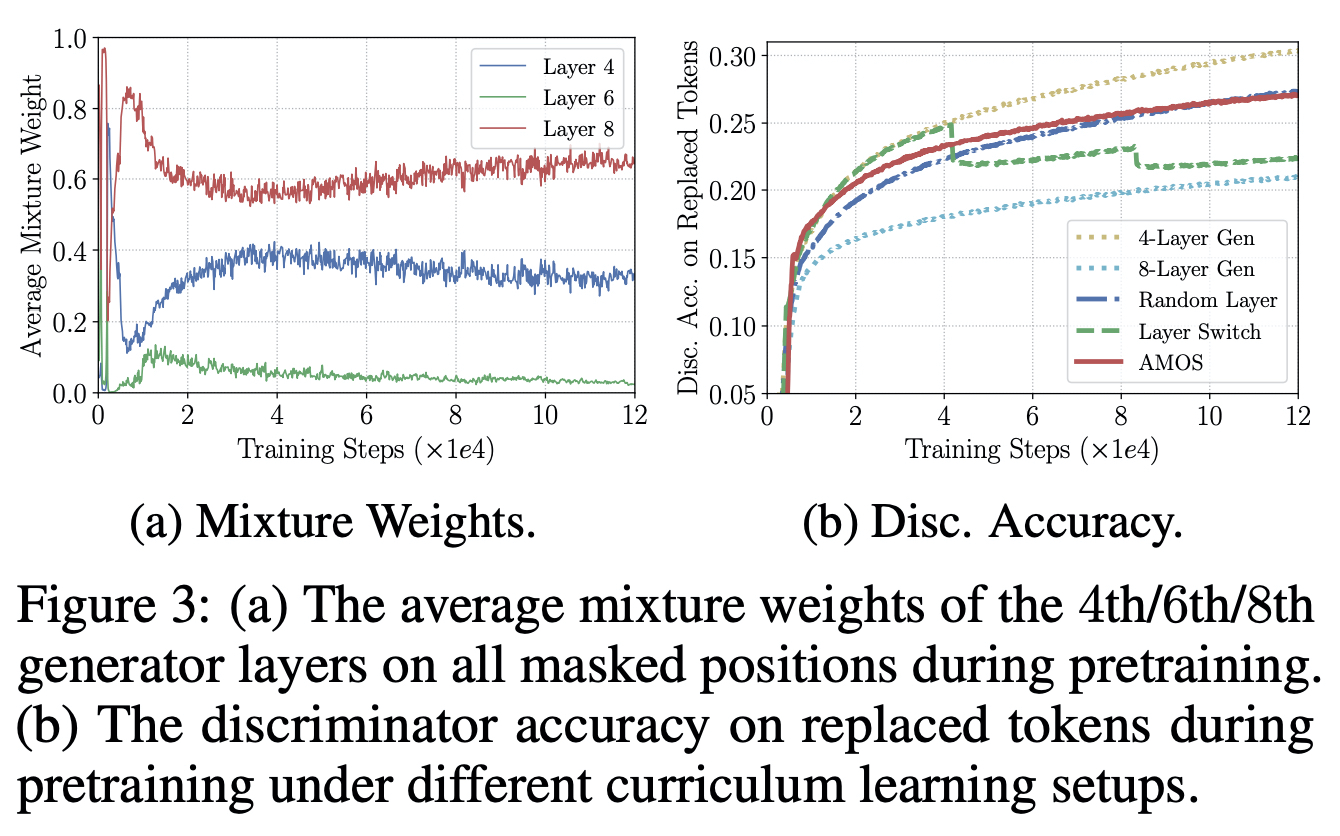
- Curriculum setup
- Mixture weights으로 결합하는 것이 아니라, 랜덤하게 그 중 하나 뽑아서 Discriminator로 보냈음.
- layer switch : 4, 6, 8 레이어의 결과값들이 순서대로 Discriminator 들어가도록 함.
- Adversarial setup
- -adv. train : Mixture weights 구할 때 모든 가중치를 같게함.
- MLM setup : layer 중간 gradient 전부 통하게 함.
- 단일 레이어를 사용하는 것보다 레이어 다양하게 사용하는 것이 낫다.
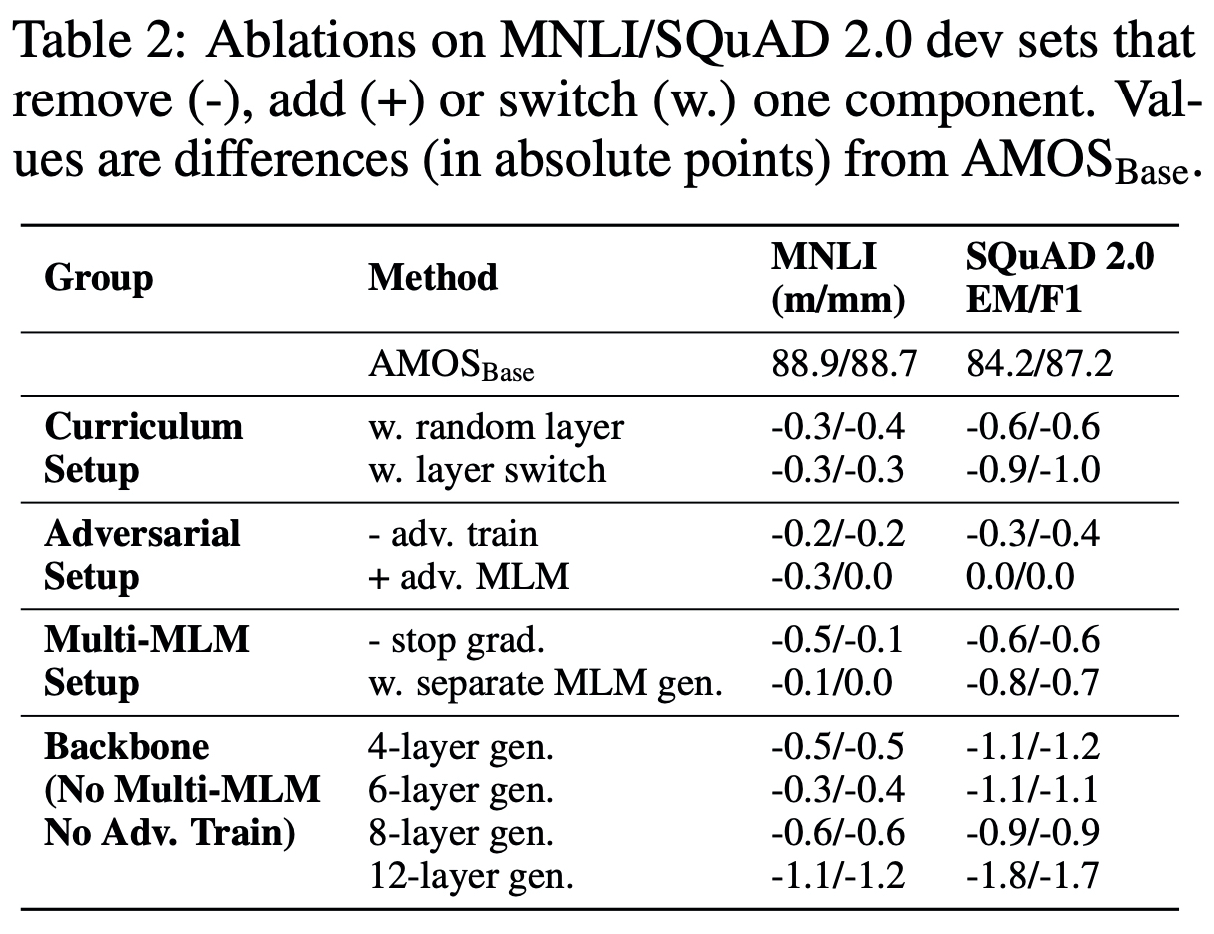
Diverse pretraining signals
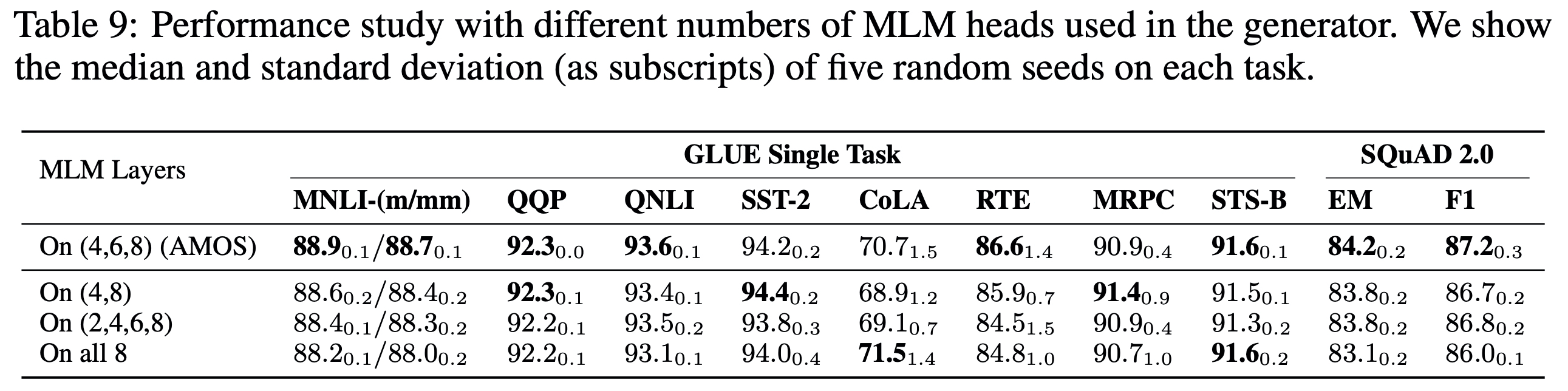
- 세 레이어에 대해 각각 잘하는 것이 조금씩 다른 것을 통해서 난이도와 언어적인 측면에서의 다양성을 Discriminator에게 줄 수 있다고 볼 수 있다.
- 네 번째 레이어는 다 잘하지는 못하지만, 이런 부분들조차 Discriminator는 변경된 토큰인지 아닌지의 여부를 판단하는데에 도움이 된다.
- 네 번째 레이어는 다 잘하지는 못하지만, 이런 부분들조차 Discriminator는 변경된 토큰인지 아닌지의 여부를 판단하는데에 도움이 된다.
Adversarial Training
Mixture weights
- 네 번째, 여섯 번째, 여덟 번째 layer 비교했을 때, 여덟 번째의 레이어에 붙은 mixture weight는 계속해서 증가하는 한편, 나머지 둘은 훈련이 계속될 수록 조금 줄어드는 양상을 보였다.
- 훈련이 진행될 수록 문제를 더 어렵게 만들고자 한다는 것을 알 수 있다.
Generator ablation
- AMOS와 Random layer 비교하면, 훈련 초기에는 AMOS가 쉬운 문제들을 주고, 시간이 흐를 수록 더 어려운 문제들을 내어주고 있다고도 해석할 수 있다.
- Layer switch 경우에는 두 번째 레이어, 네 번째 레이어, 여덟 번째 레이어를 순차적으로 사용하면서 정확도가 흔들리는 양상을 보인다. 상위 레이어로 쓸 때마다 훈련을 방해하는 것으로 볼 수 있다.

산미 있는 커피를 좋아하는 자연어처리 엔지니어. 일상 속에서 요가와 따릉이
를 좋아합니다. 인간의 언어를 이해하고 생성하는 AI 기술 발전을 위해 노력하고 있습니다. 🧘♀️🚲☕️💻